pg_duckpipe is a PostgreSQL extension for real-time CDC to DuckLake columnar tables. This month: transparent query routing, append-only changelog, fan-in streaming, partitioned table support, and more.
All of these groups share the same goal: bringing PostgreSQL enthusiasts together to learn, exchange ideas, and connect with each other — often organized entirely in people’s spare time.
To me, this is a wonderful sign of PostgreSQL’s continued growth and adoption around the world.
Seeing this wave of community activity inspired me as well. At the beginning of 2026, I decided to start something similar in my own city: the PostgreSQL User Group Vienna.
Last week on Wednesday March 18, 2026, the moment finally arrived: I attended the first meetup that I had organized myself — and it turned out to be an amazing experience.
Realizing something was missing
The idea to organize a meetup did not appear overnight.
Over the past year (especially while helping organize PGDay Austria 2025, which took place in September) I noticed something interesting. There were clearly people in Austria who were excited about PostgreSQL, but they were not very well connected with each other.
This observation stood out even more because I had already attended many conferences and meetups across Europe during the past two years. At those events I experienced firsthand how welcoming and vibrant the PostgreSQL community is.
The contrast made me realize that something similar was missing locally. Throughout 2025, the thought kept coming back to me:
>> Austria could really use a regular PostgreSQL meetup. <<
For context, I should mention that I’m not a technical person …. my background is actually in marketing. Still, I have been closely following the PostgreSQL ecosystem and communi
Recently on the pgsql-performance mailing list, a question popped up regarding a Top-N query gone wrong. On the surface, the query merely fetched the latest 1000 rows through a join involving a few CTEs in a dozen tables with a few million rows distributed among them. A daunting query with an equally daunting plan that required about 2-3 seconds of execution time. Not ideal, but not exactly a show-stopper either. But high concurrency compounded the problem, with 40 sessions enough to completely saturate the available CPU threads.In the end all it took was a new index to solve the conundrum, as is usually the case with queries like this. Problem solved, right?Well... maybe. But let's play a different game.What if the query was already optimal? What if every join was fully indexed, the planner chose the most optimal variant, and yet the sheer volume of data meant two seconds was the fastest possible time? Now imagine not 40 concurrent users, but 4000. What happens then?
It's Just Math
Suppose a query takes two seconds after being fully optimized and there are 4000 users that each need that result once per page load, spread across a 60-second window. That's roughly 67 concurrent executions at any given moment. A 2-vCPU machine can only handle two of these, what about the other 65?That's an irreducible capacity mismatch. If we can't reduce the execution time of the original query, we must provide some kind of substitution instead, one that reduces the number of times Postgres runs that query at all.The good news is that Postgres has built-in tools for this. The better news is that there are external tools that extend those capabilities substantially. Sometimes—though a Postgres expert is loathe to admit it—the right answer rests outside of Postgres.Let's explore the available tools.
It's a Material World
Postgres has supported materialized views since version 9.3, and they are exactly what they sound like: a view whose results are physically stored on disk, rather than recomputed on demand. Creating one is [...]
Every migration unfolds a story. Here are the chapters most teams miss.
Years of guiding customers and partners through Oracle and SQL Server migrations to PostgreSQL taught me one thing above everything else: the tool was never the whole answer.
Legacy Oracle and SQL Server code wasn’t written yesterday. It was built over three decades, under different constraints, by people solving real problems with what they had. That logic has history. It deserves empathy not just a conversion pass.
Ora2pg, AWS SCT, Google Cloud DMS, Ispirer all are solid tools. All do a decent job translating DDL and procedural logic. But default tooling output becomes your new core first PostgreSQL foundation. If that foundation has cracks, your customer’s first experience of PostgreSQL will be frustration not its true capability.
Every migration I’ve worked on unfolded a story. I learned something new in each one and carried that into every PostgreSQL implementation I built after.
Here are four gotchas that will bite you if you’re not watching.
1. Oracle NUMBER Without Precision – A Silent Performance Trap
Oracle lets you declare NUMBER without precision or scale. That’s a 30-year-old design choice. Most tools map it to NUMERIC or DOUBLE PRECISION depending on context but without deliberate fine-tuning, you get a blanket mapping that introduces implicit casting inside procedural blocks and hurts performance long term.
It compounds further when NUMBER columns carry primary key or foreign key constraints wrong type mapping directly impacts index access patterns, storage, and query performance over time.
If your conversion tool is producing this mapping without any precision inference — please run. Fix it before you go further.
On 20th of March 2026, Amit Kapila committed patch: Add support for EXCEPT TABLE in ALTER PUBLICATION. Following commit fd366065e0, which added EXCEPT TABLE support to CREATE PUBLICATION, this commit extends ALTER PUBLICATION to allow modifying the exclusion list. New Syntax: ALTER PUBLICATION name SET publication_all_object [, ... ] where publication_all_object is … Continue reading "Waiting for PostgreSQL 19 – Add support for EXCEPT TABLE in ALTER PUBLICATION."
What is the best way to manage database schema migrations in 2026?
Since this sort of thing is getting easier with AI tooling, I spent some time doing a survey across a bunch of recognizable multi-contributor open source projects to see how they do database schema change management.
Biggest takeaway: the framework provided by your programming language is the most common pattern. After that seems to be custom project-specific code. Even while Pramod Sadalage and Martin Fowler’s twenty-year-old general evolutionary pattern is followed, I was surprised to see very few occurrences of the specific tools they listed in their 2016 article about Evolutionary Database Design. Those tools might be used behind some corporate firewalls, but they aren’t showing up in collaborative open source projects.
Second takeaway: it should be obvious that we still have schema migrations with document databases and distributed NoSQL databases; but lots of interesting illustrations here of what it looks like in practice to deal with document models and NoSQL schemas as they change over time. My recent comment on an Adam Jacob LinkedIn post:“life is great as long as changing your schema can remain avoidable (ie. requiring some kind of migration).”
What about the method of triggering the schema migrations? The most common pattern is that the application process itself triggers schema migration. After that we have kubernetes jobs.
The rest of this blog post is the supporting data I generated with some AI tooling. I made sure to include links to source code, for verifying accuracy. I spot checked a few and they were all accurate – but I didn’t go through every single project.
If you spot errors, please let me know!! I’ll update the blog.
A survey of how major open-source projects handle database schema migrations. Each project includes a real code example and how migrations are triggered during upgrades.
Introduction: The Market Is Talking About AI, but the Deeper Change Is Architectural
The database market is full of confident declarations right now. One vendor says the cloud data warehouse era is ending. Another argues that AI is redrawing the database landscape. A third claims that real-time analytics is now the center of gravity. Each story contains some truth, and each vendor naturally presents itself as the answer.
But there is a risk in taking these narratives too literally. The deeper shift in enterprise data platforms is not simply that AI is changing databases. It is that modern platforms are being forced to reduce the seams between systems. That is the more important architectural story, and it is the one that will matter long after today’s product positioning slides have been replaced by tomorrow’s.
For years, enterprises tolerated fragmented data architectures because the fragmentation felt manageable. One system handled transactions. Another handled analytics. A streaming layer was added for movement and enrichment. Dashboards sat elsewhere. Then machine learning appeared, followed by vector stores, feature stores, observability engines, and lakehouse layers. For a while, the industry treated this as normal evolution. Eventually, however, many teams discovered that they were not building a platform so much as negotiating peace between products.
That is why this moment matters. AI may be accelerating the conversation, but the real pressure is architectural. Enterprises are trying to simplify how data flows, how systems interact, and how teams operate. In other words, they are trying to remove seams.
The Problem: The Cost of Separation Has Become Too High
The old world was built around separation. In one sense, that separation was rational. Different workloads genuinely do have different requirements. Transactions need integrity and predictability. Analytics often need scale and throughput. Observability workloads have different ingestion and retention patterns. AI expe
Your PostgreSQL HA cluster promotes a new primary. Patroni says everything is healthy. But your application is still talking to the old, dead node. Welcome to the OCI VIP problem.
If you have built PostgreSQL high availability clusters on AWS or Azure, you have probably gotten comfortable with how virtual IPs work. You assign a VIP, your failover tool moves it, and your application reconnects to the new primary. Clean. Simple. Done.
Then you try the same thing on Oracle Cloud Infrastructure and something quietly goes wrong.
The cluster promotes. Patroni (or repmgr, or whatever you are using) does its job. The standby becomes the new primary. But the VIP does not follow. Your application keeps sending traffic to the old node — the one that just failed. From the outside, it looks like the database is down. From the inside, everything looks green.
This is one of the more frustrating failure modes we have worked through in production. Not because it is hard to fix, but because it is hard to catch. It passes every test you throw at it right up until the moment it matters.
Let me walk you through why this happens, how to fix it, and how to pick the right approach for your environment.
Why OCI Handles VIPs Differently
On AWS, a secondary private IP can float between instances within a subnet. You callassign-private-ip-addressesand it moves. On Azure, you update a NIC’s IP configuration. In both cases, your failover tool can handle this natively, or with a small callback script.
OCI does not work that way.
On OCI, a virtual IP (implemented as a secondary private IP on a VNIC) is explicitly bound to a specific instance’s Virtual Network Interface Card. It cannot float between instances the way it does on AWS or Azure. When your primary fails and the standby gets promoted, the VIP stays attached to the old instance’s VNIC. It does not move on its own, and the stand
Most people who work with PostgreSQL eventually learn two commands for query tuning: EXPLAIN and EXPLAIN ANALYZE.
EXPLAIN shows the planner’s chosen execution plan, and EXPLAIN ANALYZE runs the query and adds runtime statistics. For most tuning tasks, this already provides a wealth of information.
But what many people don’t realize is that EXPLAIN has a handful of other options that can make troubleshooting much easier. In some cases they answer questions that EXPLAIN ANALYZE alone cannot.
In this post we’ll take a look at a few of those lesser-known options.
BUFFERS: Where Did the Data Come From?
One common question during performance analysis is whether data came from: shared buffers (cache), disk, or temporary buffers. This is where the BUFFERS option comes in handy. Output can look something like this:
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM mytable WHERE id = 123;
[...]
Index Scan using mytable_pkey on mytable
Buffers: shared hit=5 read=2
[...]
In the example above, we see:
shared hit – pages already in cache (i.e., cache hit)
shared read – pages fetched from disk (i.e., cache miss)
Note that buffers in this context are 8 kilobyte blocks of memory (standard block size for most storage systems)
This is extremely useful when trying to determine if performance problems are related to: cold cache, excessive disk reads, or insufficient memory (i.e., cache is too crowded to keep all the data being worked with).
Especially for index scans, this information confirms whether a query that should be index-friendly is actually pulling large portions of the table into memory.
MEMORY: Memory used by the
This is a new feature introduced in version 18. It is different from BUFFERS in the sense that it tracks the amount of memory consumed during the query planning phase, not execution. Output would appear at the bottom of EXPLAIN output like this:
EXPLAIN (ANALYZE, TIMING OFF)
SELECT * FROM mytable WHERE id = 123;
[...]
Pla
The PostgreSQL User Group Vienna met for the very first time on Wednesday, March 18 2026, organised by Cornelia Biacsics.
Speakers:
Ranjeet Kumar
Jan Karremans
Pavlo Golub
On Thursday, March 19 2026, the AMS DB came together for talks and networking.
Organised by:
Floor Drees
Jessie Tu
Mattias Jonsson
Daniël van Eeden
Speakers:
Matthias van de Meent
Martin Alderete
León Castillejos
The PostgreSQL England North Meetup Group met also for the very first time on Thursday, March 19 2026. It was organised by Daniel Chapman and Stephen Wood.
I'm a Product Manager. Not a developer. I want to be upfront about that because everything that follows only makes sense if you understand that I have no business writing software - and I did it anyway.I built MM-Ready, an open-source CLI tool that scans a PostgreSQL database and tells you exactly what needs to change before you can run multi-master replication with pgEdge Spock. It checks 56 things across your schema, replication config, extensions, sequences, triggers, and SQL patterns. It gives you a severity-graded report - CRITICAL, WARNING, CONSIDER, INFO - with specific remediation steps for each finding. It runs against a live database, a schema dump file, or an existing Spock installation.I built the first version in about four hours using Claude Code while operating in a zombie-like half-asleep state. Not so much vibe-coding as trance-coding.
The Priority that's never priority enough
Every customer evaluating the move to multi-master replication has the same question: "What, if anything, do I need to change in my database before I can turn this on?"The answer could be "nothing", or it could potentially touch dozens of things. Tables without primary keys are insert-only replication - with logical replication, UPDATE and DELETE require a unique row identifier. Foreign keys with CASCADE actions can fire on the origin and create conflicts because foreign keys aren't validated at the subscriber. Certain sequence types don't replicate well. Some extensions aren't compatible. Deferrable constraints get silently skipped for conflict resolution. doesn't guarantee uniqueness for logical replication conflict resolution. So on and so forth. These things aren't bugs or issues - they're a natural consequence of a shift in operational mindset. It's akin to moving from a one-steering-wheel driving experience, and getting in a skid-steer with its highly maneuverable double-joystick.Our Customer Success team was having to do this analysis mostly by hand. They had scripts they'd written, tribal knowledge passed bet[...]
A feature about how to handle harhref keys when querying a table.
Perl and DBI hashref keys case-sensitive
Perl and DBI are brilliant in giving you power to connect to a database and extract data. There is however something I never noticed, because I’m used to a PostgreSQL: when fetching a row as an hashref, the keys are stored in lowercase. This is not something tied to DBI, nor to Perl, rather to PostgreSQL and the way it handles SQL.
In short, SQL is case insensitive, with PostgreSQL managing this as to lower case, while other databases manging this as to upper case. Now, clearly, if you don’t manage this, you can find yourself with the keys of an hash depending on the specific database:
#!perlusev5.40;useDBD::Pg;my$database=DBI->connect('dbi:Pg:dbname=testdb;host=rachel','luca','xxx');my$statement=$database->prepare('select * from perl');$statement->execute;my$row=$statement->fetchrow_hashref;say"Columns: ",join(', ',keys$row->%*);
The above snippet reports the following output (assuming the perl table have been created as follows):
% psql -h rachel -U luca -c'\d perl' testdb
Table "public.perl"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+----------------------------------
pk | integer | | not null | nextval('perl_pk_seq'::regclass)
a | text | | |
b | text | | |
Indexes:
"perl_pkey" PRIMARY KEY, btree (pk)
% perl test.pl
Columns: a, b, pk
However, the same piece of code can produce different results if the database engine is using uppercase everywhere (yeas Oracle, I’m looking at you!).
I discovered that DBI provides a property, named FetchHashKeyName, that can be set to either always lowercase with NAME_lc or viceversa, to always upper case with NAME_uc. This means you can overwrite the default behavior of your database with something like the
On 12nd of March 2026, Robert Haas committed patch: Add pg_plan_advice contrib module. Provide a facility that (1) can be used to stabilize certain plan choices so that the planner cannot reverse course without authorization and (2) can be used by knowledgeable users to insist on plan choices contrary to what the planner believes … Continue reading "Waiting for PostgreSQL 19 – Add pg_plan_advice contrib module."
The previous article showed that PostgreSQL 18 makes optimizer statistics portable, but left one gap open:
It's not worth trying to inject relpages as the planner checks the actual file size and scales it proportionally.
The planner doesn't trust pg_class.relpages. It calls smgrnblocks() to read the actual number of 8KB pages from disk. Your table is 74 pages on disk but pg_class.relpages says 123,513? The planner uses the ratio to scale reltuples down to match the actual file size. The selectivity ratios stay correct, plan shapes mostly survive, but the absolute cost estimates are off.
For debugging a single query, that's usually fine. For automated regression testing where you compare EXPLAIN costs across runs, it breaks things. A cost threshold of 2× means something different when the baseline was computed from fake-scaled numbers.
As part of my work on RegreSQL I'm happy to announce pg_regresql extension which fixes this by hooking directly into the planner.
Why the planner ignores relpages
When PostgreSQL's planner calls get_relation_info() in plancat.c, it delegates to estimate_rel_size() which ends up in table_block_relation_estimate_size() in tableam.c. There, the actual page count comes from the storage manager:
curpages = RelationGetNumberOfBlocks(rel);
The function then computes a tuple density from pg_class (reltuples / relpages) and multiplies it by curpages to estimate tuples. So pg_class.reltuples isn't ignored, it's scaled to match the real file size. The reasoning is sound for normal operation: the catalog might be stale, but the file system is always current.
The same applies to indexes. The planner reads their actual sizes from disk too.
What pg_regresql does
The extension hooks into get_relation_info_hook, a planner callback that runs after PostgreSQL reads the physical file stats. The hook replaces the file-based numbers with the values stored in pg_class:
Recently during one of the Oracle to PostgreSQL migration with enterprise customer while designing cutover runbook, we were evaluating steps to perform Sequence value reset to match it as per Source so that every new value request using NextVal is an new one and does not incur transactional failure.
It is one of the critical steps of any database migrations, as in most cases sequence LAST_VALUE is not migrated at target implicitly and sequence values need to be matching as per source so that new transaction never fails and application work post cutover.
We used ora2pg’s SEQUENCE_VALUES export to generate DDL command to set the last values of sequences.
ora2pg’s SEQUENCE_VALUES export generates ALTER SEQUENCE ... START WITH. That command does not reset the sequence.
Expected: next nextval() = 1494601. Actual: sequence continues from wherever it was.
Silently wrong. The kind that surfaces as a “balance mismatch” as part of post-cutover steps.
Understand Different Sequence Reset Options.
Any sequence in PostgreSQL has three internal fields: start_value → reference point for bare RESTART last_value → where the counter actually is (nextval reads this) is_called → has last_value been consumed yet?
We have couple of options to reset last_value for an sequences,
Following table summarize with all options in comparison with START WITH.
I’ve been busy with an internal project at work, but have responded to a few pg_clickhouse reports for a couple crashes and vulnerabilities, thanks to pen testing and a community security report. These changes drive the release of v0.1.5 today.
Welcome to Part three of our series for building a High Availability Postgres cluster using Patroni! Part one focused entirely on establishing the DCS using etcd to provide the critical DCS backbone for the cluster, and part two added Patroni and Postgres to the software stack. While it's entirely possible to stop at that point and use the cluster as-is, there's one more piece that will make it far more functional overall.New connections need a way to reach the primary node easily and consistently. Patroni provides a REST interface for interrogating each node for its status, making it a perfect match for any software or load-balancer layer compatible with HTTP checks. Part three focuses on adding HAProxy to fill that role, completing the cluster with a routing layer.Hopefully you still have the three VMs where you installed etcd, Postgres, and Patroni. We will need those VMs for the final stage, so if you haven't already gone through the steps in part one and two, come back when you're ready.Otherwise, let's complete the cluster!
What HAProxy adds
HAProxy is one of the most common HTTP proxies available, but it also has a hidden superpower: it can transparently redirect raw TCP connections as well. This means it can also act as a proxy for any kind of service such as Postgres. Here's how it works:
HAProxy connects to the Patroni REST interface and gets the status for the "/" URL.
Patroni will only respond with a "200 OK" status on the primary node. All other nodes will produce a "500" error of some kind.
HAProxy marks nodes that respond with errors as unhealthy.
All connections get routed to the only "healthy" node: the primary for the cluster.
Of course that's not the end of it; the Patroni REST API is incredibly powerful, as it provides multiple additional endpoints. For example a check against:
/replica will succeed if the node is a healthy streaming replica of the primary, a good match for offloading intensive read queries from the primary node.
Yes, it was St. Patrick’s Day, and also Illinois Primaries, and the weather was beyond bad, but we still had a good crowd!
Pizza always comes first :), because nobody is going to go hungry! Whether you stay for Postgres or not is up to you, so I am assuming that when people are coming and staying, it’s not just for pizza
There was a time when High Availability in PostgreSQL came with an implicit assumption: if something important happened, an administrator could log into the server, inspect the state of the cluster, and run the command that steadied the ship. That assumption is fading fast. In many modern enterprises, direct OS-level access is no longer part of the operating model. SSH is locked down, bastion access is tightly controlled, and every administrative pathway is examined through the lens of zero-trust security.
And yet—High Availability doesn’t wait.
That shift creates a very real operational question for database teams: how do you maintain control of a PostgreSQL HA environment when the traditional control surface has been deliberately removed?
This is where the refreshed vision for efm_extension becomes interesting. It is an open-source PostgreSQL extension, released under the PostgreSQL License, designed to expose EDB Failover Manager (EFM) operations directly through SQL—bringing operational control into a governed, auditable layer.
The HA Landscape: Patroni, repmgr, and EFM
PostgreSQL High Availability has never been a one-size-fits-all story.
Some teams lean toward Patroni, embracing distributed coordination and cloud-native patterns. Others prefer repmgr, valuing its simplicity and DBA-centric workflows. And then there is EDB Failover Manager (EFM)—a mature, enterprise-grade solution designed to monitor streaming replication clusters and orchestrate failover with predictability and control.
Each of these tools reflects a different philosophy. But they share one quiet assumption:
Operational control happens at the OS level.
And that assumption is exactly where modern security models push back.
The Real Problem: Control Without Access
In today’s enterprise environments, responsibilities are deliberately separated.
On 10th of March 2026, Álvaro Herrera committed patch: Introduce the REPACK command REPACK absorbs the functionality of VACUUM FULL and CLUSTER in a single command. Because this functionality is completely different from regular VACUUM, having it separate from VACUUM makes it easier for users to understand; as for CLUSTER, the term is heavily … Continue reading "Waiting for PostgreSQL 19 – Introduce the REPACK command"
PostgreSQL major version upgrades are one of those tasks that every DBA has to deal with regularly. They are routine — but they are also full of small, potentially dangerous details that can turn a straightforward maintenance window into an incident. Having performed hundreds of upgrades across different environments over the years, I want to share a comprehensive, practical guide to upgrading from PostgreSQL 17 to 18, with particular focus on what has changed and what has finally improved in the upgrade process itself.
This article is based on my PGConf.EU 2024 talk, updated to cover the PostgreSQL 17→18 upgrade path and the significant improvements that landed in version 18. This time of the year we usually recommend our customers to upgrade: current release 18.3 is stable enough.
Why Upgrades Matter
Let me start with a reality check. PostgreSQL major versions are supported for five years. If you are running a version that is past its end-of-life, you are exposed to unpatched security vulnerabilities and bugs that the community will never fix. But even within the support window, newer versions bring performance improvements, new features, and better tooling. The question is not whether to upgrade, but how to do it safely and with minimal downtime.
The upgrade itself is not rocket science. The tricky part is the combination of small details — replication slots, extension compatibility, configuration drift between old and new clusters, statistics collection, and the behavior of your connection pooler during the switchover. Any one of these can bite you if you are not paying attention.
Preparation
Read release notes. If you want to jump from lets say version 13 to version 18, read them all. There could be some manual steps you need to make.
Plan and test. Upgrades are simple and straightforward, even major upgrades. The problem is in small details which are easy to overlook. Collation, checksums, extensions, forgotten checkpoint, customized statistics targets could make your li
I'm planning to hold a single hacking workshop for April and May combined, covering Masahiko Sawada's talk, Breaking away from FREEZE and Wraparound, given at PGCon 2022. If you're interested in joining us, please sign up using this form and I will send you an invite to one of the sessions. Thanks to Sawada-san for agreeing to join us.
On 4th of March 2026, Amit Kapila committed patch: Allow table exclusions in publications via EXCEPT TABLE. Extend CREATE PUBLICATION ... FOR ALL TABLES to support the EXCEPT TABLE syntax. This allows one or more tables to be excluded. The publisher will not send the data of excluded tables to the subscriber. To … Continue reading "Waiting for PostgreSQL 19 – Allow table exclusions in publications via EXCEPT TABLE."
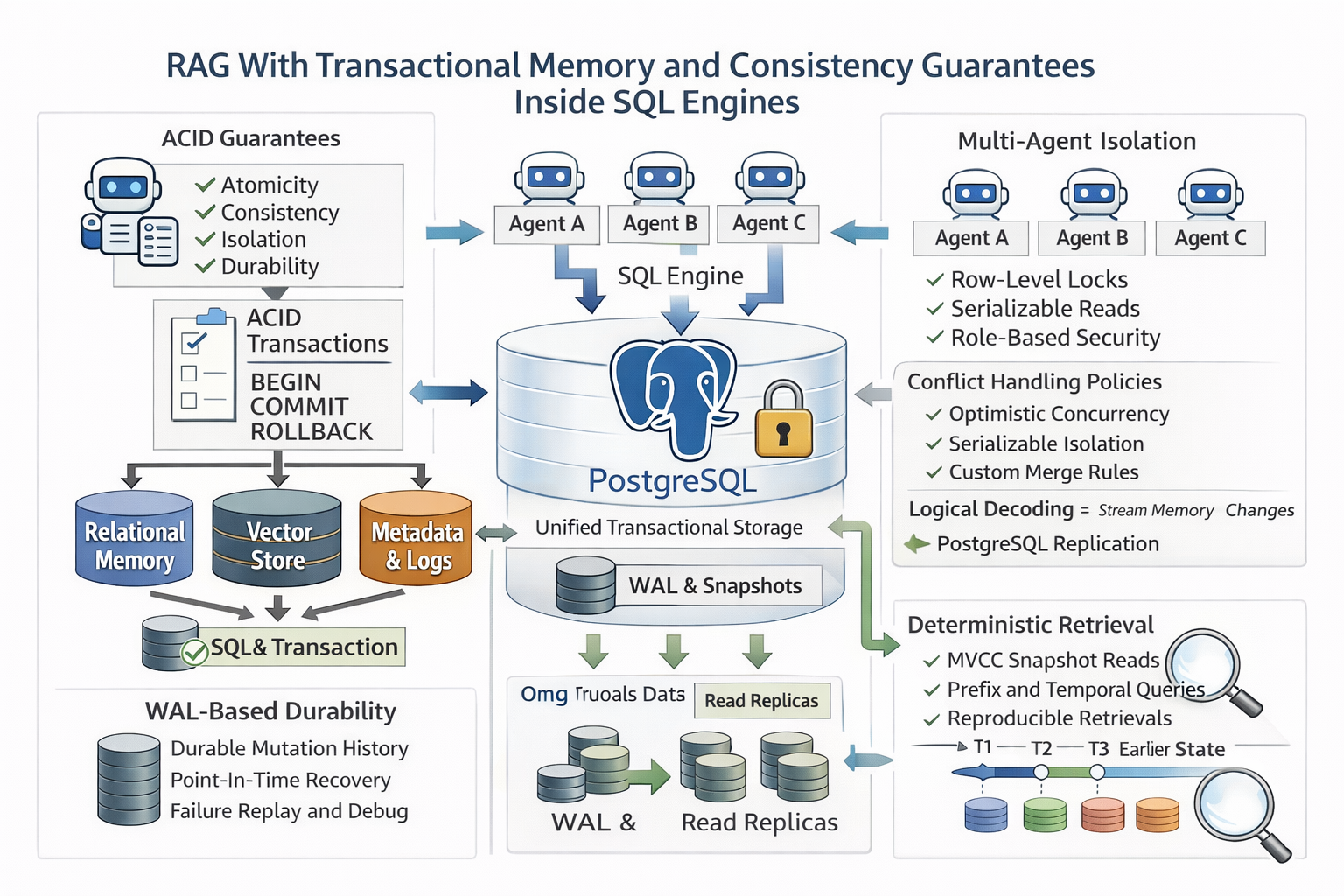
Most RAG systems were built for a specific workload: abundant reads, relatively few writes, and a document corpus that doesn't change much. That model made sense for early retrieval pipelines, but it doesn't reflect how production agent systems actually behave. In practice, multiple agents are constantly writing new observations, updating shared memory, and regenerating embeddings, often at the same time. The storage layer that worked fine for document search starts showing cracks under that kind of pressure.The failures that result aren't always obvious. Systems stay online, but answers drift. One agent writes a knowledge update while another is mid-query, reading a half-committed state. The same question asked twice returns different answers. Embeddings exist in the index with no corresponding source text. These symptoms get blamed on the model, but the model isn't the problem. The storage layer is serving up an inconsistent state, and no amount of prompt engineering can fix that.This isn't a new class of problem. Databases have been solving concurrent write correctness for decades, and PostgreSQL offers guarantees that meet those agent memory needs.
What RAG Systems Are Missing Today
RAG systems depend on memory that evolves over time, but most current architectures were designed for static document search rather than stateful reasoning, creating fundamental correctness, consistency, and reproducibility problems in production environments.
Stateless Retrieval Problems and Solutions
Most RAG pipelines treat retrieval as a stateless search over embeddings and documents. The system pulls the top matching chunks with no awareness of how memory has evolved, what the agent's current session context is, or where a piece of information sits on a timeline. For static document search, that limitation rarely matters. For agent memory, where knowledge changes continuously, it is a real problem.Without stateful awareness, retrieval starts mixing facts from different points in time. One query might retrieve yester[...]
Like much of the world, I have been exploring capabilities and realities of LLMs and other generative tools for a while now. I am focused on using the technology with the framing of my technology-focused work, plus my other common scoping on data privacy and ethics. I want basic coding help (SQL, Python, Docker, PowerShell, DAX), ideation, writing boilerplate code, and leveraging existing procedures. Naturally, I want this available offline in a private and secure environment. I have been focused on running a local LLM with RAG capabilities and having control over what data goes where, and how it is used. Especially data about my conversations with the generative LLM.
This post collects my notes on what my expectations and goals are, and outlines the components I am using currently, and thoughts on my path forward.
The 23rd edition of the Southern California Linux Expo, or SCaLE 23x, took place from March 5-8, 2026, in Pasadena, California. It was another fantastic community-run event with talks you don't get to hear anywhere else, and that incredible open-source community spirit.
While I didn't broadcast any live streams from the conference floor this year, I did end up catching some great talks (fortunately everything's recorded!) and having some deeply rewarding hallway track conversations. A highlight was catching up with folks from LPI, the legendary Jon "maddog" Hall, and Henrietta Dombrovskaya. We had a great discussion around our ongoing PostgreSQL Compatibility initiative: We are continuing to define what "Postgres Compatible" truly means to prevent market confusion and ensure a reliable "standard" for users. If you are interested in contributing to this effort, come join the conversation on our new Discord server:
Postgres once again had a stellar presence at SCaLE with a dedicated PostgreSQL track. We had an entire lineup of trainings and talks, plus a PostgreSQL Booth in the expo hall and the always-popular SCaLE 23x PostgreSQL Ask Me Anything session. A massive thank you to the organizers of PostgreSQL@SCaLE, the trainers, speakers, and all the volunteers who made it happen!
On 26th of February 2026, Andrew Dunstan committed patch: Add non-text output formats to pg_dumpall pg_dumpall can now produce output in custom, directory, or tar formats in addition to plain text SQL scripts. When using non-text formats, pg_dumpall creates a directory containing: - toc.glo: global data (roles and tablespaces) in custom format - map.dat: … Continue reading "Waiting for PostgreSQL 19 – Add non-text output formats to pg_dumpall"