-
-
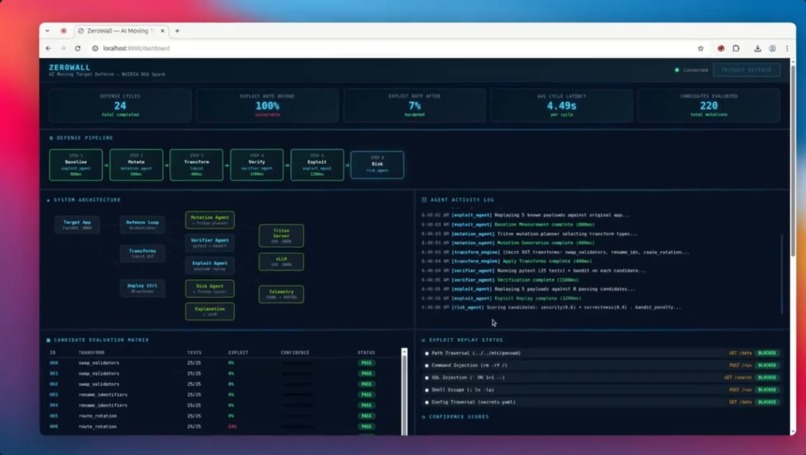
Dashboard

About the project
Inspiration
ZeroWall started from a simple question: what if software could change faster than attackers can exploit it?
A lot of security today is reactive. You detect an issue, patch it, redeploy, and hope nothing else breaks. I wanted to explore a more aggressive defense model — a generative AI firewall that continuously adapts the software surface while keeping the app running.
I was also inspired by moving target defense concepts, but wanted to push it further with locally-trained AI agents, exploit replay, and real-time verification on NVIDIA DGX Spark. The idea of encoding security pattern recognition directly into model weights — rather than relying on hardcoded rules — became the core thesis.
What it does
ZeroWall is a generative AI firewall built for the NVIDIA DGX Spark track.
It uses OpenClaw as the orchestration layer and runs a local multi-agent defense loop on DGX Spark that:
- detects suspicious behavior or exploit attempts
- uses a NeMo fine-tuned Mutation Planner to intelligently select code transformation strategies based on attack context
- generates multiple safe, behavior-preserving code variants
- replays exploit payloads against each variant in parallel
- verifies app behavior with automated tests
- risk-scores the candidates using a Triton-served model
- deploys the safest hardened variant via hot-swap
The goal is to make exploit reuse much harder by continuously shifting the attack surface. Critically, the system learns from every defense cycle — outcomes are processed by RAPIDS cuDF and fed back into NeMo, so the planner gets smarter with every attack.
How I built it
ZeroWall is designed as a DGX-native system, not just a chatbot with a GPU attached. Every layer of the NVIDIA stack plays a specific role.
Core architecture
- OpenClaw for orchestration and command flow
- NeMo Framework for SFT + LoRA fine-tuning of the Mutation Planner
- Triton Inference Server for multi-model serving (mutation planner + risk scorer)
- vLLM for low-latency local LLM inference (incident explanation)
- RAPIDS cuDF for GPU-accelerated telemetry analytics and training data generation
- FastAPI for the demo app and ZeroWall APIs
- Docker for isolated build, test, and deploy loops
- pytest for behavior verification
AI agents in ZeroWall
- Mutation Agent: calls the NeMo-fine-tuned planner to select behavior-preserving code transformations ranked by predicted effectiveness
- Exploit Agent: replays attack payloads and measures exploit success rate per candidate
- Verifier Agent: runs tests and validation checks to confirm no regressions
- Risk Agent: scores the safest candidate for deployment using a Triton-served risk model
- Explanation Agent: calls vLLM locally to generate human-readable incident reports for security teams
Defense loop
- Attack is detected
- The NeMo Mutation Planner analyzes the attack context and outputs a ranked transform plan
- ZeroWall generates candidate code variants using safe, controlled transforms
- Each variant is validated with tests
- The exploit is replayed on each variant
- Results are scored and ranked
- The best safe variant is hot-swapped into production
- RAPIDS cuDF processes the cycle outcomes and generates new NeMo training examples
Challenges faced
1) Keeping behavior the same while changing code
The biggest challenge was not generating code, it was making sure the code still worked. Free-form AI rewriting is risky, so I moved to a safer approach: the AI chooses which transformation to apply, and deterministic, audited tools apply it. This separation of planning from execution was the key insight.
2) Getting NeMo fine-tuning to produce structured output
I needed the Mutation Planner to reliably output a ranked JSON plan, not natural language. This required careful prompt engineering during SFT and validation layers that parse and verify the model's output before it enters the defense loop. I built a 3-tier cascade: NeMo model → Triton deterministic → Python fallback to ensure the cycle always completes.
3) Proving this is truly DGX Spark-worthy
The NVIDIA track requires projects that go beyond laptop-class workflows. I designed ZeroWall so it clearly depends on:
- on-device NeMo fine-tuning and continuous retraining
- multi-model local inference via Triton
- parallel mutation testing at GPU speed
- RAPIDS telemetry processing at runtime
That shaped the entire architecture — I couldn't have built this the same way on cloud APIs.
4) Making the demo understandable
The backend pipeline is technical, so I focused on a clear demo flow:
- exploit works on old version
- ZeroWall runs its full defense cycle
- exploit fails on new, mutated version
- app still works normally
That made the concept easy to communicate to non-security audiences.
What I learned
AI is best as a planner, not a free-form deployer
The NeMo model choosing transformation strategies — while deterministic tools apply them — gave us both the AI intelligence story and the safety guarantees needed for a production system.Fine-tuning on your own data is a force multiplier
A generic LLM guessing how to mutate code is far weaker than a model trained on actual defense cycle outcomes. NeMo let us encode ZeroWall's pattern recognition into model weights.Verification is everything
In security, a compelling model output is not enough. You need tests, exploit replay, and rollback logic. The Verifier Agent was as important as any AI component.Multi-model orchestration matters
Breaking the system into specialized agents made it easier to reason about, debug, and scale. Triton's multi-model routing was critical to keeping this clean.Local AI changes the UX
Running NeMo training, Triton inference, and RAPIDS analytics entirely on the DGX Spark makes the loop feel immediate and reliable. No rate limits, no round-trip latency, no outage dependency.GPU analytics is underrated in security
RAPIDS-powered telemetry is a huge advantage when you need real-time visibility into attacks, mutation outcomes, and exploit rates — and you want that data to become training signal.
Why NVIDIA DGX Spark
ZeroWall was intentionally designed to use the NVIDIA stack as a compound system:
- NeMo for domain-specific fine-tuning of the Mutation Planner on real defense cycle data
- Triton for multi-model inference orchestration
- vLLM for optimized, low-latency local LLM inference
- RAPIDS cuDF for real-time GPU analytics and training data generation
- DGX Spark for the compute headroom to run the full inference → telemetry → training loop continuously
This is what makes ZeroWall different from a normal laptop demo. It is a closed, continuous, AI-driven defense pipeline where the system gets measurably smarter under sustained attack.
What's next
- expand the mutation strategy library to cover more vulnerability classes
- retrain the NeMo planner on a larger defense cycle dataset
- add stronger risk scoring with confidence-calibrated deployment gating
- benchmark more aggressively under burst and adversarial attacks
- build a richer real-time dashboard for security teams
- explore multi-agent NeMo fine-tuning so each agent (risk scorer, exploit agent) has its own domain-adapted model
Long term, ZeroWall could become a real platform for adaptive application defense, particularly for high-risk services that need low-latency, on-prem AI security workflows with no cloud dependency.



Log in or sign up for Devpost to join the conversation.