
Mathematical research traditionally involves a small number of professional mathematicians working closely on difficult problems. However, I have long believed that there is a complementary way to do mathematics, in which one works with a broad community of mathematically minded people on problems which may not be as deep as the problems one traditionally works on, but still are of mathematical interest; and that modern technologies, including AI, are more suitable for contributing the latter type of workflow. The “Polymath projects” were one example of this broad type of collaboration, where internet platforms such as blogs and wikis were used to facilitate such collaboration. Some years later, collaborative formalization projects (such as the one to formalize the Polynomial Freiman–Ruzsa conjecture of Marton, discussed previously on this blog here) became popular in some circles. And in 2024, I launched the Equational Theories Project (ETP) (discussed on this blog here and here), combining the rigor of Lean formalization with “good old fashioned AI” (in the form of automated theorem provers) to settle (with formal verification) over 22 million true-false problems in universal algebra.
Continuing in this spirit, Damek Davis and I are launching a new project, in the form of an experimental competitive challenge hosted by the SAIR Foundation (where I serve as a board member, and which is supplying technical support and compute). The idea of this challenge, motivated in part by this recent paper of Honda, Murakami, and Zhang, is to measure the extent to which the 22 million universal algebra true-false results obtained by the ETP can be “distilled” into a short, human-readable “cheat sheet”, similar to how a student in an undergraduate math class might distill the knowledge learned from that class into a single sheet of paper that the student is permitted to bring into an exam.
Here is a typical problem in universal algebra that the ETP was able to answer:
Problem 1 Suppose thatis a binary operation such that
for all
. Is it true that
for all
?
Such a problem can be settled either by algebraically manipulating the initial equation to deduce the target equation, or by finding a counterexample to the target equation that still satisfies the initial equation. There are a variety of techniques to achieve either of these, but this sort of problem is difficult, and even undecidable in some cases; see this paper of the ETP collaborators for more discussion. Nevertheless, many of these problems can be settled with some effort by humans, by automated theorem provers, or by frontier AI systems; here for instance is an AI-generated solution to the above problem.
However, these AI models are expensive, and do not reveal much insight as to where their answers come from. If one instead tries a smaller and cheaper model, such as one of the many open-source models available, it turns out that these models basically perform no better than random chance, in that when asked to say whether the answer to a question such as the above is true or false, they only answer correctly about 50% of the time.
But, similarly to how a student struggling with the material for a math class can perform better on an exam when provided the right guidance, it turns out that such cheap models can perform at least modestly better on this task (with success rates increasing to about 55%-60%) if given the right prompt or “cheat sheet”.
“Stage 1” of the distillation challenge, which we launched today, asks for contestants to design a cheat sheet (of at most 10 kilobytes in size) that can increase the performance of these models on the above true-false problems to as high a level as possible. We have provided a “playground” with which to test one’s cheat sheet (or a small number of example cheat sheets) some cheap models against a public set of 1200 problems (1000 of which were randomly selected, and rather easy, together with 200 “hard” problems that were selected to resist the more obvious strategies for resolving these questions); a brief video explaining how to use the playground can be found here.
Submissions stage will end on April 20, after which we will evaluate the submissions against a private subset of test questions. The top 1000 submissions will advance to a second stage which we are currently in the process of designing, which will involve more advanced models, but also the more difficult task of not just providing a true-false answer, but also a proof or counterexample to the problem.
The competition will be coordinated on this Zulip channel, where I hope there will be a lively and informative discussion.
My hope is that the winning submissions will capture the most productive techniques for solving these problems, and/or provide general problem-solving techniques that would also be applicable to other types of mathematical problems. We started with the equational theory project data set for this pilot competition due to its availability and spectrum of difficulty levels, but if this type of distillation process leads to interesting results, one could certainly run in on many other types of mathematical problem classes to get some empirical data on how readily they can be solved, particularly after we learn from this pilot competition on how to encourage participation and share of best practices.
SAIR will also launch some other mathematical challenges in the coming months that will be of a more cooperative nature than this particular competitive challenge; stay tuned for further announcements.
 that arise from some mathematical optimization problem of interest, for instance finding the best constant
that arise from some mathematical optimization problem of interest, for instance finding the best constant  , the constant in a certain autocorrelation quantity relating to Sidon sets
, the constant in a certain autocorrelation quantity relating to Sidon sets , the constant
, the constant (or some subinterval of the integers) and remove some congruence classes
(or some subinterval of the integers) and remove some congruence classes  for various moduli
for various moduli 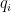 . Here we shall concern ourselves with the simple setting where we are sieving the entire integers rather than an interval, and are only removing a finite number of congruence classes
. Here we shall concern ourselves with the simple setting where we are sieving the entire integers rather than an interval, and are only removing a finite number of congruence classes  . In this case, the set of integers that remain after the sieving is periodic with period
. In this case, the set of integers that remain after the sieving is periodic with period  , so one work without loss of generality in the cyclic group
, so one work without loss of generality in the cyclic group 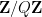 . One can then ask: what is the density of the sieved set
. One can then ask: what is the density of the sieved set 

 , the density of the sieved set is maximized when all the
, the density of the sieved set is maximized when all the  vanish. Thus,
vanish. Thus, 

 ,
,  , and
, and  , then only
, then only  remains, giving a density of
remains, giving a density of  . On the other hand, if one sieves out
. On the other hand, if one sieves out  ,
,  , and
, and  and
and  , giving the larger density of
, giving the larger density of  .
.  , with residue classes now becoming cosets of various subgroups of
, with residue classes now becoming cosets of various subgroups of  be cosets of a finite cyclic abelian group
be cosets of a finite cyclic abelian group 
 ,
,  ,
,  , and
, and  . Then the cosets
. Then the cosets  ,
,  , and
, and  cover the residues
cover the residues  , with a cardinality of
, with a cardinality of 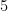 ; but the subgroups
; but the subgroups 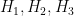 cover the residues
cover the residues  , having the smaller cardinality of
, having the smaller cardinality of  .
.  together reduces the total amount of space that these cosets occupy. As pointed out in comments, the requirement of cyclicity is crucial; four lines in a finite affine plane already suffice to be a counterexample otherwise.
together reduces the total amount of space that these cosets occupy. As pointed out in comments, the requirement of cyclicity is crucial; four lines in a finite affine plane already suffice to be a counterexample otherwise.
 -groups, Rogers’ theorem is an immediate consequence of two observations:
-groups, Rogers’ theorem is an immediate consequence of two observations:
 for some prime power
for some prime power 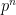 .
.  of coprime orders, then it also holds for the product
of coprime orders, then it also holds for the product  .
.  is simply the largest of the
is simply the largest of the 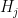 , which has the same size as
, which has the same size as  and thus has lesser or equal cardinality to
and thus has lesser or equal cardinality to  .
.
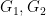 and standard group theoretic arguments (e.g.,
and standard group theoretic arguments (e.g.,  of subgroups of
of subgroups of 
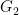 to each “vertical slice” of
to each “vertical slice” of 
 to each “horizontal slice” of
to each “horizontal slice” of 
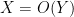 or
or 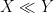 , for instance, to indicate a bound of the form
, for instance, to indicate a bound of the form  for some unspecified constant
for some unspecified constant 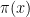 is asymptotic to the logarithmic integral
is asymptotic to the logarithmic integral  , in
, in 
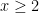 .
.
 , and let
, and let 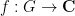 be
be  . Then there exists a polynomial
. Then there exists a polynomial  of degree at most
of degree at most  such that
such that 
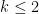 case (by work of
case (by work of  , for instance, is treated by this theorem but not covered by previous results. In the aforementioned paper of Candela et al., a result similar to the above theorem was also established, except that the polynomial
, for instance, is treated by this theorem but not covered by previous results. In the aforementioned paper of Candela et al., a result similar to the above theorem was also established, except that the polynomial  was defined in an extension of
was defined in an extension of  correlated with a projection of a phase polynomial, rather than directly with a phase polynomial on
correlated with a projection of a phase polynomial, rather than directly with a phase polynomial on  is a countable abelian group of bounded exponent, and
is a countable abelian group of bounded exponent, and  is an ergodic
is an ergodic 
 of
of  is a compact abelian group extension by a cocycle of “type”
is a compact abelian group extension by a cocycle of “type”  , and them attempt to show that each such cocycle is cohomologous to a polynomial cocycle. However, this appears to be impossible in general, particularly in low characteristic, as certain key short exact sequences fail to split in the required ways. To get around this, we have to work with a different tower, extending various levels of this tower as needed to obtain additional good algebraic properties of each level that enables one to split the required short exact sequences. The precise properties needed are rather technical, but the main ones can be described informally as follows:
, and them attempt to show that each such cocycle is cohomologous to a polynomial cocycle. However, this appears to be impossible in general, particularly in low characteristic, as certain key short exact sequences fail to split in the required ways. To get around this, we have to work with a different tower, extending various levels of this tower as needed to obtain additional good algebraic properties of each level that enables one to split the required short exact sequences. The precise properties needed are rather technical, but the main ones can be described informally as follows:
 is automatically of type
is automatically of type 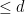 ; exactness, roughly speaking, asserts the converse.) Informally, the cocycles should be “as polynomial as possible”.
; exactness, roughly speaking, asserts the converse.) Informally, the cocycles should be “as polynomial as possible”. 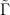 is represented).
is represented).  that maps polynomials on the system to polynomials on the group
that maps polynomials on the system to polynomials on the group  , with the image being a
, with the image being a 
 of a given degree
of a given degree  , and specifically the question of bounding the arclength
, and specifically the question of bounding the arclength  of such lemniscates. For instance, when
of such lemniscates. For instance, when  , the lemniscate is the unit circle and the arclength is
, the lemniscate is the unit circle and the arclength is 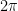 ; this in fact turns out to be the minimum possible length amongst all (connected) lemniscates, a
; this in fact turns out to be the minimum possible length amongst all (connected) lemniscates, a 

 is the
is the 
 for all monic polynomials of degree
for all monic polynomials of degree  . Asympotically, bounds of the form
. Asympotically, bounds of the form  had been known for various
had been known for various  ,
, 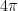 ; a significant advance was made
; a significant advance was made 
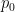 . In that paper, the authors comment that the
. In that paper, the authors comment that the  error could be improved, but that
error could be improved, but that  seemed to be the limit of their method.
seemed to be the limit of their method.
 .
.  .
.  .
.  (for instance by combining it with other known tools to control the diameter of the lemniscate), but it seems challenging to use this approach to get bounds close to the optimal
(for instance by combining it with other known tools to control the diameter of the lemniscate), but it seems challenging to use this approach to get bounds close to the optimal  .
.

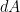 is area measure,
is area measure,  is the log-derivative of
is the log-derivative of  is the log-derivative of
is the log-derivative of 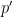 , and
, and  is the region
is the region  . This and the triangle inequality already lets one prove bounds of the form
. This and the triangle inequality already lets one prove bounds of the form  by controlling
by controlling  using the triangle inequality, the
using the triangle inequality, the  on one hand, and the oscillating nature of
on one hand, and the oscillating nature of 
 is an enlargement of
is an enlargement of  are certain error terms that can be controlled by a number of standard tools (e.g., the
are certain error terms that can be controlled by a number of standard tools (e.g., the  ,
,  ,
,  . For simplicity let us normalize
. For simplicity let us normalize 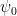 to be real, and
to be real, and 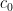 to be negative real. In order to have a non-trivial lemniscate in this region,
to be negative real. In order to have a non-trivial lemniscate in this region,  . Because the unit circle
. Because the unit circle 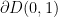 is tangent to the line
is tangent to the line  at
at  is then heuristically approximated by the condition that
is then heuristically approximated by the condition that  . On the other hand, the hypothesis
. On the other hand, the hypothesis  for some amplitude
for some amplitude  , which heuristically integrates to
, which heuristically integrates to  . Writing
. Writing  in polar coordinates as
in polar coordinates as  and
and  , the condition
, the condition  can then be rearranged after some algebra as
can then be rearranged after some algebra as 
 . This makes the main terms on both sides of
. This makes the main terms on both sides of  and
and  .)
.)

 and
and  , yielding the first bound
, yielding the first bound 
 ranges over critical points. From some elementary geometry, one can show that the more the critical points
ranges over critical points. From some elementary geometry, one can show that the more the critical points  sense), the more one can gain over the triangle inequality here; conversely, the
sense), the more one can gain over the triangle inequality here; conversely, the 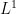 dispersion
dispersion  of the critical points (after normalizing so that these critical points have mean zero) can be used to improve the control on the error terms
of the critical points (after normalizing so that these critical points have mean zero) can be used to improve the control on the error terms 
 . In this case, one can do some elementary manipulations of the factorization
. In this case, one can do some elementary manipulations of the factorization 
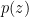 and
and  ; for instance, we will be able to obtain an approximation of the form
; for instance, we will be able to obtain an approximation of the form 

 . An extremely careful version of the previous analysis can now give an estimate of the shape
. An extremely careful version of the previous analysis can now give an estimate of the shape 
 , where
, where  is a measure of how close
is a measure of how close  to deal with the constant term
to deal with the constant term  ). This establishes the final bound (for
). This establishes the final bound (for  (or, equivalently, a
(or, equivalently, a 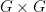 multiplication table). An equational law is an equation involving this operation and a number of indeterminate variables. Some examples of equational laws, together with the number that we assigned to that law, include
multiplication table). An equational law is an equation involving this operation and a number of indeterminate variables. Some examples of equational laws, together with the number that we assigned to that law, include
 (Trivial law):
(Trivial law): 
 (Singleton law):
(Singleton law): 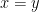
 (Commutative law):
(Commutative law): 
 (
(
 (Associative law):
(Associative law): 
 ; one can explore them in our “
; one can explore them in our “ implications of this type to settle; most of these are relatively easy and could be resolved in a matter of minutes by an expert in college-level algebra, but prior to this project, it was impractical to actually do so in a manner that could be feasibly verified. Also, this problem is known to become undecidable for sufficiently long equational laws. Nevertheless, we were able to resolve all the implications informally after two months, and have them completely formalized in Lean after a further five months.
implications of this type to settle; most of these are relatively easy and could be resolved in a matter of minutes by an expert in college-level algebra, but prior to this project, it was impractical to actually do so in a manner that could be feasibly verified. Also, this problem is known to become undecidable for sufficiently long equational laws. Nevertheless, we were able to resolve all the implications informally after two months, and have them completely formalized in Lean after a further five months.
 for some coefficients
for some coefficients  , turned out to resolve many cases.
, turned out to resolve many cases.  but not another
but not another  , by starting with a base magma
, by starting with a base magma  that obeyed both laws, taking a Cartesian power
that obeyed both laws, taking a Cartesian power  of that magma, and then “twisting” the magma operation by certain permutations of
of that magma, and then “twisting” the magma operation by certain permutations of 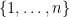 designed to preserve
designed to preserve  ” which were tractable to compute, and again gave ways to construct magmas that obeyed one law
” which were tractable to compute, and again gave ways to construct magmas that obeyed one law  (E677) imply the law
(E677) imply the law  (E255) for finite magmas?
(E255) for finite magmas? 
Recent Comments