Da tempo e sempre più frequentemente l’arma legale viene usata
per intimidire o mettere a tacere voci scomode impegnate su temi di
interesse pubblico. La pratica è nota come SLAPP,
acronimo di Strategic Lawsuit Against Public Participation
(Azione legale strategica contro la partecipazione pubblica).
Le SLAPP sono cause civili o penali che, pur
essendo formalmente legittime, vengono promosse con
finalità dissuasive. Ad esempio può essere considerata una
SLAPP una causa ad un giornalista con l’obiettivo di impedirgli di
continuare a lavorare liberamente, ostacolando la diffusione
pubblica di una informazione. Solitamente si procede tramite azioni
per diffamazione con richieste di risarcimento molto elevate,
talvolta addirittura milionarie, tali da mettere in difficoltà chi
prova a realizzare delle inchieste e da creare un effetto di timore
diffuso: come esempio, si riporta l’azione intentata nel 2023 dalla
compagine petrolifera Shell contro Greenpeace onde intimare a
quest’ultima ad interrompere ogni protesta, pena il perseguimento
di risarcimenti fino a £7 milioni.
Si tratta, evidentemente, di pratiche che incidono sui
diritti fondamentali riconosciuti a livello europeo, con
particolare riferimento alle libertà di espressione e di
informazione (art. 10 della Convenzione Europea dei Diritti
dell’Uomo, nonché art. 21 della Costituzione italiana).
Contro questo fenomeno in Europa si è
costituita l’associazione CASE (Coalition
Against SLAPPs in Europe), che raccoglie oltre 120
associazioni ed organizzazioni non governative impegnate nel
monitoraggio delle SLAPP.
Lo stato dell’attività SLAPP in Europa è sintetizzato in un
rapporto annuale elaborato per CASE dalla Daphne Caruana
Galizia Foundation (intitolata alla giornalista maltese
assassinata in un attentato dinamitardo nel 2017).
Nell’ultimo rapporto, pubblicato nel gennaio 2026 e denominato
Democracy in the
Dock, emergono aspetti non positivi. Nel quindicennio
intercorso dall’inizio della mappatura, nel 2010, si sono
registrati 1.303 casi di SLAPP in 43 Stati
europei, di cui 167 nel solo 2024. Si tratta di dati in
crescita, a dimostrazione della perdurante diffusione della
pratica. Si teme, inoltre, che le minacce siano ben più di quante
dichiarate, arrivando spesso queste prima dell’avvio di un giudizio
(es.: minacce legali da parte degli avvocati).
I soggetti più colpiti, oltre ai giornalisti, sono attivisti,
associazioni per i diritti umani, organizzazioni ed accademici
impegnati su temi pubblicamente sensibili quali corruzione,
attività economiche e/o governative, ambiente e politica.
I ricorrenti sono spesso grandi aziende o personalità politiche,
ossia soggetti che dispongono di ingenti risorse economiche,
acutizzando così lo squilibrio tra le parti.
Uno sviluppo positivo è invece rappresentato dalla Direttiva
(UE) 2024/1069 adottata dal Parlamento europeo e dal Consiglio
dell’Unione Europea, volta ad introdurre strumenti per
contrastare le cause manifestamente infondate o
intimidatorie. La direttiva dovrà essere recepita dagli
Stati membri entro maggio 2026. Il rapporto segnala, tuttavia, come
questa offra tutele soprattutto nelle cause transfrontaliere
(appena l’8,5% dei casi), non garantendo invece una sufficiente
armonizzazione per le questioni di carattere nazionale. Nei mesi a
venire saranno pertanto da monitorarne con attenzione gli effetti,
onde eventualmente intervenire con proposte mirate al legislatore
per correggerne i punti deboli.
Wikimedia Italia, nella sua azione di
diffusione della conoscenza libera, si trova ad incrociare ostacoli
di questo tipo e fa parte e supporta la CASE e le
iniziative volte a garantire il rispetto delle libertà
costituzionali di espressione ed informazione, anche contro quei
pretestuosi ricorsi alla giustizia impiegati come strumenti di
intimidazione o censura preventiva.
Anche nel mese di febbraio le ricerche degli utenti su Wikipedia
hanno raccontato molto dell’attualità, delle curiosità del pubblico
e degli eventi che hanno animato il dibattito mediatico e culturale
italiano. Tra i temi più presenti spiccano quelli legati alle
Olimpiadi invernali di Milano Cortina 2026, che per settimane hanno
attirato l’attenzione del pubblico, insieme a fatti di cronaca,
personaggi della cultura e fenomeni della cultura pop. Con il
contributo dei volontari Oltrepier e Paul Gascoigne, abbiamo
raccolto e commentato le dieci voci più lette su Wikipedia
in italiano tra il 1° e il 28 febbraio 2026, offrendo uno
sguardo su ciò che ha incuriosito e coinvolto maggiormente i
lettori dell’enciclopedia libera.
Nonostante la concomitanza di alcuni eventi di grande popolarità
per il pubblico italiano, a emergere su tutte le altre voci è
stato, invece, il finanziere statunitense morto per suicidio nel
2019, a causa della prosecuzione dello scandalo legato agli
“Epstein Files”,
pubblicati dal Dipartimento di Giustizia
degli Stati Uniti tra la fine del 2025 e l’inizio del 2026.
Questa enorme quantità di
materiali, che include email, fotografie e atti investigativi,
ha riacceso l’attenzione sul caso, alimentando teorie del complotto,
nuove inchieste giornalistiche e dibattiti pubblici sul sistema di
relazioni che Epstein intratteneva con figure politiche, economiche
e culturali di alto profilo. Le rivelazioni e le polemiche legate
alla gestione e alla parziale censura dei documenti, insieme al
grande numero di personaggi influenti citati nei file, hanno
quindi contribuito a mantenere il tema al centro dell’agenda
mediatica.
Al secondo posto della classifica si colloca il Festival di
Sanremo, ormai ultimo presidio della tradizione nazionalpopolare
italiana. L’edizione di quest’anno, caratterizzata da toni più
pacati rispetto al passato e – quasi – priva di scandali o di
figure capaci di catalizzare l’attenzione del grande pubblico, ha
visto trionfare Sal Da Vinci con il brano
Per sempre sì, con
cui parteciperà anche al prossimo Eurovision Song Contest a
Vienna. Hanno invece completato il podio due proposte musicali più
contemporanee, come Sayf (con
Tu mi piaci tanto) e
Ditonellapiaga (con
Che fastidio!).
Quest’ultima si è distinta anche nella serata delle cover, in cui
ha prevalso con una rivisitazione di The Lady Is a Tramp,
in coppia con la rivelazione TonyPitony. Infine, il
vincitore della categoria “Nuove proposte” è stato Nicolò Filippucci, che ha
presentato il brano Laguna.
Dal 6 al 22 febbraio 2026 l’Italia è stata protagonista della
sua terza Olimpiade invernale, quarta in assoluto, dopo quelle di
Cortina 1956 e di
Torino 2006. I Giochi
si sono svolti non solo a Milano e Cortina d’Ampezzo, ma anche in
altri territori della Lombardia e del Trentino-Alto Adige. Anche
grazie alle ottime prestazioni degli atleti padroni di
casa, capaci di vincere dieci ori e 30 medaglie complessive,
l’edizione ha riscosso un grande successo di pubblico, pur tra
numerose controversie,
conduzioni non sempre impeccabili e preoccupazioni sull’effettiva
sostenibilità delle infrastrutture costruite in preparazione ai
Giochi.
Il pattinatore statunitense, di origini uzbeke da parte dei
genitori, entrambi ex
pattinatori, era una delle star più attese delle Olimpiadi
invernali (#4), avendo già conquistato un titolo mondiale a
soli 22 anni ed essendo stato il primo atleta a completare in gara
il difficilissimo quadruplo Axel.
Tuttavia, dopo aver contribuito in modo decisivo all’oro degli
Stati Uniti nel team event, la sua
gara individuale è
stata segnata da errori e cadute inattese, che lo hanno fatto
scivolare fino all’ottavo posto. La fotografia che ritrae il
padre-allenatore che, all’annuncio del punteggio del figlio, si
dispera con la testa fra le mani, è rimasta una delle immagini
simbolo della rassegna a cinque cerchi.
Il romanzo di Emily Brontë, pubblicato
nel 1847, è tornato al centro dell’attenzione negli ultimi mesi,
grazie all’uscita di una nuova trasposizione
cinematografica, arrivata nelle nostre sale il 12 febbraio. Il
nuovo adattamento, diretto da Emerald Fennell e
interpretato da Margot Robbie e Jacob Elordi, ha infatti
spinto molti lettori a riscoprire il romanzo, celebre per l’intensa
e tormentata relazione tra Heathcliff e Catherine Earnshaw.
Inoltre, il film si è distinto anche per la colonna sonora
originale, in cui la popstar inglese Charli XCX ha avuto un
ruolo preponderante.
Come anticipato alla voce #2, il cantante e attore, nato a New
York ma cresciuto a Napoli, ha inaspettatamente vinto l’ultimo
Festival di Sanremo, a cui ha preso parte per la seconda volta in
carriera, con il brano Per sempre sì. Da
Vinci si è dunque aggiudicato il diritto di prendere parte al
prossimo Eurovision Song Contest,
che si terrà a Vienna dal 12 al 16 maggio.
Proprio come Federica Brignone (#3), anche la pattinatrice di
velocità è riuscita nell’impresa di vincere due ori olimpici
durante l’edizione di Milano-Cortina (#4), aggiudicandosi prima la
gara dei 3000 metri e,
successivamente, quella dei 5000 metri.
L’artista bolognese è stato uno dei concorrenti dell’ultimo
Festival di Sanremo, in cui ha proposto il brano Uomo che cade,
classificatosi al 16° posto finale. Nella serata delle cover
Tredici Pietro si è preso la scena grazie alla sua rivisitazione di
Vita, brano di
Lucio Dalla e del padre Gianni Morandi; quest’ultimo, per
l’occasione, è salito sul palco per un duetto speciale con il
figlio.
Riportiamo oggi un aggiornamento in merito ai festeggiamenti
avvenuti in Sicilia in occasione del venticinquesimo
compleanno di Wikipedia. Il presente articolo è
stato pubblicato in lingua inglese su Diff, il blog
comunitario del movimento Wikimedia, il 5 marzo 2026, a
firma di Léa Lacroix (Auregann), supporto agli eventi di
Wikimedia Italia in Sicilia.
La Sicilia è un’isola al centro del Mediterraneo: crocevia di
culture e di placche tettoniche, e teatro di una storia ricca e
antichissima. Dal 2023, i volontari di
Wikipedia lavorano per riattivare la comunità locale
attraverso eventi e campagne.
I festeggiamenti per il compleanno di
Wikipedia sono stati l’occasione per proseguire
questo percorso, mettendo in contatto redattori volontari
provenienti da tre diverse aree dell’isola. Abbiamo condiviso i
risultati raggiunti finora e sfruttato l’entusiasmo dell’incontro
per avviare nuovi progetti.
L’incontro per il 25°
anniversario di Wikipedia a Palermo
A Palermo, capoluogo della regione e
centro delle principali decisioni politiche, stiamo lavorando per
far crescere la comunità open source locale e coinvolgerla
nel movimento Wikimedia. Allo stesso tempo,
continuiamo a rafforzare i legami con le realtà della cittadinanza
attiva del quartiere della Kalsa, nel centro
storico della città. Il nostro evento si è svolto
presso Orbita, un centro sociale e culturale
di recente apertura.
Abbiamo riunito una dozzina di wikimediani e attivisti dell’open
source curiosi di conoscere meglio i progetti Wikimedia. Durante
l’incontro abbiamo
presentato Wikipedia, Wikidata e
anche la mappa collaborativa OpenStreetMap,
festeggiando il compleanno di Wikipedia con una torta.
Il giorno successivo abbiamo organizzato
un mapping party: utilizzando l’app
StreetComplete, abbiamo attraversato Palermo per aggiungere
informazioni sulle strade della città, sulle attività commerciali e
sull’accessibilità degli spazi urbani.
Questo fine settimana di incontri e attività collettive ha
contribuito a rafforzare i legami tra i wikimediani già attivi a
Palermo e i nuovi arrivati, ponendo le basi per la crescita di un
gruppo locale autonomo.
L’incontro per il 25°
anniversario di Wikipedia a Catania
A Catania, dove hanno sede molti degli
organizzatori della comunità e che rappresenta uno dei principali
poli digitali dell’isola, stiamo costruendo collaborazioni con
comunità affini, tra cui gruppi dedicati agli open data, a Linux e
allo sviluppo software, cogliendo ogni occasione di incontro per
rafforzare i legami tra volontari.
In occasione del compleanno di Wikipedia, abbiamo inoltre
avviato un contatto con Legambiente, una
delle principali organizzazioni italiane impegnate nella tutela
dell’ambiente, con l’obiettivo di preparare il lancio della
campagna Wiki Loves Earth previsto per
la fine dell’anno.
L’incontro celebrativo si è svolto nella sede di Legambiente a
Catania ed è stato dedicato alla documentazione delle aree naturali
protette. Abbiamo presentato, tra l’altro, l’elenco dei parchi
siciliani che non sono ancora illustrati su Wikimedia
Commons.
L’ultima tappa del nostro viaggio è
stata Ragusa, importante centro per il
turismo e l’agricoltura in Sicilia. Qui abbiamo discusso di come i
progetti Wikimedia possano contribuire a documentare il patrimonio
naturale dell’isola, ma anche gli effetti dei cambiamenti climatici
sugli ecosistemi.
Pochi giorni prima del nostro incontro, la Sicilia era stata
colpita da due eventi naturali particolarmente gravi.
Il ciclone Harry ha interessato le coste
di diverse regioni del Mediterraneo, causando ingenti danni alle
strutture e accelerando l’erosione costiera. Poco dopo, forti
piogge hanno provocato una grave frana nel comune
di Niscemi, con danni significativi agli
edifici e gravi disagi per la popolazione.
In situazioni come queste, la comunità di Wikipedia può svolgere
un ruolo importante: non solo nel documentare le conseguenze
immediate dei disastri, ma anche nel registrare i cambiamenti a
lungo termine degli ecosistemi.
In quell’occasione, il volontario Fabio
Rinnone, originario di Niscemi, ha condiviso con gli
altri partecipanti le attività intraprese per registrare e
sistemare le informazioni relative all’evoluzione del dissesto.
L’obiettivo del lavoro è stato garantire che i dati e le notizie
sulla frana venissero riportati con accuratezza enciclopedica,
mettendoli a disposizione della collettività in modo aperto e
tempestivo.
Sul piano operativo, l’impegno si è tradotto nell’aggiornamento
costante della voce di Niscemi
su Wikipedia e nella stesura di una nuova voce
specifica dedicata all’evento franoso. Per supportare il contenuto
testuale con un’adeguata documentazione visiva, indispensabile
per descrivere le profonde alterazioni morfologiche del territorio,
è stato chiesto all’ingegnere Gianfranco Di Pietro di
condividere le riprese aeree dell’area colpita effettuate con il
suo drone, che ha accolto la richiesta, provvedendo a caricare i
propri scatti fotografici su Wikimedia Commons e rilasciandoli con
una licenza libera.
L’escursione per la campagna
Wiki Loves Earth a Ragusa
Durante l’incontro abbiamo conosciuto anche una guida
naturalistica locale. Le abbiamo presentato Wikipedia e discusso di
come le guide possano contribuire alla campagna Wiki
Loves Earth, condividendo su Wikimedia Commons fotografie
dei paesaggi naturali che documentano durante il loro lavoro.
Abbiamo inoltre partecipato insieme a un’escursione in una delle
aree naturali protette della regione, vicino alla foce
del fiume Irminio. Durante la visita abbiamo avuto
l’opportunità di fotografare i danni causati dal recente ciclone,
che ha parzialmente distrutto dune e scogliere.
I tre eventi organizzati in Sicilia per celebrare il compleanno
di Wikipedia non sono stati soltanto un momento di festa per i
risultati raggiunti nei primi 25 anni del progetto. Sono stati
anche un’occasione per ribadire l’importanza di Wikipedia oggi e il
ruolo fondamentale dei volontari locali che lavorano sul
territorio, documentando eventi climatici e monitorando i loro
effetti sugli ecosistemi naturali e sulle comunità umane.
Nel corso dell’anno, i wikimediani siciliani continueranno il
loro lavoro di documentazione dei paesaggi protetti partecipando
alla campagna Wiki Loves Earth e organizzando nuovi incontri
dedicati a Wikipedia.
Nel cuore della Lombardia, a Esino Lario,
nasce una storia sorprendente, capace di intrecciare passione e
memoria musicale alla cultura digitale contemporanea: quella
di Martino “Tino” Barindelli e della sua
straordinaria collezione dedicata al mondo dell’opera
del Novecento.
Chi era Tino
Barindelli
Tino Barindelli apparteneva a una famiglia benestante di
Esino Lario. Era un uomo colto, appassionato
di musica classica e profondamente innamorato
dell’opera lirica. Barindelli visse la
musica anche attraverso una fitta rete di
corrispondenze con i grandi protagonisti della scena lirica
internazionale quali cantanti
lirici e direttori d’orchestra che si esibivano nei
principali teatri del mondo. Molti rispondevano
inviando fotografie in costume di scena,
talvolta nei panni di personaggi iconici, accompagnate
da dediche personali, biglietti o
lettere.
Barindelli raccolse e conservò con cura oltre un
migliaio di documenti risalenti al periodo tra gli
anni quaranta e gli anni Sessanta, con alcuni esemplari anche
successivi: ritratti ufficiali realizzati dai teatri in occasione
degli allestimenti operistici, fotografie promozionali, cartoline,
lettere manoscritte.
Si tratta in larga parte di materiali legati a produzioni nei
più importanti teatri lirici italiani e
internazionali, tra cui il Teatro alla
Scala. Molti degli artisti ritratti
ricoprivano ruoli principali e sono
oggi figure enciclopediche, ma non sempre
adeguatamente documentate dal punto di vista iconografico. Se per
alcuni direttori d’orchestra esistono archivi consolidati, molto
più rara è la disponibilità di immagini storiche di cantanti
lirici, soprattutto in costume di scena.
Alla morte di Barindelli, l’archivio è passato agli
eredi. Le nipoti, riconoscendone il valore storico e
culturale, insieme con il Comune di Esino
Lario, hanno avviato un accurato processo di
digitalizzazione, affidandosi a un
fotografo professionista e annotando meticolosamente i dati
relativi a ogni scansione.
Da memoria privata a
patrimonio aperto nelle piattaforme Wikimedia
Grazie all’incontro con Wikimedia Italia, già legata a Esino
Lario per l’edizione 2016 di
Wikimania – il raduno mondiale dei volontari dei
progetti Wikimedia, ospitata dieci anni fa proprio nel comune
lecchese – è stato condiviso l’obiettivo di rendere
accessibile questo patrimonio. Gli eredi della
famiglia Barindelli e il Comune di Esino
Lario hanno deciso di promuovere la pubblicazione dei
materiali in open access.
Le immagini vengono progressivamente caricate
su Wikimedia Commons, corredate di metadati
accurati e collegate alle relative voci
su Wikipedia e Wikidata.
Il lavoro è iniziato nel 2025 con un primo lotto di circa 200
ritratti di soprani. Nel 2026, volontari e staff di Wikimedia
Italia stanno completando l’elaborazione del resto della
collezione.
L’impatto della
digitalizzazione dell’archivio Barindelli
I risultati della digitalizzazione del patrimonio sono già
significativi.
Al 6 febbraio 2026, le immagini
digitalizzate provenienti dalla collezione Barindelli
sono 997. Di
queste, 628 (63%) sono già utilizzate
nei progetti Wikimedia: compaiono 2.804 volte in 2.079
pagine tra Wikipedia e altri progetti collegati,
distribuite su 60 wiki in 56 lingue
diverse.
Le visualizzazioni superano le 200.000 al
mese, segno concreto di come un archivio nato tra le mura
di una casa privata sia oggi diventato uno strumento di conoscenza
a livello internazionale.
Le voci della famiglia Barindelli e
del sindaco di Esino Lario
La trasformazione della collezione Barindelli in patrimonio
pubblico è il risultato di una sinergia tra famiglia e
amministrazione comunale. Ne raccontano il
percorso Paola Febelli, nipote del
collezionista, che ne ha promosso la donazione, e il sindaco di
Esino Lario, Pietro Pensa, che ne evidenzia
il valore storico e identitario per il territorio.
La testimonianza dell’erede
Paola Febelli, nipote di Tino Barindelli
Sotto certi aspetti niente è più predestinato del Caso. Una
mattina di grandi pulizie, come per caso, mi sono ritrovata a
guardare i ricordi di mio zio Tino Barindelli, melomane, che per
tutta la vita aveva collezionato fotografie, meglio se con dedica,
di cantanti lirici e maestri d’orchestra.
Il suo particolare stato di paraplegico gli aveva dato
una enorme quantità di tempo libero per questa sua collezione.
Scriveva una lettera all’artista con la richiesta di foto e dedica
e inseriva una busta preaffrancata per la risposta. In oltre
quaranta anni, aveva collezionato un grandissimo numero di
foto di cantanti lirici e maestri d’orchestra.
Parlatone per caso con un amico, anch’esso melomane,
venivo a sapere che questa “collezione” poteva interessare
moltissimo gli addetti ai lavori in quanto copriva oltre quaranta
anni di attivita musicale in Italia e all’estero. Circa 1200 foto e
una quantità di lettere di risposta ricevute. Una volta catalogate,
prodotto un opuscolo che spiegava la provenienza, in prima istanza
ho pensato di donare il tutto a qualche ente musicale di pregio per
la loro biblioteca.
Pensando però che così facendo avremmo, sotto certi aspetti,
“congelato” il contenuto della collezione in qualche scaffale più o
meno polveroso ….. ho pensato di donare il tutto al Comune di Esino
Lario dove “Zio Tino” aveva vissuto durante la guerra nella casa
paterna e dove poi ha passato gran parte del suo tempo.
Tra l’altro, il Sindaco di Esino Lario Pietro Pensa era un
amico mio dai tempi della gioventù e già negli anni scorsi si era
prodigato per costruire un museo della storia locale tra le varie
attività a favore del territorio, tra le quali mi ricordavo
anche l’organizzazione nell’anno 2016 del raduno mondiale di
Wikipedia proprio a Esino Lario.
Ecco come una serie di coincidenze mi ha portato a incrociare
Wikipedia e le sue preziose pagine.
Il commento di Piero Pensa,
sindaco di Esino Lario
È con profonda emozione e sincero orgoglio istituzionale che
a nome dell’Amministrazione comunale annuncio l’acquisizione
ufficiale della Collezione Tino Barindelli, un patrimonio che
trascende il mero valore archivistico per configurarsi quale
autentico lascito culturale e civile. Con questo atto, la nostra
comunità rende omaggio a Martino “Tino” Barindelli, figura
esemplare capace, partendo da un piccolo borgo montano, di
stabilire un dialogo vivo e fecondo con il panorama artistico
internazionale.
La vicenda umana e culturale di Tino Barindelli rappresenta una
testimonianza straordinaria del fatto che la passione, la curiosità
intellettuale e la dedizione all’arte non conoscono confini
geografici né limitazioni materiali. Attraverso il canale, allora
fondamentale, delle Poste Italiane, egli seppe costruire una rete
epistolare di eccezionale ampiezza e valore, entrando in contatto
diretto con alcune delle più eminenti personalità della musica e
del teatro del Novecento. Tra queste si annoverano nomi
di assoluto rilievo quali Zubin Mehta, Arturo Toscanini, Maria
Callas, Boris Christoff e Wilhelm Furtwängler, i quali risposero
con generosità all’iniziativa di un appassionato collezionista,
inviando fotografie autografate e dediche personali. Tali
materiali costituiscono oggi un corpus documentale di
straordinaria rilevanza storica e artistica.
Per una comunità come Esino Lario, l’acquisizione di questo
patrimonio rappresenta non soltanto un motivo di legittimo
orgoglio, ma anche un’affermazione identitaria: essa ribadisce il
ruolo del nostro territorio quale luogo di cultura, di apertura e
di dialogo. Al contempo, la Collezione Barindelli assume un valore
che supera i confini locali, ponendosi quale risorsa di interesse
per studiosi, ricercatori e appassionati a livello internazionale.
Essa consente infatti di restituire visibilità non solo alle grandi
figure consacrate, ma anche a quegli artisti meno noti che hanno
contribuito in modo significativo alla storia dello spettacolo
e che rischiavano, altrimenti, di essere consegnati
all’oblio.
Desideriamo esprimere la più profonda gratitudine a Paola e
Renata Barindelli per la generosa donazione e per la volontà di
condividere questo patrimonio con la collettività. Grazie altresì
al lavoro di digitalizzazione e alla pubblicazione su
Wikipedia, la collezione è oggi accessibile al pubblico
globale, in linea con i principi della conoscenza aperta. Ogni
documento è stato accuratamente digitalizzato in alta definizione,
al fine di garantirne la conservazione e la fruizione nel
tempo.
In segno di riconoscimento per l’infaticabile opera di Tino
Barindelli, l’Amministrazione ha deliberato l’allestimento
permanente di una selezione significativa della collezione presso
il Cineteatro comunale. Tale esposizione costituirà un
presidio culturale stabile, suscettibile di aggiornamenti
temporanei, ma destinato a mantenere viva la memoria e il valore di
questa straordinaria testimonianza.
Oggi, Esino Lario restituisce al mondo lo sguardo e l’eredità
di un uomo che ha saputo coltivare grandi visioni, trasformando un
piccolo centro montano in un punto di intersezione con la storia
universale dell’arte e dello spettacolo.
Dal 28 al 30 agosto 2026 a Parigi si
terrà State of the Map
2026, il raduno mondiale della comunità OpenStreetMap.
Per l’occasione, Wikimedia Italia stanzia delle borse
di partecipazione per alcuni volontari italiani.
Cos’è State of the
Map
State of the Map è l’incontro
globaledella comunità di
OpenStreetMap, volto a promuovere la crescita dei
dati geospaziali aperti e a rafforzare la comunità della
mappatura libera e collaborativa.
La conferenza, ospitata dalla capitale francese, sarà organizzata
in formato ibrido, permettendo la
partecipazione sia in presenza sia da remoto.
Wikimedia Italia ha reso disponibili delle borse di
partecipazione per facilitare la presenza della comunità
all’evento State of the Map 2026.
Sono previste 10 borse, ciascuna fino a un
massimo di €600, per coprire le spese di
viaggio e alloggio; l’iscrizione all’evento sarà sostenuta
separatamente dall’associazione.
Come richiedere la
borsa per State of The Map 2026
Le borse di partecipazione per State of the Map 2026 mirano
a incoraggiare la presenza dei membri della comunità
italiana dei progetti OpenStreetMap e Wikimedia, con
l’obiettivo di arricchire e promuovere tali iniziative. La
partecipazione dei diversi gruppi all’interno del movimento OSM
contribuirà ad arricchire il raduno e a potenziare gli altri
progetti correlati.
Criteri di
idoneità
Possono candidarsi coloro che soddisfano
i seguenti requisiti:
Essere cittadini o residenti maggiorenni di uno Stato
della Comunità Europea al 1° agosto 2026.
Disporre di un conto corrente presso un istituto con
sede in uno Stato della Comunità Europea per il riconoscimento
degli accrediti.
Avere una conoscenza della lingua inglese almeno di
livello A2 (elementare).
Essere utenti attivi in uno dei progetti
OpenStreetMap e/o Wikimedia in lingua italiana o in altri progetti
nell’ambito della conoscenza libera, del software libero o di
iniziative culturali e associative; in alternativa, avere
l’intenzione di sfruttare quanto acquisito con la partecipazione a
State of the Map per future attività da compiere nei prossimi 12
mesi.
Non possono candidarsi coloro che hanno
già ottenuto una borsa di partecipazione per l’edizione corrente
dalla OpenStreetMap Foundation o da un altro capitolo
OpenStreetMap.
Termini e
comunicazioni
La scadenza per l’invio delle domande è fissata
al 22 marzo 2026 entro le ore 23:59.
L’esito verrà comunicato entro l’8 aprile
2026.
Per ulteriori dettagli sui criteri di selezione, le modalità di
erogazione del finanziamento e gli obblighi del borsista, si prega
di consultare il programma
completo.
La comunità italiana dei mappatori di
OpenStreetMap ha partecipato a “M’illumino di
meno” 2026, scegliendo come progetto del mese la
mappatura dell’illuminazione pubblica e dei
lampioni. L’iniziativa si è svolta completamente online,
coinvolgendo tutte le regioni italiane.
I dati raccolti sono stati resi disponibili e liberamente
riutilizzabili per studiare la distribuzione
dell’illuminazione nelle aree urbane e i suoieffetti sociali e ambientali, con un’attenzione
particolare al tema dell’inquinamento luminoso.
Il contributo della comunità
italiana di OpenStreetMap
Dei circa 178.000 lampioni attualmente presenti su
OpenStreetMap in Italia, ben 76.000 sono stati
mappati nel solo mese in corso, come risulta da Taginfo e dal conteggio
pubblicato sul forum. Proseguendo con questo ritmo, in
un solo mese verrebbe mappato un numero di lampioni pari a
quello inserito nei precedenti vent’anni.
Oltre alla mappatura dei singoli punti luce, sono state
integrate anche informazioni su numerose strade, specificando quali
risultano illuminate e quali no, arricchendo così in modo
significativo il database, come evidenziato su Taginfo.
Sono stati inoltre sviluppati da volontari italiani
diversi strumenti e mappe dedicate, utili per
individuare le aree ancora da mappare, monitorare il numero di
modifiche e visualizzarne l’andamento; ad esempio, il lavoro svolto dal
volontario Giopera. L’iniziativa ha suscitato
interesse anche a livello internazionale: un volontario
statunitense, ispirato dall’attività della comunità italiana, ha
contribuito sviluppando un’ulteriore mappa tematica, come quella
del volontario Watmildon.
La testimonianza del
volontario Giopera
A seguire, riportiamo la testimonianza del volontario italiano
Giopera, che ha condiviso la propria esperienza e
il proprio contributo nell’ambito del progetto.
“Innanzitutto, considero la partecipazione al progetto una
bella attività e una sfida stimolante per la community italiana,
sia in termini di miglioramento della mappa sia per la promozione
della libertà dell’informazione. Attraverso raccolte dati e
campagne di mappatura di questo tipo, è infatti possibile
mettere a disposizione di enti terzi, ricercatori e appassionati un
patrimonio informativo che consenta di svolgere analisi e trarre
conclusioni interessanti, utili sia per lo sviluppo del territorio
sia per una gestione più efficiente. Un esempio, nel
caso dei lampioni, può essere il calcolo dei risparmi derivanti da
un’eventuale conversione di tutte le luci.
Per questo progetto ho scelto di procedere seguendo una
gerarchia stradale: finora mi sono concentrato sulla mappatura di
autostrade, svincoli e strade immediatamente collegate in Veneto.
Le autostrade e le tangenziali sono infatti contesti in cui la
presenza di lampioni è prevedibile in determinate aree,
risultano più facilmente identificabili e offrono maggiori
informazioni per determinarne posizione ed effettiva presenza.
Inoltre, trattandosi di infrastrutture ad alta frequentazione, i
dati inseriti possono risultare particolarmente utili,
contribuendo alla crescita della mappa e al miglioramento
dell’esperienza per l’utente finale.
Come strumento principale utilizzo con grande soddisfazione
JOSM, che adopero quotidianamente e che trovo estremamente
efficiente, soprattutto su un portatile poco performante, perché
consente di eseguire molte operazioni rapidamente. L’editor iD, per
sua natura basato su browser, risulta invece più limitato in
questo senso. Per la parte di controllo qualità (QA), al fine
di verificare di aver aggiunto correttamente i lampioni su tutte le
corsie di entrata e uscita, utilizzo lights.giope.re, un sito che
ho realizzato apportando migliorie tecniche
al progetto
originale. Questo strumento mi consente di
visualizzare nel giro di pochi minuti i lampioni inseriti e di
controllarne la corretta distribuzione nelle varie aree.
Un ulteriore ringraziamento va alle immagini satellitari
fornite da Bing, che grazie alle ombre e alle diverse angolazioni
permettono di identificare con buona precisione la posizione dei
lampioni, oltre alle immagini caricate dai volontari su servizi
come Mapillary, KartaView e Panoramax, che consentono di
verificare la presenza effettiva dei punti luce quasi come se si
fosse sul posto.
Infine, desidero ringraziare Ivan Branco per aver
coordinato finora il progetto del mese e Watmildon per aver
sviluppato e proposto una piattaforma che monitora l’avanzamento
della campagna di mappatura in tutta Italia.”
Il prossimo 12 aprile Wikimedia Italia
parteciperà alla Milano Marathon nell’ambito del
Charity Program, portando
in strada la propria visione di conoscenza libera, accessibile e
condivisa.
Sono già molte le persone che hanno scelto di correre per sostenere i
nostri progetti: ricercatrici e ricercatori, neo mamme,
ingegneri del Politecnico e tanti altri runner che si stanno
allenando e attivando per raccogliere fondi a favore della
conoscenza libera.
È possibile scoprire le loro storie e contribuire alla raccolta
fondi attraverso la nostra pagina su Rete del Dono: https://www.retedeldono.it/progetto/corri-la-conoscenza-libera
Non solo corsa: due maratone per la
conoscenza libera
In occasione della Milano Marathon, vogliamo raccontare al
pubblico l’anima di Wikimedia Italia: cosa facciamo ogni giorno,
quali progetti sosteniamo, chi sono le persone che stanno dietro a
progetti come Wikipedia e OpenStreetMap.
Per questo, accanto alla prova sportiva, organizzeremo
due maratone tematiche aperte al pubblico presso
lo stand di Wikimedia Italia in via Marina (zona Palestro).
Editathon sportiva su Wikipedia
Un’editathon è una “maratona di scrittura”: persone che mettono
a disposizione il loro tempo e le loro competenze per condividere
sapere libero, semplicemente utilizzando il loro computer.
Obiettivi dell’iniziativa:
creare nuove voci di Wikipedia dedicate ad
atleti, discipline e realtà sportive locali;
migliorare e aggiornare contenuti
esistenti;
valorizzare lo sport come strumento di inclusione,
benessere e coesione sociale.
L’attività sarà aperta anche a contributrici e contributori
esperti, che si renderanno disponibili per raccontare ai curiosi
come funziona Wikipedia e svelare cosa significa, concretamente,
contribuire alla più grande enciclopedia libera online.
“Mappa l’accessibilità”, per una
Milano più inclusiva
Accanto alla scrittura, spazio anche alla mappatura con un
mapathon dedicato al tema delle infrastrutture
accessibili.
Un mapathon è una maratona di mappatura
collaborativa: persone che, smartphone alla mano,
percorrono le vie della città e, grazie ad app dedicate, raccolgono
e integrano dati utili a migliorare le mappe libere.
L’obiettivo è arricchire le informazioni relative (tra le altre)
a:
accessi per persone con disabilità
motoria;
presenza di rampe, ascensori e percorsi
accessibili;
parcheggi riservati a persone con
disabilità.
Un contributo concreto per rendere i dati aperti più completi e
utili per tutte e tutti.
Conoscenza libera e inclusione
Le due maratone riflettono la nostra visione: costruire
conoscenza aperta, condivisa e accessibile, capace di generare
inclusione e partecipazione.
Partecipare alla Milano Marathon Charity Program significa
rafforzare questo impegno, mettendo competenze, energia e passione
al servizio della comunità.
Nei prossimi giorni pubblicheremo tutte le informazioni
dettagliate per partecipare alle attività allo stand di via
Marina.
Gennaio si è aperto con un’ondata di notizie, eventi e finali
attesissimi che hanno spinto migliaia di lettori a cercare
approfondimenti su Wikipedia. Dalla conclusione di una delle serie
più amate degli ultimi anni alle tensioni geopolitiche
internazionali, passando per la cronaca, il cinema e il calcio, le
pagine più consultate raccontano un mese intenso e ricco di svolte.
Con il contributo dei volontari Oltrepier e Paul
Gascoigne, abbiamo raccolto e commentato le dieci voci
più visualizzate su Wikipedia in italiano tra
il 1° e il 31 gennaio 2026, tracciando una mappa degli
interessi che hanno segnato l’inizio del nuovo anno.
Il nuovo anno ha segnato il momento dell’addio definitivo alla
città di Hawkins, a quasi dieci anni dall’esordio di una serie che
ha lasciato un’impronta profonda nell’immaginario collettivo.
L’episodio conclusivo della quinta
stagione (#10), rilasciato negli Stati
Uniti allo scoccare della mezzanotte del 31 dicembre
e trasmesso in
Italia nella notte di Capodanno, ha catalizzato
l’attenzione di milioni di spettatori, ansiosi di capire
se Undici e i suoi
amici sarebbero riusciti a sconfiggere il temibile Vecna. E fra chi
voleva ripassare la storia prima di iniziare gli ultimi episodi e
chi cercava spiegazioni sul finale, la voce è diventata un punto di
riferimento inevitabile, conquistando così il primo posto in
classifica.
Al secondo posto troviamo il celebre stilista italiano Valentino
Garavani, scomparso il 19
gennaio all’età di 93 anni. Nato a Voghera, Valentino iniziò la propria carriera
negli anni Cinquanta lavorando presso gli atelier di Balenciaga, Jean Dessès
e Guy Laroche. Nel 1959 si
mise in proprio, aprendo un atelier a Roma con l’aiuto economico del padre; dopo
un inizio difficile, riuscì ad affermarsi nel mondo della moda
grazie a uno stile innovativo ed elegante, che ha reso i suoi abiti
emblema di lusso e raffinatezza. Fra le principali eredità del suo
lavoro si segnala il celebre “rosso Valentino”, una particolare
sfumatura divenuta iconica.
La scalata di Checco
Zalone nella classifica dei film con maggiori incassi
grazie a Buen Camino (#7) è
stata seguita con attenzione dal pubblico italiano, che ha
consultato più volte la lista aggiornata per monitorare il
record.
Il ritorno al cinema di Luca Medici, in arte Checco Zalone,
avvenuto lo scorso Natale, ha
segnato diversi punti di svolta nella carriera del comico barese:
il ricongiungimento con il regista Gennaro Nunziante e
il passaggio a una nuova casa produttrice. Il film ha stabilito un
doppio record di incassi, superando prima Quo vado? e poi
infrangendo il primato detenuto da Avatar,
conquistando così il maggiore incasso di
sempre in Italia (#6).
L’attaccante olandese, arrivato alla Roma in prestito
dall’Aston
Villa il 16 gennaio, si è subito candidato a diventare il
colpo più importante del
calciomercato invernale, segnando
all’esordio contro il Torino e
guadagnandosi un posto da titolare. Dopo gli inizi al PSV Eindhoven e le
esperienze con Borussia
Dortmund e Aston Villa, Malen cerca ora continuità nella
Capitale.
Come per la voce al primo posto, anche la lista degli episodi
della quinta stagione di Stranger
Things è stata al centro dell’attenzione dei
fan, desiderosi di orientarsi tra titoli, date di uscita e sviluppi
narrativi del gran finale.
Riportiamo oggi un aggiornamento in merito al progetto
collaborativo del 2025 tra Wikimedia Italia e
il Touring Club
Italiano. Il presente articolo è
stato pubblicato per la newsletter
GLAM nel mese di dicembre 2025,
a firma di Marta Arosio,
Responsabile delle relazioni con le Istituzioni
Culturali di Wikimedia Italia.
Le Guide Rosse d’Italia su
Wikimedia Commons
Nel corso del 2025, la collaborazione tra Wikimedia
Italia e il Touring Club Italiano ha raggiunto un
nuovo e importante traguardo, concentrandosi su una delle
pubblicazioni più iconiche e autorevoli del TCI:
le Guide Rosse d’Italia.
In continuità con il lavoro svolto negli anni precedenti sulla
cartografia storica, archivi fotografici e materiali visivi
relativi all’arte, alla cultura e all’industria italiane, il
progetto di quest’anno ha avuto come
obiettivo la digitalizzazione e
la pubblicazione in formato aperto delle mappe contenute nelle
Guide Rosse dedicate alla Lombardia e al Veneto, oltre che
nelle guide autonome di Milano e Venezia. La
raccolta comprende mappe territoriali, piante urbane e di
quartiere, nonché planimetrie dettagliate di monumenti e complessi
architettonici. Tutti questi materiali sono
oggidisponibili su Wikimedia Commons con
licenza libera.
Le mappe e le planimetrie architettoniche provenienti da una
fonte autorevole come il Touring Club Italiano rappresentano
una risorsa di grande valore per l’ecosistema Wikimedia.
Per ragioni legate al diritto d’autore, infatti, il materiale
cartografico disponibile sui progetti Wikimedia è spesso molto
datato, oppure realizzato direttamente dagli utenti: una pratica
estremamente preziosa, ma non sempre supportata da fonti editoriali
riconosciute. L’apertura delle mappe curate e
pubblicate dal TCI costituisce quindi un significativo salto
di qualità, contribuendo a rafforzare l’affidabilità degli
articoli di Wikipedia e a migliorarne accuratezza e
verificabilità.
Il caricamento dei materiali si è concluso nell’ottobre 2025 e i
primi dati di utilizzo dimostrano chiaramente l’impatto del
progetto. Le mappe sono attualmente utilizzate in 759
pagine in 38 edizioni linguistiche
diverse, e hanno totalizzato oltre un milione
di visualizzazioni nel solo mese
di novembre 2025.
Tra i contenuti più consultati spiccano la mappa di
Cortina d’Ampezzo e la pianta del Duomo
di Milano. La prima ha acquisito particolare visibilità
alla luce delle prossime Olimpiadi
invernali, mentre la seconda conferma come planimetrie
autorevoli di monumenti simbolo possano diventare punti di
riferimento fondamentali per l’enciclopedia libera.
Il progetto del 2025 dimostra ancora una volta che la
collaborazione tra le istituzioni
GLAM e il movimento Wikimedia non si limita
all’apertura delle collezioni, ma passa anche attraverso scelte
editoriali consapevoli e l’attenzione alla qualità e al riutilizzo
dei materiali condivisi, a beneficio delle comunità globali di
lettori e volontari.
Il lavoro sulle Guide Rosse proseguirà anche nei prossimi
anni, con l’obiettivo di ampliare progressivamente la disponibilità
di questo straordinario patrimonio cartografico e consolidarne il
ruolo come risorsa condivisa per la ricerca, l’istruzione e la
diffusione della conoscenza.
La Protezione Civile del Friuli Venezia Giulia ha avviato un
progetto innovativo di rilievo del territorio a 360
gradi, con l’obiettivo di migliorare la qualità dei dati
cartografici e supportare in modo sempre più efficace la gestione
delle emergenze.
L’iniziativa si basa sull’utilizzo di un veicolo fuoristrada
attrezzato con sistemi di ripresa panoramica e strumenti di
georeferenziazione avanzati, in grado di raccogliere informazioni
dettagliate lungo la rete stradale regionale.
Le immagini e i dati acquisiti vengono integrati nei sistemi
informativi utilizzati dal Numero Unico di Emergenza
112, consentendo agli operatori di localizzare con
maggiore precisione il punto di origine delle chiamate e di
pianificare interventi più rapidi e mirati, anche in aree isolate o
difficilmente individuabili.
Gli strumenti e la
condivisione su OpenStreetMap
Alcuni degli strumenti utilizzati per l’analisi delle fotografie
acquisite e per eseguire l’aggiornamento della cartografia sono
quelli messi a disposizione da OpenStreetMap, come ID
Editor o JOSM.
Un aspetto centrale del progetto è proprio
la condivisione dei dati raccolti su
OpenStreetMap, il database geografico libero che
rappresenta una delle più grandi risorse di mappatura
globale.
Attraverso questo contributo, vengono aggiornate e arricchite
informazioni fondamentali come numerazione civica,
segnaletica stradale, sensi di marcia, accessi,
punti di interesse e caratteristiche della
viabilità. Dati che risultano utili non solo per i
servizi di emergenza, ma anche per cittadini, enti locali e
sviluppatori.
La scelta di puntare anche su OpenStreetMap rafforza il valore
pubblico dell’iniziativa: i rilievi non rimangono confinati a un
uso interno, ma diventano parte di un patrimonio
informativo condiviso, costantemente aggiornabile e
riutilizzabile. In questo modo, il progetto contribuisce a
migliorare l’affidabilità delle mappe digitali e a rendere il
territorio più leggibile e sicuro per tutti.
I risultati raggiunti
Ad oggi, i rilievi hanno coperto ben 480
chilometri di strade, dando vita a una straordinaria
raccolta di 135.000
fotografieimmersive a 360° che
raccontano, con precisione e dettaglio, ogni metro del territorio
esplorato. Le immagini hanno già suscitato grande interesse,
con oltre 270.000 visualizzazioni e
download da parte degli utenti.
L’integrazione tra tecnologie di rilievo avanzate, sistemi di
emergenza e dati aperti rappresenta quindi un esempio concreto di
come l’innovazione possa tradursi in benefici reali per la
comunità, unendo efficienza operativa e apertura dei dati.
L’altro giorno, parlando di
Grokipedia, ho accennato al fatto che Wikipedia deve per forza
fare i conti con l’intelligenza artificiale. Qui provo a spiegare
come io vedo la situazione. Premetto che tutto quello che scrivo
riflette esclusivamente il mio pensiero, non quello della comunità
di Wikipedia in lingua italiana, di Wikimedia Italia o tanto meno
della Wikimedia Foundation.
Il primo punto da considerare è capire perché
usare l’IA. Attenzione: non sono luddista, e non ho nulla a priori
contro il suo uso. Spero però che nessuno creda davvero che gli LLM
siano creativi, riuscendo quindi a scrivere qualcosa di davvero
nuovo e non rimasticato (pur molto bene): d’altra parte se ci
riuscissero il testo sarebbe considerato una ricerca originale (RO)
che in Wikipedia è assolutamente vietata, perché tutto deve essere
verificato indipendentemente. (Nota: mentre sto scrivendo c’è una
curiosa convergenza tra utenti destrorsi e sinistrorsi che stanno
cercando di far passare il concetto che le ricerche originali si
possono usare). E taciamo sul fatto che le “ricerche originali”
degli LLM sono spesso cose che non stanno né in cielo né in terra:
ultimamente abbiamo avuto l’utente LugAIno che scriveva testi più o
meno casuali sulla città di Lugano. Aggiungiamo poi che c’è il
gtrande rischio che il testo generato, specialmente se si parla di
un argomento di nicchia, potrebbe essere troppo simile alla fonte
originale e pertanto essere una violazione di copyright. Non sapere
quali siano le fonti non ci permette nemmeno di scoprirlo.
Da qui si passa al secondo punto: Wikipedia richiede di inserire
le fonti delle affermazioni indicate, cosa che di solito non si ha
con gli LLM: ci sono delle eccezioni, come Copilot e Perplexity, ma
anche se loro affermano di indicare da dove hanno preso le
informazioni questo non significa molto. L’altra settimana per
esempio, chiedendo a Perplexity quando una chiesa milanese era
stata eretta come basilica minore, Perplexity mi “citò una fonte”
secondo cui il decreto relativo era stato emesso nel luglio 2025…
da papa Francesco.
Ciò detto, non c’è nessuna ragione intrinseca per vietare tout
court l’uso dell’IA per migliorare le voci: quello che serve è che
non si copincolli il testo creato ma lo si controlli e lo si
corregga dove necessario. Alcuni esempi di uso dell’IA? Il recupero
di fonti (reali…) che possono utilmente ampliare quanto già
scritto; la revisione di un testo in modo che sia più scorrevole;
la traduzione di quanto già presente in un’altra edizione
linguistica di Wikipedia (ma in questo caso ricordatevi di citarla
come fonte!). L’IA è molto brava a fare il lavoro sporco, proprio
perché in pancia ha una quantità enorme di informazioni.
L’importante è appunto non dimenticarsi che l’intervento umano
continua a essere necessario.
La corte di appello di Stoccarda
ha confermato che il Codice Urbani vale solo all’interno
dell’Italia. Il codice Urbani è quello che afferma che un’opera
anche fuori copyright perché vecchia di secoli può essere soggetta
a “una tutela”; questo significa che se io voglio usare un’immagine
dell’uomo vitruviano di Leonardo devo chiedere a chi gestisce
l’immagine il permesso, e presumibilmente pagare per il diritto di
usarlo. Bene: Ravenburger aveva prodotto un puzzle con l’uomo
vitruviano, il ministero della Giustizia e le Gallerie
dell’Accademia di Venezia hanno fatto causa, Ravensburger ha fatto
una controcausa, e il risultato è che il puzzle può essere venduto
tranquillamente al di fuori dell’Italia. La Corte non si è espressa
sulla legalità del codice Urbani ripetto alla direttiva copyright,
né poteva farlo; in pratica ha detto “non ci curiamo di cosa fate
in Italia, affaracci vostri”.
Non credo che il nostro governo cambierà posizione: questo
significa che noi italiani saremo cornuti e mazziati. Chissà se
chiederanno anche di oscurare le immagini di Wikipedia se ci si
connette dall’Italia…
È in corso di discussione alla Camera la proposta
di legge 2224, presentata da due deputati di Fratelli d’Italia
e due di Forza Italia, avente titolo “Modifiche alla legge 22
aprile 1941, n. 633, in materia di tutela del diritto d’autore
relativo alle fotografie”. Cosa dice questa proposta? Facciamo
prima un passo indietro, e vediamo cosa dice attualmente la legge
sul diritto d’autore.
Ci sono due tipi di tutela delle fotografie (il termine è da
intendersi in senso molto lato: ovviamente non c’è più bisogno di
avere pellicola o simili per avere una foto, pensate alle foto
fatte con il furbofono). Da un lato ci sono le fotografie
artistiche, dove si sottintende un atto di creatività del
fotografo: queste fotografie sono equiparate ai libri, nel senso
che hanno la stessa tutela (il copyright scade settant’anni dopo la
morte dell’autore). Dall’altro ci sono le fotografie che non hanno
creatività e sono semplicemente di tipo descrittivo: questa
categoria comprende anche i singoli fotogrammi cinematografici e le
foto di opere d’arte. Queste immagini hanno una protezione che dura
vent’anni. La proposta di legge si occupa solo di quest’ultimo tipo
di fotografie, e porta da venti a settanta anni la loro
protezione. In altre parole, non potremmo per esempio usare per
altri sette-otto anni una foto che mostra una strada cittadina nei
primi anni ’60 per mostrare come i centri storici erano intasati
dalle auto.
Ribadisco: stiamo parlando di foto che per definizione del
legislatore non hanno alcuna creatività, che dovrebbe essere il
concetto su cui si basa tutto il diritto d’autore. A questo punto
mi sa che il prossimo passo sarà la tutela degli scatti automatici,
perché si dirà che c’è comunque l’autorialità di chi ha posizionato
la fotocamera in quel punto e poi ha definito l’algoritmo che
decide il momento in cui la foto viene scattata…
Ma c’è una cosa ancora più ironica. L’unico motivo che io vedo
alla base di questa proposta di legge è che qualcuno ritiene che in
questo modo i fotografi potrebbero guadagnare tanti soldi con i
diritti di queste foto, che adesso possono essere usati dopo
vent’anni che non sono pochi ma nemmeno troppi: come ho detto, le
foto creative sono già tutelate dalla legge. Bene. Pensateci un
attimo. Stiamo parlando di foto puramente descrittive, senza nulla
di artistico. Se io avessi bisogno di un’illustrazione di questo
tipo e dovessi pagare per usarla, farei molto prima a generare
un’immagine con l’intelligenza artificiale. Il fatto stesso che
questa immagine è una mera descrizione elimina a priori i problemi
di una possibile violazione di copyright, e in questo modo non solo
non pago nessuno ma non devo neppure aggiungere una didascalia
indicante l’autore. Non so che ne pensiate voi, ma per me una legge
come questa sembra solo un boomerang.
Leggo
su Slate che la Heritage Foundation, il think tank americano
che sta gestendo il famoso Project 2025 che tanto piace a Trump,
vuole “identificare e prendere di mira” gli utenti di Wikipedia che
secondo loro “abusano della loro posizione” su Wikipedia. Il motivo
del contendere dovrebbe essere il fatto che quegli utenti sono
filopalestinesi.
Non entro sulla neutralità o meno delle voci in questione, che
non ho nemmeno guardato. Sono almeno quindici anni che affermo che
Wikipedia non può dare la verità, ma al più la verificabilità di
quello che scrive (e sì, lo so che a volte non riesce nemmeno a
fare quello). Quello che è proccupante è l’intimidazione degli
utenti. Come sapete, anche quando nell’enciclopedia non si scrive
come anonimi quello che si legge come autore è solo il nickname
scelto: nel mio caso per esempio io mi firmo “.mau.”, con
scarsissima fantasia. Il nickname, oltre che essere figlio della
cultura di rete degli anni ’90, serve anche nel caso di testi che
potrebbero generare reazioni anche sulla persona: chi scrive su
argomenti delicati potrebbe quindi decidere di farlo sotto
pseudonimo, cosa che non dovrebbe nuocere a Wikipedia perché si
immagina che le affermazioni inserite abbiano le fonti a supporto e
altrimenti verrebbero tolte, nome vero o falso che abbiano.
Io indico esplicitamente sulla mia pagina utente il mio nome e
cognome, ma io non scrivo su temi caldi. Inoltre io sono da così
tanti anni in rete e ho scritto pubblicamente così tante cose che
trovare informazioni su di me è banale, e comunque parto sempre dal
principio che tutto quello che scrivo potrà essere usato contro di
me, e quindi sto attento a quello che scrivo. Ma appunto non è
troppo difficile trovare informazioni su qualunque persona scriva
in rete, se si cerca con sufficiente sforzo: tutto questo è il
doxxing, e ne vediamo esempi tutti i momenti. Anche nel nostro
piccolo circola una lista di “veri nomi di amministratori di
Wikipedia in italiano” (con alcuni errori), tanto per dire.
Il fatto è che il doxxing è MOLTO pericoloso, sicuramente molto
più della boutade di Musk che offre un miliardo di dollari a
Wikipedia se cambierà il nome in Dickopedia. (Poi uno si può
chiedere perché rosica così tanto, ma la gente è spesso strana). Io
preferisco una Wikipedia poco perfetta a una Wikipedia ingessata,
anche se la Heritage Foundation avesse ragione sulla mancata
imparzialità di quelle voci: si comincia così e non si sa mai dove
si finisce, anzi lo si sa benissimo.
Bisogna dire che i giudici italiani sono coerenti.
Anche nella causa per l’uso non autorizzato dell’immagine del duca
d’Este su un aceto balsamico, la corte d’appello di Bologna
ha dato ragione al ministero della Cultura: non importa se le
immagini sono di opere ovviamente fuori copyright, e non importa
nemmeno se sono semplici immagini e non gli originali: se la vuoi
usare per scopi commerciali, devi avere l’autorizzazione relativa
(e immagino sganciare soldi, che ce n’è sempre bisogno). Per
fortuna io non ho scopi commerciali né diretti né indiretti, quindi
posso lasciare l’immagine incriminata.
Avrei forse capito se l’autorizzazione fosse necessaria per
evitare usi distorti, anche se si potrebbe partire con una
discussione sulla possibilità o meno di parodia. Ma non pare il
caso, visto che si afferma che questi beni, una volta usati per
lucro, perderebbero il loro valore come beni riconosciuti e
protetti dalla legge. Ma questo, almeno a mio parere, dovrebbe
allora valere anche per gli usi non a fini di lucro. Peggio ancora,
il Codice dei Beni Culturali nasce (lo dice esso stesso) per
“preservare la memoria della comunità nazionale e del suo
territorio e promuovere lo sviluppo della cultura”, in accordo
all’articolo 9 della Costituzione.
Continuo a pensare che se questa è l’idea del MiC almeno siano
coerenti e vietino tutti gli usi pubblicitari del patrimonio
culturale italiano, a partire
dai loro. Mi chiedo solo quando qualcuno verrà a bloccare l’uso
di quelle immagini su Wikipedia, visto che la licenza prevede il
riuso commerciale e – fatto salvo per le opere fotografate per Wiki
Loves Monuments – non mi pare proprio sia stata richiesta
un’autorizzazione e qiundi non importa se quelle immagini sono solo
per motivi di studio e ricerca.
Purtroppo pare che Totò Schillaci abbia avuto una
recidiva del tumore al colon che l’aveva colpito. Purtroppo la
mamma dei cretini è sempre incinta, e un utente anonimo oggi alle
15 aveva modificato la voce di Wikipedia sul protagonista di Italia
90, indicandone la morte. La falsa notizia è stata tolta un paio
d’ore dopo da un altro utente anonimo, non prima che Repubblica
scrivesse ” Addirittura il profilo di Wikipedia, come spesso
accade, aveva proposto un aggiornamento di pessimo gusto
annunciando la scomparsa nel 59enne proprio in data 8 settembre
2024.” (sì, la frase non ha senso: se il vandalo ha scritto oggi e
l’articolo è di oggi, specificare la data non serve a nulla).
L’utente che ha inserito la morte di Schillaci è un siciliano
non meglio identificabile, almeno con le informazioni pubbliche che
io come tutti voi ho a disposizione. Invece si sa qualcosa di più
dell’utente che ha tolto la data di morte, come potete vedere
dall’immagine: si connetteva dalla sottorete pubblica del
Messaggero, e presumibilmente è un giornalista. Per quel poco che
può valere, voglio ringraziarlo pubblicamente.
Per la quarta volta la Wikimedia Foundation
non è stata accettata come membro osservatore WIPO. (Ne avevo già parlato
due anni fa, quando si era provato a chiedere di entrare come
osservatori i capitoli nazionali).
Per la quarta volta il veto è arrivato dalla Cina.
Direi che non c’è molto da aggiungere.
Mi ero perso
questo articolo di Capodanno, che raccontava di come un giudice
di pace aveva dato torto alla SIAE in un caso in cui una rivista
aveva pubblicato delle foto di opere di autori contemporanei ed era
stata citata a giudizio perché non aveva pagato i diritti: nella
sentenza il giudice ribadì “il principio cardine della legge sul
diritto d’autore, in base alla quale è libero l’uso delle immagini
ai fini di critica e discussione e purché non costituiscano
concorrenza all’utilizzazione economica”.
Mi ero anche perso (occhei, non è che io legga più tanto spesso
Repubblica
questo articolo di mercoledì, dove il gruppo GEDI si lamentava
perché giornali e riviste – ma anche i musei – faticavano a sapere
quanto avrebbero dovuto pagare per l’uso delle immagini, e in caso
il preventivo arrivasse era esorbitante.
Ora il presidente della SIAE Salvatore Nastasi
annuncia che le cose cambieranno: «Nei prossimi giorni proporrò
al consiglio di gestione della Società una soluzione che rispetti
le norme ma che consenta di mettersi al passo coi tempi e in linea
con le principali nazioni europee. Va infatti ricordato che in
Europa ogni Paese tratta questo argomento in maniera diversa».
Vi siete accorti di una cosa? Nastasi non parla di legge, anche
perché come citato sopra il testo della legge parla chiaro: se stai
raccontando di una mostra (diritto di cronaca) e usi immagini che
non possono in pratica essere rivendute come opere tu
hai il diritto di farlo. Nastasi sta dicendo che la SIAE
eviterà benignamente di chiederti i soldi, sapendo che citarti a
giudizio porterebbe a un’ulteriore sconfitta: certo, tra un paio
d’anni, ma gente tignosa ce n’è sempre. D’altra parte il punto è
sempre lo stesso: gli autori, soprattutto quelli piccoli che
ottengono solo le briciole e presumibilmente non vedono nemmeno un
euro di questi diritti che finiscono in un unico calderone, ci
guadagnano di più a essere citati in un articolo di giornale o
nella brochure di una mostra oppure nel modo che la SIAE persegue
attualmente?
D’altra parte è una vita che Wikipedia aspetta un decreto
attuativo che specifichi quale sia la bassa risoluzione per le
immagini ammessa dal comma 1 bis dell’articolo 70 della legge sul
diritto d’autore, e immagino che finché ci sarà la SIAE potremo
aspettare ancora una vita o due…
L’anno scorso un tribunale italiano
aveva stabilito che Ravensburger doveva pagare i diritti allo
stato italiano se voleva fare un puzzle raffigurante l’Uomo
vitruviano di Leonardo, insomma la figura che vedete su una faccia
delle italiche monete da un euro. Come fa a essere sotto copyright?
forse vi chiederete. La risposta è “no, non è ovviamente sotto
copyright né lo è mai stato, ma lo Stato Italiano nella sua
indefinita saggezza ha deciso che le opere da esso possedute non
possano essere riprodotte se non pagando al suddetto Stato un
balzello. Tutto questo è stato definito più volte da governi di
ogni colore, dal Codice Urbani sotto la buonanima di Berlusconi
all’Art Bonus di Franceschini fino agli attuali tariffari
(oggettivamente da poco ridotti di costo) con l’attuale
governo.
Qualche giorno fa, però, una corte di Stoccarda
ha sostanzialmente detto “In Italia potete fare quello che vi
pare, o quasi: ma non potete pretendere che all’estero si rispetti
quella che è una vostra legge locale”. Qual è il risultato pratico?
Lo Stato (cioè noi) ha sprecato un po’ di soldi per fare un’inutile
causa in Germania; Ravensburger e gli altri si limiteranno a non
vendere in Italia cose basate su opere d’arte italiana; e noi
rimarremo cornuti e mazziati. Ma forse è tutta una manovra
dell’attuale governo, che si sta fregando le mani all’idea che
potrà autarchicamente rafforzare l’italica filiera con produttori
nostrani felicissimi di pagare per presentare alla nazione la
nostra passata ingegnosità.
Perlomeno dal punto di vista di Wikipedia siamo un po’ più
tranquilli: l’immagine dell’Uomo vitruviano può tranquillamente
restare, e se noi italiani non potremo usarla a fini commerciali
qualcuno se ne farà una ragione.
(l’immagine è ovviamente un particolare dell’Uomo
vitruviano, vedi
Wikimedia Commons)
Piergiovanna Grossi è un’attiva wikipediana. Ma è anche
una professoressa a contratto e una ricercatrice, e le è capitato
di scrivere un articolo per una rivista locale di
settore un articolo sull’attribuzione dell’ex
Oratorio del Montirone ad Abano Terme, il tutto corredato con
due foto che lei stessa aveva scattato all’archivio di Stato di
Venezia. Bene: dopo aver pagato 16 euro per un preventivo, ha
ancora dovuto sborsare 2 (due) euro per il privilegio di poter
scattare e utilizzare due foto… oltre ad altri 32 euro di marche da
bollo.
Il tutto è stato
raccontato la scorsa settimana sul Corriere da Gian Antonio
Stella (al quale ho un solo appunto da fare. Mi sta anche bene che
“è ovvio che l’Italia ha il dovere di mettere dei paletti contro
l’uso di foto del David di Michelangelo con delle sneakers ai piedi
o del Bacco di Caravaggio con uno smartphone in mano”: ma per
quello basta un decreto ministeriale che vieti un uso non
documentale delle immagini.) La beffa ulteriore, se ci fate caso, è
che dopo tutto il carteggio burocratico con la direttrice i soldi
che vanno all’archivio di Stato sono appunto 2 (due) euro: il resto
se l’è intascato lo Stato. Insomma, non siamo neppure alla storia
del
puzzle Ravensburger (che finirà con il produttore che dovrà
pagare la sanzione e si guarderà bene da produrre altri puzzle con
opere site in Italia, e lo stesso capiterà con tutti gli altri:
ottima pubblicità per il nostro patrimonio artistico).
Il ministro Sangiuliano che ha emanato il decreto in questione è
solo l’ultimo esponente di una classe politica che è convinta non
solo che il patrimonio artistico sia un bancomat, ma anche appunto
che si pubblicizzi da solo. Beh, non penso che l’ex Oratorio del
Montirone sarà molto visitato, pubblicità o non pubblicità: ma
proprio per questo è ancora più sconcertante la richiesta di un
balzello…
Siamo in estate, non che molto da dire, e così
Carlo
Lottieri spiega sul Giornale (nella sezione”spettacoli”, chissà
come mai) “Così
Wikipedia è diventata il baluardo del conformismo“. Bisogna
ammettere che Lottieri di conformismo ne sa a pacchi: il suo
articolo precedente di domenica si intitola infatti
“Così l’università è diventata il regno del conformismo”.
Quando hai un bel titolo, perché non sfruttarlo? Io avrei altro da
fare, ma sono in spiaggia, fa caldo e per rilassarmi un po’ mi sono
messo a commentarlo punto per punto.
Cominciamo da quando Lottieri racconta che
Wikipedia nacque da un’intuizione libertaria. Secondo lo stesso
Jimmy Wales, che aveva seguito un corso di teoria economica alla
Auburn University, fu la lettura dell’economista Friedrich A. von
Hayek a suggerire l’ipotesi di questa enciclopedia on line di cui
tutti possono essere i redattori.
Beh, non è proprio così. Inutile dire che l’articolo non
contiene nessuna fonte per le affermazioni di Lottieri: mica sta
scrivendo Wikipedia. La fonte ve l’ho
trovata io e dice questo: “to share and synchronize local and
personal knowledge, allowing society’s members to achieve diverse,
complicated ends through a principle of spontaneous
self-organization.” e ancora “When information is dispersed (as it
always is), decisions are best left to those with the most local
knowledge.” Tenete a mente soprattutto questa seconda frase. (poi
io sono convinto che quella di Jimbo sia una razionalizzazione a
posteriori: ricordate che Wikipedia nasce come testo di lavoro per
scrivere Nupedia che era tutto meno che autoorganizzata).
Nella più classica costruzione di una polemica, Lottieri
continua scrivendo
Sul piano delle informazioni si può essere ragionevolmente
fiduciosi che Wikipedia sia credibile, anche grazie al costante
monitoraggio riservato a ogni lemma.
(Occhei, i lemmi sono in un dizionario e non in un’enciclopedia,
ma evidentemente il liberismo non fa di queste distinzioni) Non che
questo sia vero, come sanno tutti quelli che passano tanto tempo su
Wikipedia, ma tant’è. Ma poi continua
È però evidente che tra gli autori (tra coloro che
spontaneamente e senza remunerazione redigono i testi) è più facile
trovare professori di scuola media invece che artigiani,
bibliotecari invece che imprenditori, e via dicendo. I primi hanno
più tempo a disposizione e spesso si ritengono adeguatamente
competenti per trattare questioni di diritto, metafisica,
sociologia, letteratura spagnola e via dicendo.
E qui si cominciano a vedere le sue fallacie. Per chi “è
evidente”? Perché “è evidente?” Dando per buono che imprenditori e
artigiani abbiano meno tempo a disposizione perché loro devono
tenere in piedi l’economia – ma vi assicuro che gli imprenditori ci
sono eccome, solo che l’unica conoscenza locale che paiono avere è
quella del loro CV, e per le regole di Wikipedia in lingua italiana
i CV vengono cancellati senza se e senza ma – cosa gli fa dire che
loro si ritengono competenti per tutto? Il tutto senza contare che
Wikipedia da buona enciclopedia raccoglie e organizza informazioni
altrui, e le competenze per organizzare l’informazione sono molto
più semplici da ottenere rispetto a quelle per crearla.
Continuiamo:
Ne discende che nelle voci dell’enciclopedia on line troviamo
uno spirito da servizio pubblico che si converte in un costante
tono censorio verso ogni eresia.
Lo spirito da servizio pubblico c’è, tranne per i tanti che
ritengono di essere gli unici depositari della verità. Perché si
convertirebbe in un tono censorio contro ogni eresia? Non ci è dato
di sapere. Forse è perché
Va aggiunto, inoltre, che esiste un comune sentire che unisce la
maggior parte di quanti hanno letto, nel corso della loro vita, un
certo numero di libri.
Me l’avevano sempre detto, che leggere troppi libri fa male. La
conoscenza locale si ottiene lavorando, mica leggendo! Non può poi
mancare il solito attacco frontale:
[…] Si tratta dei cosiddetti «amministratori», a cui spetta
anche di decidere in un senso o nell’altro quando le divergenze si
fanno ingestibili. Basta leggere qualche discussione per
comprendere che si tratti per lo più di quella piccola porzione
della popolazione che, in Italia, quando al mattino va all’edicola
compra La Repubblica oppure il Corriere della Sera.
Per quanto mi riguarda, ho smesso da un pezzo di leggere
giornali italiani se non per qualche articolo come questo che mi
viene segnalato; ho sentito qualche altro sysop e sono tutti sulla
mia linea, anche perché quando uno ha lavorato un po’ su Wikipedia
comincia a non fidarsi troppo di qualunque notizia.
Il risultato è una mancanza di senso critico che rende Wikipedia
assai sbilanciata a favore di talune posizioni.
Altra affermazione apodittica. Anche ammettendo il percorso
logico “essendo gente che legge solo Repubblica e Corriere le loro
posizioni sono spiaggiate sul mainstream”, faccio notare come gli
amministratori (il soggetto della frase) non scrivono loro le voci
su Wikipedia. Possono al più cancellare una voce, ma non piegarla
eliminando “il senso critico “. Lo fanno in maniera coercizione
bloccando chi non la pensa come loro? Se fosse vero basterebbe fare
esempi espliciti. Ricordo che la storia di una voce è pubblica, e
si può vedere se c’è una campagna sistematica.
L’unico punto su cui devo dare ragione sul metodo a Lottieri è
quello che scommetto gli sta davvero a cuore (oppure su cui gli è
stato chiesto di scrivere): quando cioè si lamenta che nella voce
sul riscaldamento globale
In effetti, le tesi di quanti sono scettici al riguardo (premi
Nobel inclusi) non sono citate: neppure per essere contestate.
Almeno a ora,
la sezione relativa non riporta nulla al riguardo, e la cosa è
contro le linee guida che richiedono che opinioni in minoranza
siano riportate con il rilievo corretto (minimo in questo caso,
perché la minoranza è minima, ma non nullo). Al solito, Lottieri si
è però dimenticato di fare nomi e ho dovuto mettermici io. A parte
la vecchia storia di Rubbia, immagino si riferisca a
John Clauser. (Apprezzerete che io abbia scelto un link a suo
favore, spero). Non so se notate un fil rouge: Rubbia è un fisico
teorico delle particelle, Clauser un fisico quantistico.
Sicuramente grandi scienziati, ma la loro “conoscenza locale” della
climatologia sarà probabilmente superiore alla mia ma ben lontana
dall’essere a tutto campo. E allora che diavolo c’entra Hayek?
Chiaramente nulla, almeno per quanto riguarda l’organizzazione di
Wikipedia. Spero che a quella voce si aggiunga un capoverso sulle
attuali teorie non mainstream, che tra l’altro mi pare siano
cambiate nel tempo (prima si negava il contributo antropico, ora si
dice che non è rilevante e comunque le variazioni che vediamo sono
normali se non ci si limita a considerare gli ultimi 150 anni), ma
anche se ci sarà non credo Lottieri sarà contento.
Termino pensando male e facendo peccato. Ora il Giornale è della
famiglia Angelucci che ha sicuramente il dente avvelenato contro
Wikipedia. Aspettatevi tanti altri articoli così.
Aggiornamento: mi è stato fatto notare che esiste la voce
Controversia sul riscaldamento globale. Se però non c’è un
collegamento diretto dalla sezione della voce principale,come fa il
povero utente (io o Lottieri) a trovarla?
Nel silenzio generale, il mese scorso è stato approvato il D.M. 161
11/04/2023 del Ministero della Cultura, “Linee guida per la
determinazione degli importi minimi dei canoni e dei corrispettivi
per la concessione d’uso dei beni in consegna agli istituti e
luoghi della cultura statali”. In pratica, se uno vuole fare una
foto di un monumento (non sotto copyright), magari per una
pubblicazione accademica, dovrà sganciare un discreto numero di
euro al MiC: euro che forse – ma non è detto – basteranno per
pagare i funzionari che dovranno far girare tutta la trafila
burocratica. Il tutto cercando di convincere il volgo che ce lo
chiede l’Europa, dato che il decreto recita tra l’altro
«VISTA la Direttiva (UE) 2019/790 del Parlamento europeo e del
Consiglio, del 17 aprile 2019, relativa all’apertura dei dati e al
riutilizzo dell’informazione nel settore pubblico e che modifica le
direttive 96/9/CE e 2001/29/CE, recepita mediante il decreto
legislativo 8 novembre 2021, n. 177»
Il tariffario è assurdo: non lo diciamo noi di Wikimedia Italia
ma l’Associazione Italiana Biblioteche,
che nota come per esempio chiedere copie digitali costi il
triplo delle stesse copie (nel senso di avere la stessa
risoluzione) stampate. Ma soprattutto è un ulteriore tassello per
impedire di pubblicizzare i nostri beni culturali. Questo non lo
pensa solo il governo: in questi giorni il tribunale di Firenze
ha sentenziato che non si può usare l’immagine del David di
Michelangelo senza autorizzazione e senza aver pagato i diritti
(occhei, in questo caso il tariffario dice 20000 euro: il
funzionario se lo pagano), con un ulteriore esborso di 30000 euro
per l’editore che «ha insidiosamente e maliziosamente accostato
l’immagine del David di Michelangelo a quella di un modello, così
svilendo, offuscando, mortificando, umiliando l’alto valore
simbolico ed identitario dell’opera d’arte ed asservendo la stessa
a finalità pubblicitarie e di promozione editoriale». Non che io
capisca perché quei soldi debbano andare alla Galleria
dell’Accademia e non a un eventuale fondo statale, ma tant’è.
Mi chiedo solo cosa faranno adesso con la copia della Fontana di
Trevi
costruita in Brasile… altro che Totò!
Questo è un frammento della voce attuale di Wikipedia sulla
rete
tranviaria di Nizza. Tutto bene, se non fosse per il fatto che
la linea 2 è in funzione dal 2019 (sono un po’ più veloci di noi,
mi sa).
Non è la prima volta che mi è capitato di trovare voci create e
poi lasciate lì a vegetare senza aggiornamenti. È ovvio che nessuno
è obbligato a mantenere a vita una voce: però casi come questo
fanno capire che non bisogna mai dare per scontato quello che si
trova scritto…
(L’altra faccia della medaglia è la cancellazione immediata dei
cosiddetti “recentismi”, aggiunte su fatti del giorno che tra
qualche mese saranno giustamente considerati inutili…)
Per comprensibili motivi, io ricevo la rassegna
stampa su Wikipedia e Wikimedia. È un po’ sgarrupata, nel senso che
devo scartare tutti gli articoli che hanno semplicemente una foto
(giustamente) accreditata a Wikimedia Commons, ma va bene così. In
genere trovo dai 10 ai 20 articoli: oggi ce n’erano ben 71, quasi
tutti dedicati al nuovo “portale enciclopedico” russo presentato
ieri e quasi tutti copiati più o meno verbatim
dal lancio Adnkronos. Le testate più oneste lo segnalano, le
altre fanno finta di niente.
Gli unici fuori dal coro sono stati quelli di Tag43, che
hanno
intitolato “La Russia prende le distanze da Wikipedia, ecco
Znanie”. Naturalmente Znanie in russo significa “conoscenza”,
esattamente come l’inglese Knowledge. Solo che evidentemente lo
stagista di Adnkronos ha preso un lancio in lingua inglese, l’ha
tradotto e non ha pensato che forse i russi non avevano usato un
nome inglese per il loro portale; e tutti gli altri stagisti dei
quotidiani hanno copincollato il lancio d’agenzia senza farsi
troppe domande, che presumo non siano compatibili coi miseri
emolumenti che prendono. A questo punto però tanto valeva fare gli
autarchici e scrivere che si chiamerà “Conoscenza”, no?
Io non ho nessuna idea di quale sia la linea editoriale di
Tag43, ma ho molto apprezzato come hanno trattato questa
notizia.
Emily St. John Mandel è una scrittrice canadese nota
per i suoi libri Stazione Undici (credo che ne abbiano fatto
anche una serie tv, ma è un campo in cui non mi addentro) e Mare
della tranquillità. Qualche giorno fa ha
scritto un tweet chiedendo chi poteva intervistarla… per poter
far sì che nella sua voce
su Wikipedia (in inglese, in quella italiana non era nemmeno
scritto che era sposata) che era divorziata. In qualche ora Slate
ha
pubblicato un’intervista dal titolo che dice “Un’intervista del
tutto normale con la scrittrice Emily St. John Mandel” e catenaccio
“Solo per chiedere all’autrice di Station Eleven e Sea of
Tranquility che ha fatto quest’anno, tutto qui”. E in effetti la
voce di en.wiki è stata immediatamente aggiornata. In realtà non
serviva nemmeno l’intervista: almeno fino ad oggi, la spunta blu di
Twitter è una verifica dell’identità della persona, e quindi la
prima fonte che attestava il divorzio è stato quel tweet,
sostituito poi dal link all’intervista.
Per quanto la cosa vi possa sembrare stupida (e sicuramente è
sembrata tale a Mandel), Wikipedia funziona così. Un’affermazione
deve avere una fonte affidabile, e nessuno può sapere se l’utente
che scrive “Emily St. John Mandel è divorziata” è effettivamente
Mandel o qualcuno che vuole fare uno scherzo. Leggendo il thread su
Twitter, però, mi sa che il contributore che le ha detto che
“occorreva una fonte comparabile” ha fatto un po’ di casino: come
ho scritto, quello che conta è una fonte affidabile che si possa
citare con tranquillità.
Un’ultima curiosità: nell’intervista a Slate, Mandel scrive che
vedersi ancora definita sposata (si è separata ad aprile dal
marito, e il divorzio è stato concesso a novembre) “was kind of
awkward for my girlfriend”. Ieri BBC ha scritto un
articolo in cui affermavano che si erano offerti anche loro di
intervistare Mandel. Com’è, come non è, nel loro articolo quella
frase non c’è :-)
Adam Atkinson mi ha segnalato questo articolo
della BBC in cui si racconta come per dieci anni la voce
inglese sul tostapane indicava come suo inventore una persona
inesistente di nome Alan MacMasters. A quanto pare, durante una
lezione universitaria il professore sconsigliò gli studenti di
usare Wikipedia come fonte, facendo l’esempio della voce “toaster”
dove si diceva che l’inventore era un tale Maddy Kennedy. L’Alan
MacMasters reale era uno di quegli studenti, e un suo amico
modificò la voce indicando come inventore appunto “Alan Mac
Masters”. Il guaio è che poco dopo il Daily Mirror osannò
MacMasters come un grande inventore scozzese, e le citazioni
continuarono a crescere, anche perché MacMasters creò una voce sul
suo inesistente omonimo con tanto di fotografia (ovviamente
ritoccata per farla sembrare ottocentesca). MacMasters fu
addirittura proposto come personaggio da raffigurare nelle
banconote scozzesi, anche se a quanto pare la Bank of Scotland ebbe
dei dubbi e lo scartò. Solo poco tempo fa un ragazzino ebbe dei
dubbi sulla biografia di MacMasters e mise in moto le squadre
wikipediane di verifica, che hanno scoperto la burla.
nel 1897 Carlos Decambrè, inventò il ”tost” che si diffuse in
tutta europa. questo tost veniva fatto con del pane normale,
prosciutto,tacchino e diversi formaggi. Esso garantiva un buon
pranzo per i nobili perchè all’epoca i salumi e i formaggi era cibo
considerato da ricchi.
Peccato che le uniche occorrenze in rete del cognome Decambrè
siano del tipo “Carlos Decambrè inventò il tostapane”, ovviamente
senza fonti perché scopiazzature da Wikipedia senza chiaramente
citarla. Questo a parte il fatto che se mi fosse capitato di vedere
un’aggiunta sgrammaticata simile l’avrei cassata al volo perché
senza fonti attendibili…
Premetto che ho molti amici traduttori :-) (e un paio di loro
sono anche tra i miei ventun lettori… ma ovviamente non sto
parlando di loro). In un libro (tradotto dall’inglese) che ho
appena letto ho trovato a un certo punto scritta l’espressione
“contrafforte volante”. Ora, come penso molti di voi io so più o
meno cos’è un contrafforte, ma l’ultima volta che ne ho sentito
parlare sarà stato all’inizio del liceo, cioè 45 anni fa (per me
che sono anzyano: your mileage may vary). Tra l’altro manco sapevo
come si dica in inglese “contrafforte”: sono andato a cercare e ho
scoperto che è “buttress”. Una rapida ricerca mi ha fatto trovare
la voce di Wikipedia in inglese “flying buttress”: l’ho aperta, ho
controllato qual è il nome della versione in italiano e ho scoperto
che si dice “arco rampante”. (Ok, a questo punto il mio neurone ha
tirato fuori il disegnino dei contrafforti ad archi rampanti, ma
questa è un’altra storia)
La mia domanda è semplice. È possibile che un traduttore trovi
scritto “flying buttress”, traduca parola per parola, e non si
renda conto che il sintagma in italiano non ha senso? È possibile
che non gli sia mai venuto in mente di usare Wikipedia in questo
modo non standard ma utilissimo per la terminologia tecnica? (E
comunque anche Wordreference riporta la
traduzione).
Magari qualcuno si può chiedere perché l’anno scorso GQ ha pensato
di dedicare un
articolo a Stefania Rocca per il suo… quarantaseiesimo
compleanno. A parte Valentino Rossi, il 46 non è che dica molto,
non è mica il quarantadue! Se questo qualcuno è curioso, però,
magari dà un’occhiata all’URL dell’articolo e scopre che c’è
scritto “stefania-rocca-50-anni-rock”. In effetti, ricordare il
cinquantesimo compleanno ha molto più senso, su questo non ci
piove. E in effetti si fa in fretta ad andare sull’Internet Archive
e vedere che l’articolo originale
si intitolava “Stefania Rocca, i primi 50 anni di un’anima
rock”.
L’altra settimana, però, la signora Rocca e/o il suo agente
hanno deciso che il passato era passato, e quindi l’età della
signora Rocca è di soli 47 anni. Per posti come GQ ci devono essere
argomenti molto convincenti per fare riscrivere un articolo
pubblicato l’anno scorso; su Wikipedia la cosa potrebbe sembrare
banale ma in realtà è un po’ più complicata, come potete vedere. Mi
è stato riferito (ma potrebbe essere una malignità…) che l’agente
in questione ha mandato alla Wikimedia Foundation un codice fiscale
della signora Rocca dove risulta il 1975 come data di nascita… ma
il codice fiscale in questione corrisponde a un maschio e non a una
femmina.
Ad ogni modo, la signora Rocca non è certo l’unica persona a
cercare di inserire su Wikipedia una data di nascita diversa da
quella che era sempre stata considerata tale in passato. Il primo
caso che mi viene in mente è quello del mago Silvan (simsalabim!),
ma anche Elisabetta Sgarbi,
come già scrissi, afferma di essere nata nel 1965 come anche
riportato dalla Treccani: il talento della signora Sgarbi si
notava fin da ragazza, considerando che ha conseguito la laurea in
farmacia nel 1980… Avevo anche segnalato alla Treccani che nel sito
c’era stato uno scambio di caratteri, e il 1956 che è la data di
nascita della signora Sgarbi era diventato 1965, ma non mi hanno
mai risposto. Non so se Wikipedia abbia più errori della Treccani,
ma sicuramente correggerli è più semplice!
In una settimana, è stato possibile implementare la possibilità
di trovare monumenti tramite geolocalizzazione e mostrarli su una
mappa, sia qualla di cercare una determinata località italiana (per
esempio, Roma) e vedere i monumenti ivi presenti. In più, c’è anche
una bellissima scheda per ogni monumento e un simpatico tasto
refresh da premere quando ci si sposta, per esempio durante una
wikigita.
La documentazione dell’API qui riportata è ferma a qualche
versione fa per quanto riguarda il contenuto della risposta, ora
c’è qualche parametro in più.
Backend
Ebbene, quando scrivi un’app mobile ti serve anche un backend!
Ho deciso quindi di riutilizzare il mio progetto wlm.puglia.wiki ed ho esposto quindi
alcune nuove simpatiche API in alcune delle nuove versioni. Quella
piccola webapp prima aveva solamente la stessa funzione dell’app e
dava la possibilità di trovare i monumenti vicino a sé con Leaflet
+ OSM, mentre ora svolge anche da backend dell’app. Per ragioni
tecniche (non c’era un framework per Appcelerator Titanium), non ho
potuto utilizzare OSM anche sull’applicazione mobile, quindi
troverete su Android le mappe di Google e su iOS quelle di Apple,
ma tutto il lavoro di geocoding è fatto da OSM, precisamente da
Mapbox con OSM.
È stato duro anche trovare il modo di far funzionare l’URL di
caricamento del monumento, che ora viene restituito insieme alle
informazioni del monumento ed è generato miscelando informazioni
dalla query SPARQL e dall’esecuzione tramite l’API parse di
MediaWiki del Modulo:WLM su Wikipedia!
Trovare i monumenti
Il primo endpoint che ho messo a disposizione, un bel po’ di
tempo fa già prefigurandomi l’app, è /monuments.json, che accetta
come parametri sia latitude e longitude che
city, per cercare invece i monumenti vicino ad una
città.
La risposta è di questo tipo, il secondo array rappresenta il
centro della mappa, cioé il punto al centro di tutti i risultati o,
in caso di città, la localizzazione della città:
[[{"id":34746,"item":"Q61905499","wlmid":"16A6620042","latitude":"41.132779","longitude":"16.838713","itemlabel":"Non creiamo precedenti","image":null,"created_at":"2020-06-07T22:54:03.906Z","updated_at":"2020-06-07T22:54:03.906Z","itemDescription":"Scultura presso lo Stadio della Vittoria","distance":0.69212135568994,"bearing":"109.201534968318"}], [41.13698328712448,16.826640973289223]]
Più informazioni sul
singolo monumento
A vostra disposizione c’è anche l’endpoint /show.json che
accetta il parametro id corrispondente all’id del
monumento che si ottiene attraverso la prima richiesta API. La
risposta corrisponderebbe, visitando
wlm.puglia.wiki/show.json?id=34746, a:
{"id":34746,"item":"Q61905499","wlmid":"16A6620042","latitude":"41.132779","longitude":"16.838713","itemlabel":"Non creiamo precedenti","image":null,"created_at":"2020-06-07T22:54:03.906Z","updated_at":"2020-06-07T22:54:03.906Z","itemDescription":"Scultura presso lo Stadio della Vittoria","distance":0.69212135568994,"bearing":"109.201534968318"}
Notare che gli ID cambiano ad ogni risincronizzazione del
database e questo endpoint è stato creato esplicitamente per
fornire le informazioni dall’app.
Indirizzo
Dato che il geocoding a quanto pare non funziona benissimo su
iOS, ho predisposto un endpoint API del tipo /address.json che
accetta il parametro id, sempre corrispondente all’id del
monumento ottenuto sempre nel primo endpoint.
Per esempio wlm.puglia.wiki/address.json?id=34746 risponde:
Siamo ormai giunti alla versione 1.1.3. Per il raggiungimento di questo risultato mi preme
ringraziare i miei fidi beta tester anticipati Yacine Boussoufa e
Stupeficium, ma anche il carissimo sviluppatore Titanium Michael
Gangolf, che mi ha dato alcuni importanti consigli per
l’applicazione
Download
Siete convinti adesso? Mentre risolvo i problemi con la
burocrazia per pubblicare su iOS (magari ottenendo lo sconto della
quota per il no profit), vi lascio i link per scaricare
l’applicazione su Android. Notate che per utilizzare l’app
è necessario avere i Google Play Services
attivi.
Non dimenticate di lasciare una recensione o un commento, o di
scrivermi se avete qualche dubbio!
Repubblica oggi ritorna sulle minacce di morte arrivate domenica
via Twitter a Carlo Verdelli in maniera peculiare. Cito
dall’articolo:
L’ultima minaccia è, se possibile, ancora più
inquietante delle precedenti. Mostra lo screenshot della pagina
Wikipedia relativa a Carlo Verdelli, manipolata da
una mano ignota. Accanto alla data di nascita, è stata inserita
quella di morte: 23 aprile 2020. E la sintesi della bio recita: “È
stato un giornalista italiano, direttore del quotidiano la
Repubblica”. Declinata al passato. E rilanciata su Twitter da un
profilo anonimo che, nonostante le segnalazioni, risulta tuttora
attivo e vomitante insulti.
(per la cronaca, oggi pomeriggio quell’account Twitter era stato
cancellato). Qualcuno, leggendo l’articolo, avrà sicuramente
pensato che la persona in questione aveva modificato la voce
dell’enciclopedia per poi fare la schermata e pubblicarla. Bene,
non è successo nulla di tutto questo, come potete vedere voi stessi
guardando
la pagina con l’elenco delle modifiche sulla voce. Per i
curiosi, è possibile per i sysop cancellare versioni della voce che
contengano insulti o bestemmie, in modo che sia impossibile vedere
cosa c’è scritto: ma l’esistenza di una modifica rimane
comunque visibile, con la modifica in questione con una riga sopra
(strikethrough) per ricordare che qualcosa c’era stato.
Giulio Cesare è ancora vivo e lotta insieme
a noi!
Una volta i più ingenui detrattori di Wikipedia facevano una
modifica, scattavano l’immagine e poi si lanciavano a denunciare
gli errori dell’enciclopedia — errori che magari erano stati
corretti un paio di minuti dopo, alle due del mattino. Ora
evidentemente queste persone si sono un po’ più evolute, e hanno
scoperto come creare una voce fasulla senza lasciare nessuna
traccia. Ci ho provato io, e in cinque minuti ho prodotto uno
screenshot simile a quello ora non più visibile: solo che mi
sembrava macabro far morire qualcuno e ho preferito rendere ancora
vivo Giulio Cesare, come vedete qui sopra. Segnalo anche ai
giornalisti di Repubblica che leggere la voce del loro direttore
“declinata al passato” è un semplice sottoprodotto dell’avere
inserito una data di morte; avendola io tolta dalla voce sul Divus
Iulius, essa è magicamente passata al presente.
Detto in altri termini, quello che è successo è l’equivalente di
una busta contenente un proiettile e recapitata con la posta; con
il lockdown probabilmente è in effetti più semplice mettersi al
computer e falsificare una schermata. Al massimo si può chiedere
alla Polizia postale di andare dal signor Twitter e chiedere i dati
sulla connessione dell’utente che aveva postato lo screenshot, dati
che immagino non verranno consegnati, ma nulla di più. Eppure,
leggendo l’articolo, Twitter pare semplicemente essere un complice
neppure tanto importante del vero sito perpetratore, il che la dice
lunga sulla capacità di “leggere” un testo in rete.
(Per la cronaca, che io sappia non è stato chiesto a nessun
esperto wikipediano cosa poteva essere successo. Eppure a me
continuano ad arrivare richieste di persone che pretendono che io
aggiusti un danno fatto a loro su Wikipedia… Si vede che non ne
valeva la pena).









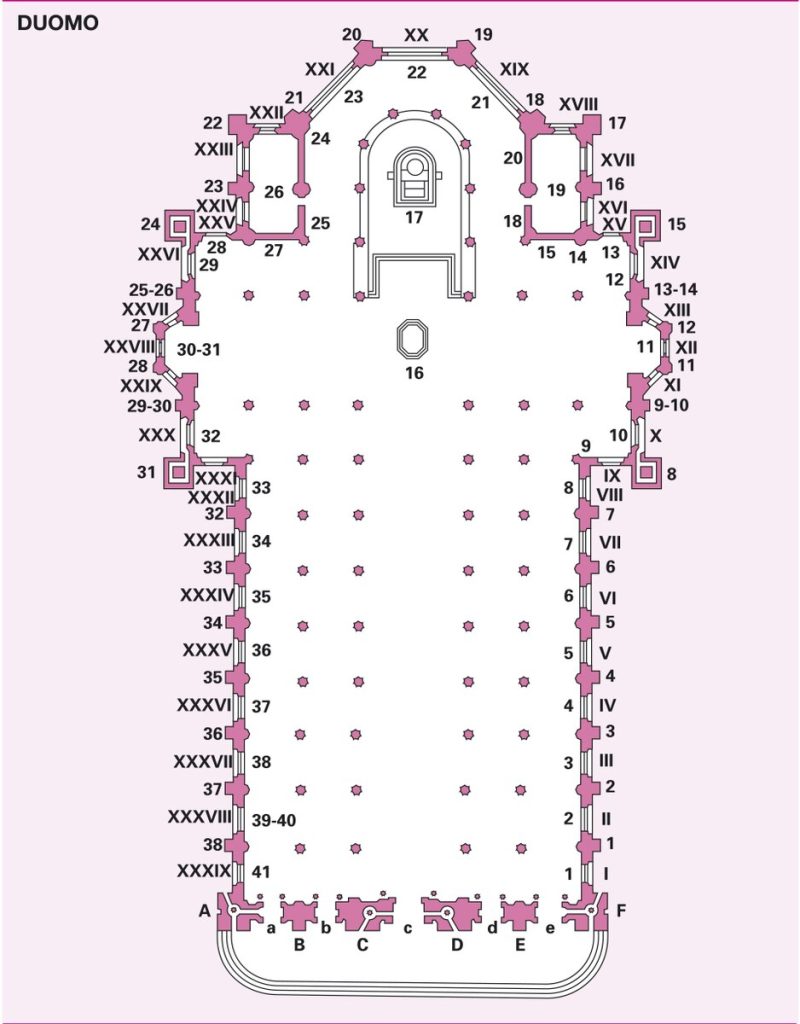
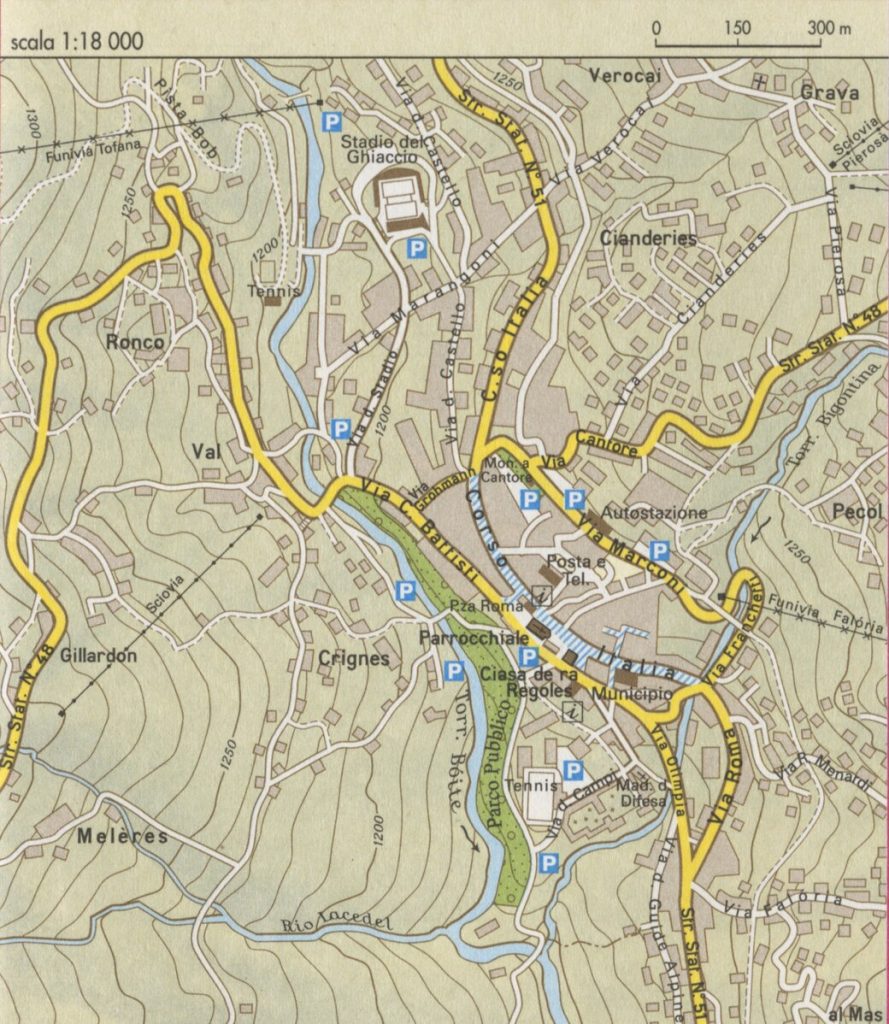
 Bisogna dire che i giudici italiani sono coerenti.
Anche nella causa per l’uso non autorizzato dell’immagine del duca
d’Este su un aceto balsamico, la corte d’appello di Bologna
Bisogna dire che i giudici italiani sono coerenti.
Anche nella causa per l’uso non autorizzato dell’immagine del duca
d’Este su un aceto balsamico, la corte d’appello di Bologna
 Purtroppo pare che Totò Schillaci abbia avuto una
recidiva del tumore al colon che l’aveva colpito. Purtroppo la
mamma dei cretini è sempre incinta, e un utente anonimo oggi alle
15 aveva modificato la voce di Wikipedia sul protagonista di Italia
90, indicandone la morte. La falsa notizia è stata tolta un paio
d’ore dopo da un altro utente anonimo, non prima che Repubblica
Purtroppo pare che Totò Schillaci abbia avuto una
recidiva del tumore al colon che l’aveva colpito. Purtroppo la
mamma dei cretini è sempre incinta, e un utente anonimo oggi alle
15 aveva modificato la voce di Wikipedia sul protagonista di Italia
90, indicandone la morte. La falsa notizia è stata tolta un paio
d’ore dopo da un altro utente anonimo, non prima che Repubblica
 Per la quarta volta la Wikimedia Foundation
Per la quarta volta la Wikimedia Foundation 
 Piergiovanna Grossi è un’attiva wikipediana. Ma è anche
una professoressa a contratto e una ricercatrice, e le è capitato
di scrivere un articolo per una
Piergiovanna Grossi è un’attiva wikipediana. Ma è anche
una professoressa a contratto e una ricercatrice, e le è capitato
di scrivere un articolo per una  Siamo in estate, non che molto da dire, e così
Siamo in estate, non che molto da dire, e così



 Emily St. John Mandel è una scrittrice canadese nota
per i suoi libri Stazione Undici (credo che ne abbiano fatto
anche una serie tv, ma è un campo in cui non mi addentro) e Mare
della tranquillità. Qualche giorno fa
Emily St. John Mandel è una scrittrice canadese nota
per i suoi libri Stazione Undici (credo che ne abbiano fatto
anche una serie tv, ma è un campo in cui non mi addentro) e Mare
della tranquillità. Qualche giorno fa 
 Per il raggiungimento di questo risultato mi preme
ringraziare i miei fidi beta tester anticipati Yacine Boussoufa e
Stupeficium, ma anche il carissimo sviluppatore Titanium Michael
Gangolf, che mi ha dato alcuni importanti consigli per
l’applicazione
Per il raggiungimento di questo risultato mi preme
ringraziare i miei fidi beta tester anticipati Yacine Boussoufa e
Stupeficium, ma anche il carissimo sviluppatore Titanium Michael
Gangolf, che mi ha dato alcuni importanti consigli per
l’applicazione
{kind=link}
{kind=link}
{kind=link}