Was ist Robots.txt? | Wie eine Robots.txt-Datei funktioniert
Eine robots.txt-Datei listet die Präferenzen einer Website für das Bot-Verhalten auf. Es informiert Bots darüber, auf welche Webseiten sie zugreifen dürfen und auf welche nicht. Robots.txt-Dateien sind für Webcrawler am relevantesten.
Lernziele
Nach Lektüre dieses Artikels können Sie Folgendes:
- Erklären, was eine robots.txt-Datei ist
- Wie interagieren Bots mit einer robots.txt-Datei
- Die in einer robots.txt-Datei verwendeten Protokolle, einschließlich des Robots Exclusion Protocol und der Sitemaps
Ähnliche Inhalte
Bot-Management
Vertrauenswürdige Bots vs. schädliche Bots
Verwaltung vertrauenswürdiger Bots
Spam-Bots
Was ist ein Bot?
Möchten Sie noch mehr erfahren?
Abonnieren Sie theNET, Cloudflares monatliche Zusammenfassung der beliebtesten Einblicke in das Internet!
Link zum Artikel kopieren
Schützen Sie sich mit Cloudflare vor Bot-Angriffen wie Credential Stuffing und Content Scraping
Was ist robots.txt?

Eine robots.txt-Datei ist eine Reihe von Richtlinien für Bots. Diese Datei ist in den Quelldateien der meisten Websites enthalten. Robots.txt-Dateien sind für die Verwaltung der Aktivitäten von Bots wie Webcrawlern gedacht, obwohl nicht alle Bots die Anweisungen befolgen.
Stellen Sie sich eine robots.txt-Datei als einen „Verhaltenskodex“-Aushang vor, der in einem Fitnessstudio, einer Bar oder einem Gemeindezentrum an der Wand angebracht ist: Der Aushang selbst hat keine Befugnis, die aufgeführten Regeln durchzusetzen, aber „gute“ Besucher werden die Regeln befolgen, während „schlechte“ Besucher die Regeln wahrscheinlich brechen, so dass sie ausgeschlossen werden müssen.
Ein Bot ist ein automatisiertes Computerprogramm, das mit Websites und Anwendungen interagiert. Eine Art von Bot wird als Webcrawler-Bot bezeichnet. Diese Bots „crawlen“ Webseiten und indizieren den Inhalt, damit er in Suchmaschinenergebnissen angezeigt wird. Eine robots.txt-Datei hilft bei der Verwaltung der Aktivitäten dieser Webcrawler, damit sie den Webserver, auf dem sich die Website befindet, oder Indexseiten, die nicht für die öffentliche Ansicht bestimmt sind, nicht überfordern. Eine robots.txt-Datei kann auch dabei helfen, die Aktivitäten von KI-Crawler-Bots zu verwalten, die Webserver manchmal weitaus stärker beanspruchen als herkömmliche Webcrawler-Bots.
Wie funktioniert eine robots.txt-Datei?
Eine robots.txt-Datei ist nur eine Textdatei ohne HTML-Markup-Code (daher die Erweiterung .txt). Die robots.txt-Datei wird wie jede andere Datei auf der Website auf dem Webserver gehostet. Man kann sich die robots.txt-Datei für eine bestimmte Website normalerweise anzeigen lassen, indem man die vollständige URL für die Startseite eingibt und anschließend /robots.txt hinzufügt, z. B. https://www.cloudflare.com/robots.txt. Die Datei ist mit keiner anderen Stelle auf der Site verknüpft, sodass Benutzer normalerweise nicht darauf stoßen werden, aber die meisten Webcrawler-Bots suchen als erstes nach dieser Datei, bevor sie den Rest der Site crawlen.
Obwohl eine robots.txt-Datei Anweisungen für Bots bereitstellt, kann sie diese Anweisungen nicht tatsächlich durchsetzen. Einige Bots, wie z. B. Webcrawler oder Newsfeed-Bots, versuchen möglicherweise, zuerst die robots.txt-Datei aufzurufen, bevor sie andere Seiten einer Domain anzeigen, und folgen möglicherweise den Anweisungen. Andere Bots ignorieren entweder die robots.txt-Datei oder verarbeiten sie, um die Webseiten zu finden, die verboten sind.
Ein Webcrawler-Bot, der mit der robots.txt konform ist, folgt den spezifischsten Anweisungen in der robots.txt Datei. Wenn die Datei widersprüchliche Befehle enthält, folgt der Bot dem detaillierteren Befehl.
Wichtig ist, dass alle Subdomains eine eigene robots.txt-Datei benötigen. So verfügt beispielsweise www.cloudflare.com über eine eigene Datei, aber alle Cloudflare-Subdomains (blog.cloudflare.com, community.cloudflare.com usw.) benötigen ebenfalls eine eigene Datei.
Welche Protokolle werden in einer robots.txt-Datei verwendet?
In Networking ist ein Protokoll ein Format zum Bereitstellen von Anweisungen oder Befehlen. Robots.txt-Dateien verwenden verschiedene Protokolle. Das Hauptprotokoll heißt Robots Exclusion Protocol. Mit diesem Protokoll können Sie Bots mitteilen, welche Webseiten und Ressourcen vermieden werden sollen. Anweisungen, die für dieses Protokoll formatiert wurden, sind in der Datei robots.txt enthalten.
Das andere Protokoll, das für robots.txt-Dateien verwendet wird, ist das Sitemaps-Protokoll. Man kann es als Robotereinschlussprotokoll betrachten. Sitemaps zeigen einem Webcrawler, welche Seiten gecrawlt werden können. Dadurch stellen sie sicher, dass ein Crawler-Bot keine wichtigen Seiten übersieht.
Beispiel einer robots.txt-Datei
Hier ist eine alte Version der robots.txt-Datei für www.cloudflare.com:
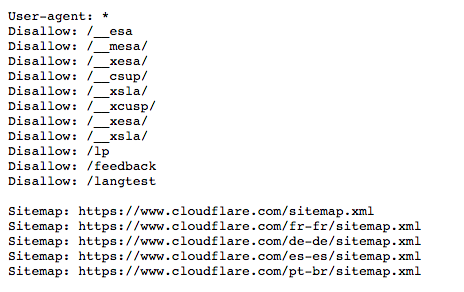
Nachfolgend erklären wir, was die einzelnen Elemente bedeuten.
Was ist ein User Agent? Was bedeutet „User-Agent: *“?
Alle Personen oder Programme, die im Internet aktiv sind haben einen „User Agent“ oder einen zugewiesenen Namen. Für menschliche Benutzer umfasst dies Informationen wie den Browsertyp und die Betriebssystemversion, jedoch keine personenbezogenen Informationen. Es hilft Websites dabei, Inhalte anzuzeigen, die mit dem System des Benutzers kompatibel sind. Bei Bots hilft der User Agent den Website-Administratoren (theoretisch), zu erkennen, welche Art von Bots die Website crawlen.
In einer robots.txt-Datei können Website-Administratoren bestimmte Anweisungen für bestimmte Bots bereitstellen, indem sie unterschiedliche Anweisungen für Bot-User-Agents schreiben. Wenn ein Administrator beispielsweise möchte, dass eine bestimmte Seite in den Google-Suchergebnissen angezeigt wird, jedoch nicht in der Bing-Suche, kann er zwei Befehlssätze in die robots.txt-Datei aufnehmen: einen Satz beginnend mit „User-agent: Bingbot“ und einen Satz beginnend mit „User-agent: Googlebot“.
Im obigen Beispiel hat Cloudflare „User-agent: *“ in die robots.txt-Datei aufgenommen. Das Sternchen steht für einen „Platzhalter-“-User-Agent. Das heißt, dass die Anweisungen für jeden Bot gelten, nicht nur für einen bestimmten Bot.
Häufige Namen von Suchmaschinen-Bot-User-Agents sind:
Google:
- Googlebot
- Googlebot-Image (für Bilder)
- Googlebot-News (für Nachrichten)
- Googlebot-Video (für Videos)
Bing
- Bingbot
- MSNBot-Media (für Bilder und Videos)
Baidu
- Baiduspider
Wie funktionieren „Disallow“-Befehle in einer robots.txt-Datei?
Der Befehl „Disallow“ ist der gebräuchlichste im Robots Exclusion Protocol. Es weist Bots an, nicht auf die Webseite oder eine Reihe von Webseiten zuzugreifen, die nach dem Befehl folgen. Nicht erlaubte Seiten sind nicht unbedingt „versteckt“ – sie sind einfach für den durchschnittlichen Google- oder Bing-Nutzer nicht nützlich und werden ihnen daher nicht angezeigt. Wenn ein Benutzer weiß, wo man diese Seiten findet, kann er meistens immer noch zu diesen Seiten navigieren.
Der „Disallow“-Befehl kann auf verschiedene Arten verwendet werden. Oben werden einige davon angezeigt.
Eine Datei blockieren (mit anderen Worten eine bestimmte Webseite)
Würde Cloudflare beispielsweise verhindern wollen, dass Bots unseren „Was ist ein Bot?“-Artikel crawlen, würde der Befehl wie folgt aussehen:
Disallow: /learning/bots/what-is-a-bot/Nach dem „Disallow“-Befehl folgt der Teil der Webseiten-URL, der nach der Homepage kommt – in diesem Fall „www.cloudflare.com“. Mit diesem Befehl werden Bots, die den Anweisungen in der robots.txt folgen, nicht auf https://www.cloudflare.com/learning/bots/what-is-a-bot/ zugreifen, und die Seite wird daher wahrscheinlich nicht in den Ergebnissen traditioneller Suchmaschinen angezeigt.
Ein Verzeichnis blockieren
Manchmal ist es effizienter, mehrere Seiten gleichzeitig zu blockieren, anstatt sie alle einzeln aufzulisten. Wenn sich alle im selben Bereich der Website befinden, kann eine robots.txt-Datei einfach das Verzeichnis blockieren, in dem sie enthalten sind.
Ein Beispiel von oben ist:
Disallow: /__mesa/Das bedeutet, dass alle im __mesa-Verzeichnis enthaltenen Seiten nicht gecrawlt werden sollten.
Vollzugriff zulassen
Ein solcher Befehl würde wie folgt aussehen:
Disallow:Dies teilt Bots mit, dass sie die gesamte Website durchsuchen können, da kein Teil davon unzulässig ist.
Die gesamte Website vor Bots verstecken
Disallow: /Die „/“ stellt hier die „Wurzel“ (root) in einer Hierarchie der Website oder die Seite dar. Von ihr aus verzweigen alle anderen Seiten, sodass sie die Homepage und alle von ihr aus verknüpften Seiten enthält. Mit diesem Befehl können Suchmaschinen-Bots die Website möglicherweise überhaupt nicht crawlen.
Welche anderen Befehle gehören zum Robots Exclusion Protocol?
Allow: Wie zu erwarten, teilt der Befehl „Allow“ Bots mit, dass sie auf eine bestimmte Webseite oder ein bestimmtes Verzeichnis zugreifen dürfen. Dieser Befehl gibt die Präferenz der Website an, Bots zu erlauben, eine bestimmte Webseite zu erreichen, während der Rest der Webseiten in der Datei nicht zugelassen wird. Nicht alle Suchmaschinen erkennen diesen Befehl.
Crawling-Verzögerung: Der Crawling-Verzögerungsbefehl soll verhindern, dass Suchmaschinen-Spider-Bots einen Server überfordern. Hier können Administratoren angeben, wie viele Millisekunden der Bot zwischen den einzelnen Anfragen warten soll. Hier ist ein Beispiel für einen Crawling-Verzögerungsbefehl zum Warten von acht Millisekunden:
Crawl-delay: 8Während andere Suchmaschinen diesen Befehl meist akzeptieren, ignoriert Google ihn. In der Google Search Console können Seitenbetreiber jedoch die Häufigkeit des Crawlens für Google einstellen.
Was ist das Sitemaps-Protokoll? Warum ist es in robots.txt enthalten?
Das Sitemaps-Protokoll hilft Bots zu wissen, was sie beim Crawlen einer Website berücksichtigen sollen.
Eine Sitemap ist eine XML-Datei, die folgendermaßen aussieht:
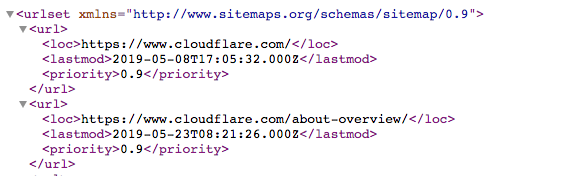
Es ist eine maschinenlesbare Liste aller Seiten einer Website. Über das Sitemaps-Protokoll können Links zu diesen Sitemaps in die Datei robots.txt aufgenommen werden. Das Format lautet: „Sitemaps:“ gefolgt von der Webadresse der XML-Datei. In der obigen Datei Cloudflare robots.txt sehen Sie mehrere Beispiele.
Während das Sitemaps-Protokoll sicherstellt, dass Web-Spider-Bots beim Crawlen einer Website nichts verpassen, folgen die Bots dennoch ihrem typischen Crawling-Prozess. Sitemaps zwingen Crawler-Bots nicht dazu, Webseiten anders zu priorisieren.
In welcher Beziehung steht robots.txt zum Bot-Management?
Bots-Management ist wichtig, um eine Website oder Anwendung am Laufen zu halten. Denn selbst eine gute Bot-Aktivität kann einen Ursprungsserver überfordern und eine Website verlangsamen oder zum Abstürzen bringen. Eine gut aufgebaute robots.txt-Datei sorgt dafür, dass eine Website für SEO optimiert bleibt und behält gutartiges Bot-Verhalten unter Kontrolle. Zur Handhabung böswilligen Bot-Traffics kann eine robots.txt-Datei nicht viel ausrichten.
Trotz der Bedeutung von robots.txt stellte Cloudflare im Jahr 2025 fest, dass nur 37 % seiner Top-10.000-Websites überhaupt eine robots.txt-Datei hatten. Das bedeutet, dass ein großer Prozentsatz, vielleicht sogar die Mehrheit der Websites, dieses Tool nicht verwendet. Um diesen Websites zu helfen, insbesondere solchen, die nicht möchten, dass ihre Originalinhalte für das KI-Training verwendet werden, bietet Cloudflare „verwaltetes robots.txt“ an. Dies ist ein Dienst, der im Auftrag einer Website die robots.txt-Datei mit den gewünschten Einstellungen erstellt oder aktualisiert. Erfahren Sie mehr über verwaltete robots.txt-Dateien.
Robots.txt Easter Eggs
Gelegentlich enthält eine robots.txt-Datei auch ein Easter Egg – witzige Nachrichten, die die Entwickler aufgenommen haben, weil sie wissen, dass Benutzer diese Dateien selten zu sehen kriegen. Zum Beispiel steht in der YouTube robots.txt-Datei: „Created in the distant future (the year 2000) after the robotic uprising of the mid 90's which wiped out all humans.“ Die Cloudflare robots.txt-Datei bittet: „Dear robot, be nice.“
# .__________________________.
# | .___________________. |==|
# | | ................. | | |
# | | ::[ Dear robot ]: | | |
# | | ::::[ be nice ]:: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | ,|
# | !___________________! |(c|
# !_______________________!__!
# / \
# / [][][][][][][][][][][][][] \
# / [][][][][][][][][][][][][][] \
#( [][][][][____________][][][][] )
# \ ------------------------------ /
# \______________________________/
Google hat übrigens eine „humans.txt“-Datei unter: https://www.google.com/humans.txt
FAQs
Was ist eine Datei robots.txt?
Eine robots.txt-Datei ist eine Liste der Präferenzen einer Website für das Bot-Verhalten, die sich in den Quelldateien der Website befindet. Sie bietet guten Bots, wie Suchmaschinen-Webcrawlern, Anweisungen dazu, auf welche Teile einer Website sie zugreifen dürfen und welche sie vermeiden sollten, um den Traffic zu verwalten und die Indizierung zu kontrollieren. Sie kann auch Regeln für KI-Crawler auflisten.
Was ist ein Webcrawler?
Ein Webcrawler ist ein automatisierter Bot, der Webseiten für Suchmaschinen besucht und indexiert, um Benutzern zu helfen, Inhalte über Suchergebnisse zu finden.
Was ist das Robots Exclusion Protocol?
Das Robots Exclusion Protocol ist das Format für Anweisungen in einer robots.txt-Datei. Das Protokoll teilt Webcrawlern mit, welche Webseiten oder Ressourcen sie auf einer Website nicht aufrufen oder durchsuchen sollen.
Was bedeutet „User-agent“ in einer robots.txt-Datei?
„User-agent“ gibt an, für welchen Bot oder welche Gruppe von Bots eine Anweisung in einer robots.txt-Datei gilt. „User-agent: *“ bedeutet, dass die Regel für alle Bots gilt.
Was ist der Befehl „Disallow“ in robots.txt?
Der „Disallow“-Befehl teilt Bots mit, dass sie bestimmte Seiten oder Verzeichnisse auf einer Website nicht crawlen sollen. Zum Beispiel weist „Disallow: /private/“ Bots an, nicht auf das Verzeichnis „private“ zuzugreifen.
Was ist das Sitemaps-Protokoll in robots.txt?
Das Sitemaps-Protokoll ermöglicht es Website-Besitzern, Links zu ihren Sitemap-XML-Dateien in der robots.txt-Datei aufzunehmen. So hilft es Bots dabei, zu erkennen, welche Seiten gecrawlt werden sollten.
Was ist der Unterschied zwischen vertrauenswürdigen und schädlichen Bots?
Gute Bots folgen mit größerer Wahrscheinlichkeit den Anweisungen aus robots.txt und leisten auch hilfreiche Dienste. Suchmaschinen-Webcrawler befolgen in der Regel die robots.txt-Regeln, wenn sie Inhalte für die Suche indexieren. Schädliche Bots ignorieren oft die robots.txt-Datei und können Inhalte scrapen, Websites angreifen oder übermäßige Anfragen senden, die die Kosten für die Website in die Höhe treiben.
Was bewirkt der Crawl-Delay-Befehl in der robots.txt-Datei?
Der Crawl-Delay-Befehl teilt Bots mit, wie lange sie zwischen den Anfragen warten sollen, um eine Überlastung des Servers zu vermeiden. Nicht alle Bots respektieren diesen Befehl: Googlebot tut dies zum Beispiel nicht, obwohl Google es Website-Administratoren erlaubt, eine ähnliche Regel über die Google Search Console festzulegen.
Wie wirkt sich robots.txt auf die SEO-Optimierung aus?
Eine gut konstruierte robots.txt-Datei kann die SEO verbessern, indem sie Suchmaschinen-Crawler-Bots mitteilt, welche Seiten indexiert werden sollen, was dazu beitragen sollte, die Indizierung von nicht wesentlichen oder doppelten Inhalten zu verhindern. Zusätzlich kann die robots.txt Webcrawlern helfen, alle Seiten zu finden, die sie über Sitemaps indexieren sollen.