-
-
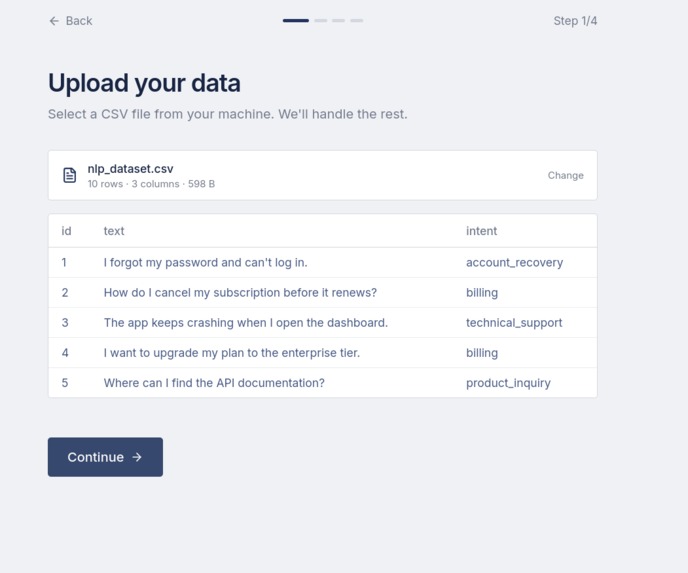
User Dataset Upload
-
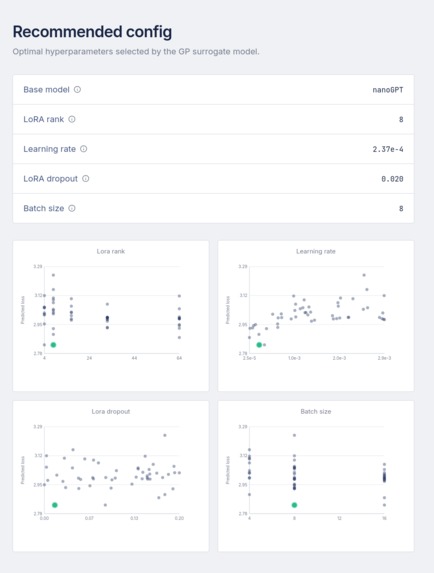
MetaTune Suggesting Hyperparameters for Model Training
-
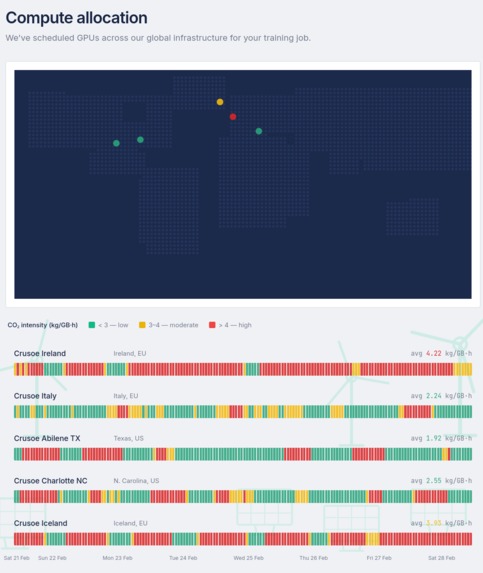
Carbon-Aware Scheduling and Routing
-
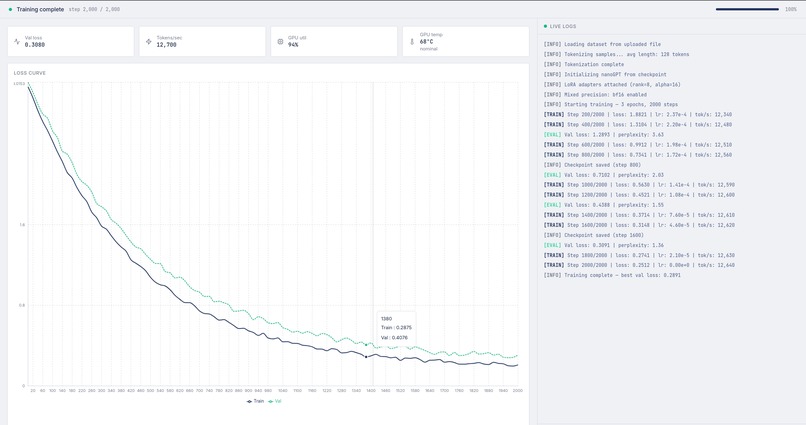
Optimized Training on Openshift
-
Carbon Statistics





MetaTune: Eliminating AI Compute Waste Before It Happens
1. The Invisible Waste
Imagine trying to crack a combination lock by testing every single number. That is exactly how the AI industry finetunes models today.
When a data scientist finetunes a model like LLaMA or nanoGPT, they don't know the correct settings (hyperparameters) to use. So, they run a "grid search", blindly launching dozens of identical training jobs with slightly different tweaks, hoping one succeeds.
The runs that fail? That is wasted money and exhausted CO₂. Today, 20% to 30% of total AI training compute comes strictly from this trial-and-error phase. This brute-force guesswork results in an estimated 8 to 10 Million Metric Tonnes of CO₂ emissions every single year. [1]
We don't need to build more data centers to solve this. We just need to stop guessing.
2. Our Solution: The "MetaTune" Engine (High-Level)
If you knew which combinations worked best for your specific type of data, you could cut your fine-tuning time by up to 90%. But currently, every AI team starts from absolute zero.
MetaTune is an end-to-end, carbon-aware ai model training/fine-tuning platform that stops the waste in two steps:
- The Brain (Compute Reduction): We build a massive database of historical fine-tuning runs. When you upload a dataset, our AI instantly profiles it, compares it to our database, and accurately predicts the top 3 best configurations. Therefore we can reduce the required training runs by 90%.
- The Router (Compute Shifting): For the jobs that need to run, we don't launch them on dirty cloud servers. Our routing engine looks at global weather forecasts and physically shifts your compute to data centers running on stranded wind and solar energy.
3. Technical Deep Dive: The Intelligence Layer
We'll focus on LoRA fine-tuning (post-training) as opposed to pre-training, because people tend to use the same pretrained model quite often for their needs, and thus there should be enough data for our model to predict the best hyperparameters. However, the same approach can be used for pre-training, as any ML training pipeline inherently involves some hyperparameters. Moreover, we'll focus on transformers and language datasets.
When a user uploads a dataset, we extract structural NLP meta-features, like the Type-Token Ratio and Zipf's Alpha. We pass this into our Bayesian Optimization engine.
Instead of random sampling, we use a Gaussian Process to model the unknown, expensive black-box function of validation loss, \( f(\lambda) \), where \( \lambda \) represents the hyperparameters. Our surrogate model calculates the Expected Improvement to decide exactly where to sample next: $$ EI(\lambda) = \mathbb{E} \left[ \max(0, f(\lambda^*) - f(\lambda)) \right] $$
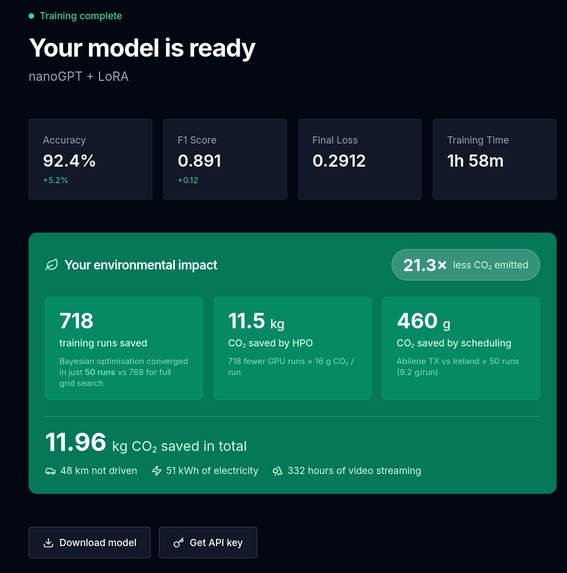
By sampling regions with statistical guarantees to be optimal based on historical priors, we reduced the amount of screening runs for a nanoGPT model from 718 down to just 50, i.e., 21x times. [2]
4. Technical Deep Dive: The Infrastructure Layer
Reducing runs is only half the battle. To eliminate the carbon footprint of those remaining runs, we built a Spatio-Temporal MILP Scheduler deployed on Crusoe Cloud.
Our backend ingests a 168-hour global weather forecast to predict grid carbon intensity for each of the datacenters Crusoe could potentially schedule its users' jobs on. Based on the weather forecast, more specifically the solar and wind intensity at the specified location, we try to predict how green will the said datacenter be at that time.
Since the carbon footprint of a datacenter is dependent of the meteorological conditions, it is worth sometimes to move a job to a greener datacenter(at that specific hour) or to pause a job if we know better times are coming shortly ahead. Especially so if the user is willing to wait a while in order to reduce their carbon footprint.
We then formulate the workload scheduling via a Mixed Integer Linear Program (MILP) with rolling horizon.
Let \( x_{j,d,t} \in {0, 1} \) be a binary decision variable that equals \( 1 \) if job \( j \) is actively running at data center \( d \) during hour \( t \). We strictly minimize the total absolute carbon emissions: $$ \min \sum_{j \in J} \sum_{d \in D} \sum_{t \in T} R_j \cdot C_{d,t} \cdot x_{j,d,t} $$
Where \( R_j \) is the required RAM/Power draw, and \( C_{d,t} \) is the forecasted carbon intensity.
The solver acts as a mathematical traffic cop. It evaluates the user's strict deadline, respects the physical hardware capacities of the data centers (\( \sum_{j} R_j \cdot x_{j,d,t} \leq K_d \)), and packs the jobs perfectly into stranded-energy windows. To ensure each job is successfully finished before the deadline, we add the constraints \( T_{min} \leq \sum_{t} x_{j,t} \leq T_{max} \), where \( T_{max} \) is the deadline and \(T_{min} \) is the estimated amount of compute hours required, which can be estimated upfront after just a few forward passes.
5. The Flywheel Effect (Our Business Moat)
We packaged this math into a seamless platform built on OpenShift, targeting SMEs, research groups, and smaller AI labs. They bring their data; we give them a highly optimized, fine-tuned model for a fraction of standard cloud costs and training time.
The Data Flywheel. With every user that trains a model on MetaTune, we ingest the hyperparameter performance telemetry back into our foundational database.
Put simply: the first healthcare startup to train a medical classification model on our platform burns extra compute figuring out the right settings. The second healthcare startup shouldn't have to. With MetaTune, they inherit the intelligence of the first. We grow smarter, cheaper, and greener with every single API call.
6. The Vision
Training AI models does not have to be expensive, inaccessible, or environmentally reckless.
The industry's answer to the AI energy crisis is to build more nuclear plants and lay more power lines. Our answer is to write smarter software. We've shown it is possible to train AI for less energy, with less wasted compute.
MetaTune makes disposable training runs a thing of the past.
[1] https://www.climateimpact.com/news-insights/insights/carbon-footprint-of-ai/ [2] Own experiments finetuning nanoGPT with 5 different datasets
Built With
- bayesianoptimisation
- docker
- fastapi
- kubernetes
- linearprogramming
- openshift
- python
- pytorch
- typescript



Log in or sign up for Devpost to join the conversation.