O que é robots.txt? | Como funciona um arquivo robots.txt
Um arquivo robots.txt lista as preferências de um site para o comportamento dos bots. Ele informa aos bots quais páginas web eles devem ou não acessar. Os arquivos robots.txt são mais relevantes para web crawlers.
Objetivos de aprendizado
Após ler este artigo, você será capaz de:
- Saiba o que é um arquivo robots.txt
- Entenda como os bots interagem com um arquivo robots.txt
- Explore os protocolos usados em um arquivo robots.txt, incluindo o Protocolo de Exclusão de Robôs e o Sitemaps
Conteúdo relacionado
Quer saber mais?
Assine o theNET, uma recapitulação mensal feita pela Cloudflare dos insights mais populares da internet.
Copiar o link do artigo
Defenda-se contra ataques de bots, como preenchimento de credenciais e raspagem de conteúdo, com a Cloudflare
O que é Robots.txt?

Um arquivo robots.txt é um conjunto de diretrizes para bots. Este arquivo está incluído nos arquivos de origem da maioria dos sites. Os arquivos robots.txt destinam-se à gestão das atividades de bots, como web crawlers, embora nem todos os bots sigam as instruções.
Pense em um arquivo robots.txt como se fosse um aviso de "Código de Conduta" afixado na parede de uma academia, de um bar ou de um centro comunitário: o aviso em si não tem poder para fazer cumprir as regras listadas, mas os usuários "bons" seguirão as regras, enquanto os "ruins" provavelmente as quebrarão e serão banidos.
Um bot é um programa de computador automatizado que interage com sites e aplicativos. Um tipo de bot é chamado de web crawler. Esses bots "rastreiam" páginas web e indexam o conteúdo para que ele possa aparecer nos resultados dos mecanismos de busca. Um arquivo robots.txt ajuda a controlar as atividades desses web crawlers para que eles não sobrecarreguem o servidor web que hospeda o site, nem indexem páginas que não são destinadas à visualização pública. Um arquivo robots.txt também pode ajudar a gerenciar as atividades de crawlers de IA, que às vezes podem exigir muito mais dos servidores web do que os web crawlers tradicionais.
Como funciona um arquivo robots.txt?
Um arquivo robots.txt é apenas um arquivo de texto sem código de marcação HTML (daí a extensão .txt). O arquivo robots.txt é hospedado no servidor web como qualquer outro arquivo no site. De fato, o arquivo robots.txt de qualquer site normalmente pode ser visualizado digitando-se a URL completa da página inicial e depois adicionando-se /robots.txt, como https://www.cloudflare.com/robots.txt. O arquivo não está vinculado a nenhum outro lugar no site, portanto os usuários provavelmente não tropeçarão nele, mas a maioria dos bots do tipo web crawler procurarão por esse arquivo primeiro antes de rastrear o resto do site.
Embora um arquivo robots.txt forneça instruções para bots, ele não pode realmente fazer com que as instruções sejam cumpridas. Alguns bots, como web crawlers ou bots de feeds de notícias, podem tentar acessar primeiro o arquivo robots.txt antes de visualizar qualquer outra página em um domínio, e podem seguir as instruções. Outros bots podem ignorar o arquivo robots.txt ou processá-lo para encontrar as páginas da web que são proibidas.
Um web crawler que esteja em conformidade com o robots.txt seguirá o conjunto mais específico de instruções contidas no arquivo robots.txt. Se houver comandos contraditórios no arquivo, o bot seguirá o comando mais granular.
Uma coisa importante a ser observada é que todos os subdomínios precisam do seu próprio arquivo robots.txt. Por exemplo, embora www.cloudflare.com tenha seu próprio arquivo, todos os subdomínios da Cloudflare (blog.cloudflare.com, community.cloudflare.com, etc.) também precisam ter seu próprio arquivo.
Quais protocolos são usados em um arquivo robots.txt?
Em rede, um protocolo é um formato usado para fornecer instruções ou comandos. Os arquivos robots.txt utilizam alguns protocolos diferentes. O protocolo principal é chamado de Protocolo de Exclusão de Robôs. Trata-se de uma forma de dizer aos robôs quais páginas e recursos devem ser evitados. As instruções formatadas para este protocolo estão incluídas no arquivo robots.txt.
Outro protocolo usado para arquivos robots.txt é o protocolo Sitemaps, que pode ser considerado um protocolo de inclusão de robôs. O Sitemaps mostra a um web crawler quais páginas ele pode rastrear. Isso ajuda a garantir que um bot crawler não ignore uma página importante.
Exemplo de um arquivo robots.txt
Aqui está uma versão antiga do arquivo robots.txt para www.cloudflare.com:
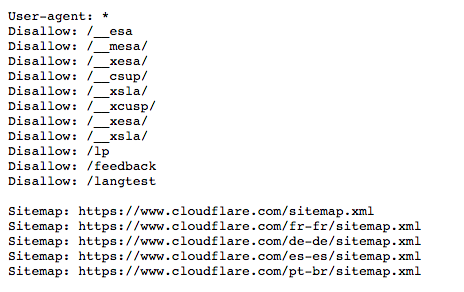
Abaixo detalhamos o que tudo isso significa.
O que é um agente de usuário? O que significa '"agente-usuário: *"?
Qualquer pessoa ou programa ativo na internet terá um "agente de usuário", ou um nome atribuído. Para usuários humanos, isso inclui informações como o tipo de navegador e a versão do sistema operacional, mas não inclui nenhuma informação pessoal, e ajuda os sites a exibirem conteúdo compatível com o sistema do usuário. Para os bots, o agente de usuário (teoricamente) ajuda os administradores do site a saberem que tipo de bots estão rastreando o site.
Em um arquivo robots.txt, os administradores do site podem fornecer instruções específicas para bots específicos, escrevendo instruções diferentes para o bot agentes de usuário. Por exemplo, se um administrador quiser que uma determinada página seja exibida nos resultados de pesquisa do Google, mas não nas pesquisas do Bing, eles poderiam incluir dois conjuntos de comandos no arquivo robots.txt: um conjunto precedido por "User-agent: Bingbot" e um conjunto precedido por "User-agent: Googlebot".
No exemplo acima, a Cloudflare incluiu "User-agent: *" no arquivo robots.txt. O asterisco representa um agente de usuário "curinga" e significa que as instruções se aplicam a todos os bots, não a um bot específico.
Os nomes mais comuns de bots de agentes usuário para mecanismos de pesquisa incluem:
Google:
- Googlebot
- Googlebot-Image (para imagens)
- Googlebot-News (para notícias)
- Googlebot-Video (para vídeos)
Bing
- Bingbot
- MSNBot-Media (para imagens e vídeo)
Baidu
- Baiduspider
Como funcionam os comandos "Disallow" em um arquivo robots.txt?
O comando Disallow é o mais comum no protocolo de exclusão de robôs. Ele instrui os bots a não acessarem a página web ou o conjunto de páginas web que seguem o comando. Páginas não permitidas não estão necessariamente "escondidas", elas simplesmente não são úteis para o usuário médio do Google ou do Bing, então não são mostradas a eles. Na maioria das vezes, um usuário do site ainda consegue acessar essas páginas se souber onde encontrá-las.
O comando "Disallow" pode ser usado de várias maneiras, muitas das quais são exibidas no exemplo acima.
Bloquear um arquivo (em outras palavras, uma página web em particular)
A título de exemplo, se o Cloudflare quisesse impedir os bots de rastrear nosso artigo " O que é um bot?", esse comando seria escrito da seguinte forma:
Disallow: /learning/bots/what-is-a-bot/Após o comando "disallow", a parte da URL da página web que vem após a página inicial, neste caso, "www.cloudflare.com". – está incluída. Com este comando em vigor, os bots que seguirem as instruções do robots.txt não acessarão https://www.cloudflare.com/learning/bots/what-is-a-bot/, e, portanto, a página provavelmente não aparecerá nos resultados dos mecanismos de busca tradicionais.
Bloquear um diretório
Às vezes é mais eficiente bloquear várias páginas ao mesmo tempo, em vez de listar todas elas individualmente. Se todas elas estiverem na mesma seção do site, um arquivo robots.txt pode simplesmente bloquear o diretório que as contém.
Um exemplo do mencionado cima é:
Disallow: /__mesa/Isso significa que todas as páginas contidas no diretório __mesa não devem ser rastreadas.
Permitir acesso total
Esse comando teria a seguinte aparência:
Disallow:Isso diz aos bots que eles podem navegar por todo o site, porque não há nada que não seja autorizado.
Ocultar todo o site para os bots
Disallow: /O "/" aqui representa a "raiz" na hierarquia de um site, ou a página a partir da qual todas as outras páginas se ramificam e, portanto, inclui a página inicial e todas as páginas vinculadas a ela. Com este comando, os bots dos mecanismos de busca podem não rastrear o site de forma alguma.
Que outros comandos fazem parte do Protocolo de Exclusão de Robôs?
Allow: como seria de se esperar, o comando "Allow" informa aos bots que eles têm permissão para acessar uma determinada página web ou diretório. Este comando indica a preferência do site em permitir que os bots acessem uma página específica, enquanto proíbe o acesso às demais páginas no arquivo. Nem todos os mecanismos de busca reconhecem esse comando.
Crawl-delay: O comando "crawl-delay" destina-se a impedir que os bots do tipo spider dos mecanismos de pesquisa sobrecarreguem um servidor. Ele permite que os administradores especifiquem quanto tempo o bot deve esperar entre cada solicitação, em milissegundos. Aqui está um exemplo de um comando "Crawl-delay" para uma espera de 8 milissegundos:
Crawl-delay: 8O Google não reconhece esse comando, embora outros mecanismos de busca frequentemente o reconheçam. Para o Google, os administradores podem alterar a frequência de rastreamento do site no Google Search Console.
O que é o protocolo Sitemaps? Por que ele está incluído no robots.txt?
O protocolo Sitemaps ajuda os bots a saberem o que incluir no seu rastreamento de um site.
Um sitemap é um arquivo XML que se parece com:
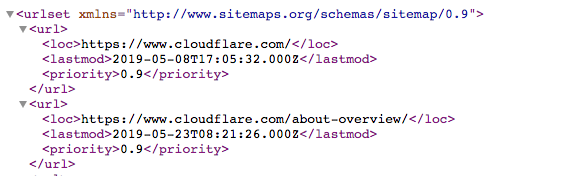
É uma lista legível por máquina de todas as páginas de um site. Por meio do protocolo Sitemaps, links para esses sites podem ser incluídos no arquivo robots.txt. O formato é: "Sitemaps:" seguido do endereço web do arquivo XML. É possível ver vários exemplos no arquivo Cloudflare robots.txt acima.
Embora o protocolo Sitemaps ajude a garantir que os bots web spider não ignorem nada ao rastrear um site: os bots continuarão a seguir seu típico processo de rastreamento. O Sitemaps não força os bots do tipo crawler a priorizar as páginas web de forma diferente.
Como o robots.txt se relaciona com o gerenciamento de bots?
O gerenciamento de bots é essencial para manter um site ou aplicativo em funcionamento, pois mesmo uma atividade de bots bons pode sobrecarregar um servidor de origem, retardando ou derrubando um ativo da web. Um arquivo robots.txt bem construído mantém um site otimizado para SEO e mantém a atividade de bots bem comportados sob controle. Um arquivo robots.txt não será muito eficaz para gerenciar o tráfego de bots maliciosos.
Apesar da importância do robots.txt, em 2025 a Cloudflare descobriu que apenas 37% de seus 10 mil principais sites tinham um arquivo robots.txt. Isso significa que uma grande porcentagem, talvez a maioria, dos sites não está usando essa ferramenta. Para ajudar esses sites, especialmente aqueles que talvez não queiram que seu conteúdo original seja usado para treinamento de IA, a Cloudflare oferece o "robots.txt gerenciado". Ele é um serviço que cria ou atualiza o arquivo robots.txt em nome de um site com as configurações desejadas. Saiba mais sobre o robots.txt gerenciado.
Easter eggs (ovos de páscoa) do Robots.txt
Ocasionalmente, um arquivo robots.txt contém Easter eggs, mensagens bem humoradas que os desenvolvedores incluíram porque sabem que esses arquivos raramente são vistos pelos usuários. Por exemplo, o arquivo robots.txt do YouTube diz "Criado num futuro distante (no ano 2000) após a revolta robótica de meados dos anos 90 que dizimou todos os seres humanos." O arquivo robots.txt da Cloudflare pede, "Caro robô, seja gentil".
# .__________________________.
# | .___________________. |==|
# | | ................. | | |
# | | ::[ Caro robô ]: | | |
# | | ::::[ seja gentil ]:: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | |
# | | ::::::::::::::::: | | ,|
# | !___________________! |(c|
# !_______________________!__!
# / \
# / [][][][][][][][][][][][][] \
# / [][][][][][][][][][][][][][] \
#( [][][][][____________][][][][] )
# \ ------------------------------ /
# \______________________________/
O Google também tem um arquivo "humans.txt" em: https://www.google.com/humans.txt
Perguntas frequentes
O que é um arquivo robots.txt?
Um arquivo robots.txt é uma lista de preferências de comportamento de bots de um site, localizada nos arquivos de origem do site. Ele fornece orientação para bots legítimos, como os web crawlers de mecanismos de busca, sobre quais partes de um site eles têm permissão para acessar e quais devem evitar, ajudando a gerenciar o tráfego e controlar a indexação. Também pode listar regras para crawlers de IA.
O que é um web crawler?
Um web crawler é um bot automatizado que visita e indexa páginas web para mecanismos de busca, ajudando os usuários a encontrar conteúdo através dos resultados de pesquisa.
O que é o protocolo de exclusão de robôs?
O protocolo de exclusão de robôs é o formato para instruções em um arquivo robots.txt. O protocolo informa aos web crawlers quais páginas ou recursos eles não devem acessar ou rastrear em um site.
O que significa "User-agent" em um arquivo robots.txt?
"User-agent" especifica para qual bot ou grupo de bots um conjunto de instruções se aplica em um arquivo robots.txt. "User-agent: *" significa que a regra se aplica a todos os bots.
O que é o comando Disallow no robots.txt?
O comando Disallow instrui os bots a não rastrearem páginas ou diretórios específicos em um site. Por exemplo, "Disallow: /private/" instrui os bots a não acessarem o diretório "private".
O que é o protocolo Sitemaps no robots.txt?
O protocolo Sitemaps permite que os proprietários de sites incluam links para seus arquivos XML de mapa de site no robots.txt, ajudando os bots a identificar quais páginas devem ser rastreadas.
Qual é a diferença entre bots bons e bots ruins?
Bots bons são mais propensos a seguir as instruções do arquivo robots.txt. Eles também prestam serviços úteis. Os web crawlers de mecanismos de busca, por exemplo, normalmente respeitam as regras do arquivo robots.txt ao indexar conteúdo para busca. Bots ruins frequentemente ignoram o arquivo robots.txt e podem extrair conteúdo, atacar sites ou enviar solicitações excessivas que aumentam os custos do site.
O que o comando Crawl-delay faz no arquivo robots.txt?
O comando Crawl-delay instrui os bots sobre quanto tempo devem aguardar entre as solicitações para evitar sobrecarregar um servidor. Nem todos os bots respeitam este comando: o Googlebot, por exemplo, não o faz, embora o Google permita que os administradores de sites estabeleçam uma regra semelhante através do Google Search Console.
Como o robots.txt afeta a otimização da SEO?
Um arquivo robots.txt bem construído pode melhorar a SEO ao informar aos crawlers dos mecanismos de busca quais páginas devem ser indexadas, ajudando a evitar que conteúdo não essencial ou duplicado seja indexado. Além disso, o arquivo robots.txt pode ajudar os web crawlers a encontrar todas as páginas que devem indexar por meio do Sitemaps.