A method called Simple Self-Distillation (SSD) enables large language models to enhance their code generation performance by training exclusively on self-generated, unverified solutions. This approach improved the Qwen3-30B-Instruct model's pass@1 score on LiveCodeBench v6 from 42.4% to 55.3%, demonstrating its efficacy without external supervision or complex verification.
View blog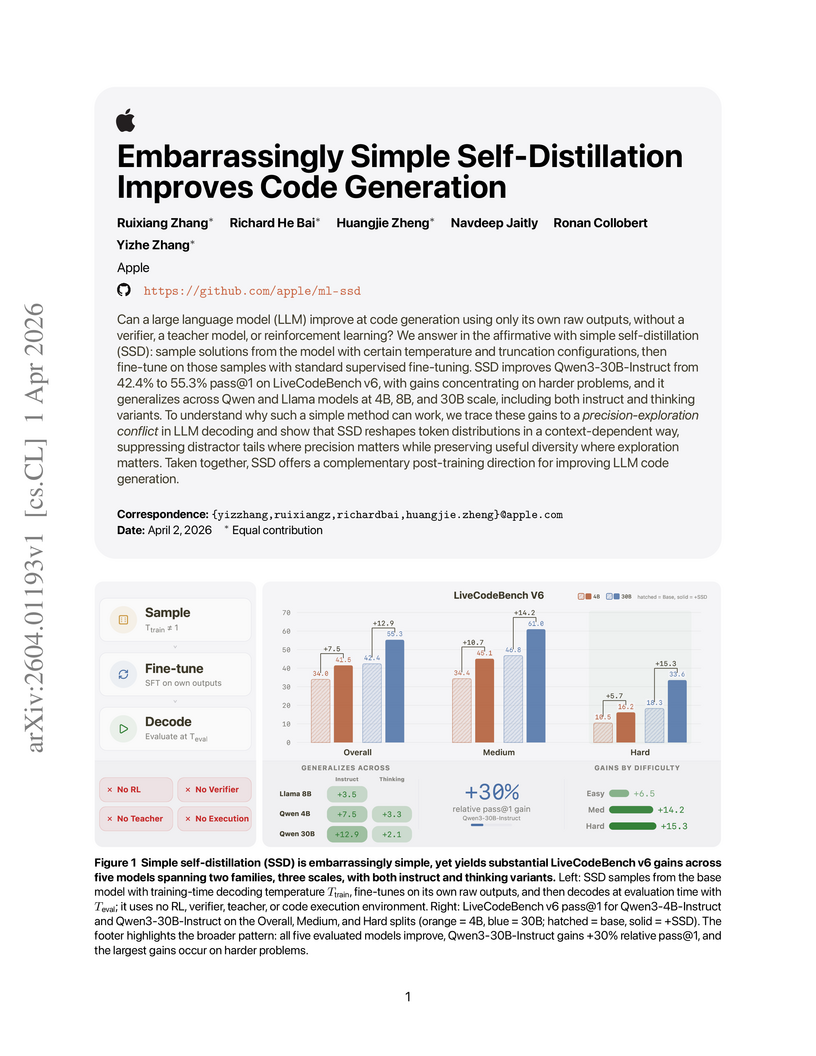
A comprehensive survey unifies the fragmented understanding of latent space in language-based models, detailing its conceptual foundation, historical evolution, technical mechanisms, emergent abilities, and future research directions. It positions latent space as a machine-native computational substrate enabling enhanced intelligence beyond explicit token-level operations.
View blog
The SKILL0 framework introduces In-Context Reinforcement Learning (ICRL) to enable Large Language Model (LLM) agents to internalize skills into their parameters, thereby achieving autonomous behavior without external skill descriptions at inference time. This approach yielded superior performance, such as an 87.9% success rate on ALFWorld (+9.7% over AgentOCR), while substantially reducing context token costs by over 5 times compared to skill-augmented methods.
View blog
Microsoft developed the AI Greenferencing framework and its Heron router, enabling the routing of AI inferencing workloads to modular data centers located at wind farms. This system leverages underutilized renewable energy and helps mitigate strain on the power grid, demonstrating a 1.8x goodput improvement and a 27% median end-to-end latency reduction for AI tasks through intelligent routing and multi-timescale resource optimization.
View blog

The CORAL framework introduces an autonomous multi-agent evolutionary system, empowering Large Language Model agents to control their discovery process and collaborate indirectly through shared persistent memory. This approach achieved new state-of-the-art results on 8 out of 11 mathematical and systems optimization tasks, exhibiting a 3-10x higher improvement rate and an 18.3% cycle reduction in kernel engineering.
View blog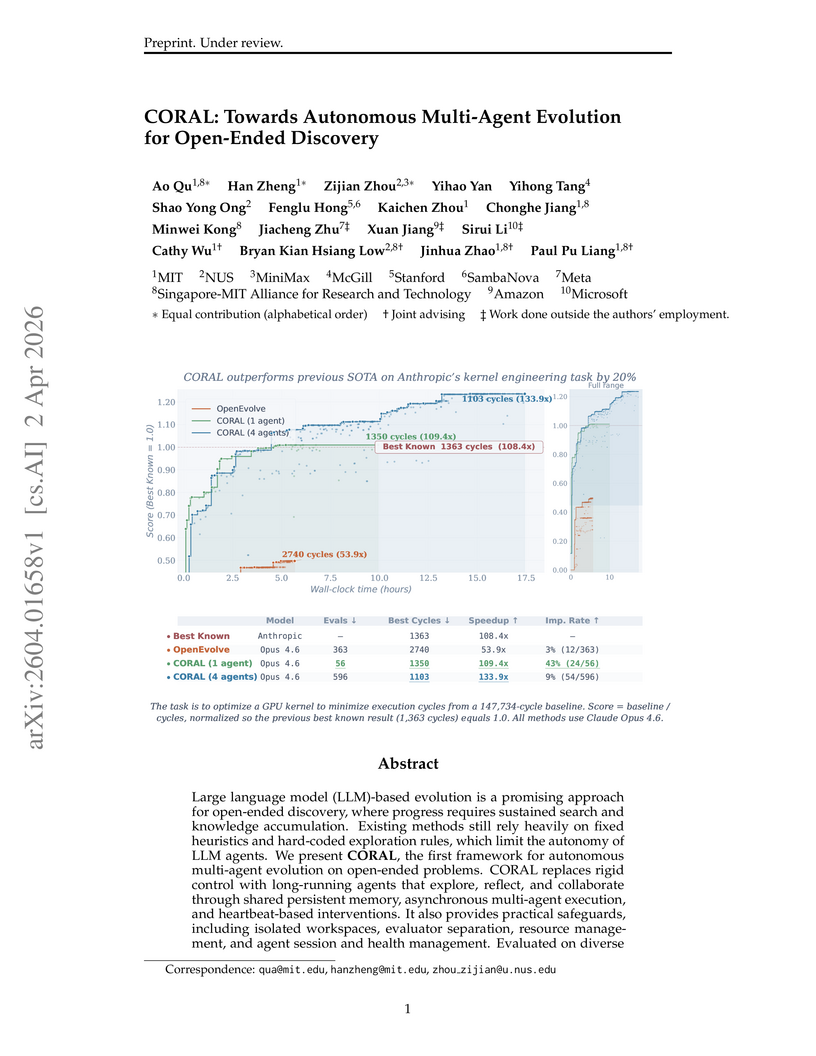
Sample-Routed Policy Optimization (SRPO) unifies Group Relative Policy Optimization (GRPO) and Self-Distillation Policy Optimization (SDPO) for large language model post-training. This framework uses adaptive sample routing and entropy-aware dynamic weighting to improve early training efficiency, enhance long-horizon stability, and achieve higher peak performance on various benchmarks.
View blog
Meta-Harness provides an end-to-end optimization framework for LLM harnesses, the external code that dictates how models interact with their environment. The system utilizes an agentic proposer with filesystem access to uncompressed historical code and execution traces, leading to a 7.7-point accuracy improvement in text classification, a 4.7-point average gain in math reasoning, and competitive pass rates on agentic coding benchmarks.
View blog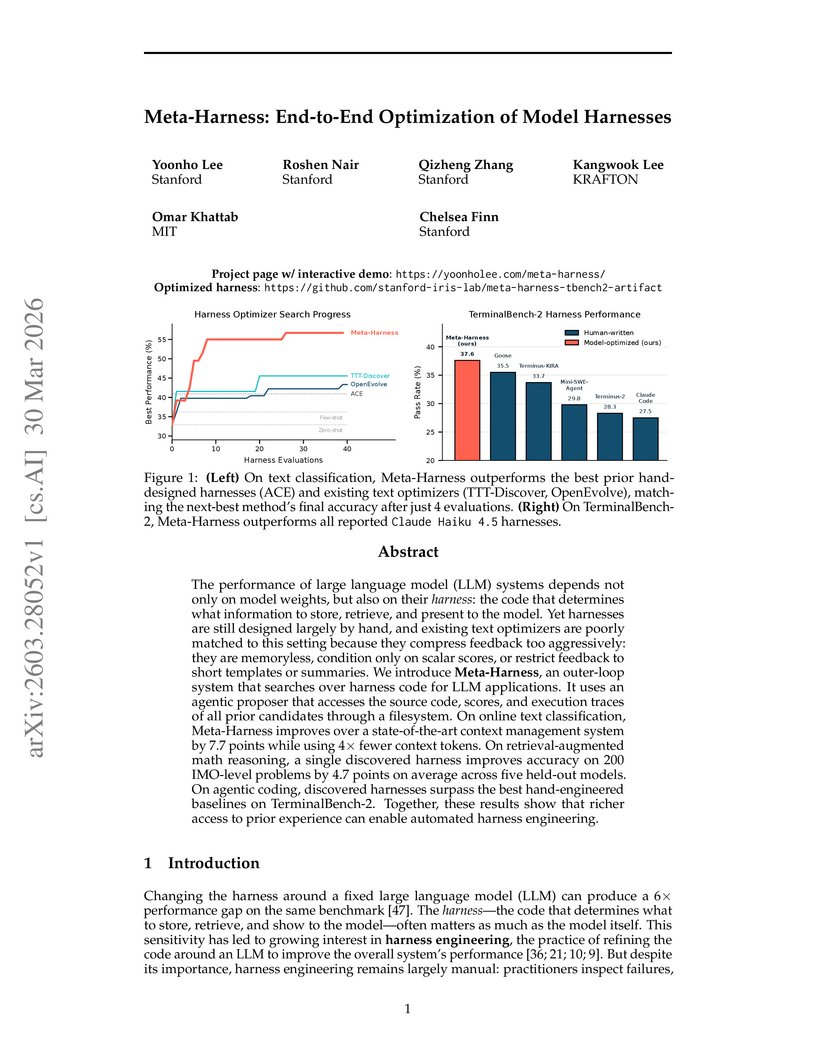
SIMPLESTREAM, a minimalist baseline employing only the most recent N video frames with an off-the-shelf visual-language model, achieves state-of-the-art performance on streaming video understanding benchmarks like OVO-Bench and StreamingBench, demonstrating that complex memory mechanisms are often not necessary for competitive results.
View blog
This research introduces a large-scale dataset, "Generative World Renderer," comprising over 4 million frames from AAA games with synchronized RGB and five G-buffer channels, alongside a novel VLM-based evaluation protocol. The work demonstrates that training on this dataset substantially improves inverse rendering performance and G-buffer-conditioned forward synthesis, enabling more robust material decomposition, precise geometry, and enhanced real-world game editing with complex atmospheric effects.
View blog
A comprehensive survey outlines On-Policy Distillation (OPD) for Large Language Models (LLMs), introducing a unified theoretical framework based on f-divergences and a three-dimensional taxonomy for existing methods. The work details how OPD mitigates exposure bias, reducing error accumulation from quadratic to linear, and explores various methodologies and future research directions for efficient and capable LLM distillation.
View blog
SteerViT introduces a method to equip any pretrained Vision Transformer with language-steerable visual representations by integrating lightweight gated cross-attention layers for early text-visual fusion. This approach achieves a Pareto improvement by enabling fine-grained control over visual features with natural language, demonstrated by a 96.0% top-1 retrieval accuracy on the CORE benchmark, while preserving the original encoder's representation quality with only 21 million trainable parameters.
View blog
Researchers at Shanghai Jiao Tong University, Tsinghua University, and UCSD developed LatentUM, a unified model that integrates visual understanding and generation within a shared semantic latent space, eliminating pixel-space mediation. This approach enhances interleaved cross-modal reasoning for tasks like visual spatial planning and action-conditioned world modeling, achieving state-of-the-art performance on relevant benchmarks.
View blog
Peking University and Alibaba Group researchers developed THINK-ANYWHERE, a mechanism enabling Large Language Models (LLMs) to invoke on-demand, token-level reasoning during code generation, enhancing adaptability and resource efficiency. The approach achieves an average pass@1 score of 70.3% across four code generation benchmarks, representing a 9.3% absolute improvement, and also generalizes to mathematical reasoning tasks.
View blog
Michel Fabrice Serret's preprint introduces the fundamental concepts of Transformer models and attention mechanisms, tailored for applied mathematicians. It systematically formalizes text encoding, attention operations, architectural components, and discusses computational optimizations like KV caching and latent attention, preparing the audience to engage with quantitative challenges in the field.
View blog
The VOID framework enables video object removal that generates physically plausible counterfactual scenarios by modeling how a scene would dynamically evolve in the absence of a target object and its interactions. It achieved 64.8% human preference and consistently high VLM-as-a-judge scores, particularly for interaction and physics realism, surpassing existing baselines.
View blog
ByteRover introduces an agent-native memory architecture where large language models directly manage and structure their own knowledge using a hierarchical, file-based Context Tree. This approach mitigates issues like semantic drift in memory-augmented generation systems and achieves 96.1% accuracy on LoCoMo, outperforming baselines by 6.2 percentage points, and 92.8% on LongMemEval-S with a median query latency of 1.6 seconds, all without relying on external databases.
View blog
ActionParty introduces an autoregressive video generator for interactive games that effectively binds actions to multiple individual subjects. The system achieves precise per-subject control by jointly modeling video frames with explicit subject states and employing specialized attention mechanisms, outperforming baselines in action accuracy and visual fidelity across 46 diverse game environments.
View blog

This research introduces a reinforcement learning framework for sequential optimal stopping in speculative trading, where agents learn optimal entry and exit times under general price dynamics and utility functions. The methodology employs randomized intensity controls with entropy regularization, yielding closed-form optimal policies as Gibbs distributions and providing theoretical convergence guarantees to the original problem.
View blog
The World Action Verifier (WAV) framework enhances action-conditioned world models by employing a self-improving cycle that leverages forward-inverse asymmetry to identify and rectify prediction errors. This approach resulted in a 2x improvement in sample efficiency for world model learning and an 18% increase in average reward for downstream robotic manipulation policies compared to baseline methods.
View blog
A systematic investigation into LLM agent memory architectures proposes a modular framework for analysis, conducting comprehensive evaluations of ten existing methods. This research introduces a new memory method that achieves competitive performance, outperforming strong baselines by 5.17% in overall F1 score on LONGMEMEVAL, while maintaining low computational overhead.
View blog