I switched to Obsidian for note taking this week, after over 3 years of using Logseq. Despite loving Logseq’s outliner format, I’ve found the app, especially the mobile app, to be slow and frustrating to use. If you’re looking to choose between the two, I hope the notes below help you see some of the tradeoffs.
I considered Obsidian and Notion. I like Notion’s features and polish, but Obsidian won because it uses local markdown files, just like Logseq. If I decide to move to another app, the migration should be as easy as this one.!
Migrating the notes
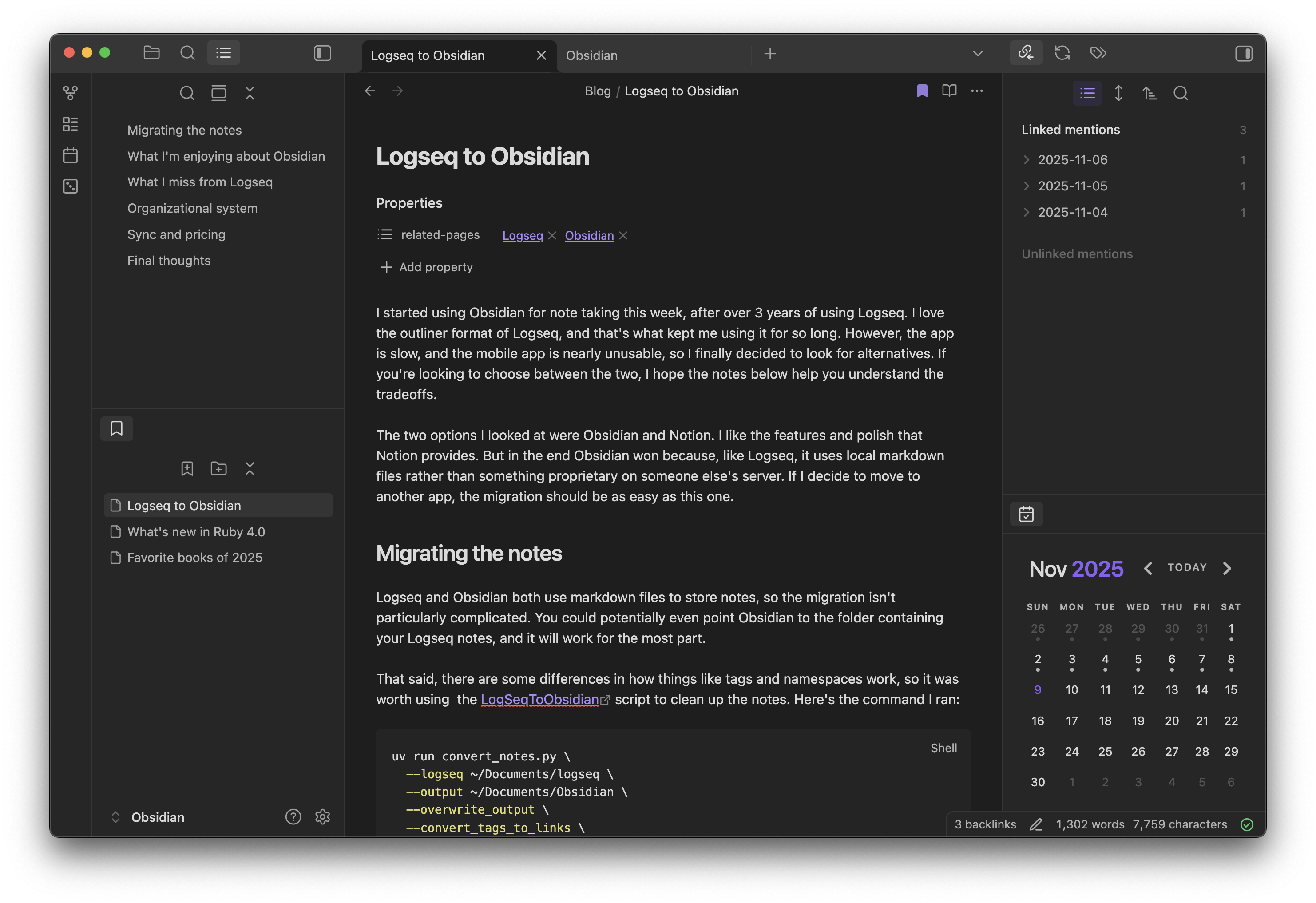
Logseq and Obsidian both use markdown files to store notes, so the migration isn’t particularly complicated. You can even point Obsidian to the folder containing your Logseq notes, and things will mostly work.
That said, there are some differences in how things like tags and namespaces work, so I used theLogSeqToObsidian script to clean up the notes. This made the transition easier. Here’s the command I ran:
uv run convert_notes.py \
--logseq ~/Documents/logseq \
--output ~/Documents/Obsidian \
--overwrite_output \
--convert_tags_to_links \
--tag_prop_to_taglist \
--journal_dashes \
--ignore_dot_for_namespaces
This isn’t perfect, though. Some Logseq specific annotations are still around, but I’m not too worried about them. I can clean them up gradually as and when I encounter them.
What I’m enjoying about Obsidian
Editing experience: Obsidian is the best markdown editor I’ve ever used. I’m already using it to draft blog posts, starting with this one. Jotting down observations about the migration in my daily notes made it easy to bring everything together into this post.
Performance: The app is so snappy, both on desktop and mobile. This was a huge problem with Logseq, especially on mobile, which made writing very frustrating.
Mobile app: The Logseq mobile app is a mess. Sometime the text that I typed would just disappear. Or text would flow outside the viewport, so I can’t see what I’m typing. The bottom bar containing the search button, would often disappear. Meanwhile, the Obsidian app has worked flawlessly so far. In fact, I’ve even done some editing and proofreading of this post on my phone.
Bases: Obsidian’s databases feature is called Bases, and I much prefer this approach for querying structured data to Logseq’s datalog queries, which I could never understand. There’s a UI for filtering results, rather than queries. But there are also formulas that you can reach for if you need something more.
Polished UI: Although both Logseq and Obsidian mostly look similar, I’m enjoying the polish that Obsidian brings. I like being able to rearrange UI elements like the bookmarks pane. The table view for bases is also much nicer than the query results table in Logseq. The default theme is also pretty great, so I haven’t had to look for alternatives.
Plugins: The plugin ecosystem looks so much richer in Obsidian. The plugins API also seems to allow more complex functionality to be added by third parties. I’m starting slow with plugins, and only have a couple of plugins so far. There are a few others that I want to try, such as Journaling and Smart Connections.
Focus on markdown: The Logseq team is rebuilding the app to use a DB instead of markdown files. This still hasn’t shipped, and in the meanwhile, work on the markdown version has stalled for over two years. Obsidian’s focus on markdown means that the app is constantly getting updates. And if I decide to move to another app, the data will still be portable.
What I miss from Logseq
Namespaces: Being able to organize travel notes as Travel/2025/Paris was really convenient. If you went to the Travel page, you could see links to the subpages (Travel/2025, Travel/2025/Paris etc), but now if I link to that page, I will only see the last part (Paris). It’s confusing if you have a separate page for notes about the city. Now I’m thinking of using dashes in the file name (like Travel - 2025 - Paris) and adding metadata for organization. There’s going to be a fair bit of manual work updating notes where I used namespaces.
Journals timeline: Logseq has a nice chronological view for journal entries, which makes it easy to scroll through last few days’ notes. In Obsidian, you have to type the date to actually go to a page. It’s also missing an easy shortcut to go to previous/next day’s entry. I needed to install a third party calendar plugin to navigate journal dates. I might try the Journaling plugin to see if that helps.
Flashcards: Obsidian doesn’t have a native spaced repetition feature like Logseq does. It’s not a dealbreaker, and I don’t use it all that much, but it was nice to have.
Inline metadata: Logseq lets you add metadata to any node anywhere. For instance, you could add a node for a book directly in today’s journal entry, and add a rating to it. Obsidian, on the other hand, only supports metadata at the page level, so you’ll have to create a separate page for each book and then attach metadata to it.
Outliner: Working with bullet points everywhere was very convenient for journal entries in Logseq. I’m going to miss that. I’m using bullet points out of habit anyway, even though you don’t get any benefits of structuring notes that way.
Pasting links into text: In Logseq, I can select some text and paste a URL, and it will automatically link it, while Obsidian will replace that text with the URL. There are plugins that fix this, but this should be the default behavior.
Organizational system
I’m not trying too hard to put in an organization system this early. For now, most notes are stored in the root folder. Search and links are doing a good enough job.
There are a few exceptions. Daily notes live in journals. Notes containing structured information that I query in bases, such as books or movies, have their own folders.
Sync and pricing
Both Logseq and Obsidian have basic sync options that let you sync your data across devices, starting at $5/month. However, Logseq is much more generous about limits, allowing 10 graphs with 10GB of storage, while Obsidian allows one vault and 1GB storage. You’ll need to pay twice as much to get similar limits as Logseq.
The basic plan is more than enough for me. Most of my 1600+ files are plain text, so I’m using about 1% of that limit.
Final thoughts
The transition has been surprisingly easy. A big part of this is because both tools are markdown-based, so it’s easy for one to read files created by the other. I’m writing more now because it’s almost as easy to jot down thoughts on the phone as it is on the laptop.
I’ll continue using Logseq at work for now because it’s the recommended notes app there. My vault is strictly local and mainly used for tracking todos, so many of my biggest gripes about the app don’t apply there.
]]>