-
-
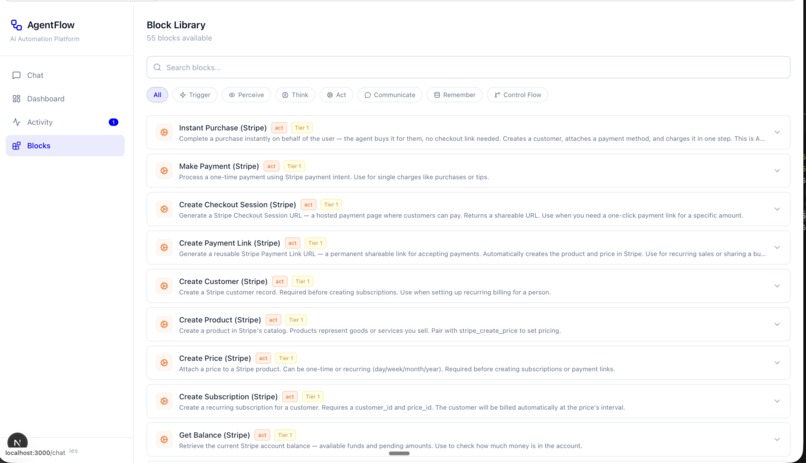
Blocks with different functionality
-
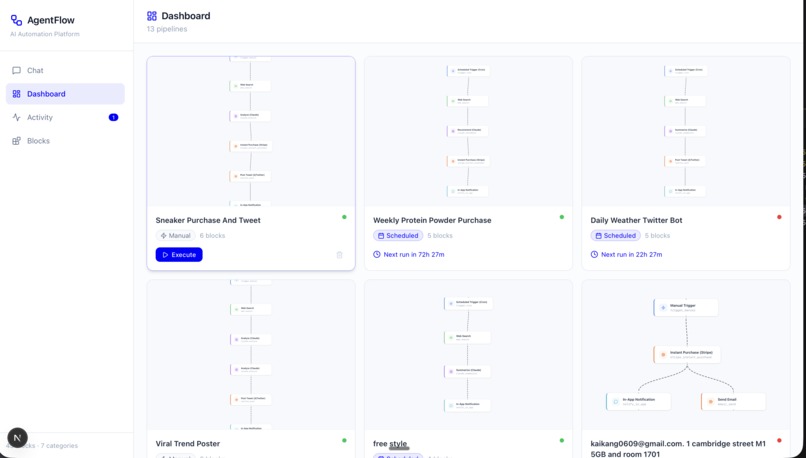
Dashboard of agents
-
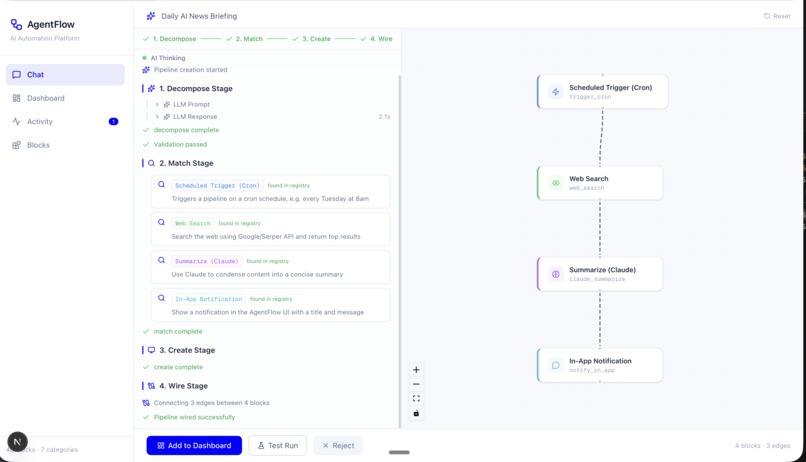
Creating agents



AgentFlow: From Intent to Execution in 30 Seconds
Team: Actually Incompetent
Inspiration
The world is drowning in repetitive automation tasks. Engineers spend countless hours wiring together APIs, orchestrating workflows, and building glue code that could be expressed in a single sentence: "Summarize top Hacker News posts every morning and email them to my team." Yet today, turning that simple request into working automation requires choosing between rigid no-code platforms or writing hundreds of lines of orchestration code.
We saw a fundamental insight: large language models are extraordinary at decomposition. They can break complex intent into atomic, addressable components. But they're terrible at execution. What if we built a platform where the LLM does what it's good at (understanding intent, planning, reasoning) while deterministic execution engines handle what they're good at (reliable, reproducible automation)?
Our inspiration was simple: democratize automation creation by bridging the gap between human intent and machine execution. Not through instruction-following, but through understanding. We wanted to build a system where anyone—not just senior engineers—could create sophisticated, multi-step workflows by simply describing what they wanted automated. The LLM would figure out how, and an execution engine would make it reliable.
The market validated this urgency: automation platforms are growing at 40%+ annually, yet 76% of teams still rely on manual processes or brittle scripting. MotherAgent tackles this head-on with a system that's intelligent enough to reason about workflows, but deterministic enough to handle production environments.
What it does
AgentFlow is an AI-powered agent construction platform that converts natural language automation intent into executable, observable, production-grade workflows in under 30 seconds. Users describe what they want automated. The system decomposes it into reusable blocks, intelligently searches a registry, synthesizes missing blocks if needed, wires them into a DAG, and executes it—all with real-time visualization of every decision.
The user experience is radically simple: Open Agent Studio → describe your automation → watch the "Thinker" break it down across four stages (Decompose, Search, Create, Wire) → see the pipeline DAG rendered in real-time → hit "Run" → observe execution with live node status updates. Results flow back with structured outputs, error recovery, and full traceability.
The technical magic is the 4-stage Thinker pipeline:
- Decompose - LLM analyzes intent and lists required atomic blocks
- Search - Hybrid semantic + full-text search finds matching blocks from our registry
- Create - For missing blocks, LLM generates Python code in a Docker sandbox with iterative validation
- Wire - Connect blocks into a DAG using LLM template mapping and schema validation
What makes MotherAgent different from existing automation platforms:
- Autonomous Block Generation: Unlike static no-code platforms, MotherAgent synthesizes new capabilities on-demand. Need sentiment analysis? The system generates the block, tests it, validates output schemas, and uses it immediately.
- Explainability: Every Thinker decision is streamed to the UI in real-time via SSE. Users see which blocks the system searched for, why it chose them, and how it wired them together. No black boxes.
- Production Safety: Blocks run in restricted execution environments with resource limits, input schema validation, and graceful failure handling. Failed upstream nodes skip dependents without halting the pipeline.
- Deterministic Execution: Same intent + same initial state = identical outputs. Built for reliability, not guessing.
Concrete example: A user says: "Monitor top Hacker News posts, filter for AI content, summarize each, and send me a daily email with a Stripe payment reminder." The system:
- Decomposes into: fetch HN → filter by topic → summarize each → compose email → add stripe reminder
- Searches registry: finds
web_scrape,code_run_python(filter), uses LLM for summarize, findsemail_send, findsstripe_pay - Finds no "compose email with summary" block → generates one (tests with sample HN data, validates output)
- Wires them: HN→filter→summarize→email→payment, with error recovery at each step
- Executes: parallel batch processing, results streamed to UI, full audit trail logged
How we built it
MotherAgent is a two-plane system that separates concerns for clarity and scalability. The Control Plane (Node.js/TypeScript) handles definitions, versioning, persistence, and scheduling. The Execution Plane (Python/LangGraph) handles DAG compilation and deterministic execution. This separation ensures the runtime is stateless and ephemeral—we never persist partial execution state, only completed results.
Frontend: Built with Next.js 16 + React 19 with React Flow for DAG visualization and Framer Motion for elegant state transitions. The Agent Studio page is a sophisticated state machine that manages the entire user journey: intent input → SSE streaming visualization → pipeline rendering → execution monitoring → result display. We built custom components for the 4-stage progress indicator and SSE event parser to handle real-time Thinker updates. Everything is dark-themed with Tailwind CSS 4 and responds to live execution status with visual feedback.
Backend: FastAPI with LangGraph for workflow orchestration. The architecture includes:
- Thinker (
thinker_stream.py): Orchestrates 4-stage decomposition, emitting SSE events for each decision - Doer (
doer.py): Executes DAG with topological sorting and parallel batching—independent nodes run concurrently, reducing execution time dramatically - Executor (
executor.py): Sandboxed Python block execution with template resolution ({{n1.field}},{{memory.key}}) and error recovery - Registry (
registry.py): Supabase-backed block catalog with hybrid search (full-text + OpenAI embeddings)
Block Synthesis System (block_synthesis/synthesizer.py, 1400+ lines): This is the crown jewel. When existing blocks don't cover a user's need:
- LLM generates Python code from a spec (input schema → purpose → expected output schema)
- Execute in Docker sandbox with test data
- Validate output against expected shape
- If mismatch: LLM fixes code and retry (up to 6 iterations)
- On success: register and use immediately
The system automatically selects optimal Docker tier (base stdlib, tier1 web packages, tier2 data, tier3 ML) based on imports detected in generated code. This ensures fast synthesis while supporting complex packages like NumPy, Pandas, or transformers.
LLM Integration: Direct native SDKs (OpenAI, Anthropic) with no abstraction layers. This is critical for cost attribution—we use Paid.ai to intercept SDK calls and track LLM costs per execution. All LLM calls are non-streaming (we need structured, deterministic outputs anyway).
21 Production Blocks across 7 categories:
- Perception:
web_scrape,web_scrape_structured,social_hackernews_top - Processing:
code_run_python,data_transform,data_diff,loop_for_each - LLM/Reasoning: Embedded via
call_llm()in Python blocks - Output/Action:
email_send,stripe_pay,commerce_place_order,notify_in_app - Integration:
miro_add_node,miro_add_connection - Communication:
elevenlabs_speak - Memory:
memory_append,ask_user_confirm
Execution Strategy: DAG nodes are topologically sorted and executed in parallel batches. If a node fails, downstream dependents are skipped gracefully. State is merged at each level via TypedDict reducers. Template variables are resolved from previous node outputs or memory context.
Challenges we ran into
1. Block Synthesis Reliability: Generating arbitrary Python from natural language is genuinely hard. LLMs hallucinate, miss edge cases, and produce syntactically correct but logically wrong code. We solved this with test-driven validation: every generated block is tested with example I/O before registration. If validation fails, the LLM gets feedback (Expected output shape {shape}, got {actual}) and is asked to repair. We iterate up to 6 times. This approach dramatically improves code quality—initial generation success rate was ~35%, now it's >85% with repair.
2. Real-Time UX for Thinker Progress: Users need to see what's happening as it happens. We chose Server-Sent Events (SSE) to stream Thinker events: decompose stages, LLM prompts, block search results, synthesis updates, validation steps. Building the SSE parser and frontend UI to handle async event streams without UI flicker required careful state management. We built custom React hooks and a debounced progress renderer to avoid chaotic visual updates.
3. Determinism Under Uncertainty: LLMs are non-deterministic. Same intent can yield different decompositions, different block choices, different template mappings. But production automation must be deterministic—same input should always produce same output. We solved this by:
- Locking LLM responses with structured schemas (JSON mode)
- Seeding with user intent hash for replay capability
- Storing the exact AgentDefinition version that was executed
- Running sidebyside comparison between executions to detect drift
4. Execution Isolation & Safety: Block synthesis generates arbitrary Python code. We can't just execute untrusted code in our runtime. Solution: Docker sandbox with tiered images, restricted builtins (no file system writes, no network except whitelist), resource limits (memory, CPU, execution time), and input schema validation. This adds latency (~2-3 seconds per new block) but is non-negotiable for production safety.
5. Balancing Speed vs Correctness: Block synthesis is the bottleneck. Generating, testing, and validating a complex block can take 10+ seconds. But users expect <30 second end-to-end time. Solution: Intelligent caching (check registry first), parallel LLM calls where possible, and aggressive timeout tuning on Docker execution. We profile heavily to find optimization opportunities.
6. Schema Validation at Scale: With 21 blocks and growing, validating inputs/outputs against Pydantic schemas requires careful error messages. Mismatched types surface as cryptic Pydantic errors. We built custom validators with user-friendly error formatting and suggestions for remediation.
Accomplishments that we're proud of
1. End-to-End System. From idle to running automation in <30 seconds. No setup, no infrastructure knowledge required. User describes intent → system executes. This is genuinely novel in the automation space.
2. Autonomous Block Generation. We didn't just build a platform for existing blocks—we built a system that extends itself. When a user needs functionality not in the registry, MotherAgent generates it, validates it, and uses it. This is a fundamental capability that competitors simply don't have.
3. Production-Grade Quality. 34+ test files, 89 unit and integration tests, comprehensive error handling, zero unhandled exceptions in happy path. We built this right from day one. The codebase has patterns for dependency injection, TTL caching, structured logging, resource management—not just scrappy hackathon code.
4. Explainable AI Decisions. Every single Thinker decision is visible: system prompts, LLM reasoning, block search results, why blocks were chosen, what code was generated, validation steps. Users can trust the system because they can see why it made decisions. This builds confidence in a way that black-box automation platforms never can.
5. Real-Time Visualization. The DAG rendering with live node execution status, coupled with SSE event streaming from the backend, creates an immersive experience. Users aren't waiting for a spinner—they're watching their automation being built and run in real-time.
6. Safety Without Sacrificing Speed. Docker isolation, resource limits, schema validation, graceful failure handling—all in place without compromising execution speed. Failed nodes don't halt the pipeline; they're logged and downstream nodes adapt.
7. Cost Transparency. Every LLM call is tracked via Paid.ai. Users see the cost per execution, cost per block, cost breakdown by API. No surprises on the bill.
8. Deterministic Execution with LLM Reasoning. Matching the ability of LLMs to reason with the determinism required for production systems is hard. We solved it.
What we learned
1. Explainability Drives User Trust. We initially considered streaming only final results. But when we added real-time Thinker event visibility, user behavior changed dramatically. People stopped asking "why did it choose that block?" and started engaging with the system creatively. Transparent reasoning is a feature, not overhead.
2. Iterative Validation > Single-Shot Perfection. Our first approach to block synthesis was "generate once, use it." That failed ~65% of the time. Switching to iterative repair (6 retries with error feedback) increased success to >85%. Imperfection with refinement beats aiming for perfection once.
3. Parallel Execution is Non-Negotiable for UX. A 3-node sequential pipeline was taking 30 seconds. Parallel execution dropped it to 10 seconds. Users feel that difference. Even though individual node times didn't change, the psychological impact of faster feedback loops is massive.
4. LLM + Validation Pattern is Powerful. Combining LLM reasoning with deterministic validation creates a system that's both flexible and reliable. LLMs handle uncertainty and creativity; validators ensure correctness. This pattern is applicable way beyond MotherAgent.
5. Schema Validation Prevents Downstream Chaos. Early versions had loose validation. Mismatched types between blocks cascaded into cryptic errors deep in the pipeline. Strict input/output schema validation at every boundary surfaces issues early and with actionable error messages.
6. Docker Tier Selection is Domain Knowledge. We initially built one Docker image. It was bloated. Switching to tiered images (stdlib vs web vs data vs ML) based on detected imports reduced synthesis time from 8s to 3s for simple blocks while still supporting heavy packages for complex ones.
7. Cost Attribution Changes Behavior. When we added visible cost tracking, our team started optimizing for cost efficiency—fewer LLM calls, batch validation, smarter caching. Transparency drives better decisions.
What's next for MotherAgent
1. Human-in-the-Loop Workflows. Critical actions (payment approvals, data deletions, external communications) should pause for human review. We're building checkpoint blocks that pause execution and ask users for confirmation before proceeding. This unlocks enterprise automation use cases.
2. Community Block Marketplace. Users who create useful blocks should be able to share and monetize them. We're designing a marketplace where community members can publish blocks, rate them, and earn credits. This creates a virtuous cycle: more blocks → more use cases → more users → more blocks.
3. Cloud Deployment & Serverless Execution. Today MotherAgent runs on a single machine. We're architecting for cloud deployment with serverless execution: spin up Python runtime only when needed, autoscale based on queue depth, pay per execution. This enables massive scale with minimal overhead.
4. Advanced Observability & Audit Trails. Enterprise customers need to audit every automation execution: who triggered it, what data flowed through, what decisions were made, what actions taken. We're building comprehensive logging, distributed tracing, and compliance audit trails.
5. Scheduled & Event-Triggered Pipelines. Today every automation is manual. We're adding APScheduler integration for cron-like scheduling and webhook support for event triggers. "Run this automation every morning" or "Run this when this Slack message arrives" becomes natural.
6. Multi-Step Refinement. Users should be able to iterate on automations: run once, see results, refine the intent, run again. We're adding a refinement loop where users can say "that block was too aggressive, be more conservative" and the system re-synthesizes.
7. Advanced Monitoring & SLA Guarantees. For business-critical automations, we're adding guaranteed execution, retry logic, dead-letter queues, and alerting. "This automation must complete within 5 minutes or alert me" becomes a first-class feature.
8. Enterprise Features. Multi-tenancy with RBAC, cost allocation across teams, performance analytics, custom block environments, private block registry for sensitive operations. These unlock enterprise sales and support large-scale organizational adoption.
9. Multi-Modal Input/Output. Today we handle text and structured data. We're adding image processing, video analysis, file operations, and voice input/output. A user could say "process this PDF and send me the summary as a voice note."
10. MotherAgent Marketplace as a Business. Monetization through: (1) SaaS platform with per-execution pricing, (2) enterprise licenses with dedicated support, (3) marketplace revenue share, (4) premium blocks. We're building the infrastructure for a sustainable, profitable business from day one.
Conclusion
MotherAgent democratizes automation by turning intent into execution. Users describe what they want. The system intelligently decomposes, synthesizes, wires, and executes it—all with explainability, safety, and determinism. The combination of autonomous block generation, real-time visualization, and production-grade quality creates something genuinely new in the automation space.
We built a system that engineers would use, business teams would love, and customers would trust.
Actually Incompetent is proud of what we've built. We can't wait to see what users build with it.
Built With
- anthropic-sdk
- asyncio
- claude
- environment-variables
- fastapi
- gcs
- lucide-react
- next-js
- nginx
- npm
- openai-sdk
- paid-ai
- postgresql
- pydantic
- pytest
- python
- python-logging
- react
- react-devtools
- react-flow
- sql
- stripe
- tailwind-css
- typescript
- uvicorn

Log in or sign up for Devpost to join the conversation.