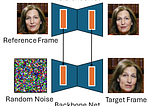
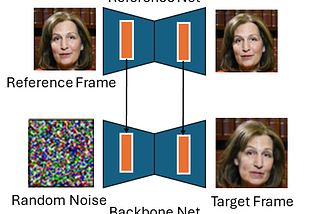
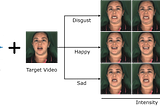
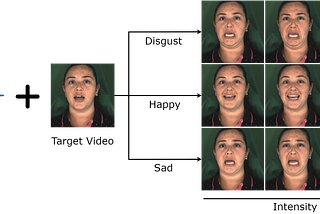Published inTowards AITowards Streaming Video Diffusion2026 will be the year of real-time video generationDec 23, 2025A response icon1Dec 23, 2025A response icon1
Published inTowards AIWhat I Learned by Building an AI-Driven NewsletterOne of the hardest parts of being a researcher in the current world of AI is keeping up with the insane volume of new work that seems to…Aug 18, 2025A response icon1Aug 18, 2025A response icon1
Avatars and the EU AI ActThe EU has announced a series of regulations for AI companies; how will this affect lip-sync/avatar/deepfake providers?Oct 29, 2024Oct 29, 2024
Breaking Down Synthesia 2.0We take a look at the tech that's underpinning the impressive new launch.Jun 24, 2024Jun 24, 2024
Published inTDS ArchiveScale Is All You Need for Lip-Sync?Alibaba’s EMO and Microsoft’s VASA-1 are crazy good. Let’s break down how they work.Jun 7, 2024Jun 7, 2024
The Definitive Guide to Lip Sync CompaniesThere are now so many lip-sync/AI Avatar/ Talking Face Generation Companies. Who is who?May 25, 2024A response icon2May 25, 2024A response icon2
Published inTDS ArchiveGaussian Head Avatars: A SummaryThere has been a recent explosion of Gaussian Splatting papers and the avatar space is no exception. How do they work and are they going to…Dec 19, 2023Dec 19, 2023
Published inTowards AIREAD Avatars: Realistic Emotion-controllable Audio Driven AvatarsAdding Emotional Control to Audio-Driven DeepfakesAug 25, 2023Aug 25, 2023
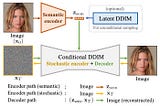
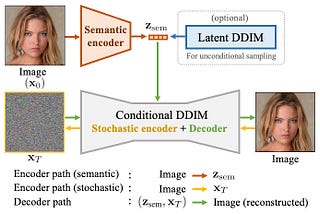
Published inTowards AIDAE Talking: High Fidelity Speech-Driven Talking Face Generation with Diffusion AutoencoderDiffusion Models + Lots of Data = Practically Perfect Talking Head GenerationJul 14, 2023Jul 14, 2023
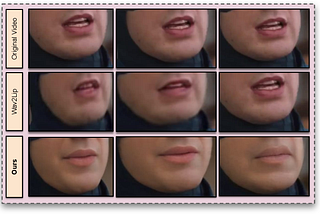
Published inTowards AITowards Generating Ultra-High Resolution Talking-Face Videos with Lip-SynchronizationThe holy grail of deepfake models is the person-generic model. So far no person-generic model has been of high visualquality, this paper is.May 27, 2023May 27, 2023