-
-

Meta Terminal
-
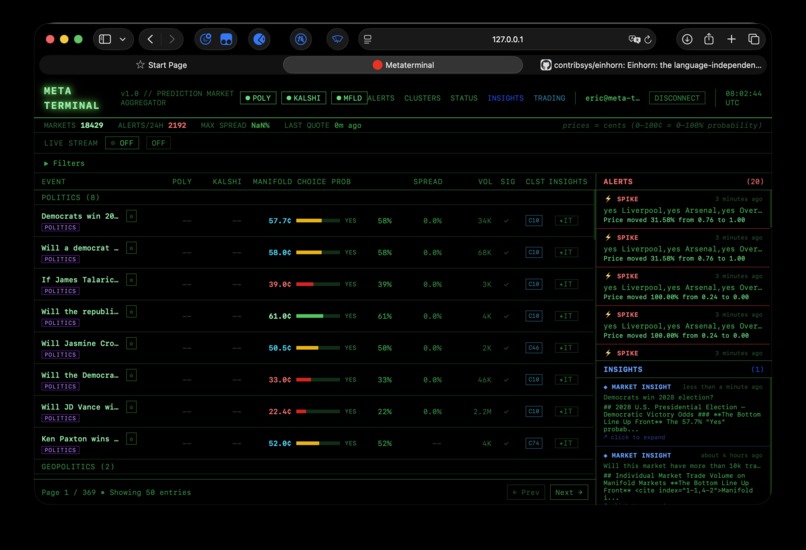
Main Page
-

AI Analysis for Market Context
-
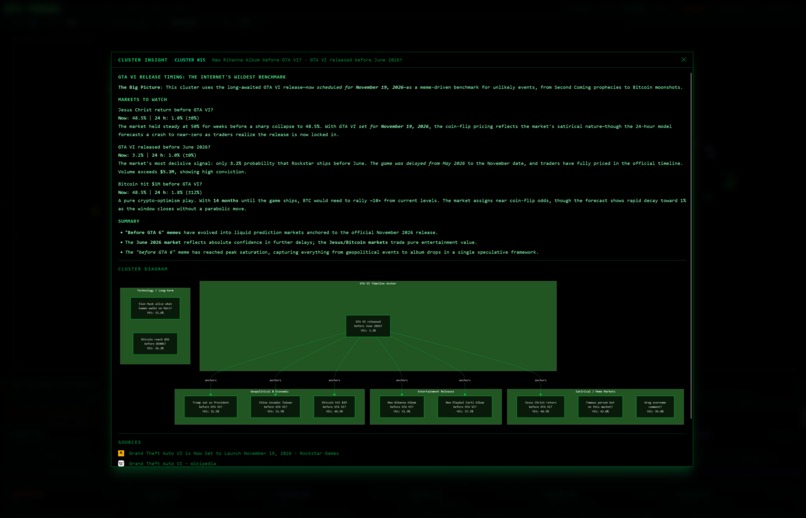
Cluster Analysis of several markets, with visualisation of relationships
-
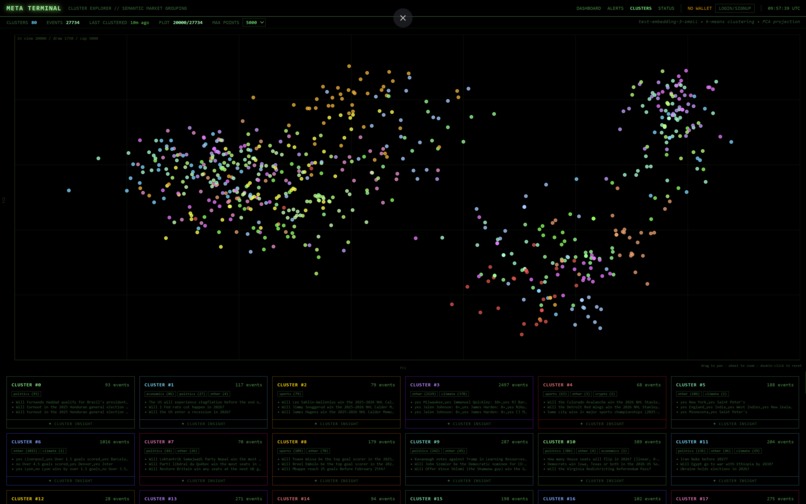
Clustering of markets
-
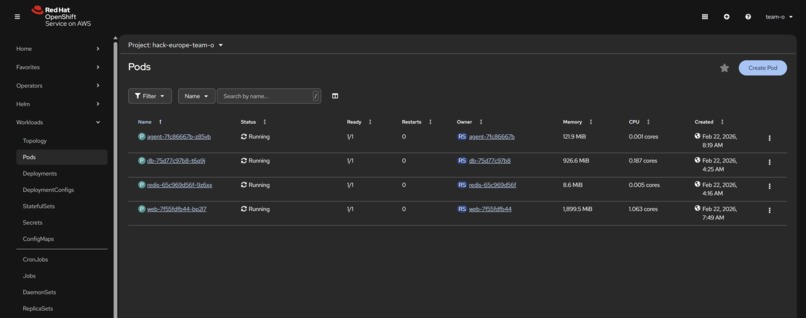
Openshift deployment
-
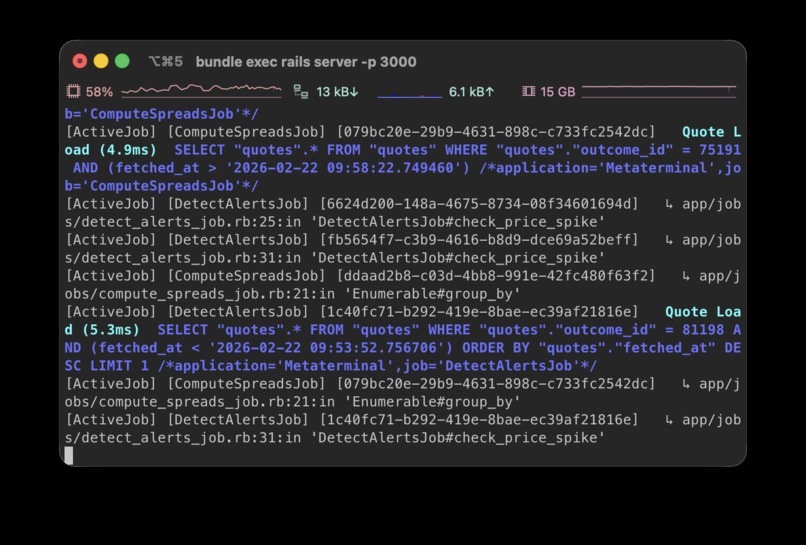
Ruby on Rails
-
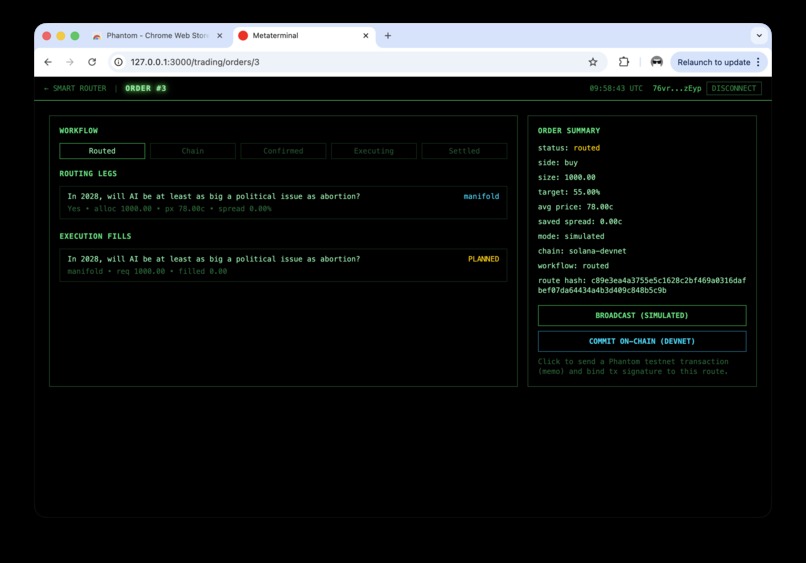
Trading Page
-
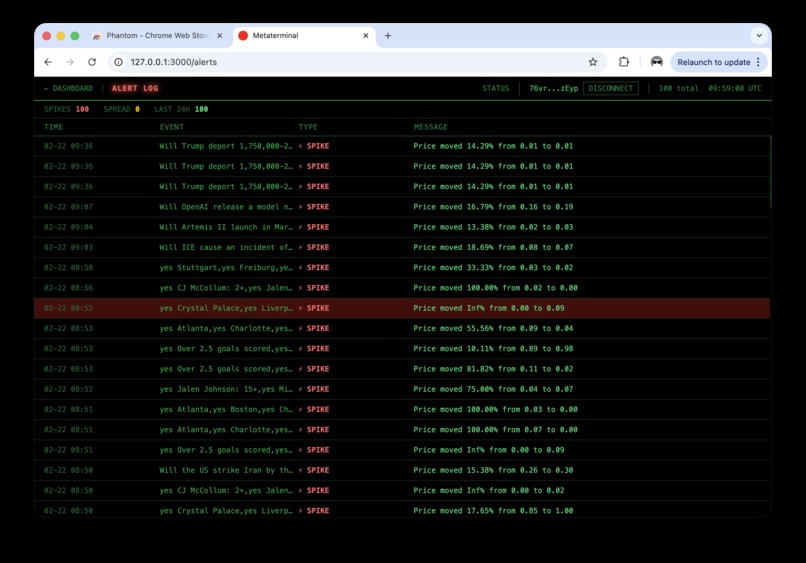
Alerts
-
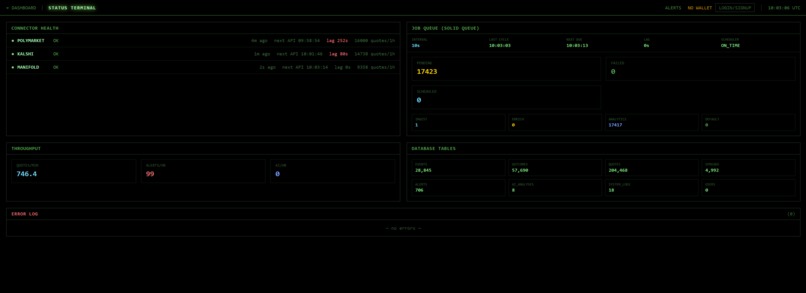
Status Page
-
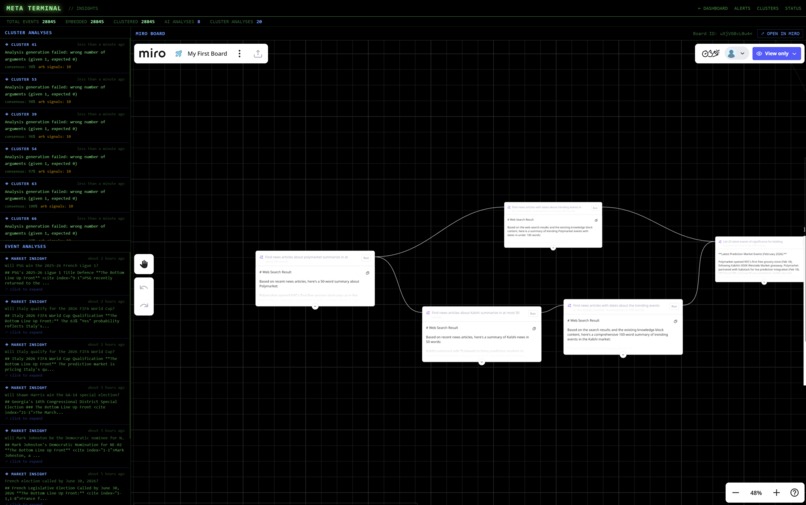
Miro AI Integration











Project Story
Prediction market liquidity is fragmented. The exact same event often trades at different probabilities across venues, but capturing that value requires hopping between dozens of tabs and analysing stale data. We built Meta Terminal to ingest real-time market data, normalise & cluster it, and deploy autonomous agents and models to analyse markets. The result is a unified, real-time terminal that identifies anomalies and arbitrage opportunities that human traders miss.
What Inspired This Project
The core inspiration was the gap between market information and actionable routing. Most dashboards stop at visualisation. We wanted to bridge:
- Real-time market aggregation
- Signal generation (spreads, spikes, anomalies)
- Execution workflow (smart order planning + on-chain commit trail)
- Market analysis & contextualisation - why the market behaves as it does
In other words: not just “what is happening,” but “what should I do next, and how do I prove what I did?”
How We Built It
Meta Terminal is built as a Rails 8 platform with three major layers:
Ingestion + normalisation
Connectors fetch markets and quotes from Polymarket, Kalshi, and Manifold. Data is normalised into canonicalevents,outcomes, andquotes.Analytics + intelligence
Background jobs compute spreads, detect volatility/anomaly alerts, agentically generate AI analysis, and cluster related markets with embeddings + k-means + PCA projection. We operate this in a microservice manner, for example, using Pydantic AI in Python to create an AI agent service for data analysis and market research.Execution + workflow state
A smart-order router ranks candidate markets and allocates order size based on spread-aware heuristics, then tracks order legs/fills and supports simulated or Solana devnet commit verification.
A simplified route scoring idea is:
$$ \text{score}_i = \alpha \cdot p_i + \beta \cdot s_i $$
where (p_i) is price and (s_i) is spread signal for candidate (i). Allocation weights are then normalised from inverse spread risk.
The whole solution is deployed using flexible microservice containers on OpenShift with a gRPC communication layer, allowing a platform that can be easily scaled depending on the volume of data being processed. Our custom clustering ML models are deployed on OpenShift to allow background task processing.
Challenges We Faced
- Cross-venue normalisation: Different APIs, schemas, quote semantics, and pagination behaviours had to map into one consistent model.
- Freshness + throughput: Ingesting every few seconds without duplicate/stale writes required careful job flow and locking.
- Signal quality: Raw spread numbers can be noisy; we needed thresholds and statistical filters to reduce false positives.
- LLM integration reliability: AI insight generation had to degrade gracefully when upstream latency/errors occur.
- Execution realism: Simulated routing is easy; introducing devnet transaction verification and workflow state transitions made correctness much harder.
- System observability: We added a status surface for connector health, queue state, and ingestion lag to debug operational issues quickly.
What We Learned
- Good market intelligence is mostly a data engineering problem before it’s an AI problem.
- Queue topology matters: separating ingest/enrichment/analytics avoids slow jobs blocking hot paths.
- Modelling workflow state explicitly (routed, submitted, confirmed, settled, failed) prevents hidden edge-case bugs.
- “Simple” connector integrations become complex at production cadence.
- AI is most valuable when constrained by structured context from deterministic pipelines.
Track
We chose to enter the "agentic AI track", as our system utilises several agents to analyse and contextualise markets. This includes conducting background research to explain market movements (e.g. why the market has settled at a certain probability), whilst also explaining clusters of prediction markets and how they relate to each other. Our agents are provided custom tools to interact with our data ingestion pipelines and ML clustering & mathematical prediction models. We envision these agents could be used to spot arbitrage opportunities between markets related to similar or linked events.
Challenge Selections
Best Use of Data
Our system utilises over 1,000,000 market events, ingested live at over 400 events per minute across 25,000 individual markets. We conduct advanced data analysis on this, alerting on major changes (spikes) in pricing and clustering related markets with embeddings + k-means + PCA projection to find arbitrage opportunities.
Best 'Built on Rails' Project
Our main web application is built using Ruby on Rails, utilising advanced features such as Active Job with a Solid Queue backend.
Best Use of Claude
Our agentic analysis and research features use the latest Claude models (namely Haiku 4.5 and Sonnet 4.6) to produce agents capable of reasoning across a high volume of market data, with a variety of custom tools available, including RAG and clustering.
Best Use of OpenShift AI Platform
We deployed our application to an OpenShift cluster directly, involving 3 distinct services with gRPC for communication between them. It proves our solution can be scaled to run on modern production infrastructure. Further, our custom clustering ML models are deployed on OpenShift to allow background task processing.
Best Use of Miro AI
We use Miro AI to visually present complex agent research workflows in an intuitive manner to end users. We envision that users could use Miro AI to manage agentic research workflows used by our solution.
Best "Built on Solana" Product
Thanks to Solana's 4ms low latency and immense contract flexibility, users can make custom smart contracts in our terminal with routers, enabling trading across multiple exchanges at a lower spread for the same event. Users can easily log in with their Solana wallet to start trading on our platform.
Best Team Under 22
All of our team members are 22 or under.
Built With
- Languages: Ruby, JavaScript, Python, Rust
- Web Framework: Ruby on Rails 8
- Frontend: Hotwire (Turbo + Stimulus), Tailwind CSS, Importmap
- Background Processing: Solid Queue
- Database: PostgreSQL
- Cache/Infra: Redis
- AI/ML: Anthropic API, OpenAI embeddings, NumPy/Pydantic, Pydantic AI
- RPC/Interop: gRPC, Protocol Buffers for internal microservice calls
- Market APIs: Polymarket (Gamma/CLOB), Kalshi API, Manifold API
- Blockchain: Solana devnet, Anchor (program scaffold), Ed25519 signature verification
- Deployment Tooling: Docker, Docker Compose, Kubernetes/OpenShift manifests, Kamal
Running the application
The application can be run by following the README instructions in our repo: https://github.com/Eric-xin/meta-terminal. Developers can also quickly get started by running docker compose -f docker-compose.dev.yml up --build, which quickly provisions a local environment with the correct dependencies and database config.
Hackathon Location
Made at HackEurope's Dublin venue.

Log in or sign up for Devpost to join the conversation.