-
-
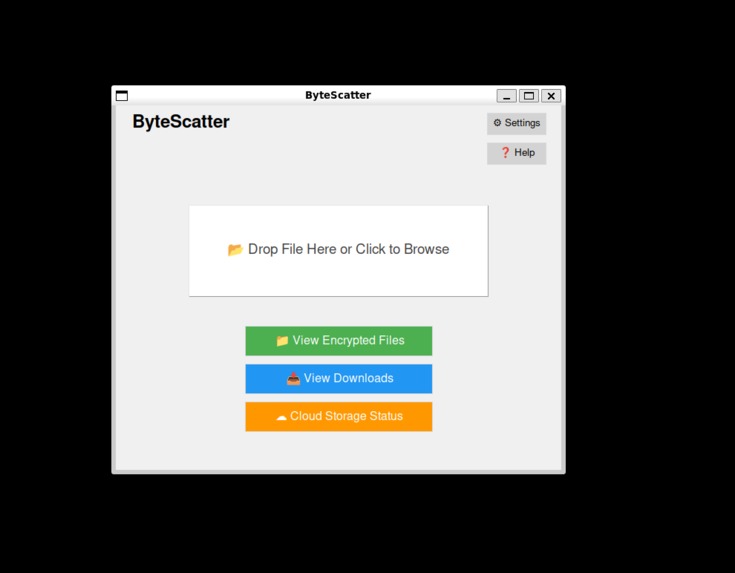
Main screen
-
Help guide
-
Select input file
-
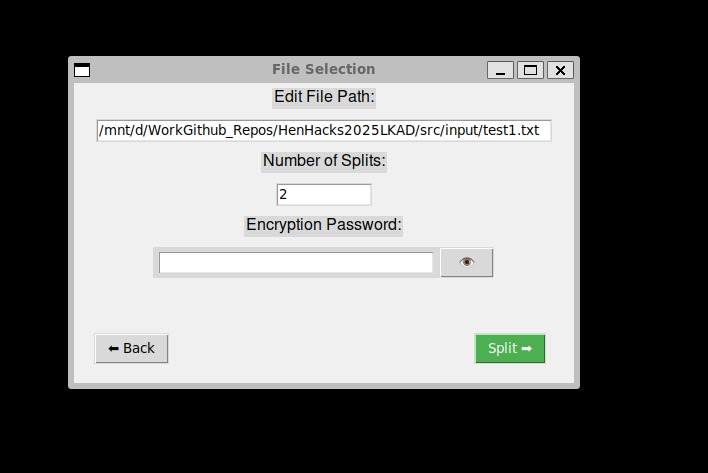
File selection
-
File selection with hidden password
-
File selection with shown password
-
Successful encryption
-
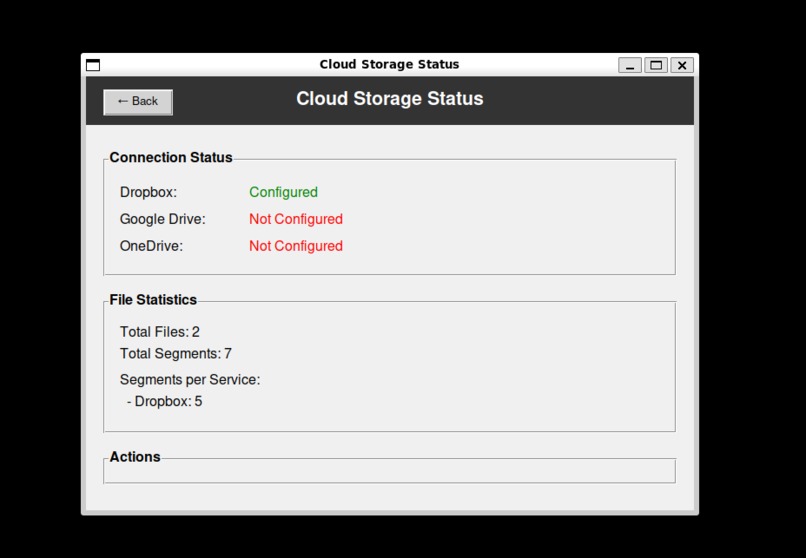
Cloud storage status
-

File manager
-
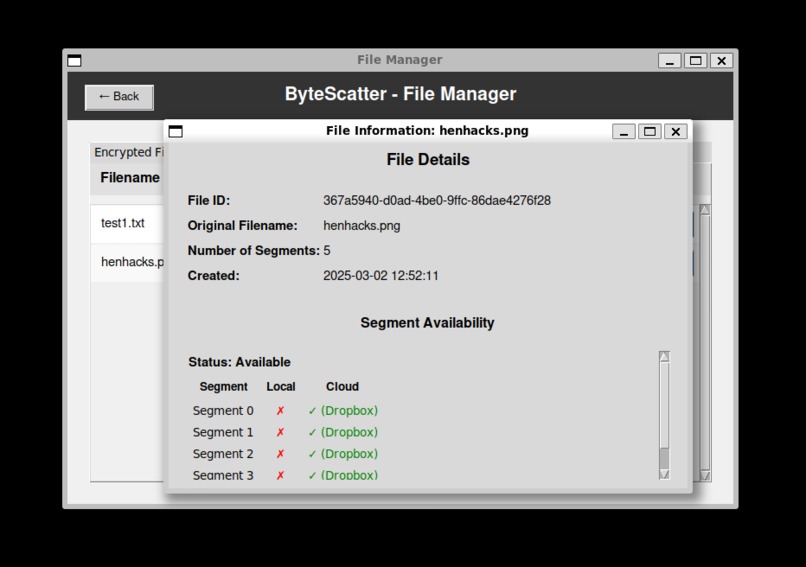
File details and segment availability
-
Currently downloaded files
-
Settings












Inspiration
ByteScatter addresses a fundamental and relevant problem in cloud storage security: how to leverage the convenience of cloud storage while mitigating the risk of unauthorized access. With this rapid change of AI training ethics and privacy laws (such as the EU cracking down on Apple), we figure this is more relevant than ever. Traditional approaches rely solely on encryption, which creates a single point of failure if the encryption key is compromised. ByteScatter takes a different approach by implementing a "divide and conquer" strategy: Files are split into multiple segments Each segment is individually encrypted with strong cryptography Segments are distributed across different cloud providers (Google Drive, Dropbox, OneDrive) A local metadata database maintains the information needed for retrieval and reconstruction This approach offers several significant advantages:
Enhanced Security: Even if an attacker compromises one cloud account, they obtain only encrypted fragments, not the complete file Distributes Trust: No single cloud provider has access to the entire dataset Leverages Multiple Storage Quotas: Users can maximize available free storage across services Redundancy Options: The system can be configured to store redundant segments for fault tolerance
What it does
ByteScatter implements a modular architecture with the following core components:
File Segmentation Engine: Splits files into a (user specified) number of chunks Encryption Module: Manages key derivation, segment encryption, and authentication Cloud Service Connectors: Interfaces with cloud storage APIs Metadata Management: Tracks segment locations and encryption details User Interface: Command-line interface for file operations / GUI
The system offers two primary workflows: File Upload (Encryption and Distribution): User provides a file, number of segments, and encryption password System segments the file and generates a master encryption key Each segment is encrypted with a unique derived key Segments are distributed across configured cloud services Metadata is recorded in the local database File Download (Retrieval and Reconstruction): User selects a file from the database and provides the password System locates segments (locally if available), and orders them Segments are decrypted and verified Original file is reconstructed and saved locally
The data flow through the system follows this pattern: Original File → Segmentation → Encryption → Cloud Distribution ↓ Metadata Storage ↓ Cloud Retrieval → Decryption → Reassembly → Restored File
Each step involves careful handling of data to maintain security and integrity throughout the process.
How we built it
ByteScatter implements a sophisticated encryption model using a key hierarchy: Master Key Derivation: A file-specific master key is derived from the user's password using PBKDF2 or Argon2id (when available) with a high iteration count
Segment Key Derivation: For each segment, a unique key is derived from the master key using HKDF Segment Encryption: Each segment is encrypted using AES-256-GCM or ChaCha20-Poly1305, providing both confidentiality and integrity.
The segmentation engine divides files intelligently based on type:
Text Files: Split by line count, ensuring each segment contains complete lines Binary Files: Split by byte ranges, ensuring each segment is under configurable size limits The system adapts segment size based on file size, with logic to prevent excessive fragmentation of large files or inefficient handling of small files. This method of implementation proves useful, as all kinds of common files are fully supported. Whether it be encrypted data formats like .docx, plain .txt, or even images and audio!
ByteScatter attempts to integrate with multiple cloud storage services through their respective APIs:
Dropbox: Direct integration using the Dropbox SDK Google Drive: Integration via the Google API client OneDrive: Integration through Microsoft Graph API
Each connector implements a common interface for upload, download, and deletion operations, making the system extensible to additional cloud services. One significant implementation detail is the handling of API rate limits and quotas. The system implements exponential backoff for failures and distributes uploads to stay within service limits.
The system uses SQLite for structured metadata storage with the following schema: master_files: Stores file-level metadata (ID, name, segment count) master_keys: Stores key derivation parameters and verification hashes segment_keys_info: Stores segment-specific encryption details segment_cloud_locations: Tracks where each segment is stored This relational approach is efficient for querying file retrieval and maintenance operations.
Challenges we ran into
Description: While pulling the latest changes, we encountered merge conflicts in multiple files. The conflicts arose due to simultaneous edits by multiple team members on the same lines of code.
Resolution Attempted: Used git status to identify conflicting files. Manually resolved conflicts by editing the files. Used git add to mark conflicts as resolved. Committed the changes using git commit.
Early versions of the encryption module faced several critical issues: Key Derivation Problems: Initial implementation derived segment keys insecurely without proper cryptographic key derivation functions
Solution: Implemented HKDF (RFC 5869) to properly derive unique segment keys Data Authentication Handling: Early versions of the code had no checks to ensure data wasn’t corrupted. This would result in the program returning a successful encrypt/decrypt while rendering the file unusable Solution: During the decryption process, unique metadata including the algorithm used, authentication tag, segment data, etc…). Each of these parameters are loaded from the DB and used to verify each segment independently (Any fails to this check result in instant halt and report)
Accomplishments that we're proud of
Secure File Distribution: Files are split, encrypted, and distributed across multiple cloud services Strong Encryption: AES-256-GCM and ChaCha20-Poly1305 provide state-of-the-art security File Management: Interface for listing, retrieving, and deleting encrypted files Cloud Integration: Support for Google Drive, Dropbox, and OneDrive (MORE ON THE WAY, the modular design is very flexible) Availability Verification: Tools to check if all segments of a file are available for retrieval Chunk Identification - Even if chunks are missing from the local machine, the DB will inform which chunks are needed to complete assembly, as well as if they are available on a cloud service
What we learned
ByteScatter represents a significant advancement in secure cloud storage by combining strong encryption with physical distribution of data. The system's core innovation—spreading encrypted segments across multiple cloud providers—creates a security model where compromising a single cloud account or even the encryption algorithm alone is insufficient to access the protected data. The development process revealed the challenges inherent in implementing cryptographic systems correctly, particularly when integrating with cloud APIs. Through careful implementation and testing, these challenges were overcome to create a robust, secure file protection system. ByteScatter demonstrates that with proper cryptographic practices and thoughtful system design, it's possible to leverage cloud storage while maintaining strong security guarantees. This approach provides a valuable option for users and organizations with sensitive data who wish to utilize cloud services without fully trusting any single provider with their complete data. Your data is yours. Let’s keep it that way.
What's next for ByteScatter
Increased ability to implement other cloud inputs.




Log in or sign up for Devpost to join the conversation.