
Ali Vosoughi

PhD Candidate, University of Rochester
World models, multimodal agents, and agentic understanding and generation of 3D scenes.
Ali Vosoughi’s research centers on multimodal foundation models — spanning world models, agentic systems, and 3D scene understanding and generation. His work spans experience with
Apple,
Microsoft Research,
Smule,
Bosch AI Research,
and
DARPA.
654 citations · h-index 12
US Patent US20250124292A1
ICASSP 2026
📧 ali.vosoughi@rochester.edu
📍 CS Department, Wegmans Hall 3211
🍎 Apple
Machine Learning Intern
Agentic Multimodal AI
Agentic Multimodal AI
🎵 Smule AI
Research Scientist Intern
Spatial Audio Generation
Spatial Audio Generation
🏢 Microsoft Research
Research Intern
Audiovisual LLM and Video Understanding
Audiovisual LLM and Video Understanding
🚗 Bosch AI Research
Research Intern
Audio LLM and Counterfactual Learning
Audio LLM and Counterfactual Learning
🛡️ DARPA PTG
Graduate Researcher
Autonomous Multimodal Perception and AR
Autonomous Multimodal Perception and AR
AAAI 2026 Best Demonstration Award Runner-up
Caption Anything in Video (Spatiotemporal Multimodal Prompting)
Caption Anything in Video (Spatiotemporal Multimodal Prompting)
Video Understanding with LLMs
Comprehensive survey with 241+ citations (IEEE TCSVT 2025)
Comprehensive survey with 241+ citations (IEEE TCSVT 2025)
PW-VQA
Causal debiasing for visual question answering with 50+ citations (IEEE TMM 2024)
Causal debiasing for visual question answering with 50+ citations (IEEE TMM 2024)
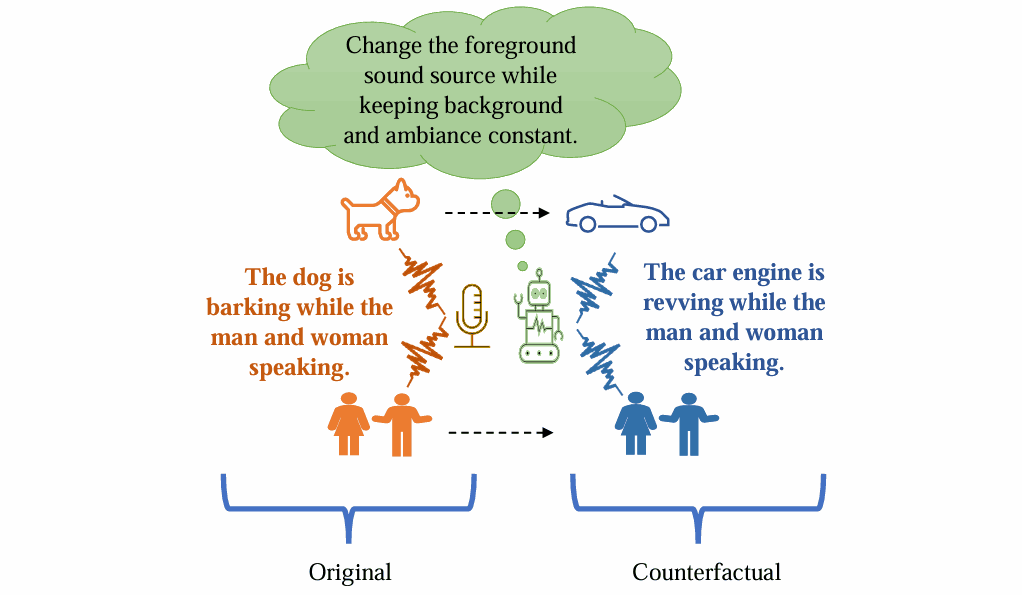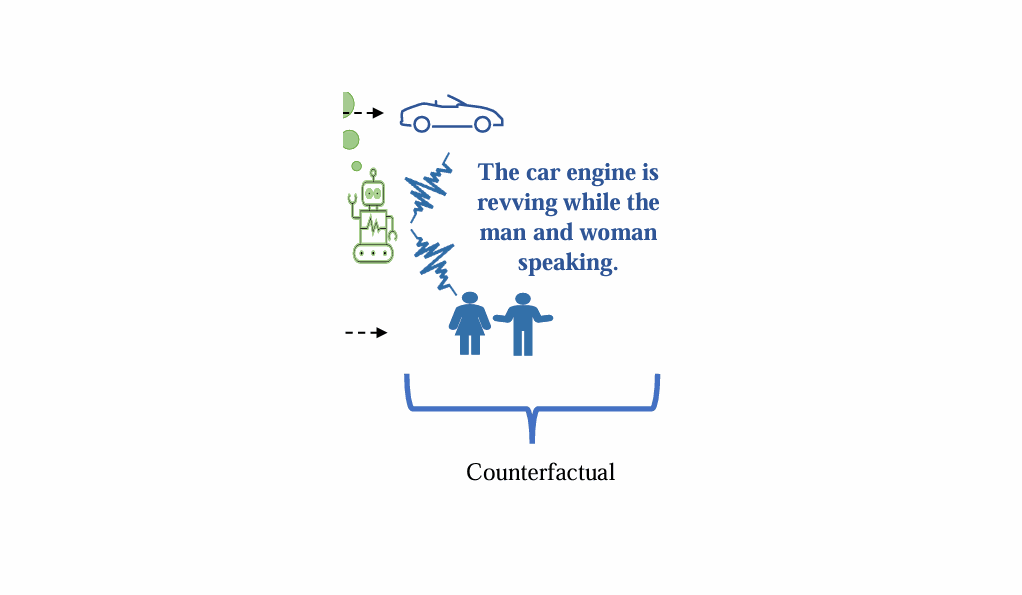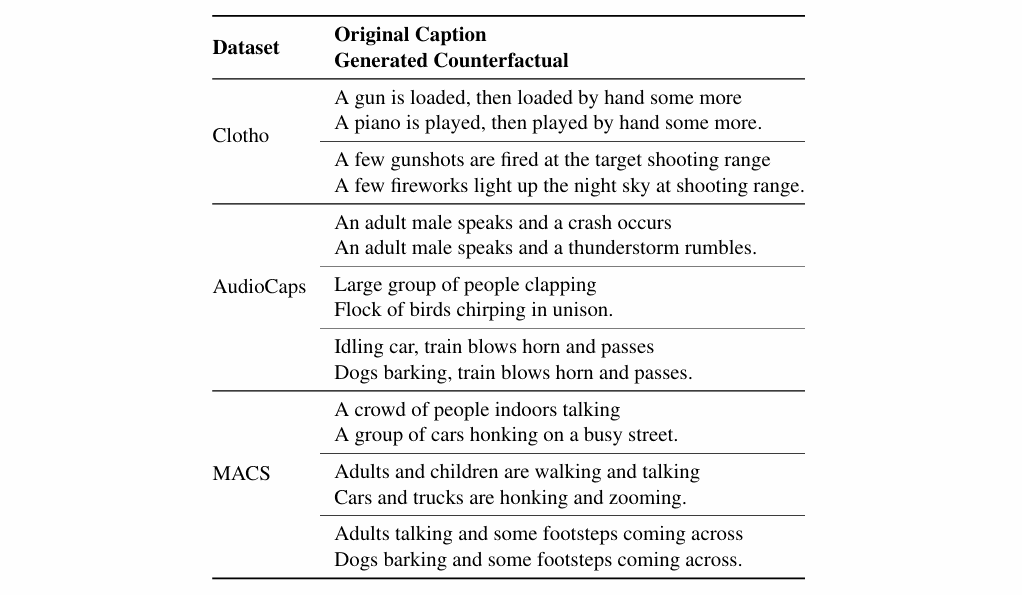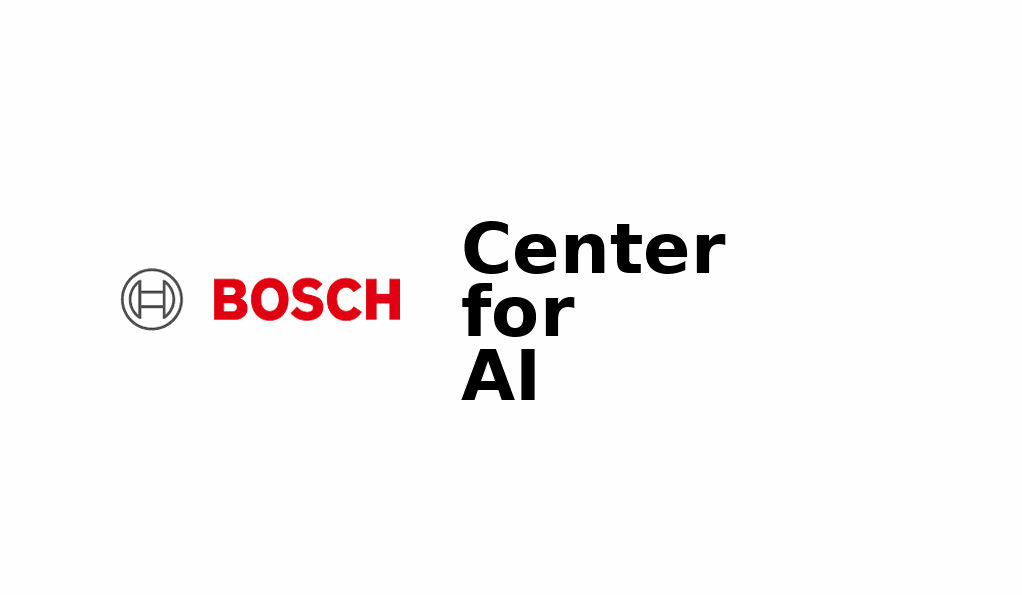
First counterfactual audio methods
ICASSP 2024 + US Patent US20250124292A1 (published Jan 2025)
ICASSP 2024 + US Patent US20250124292A1 (published Jan 2025)
PromptReverb
First text-to-spatial-audio generation at 48kHz (ICASSP 2026)
First text-to-spatial-audio generation at 48kHz (ICASSP 2026)
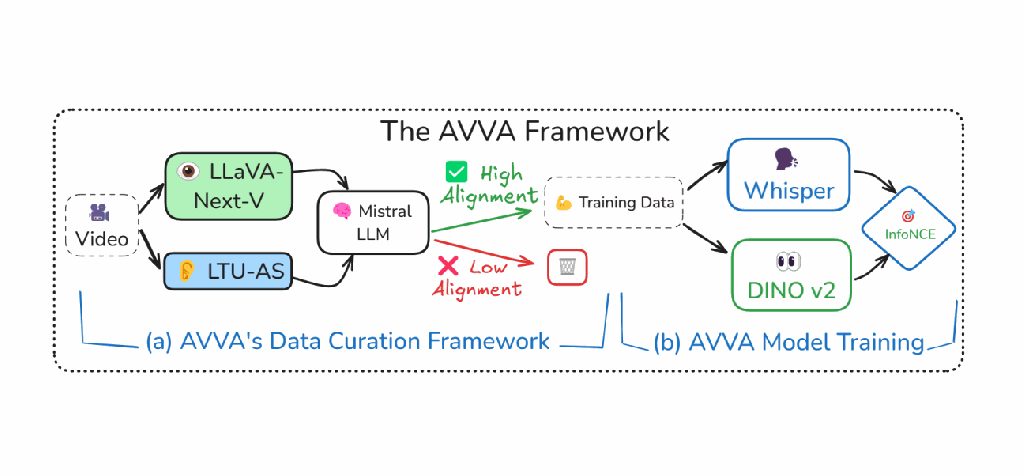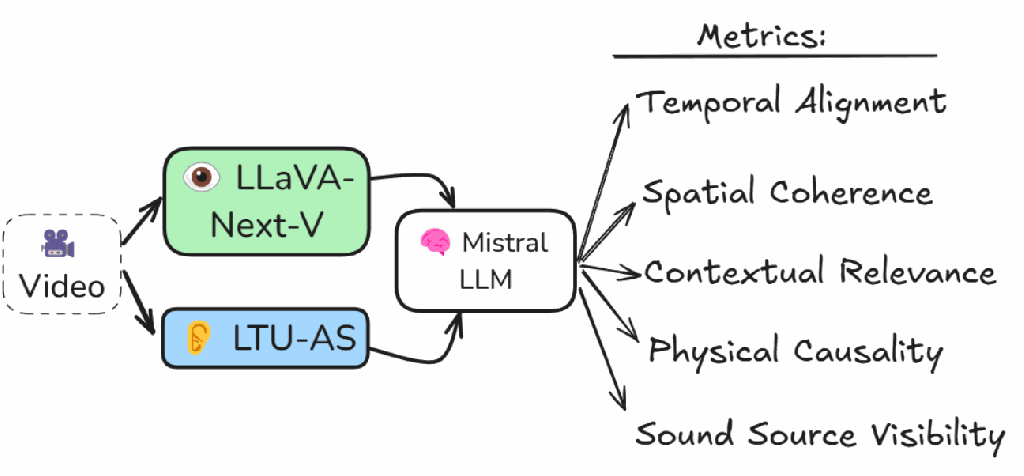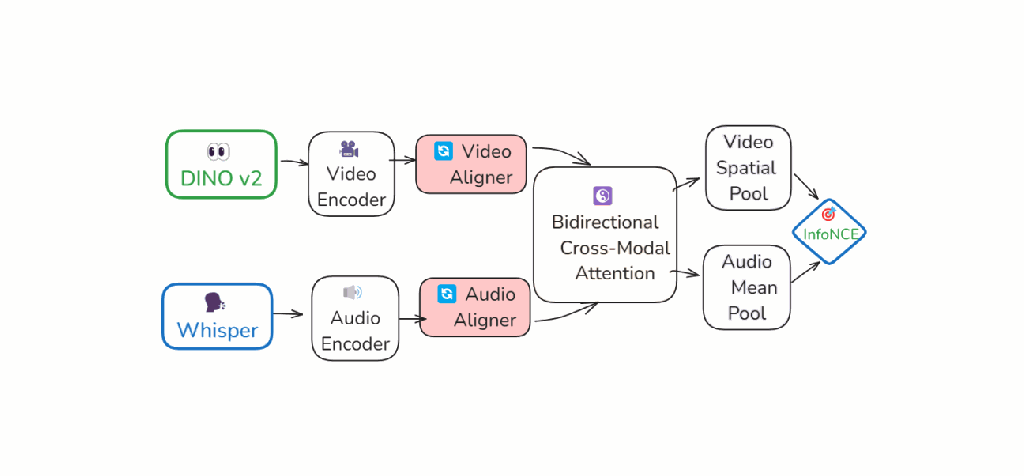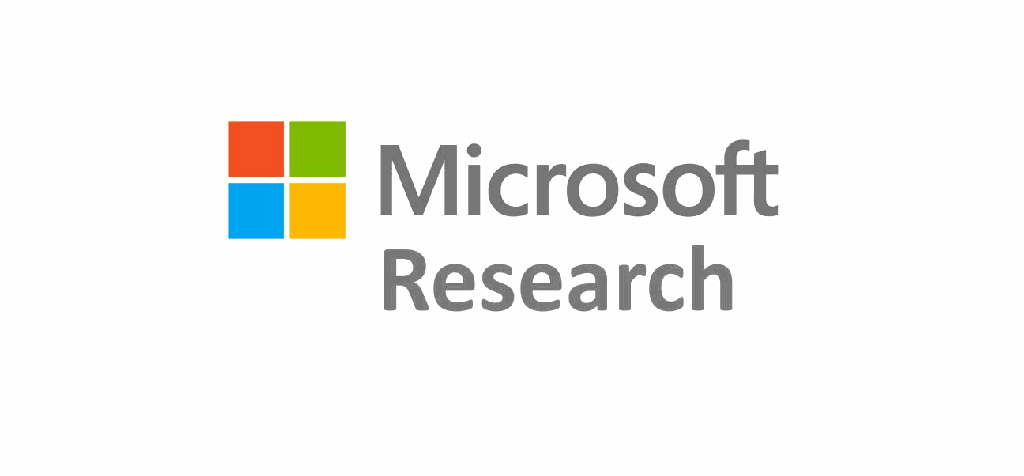
AVVA
Unified audiovisual foundation model with LLM curation (EUSIPCO 2025)
Unified audiovisual foundation model with LLM curation (EUSIPCO 2025)
Autonomous multimodal copilot
Real-time audiovisual AR demonstrations (DARPA)
Real-time audiovisual AR demonstrations (DARPA)
VERIFY benchmark
Reasoning verification framework for multimodal LLMs
Reasoning verification framework for multimodal LLMs
Video LMM Post-Training
Deep dive into video reasoning with large multimodal models
Deep dive into video reasoning with large multimodal models
AVE-2 Dataset
Open audiovisual benchmark for cross-modal event understanding
Open audiovisual benchmark for cross-modal event understanding
Recent News & Updates
02/2026
🏆 AAAI 2026 Best Demonstration Award Runner-up: Caption Anything in Video (Spatiotemporal Video Understanding and Multimodal Prompting)
12/2025
📄 NeurIPS 2025 paper accepted: MMPerspective (Multimodal LLM Reasoning, Video and Visual Perception)
01/2026
📄 ICASSP 2026 paper accepted: PromptReverb (Text-to-Spatial-Audio Generation at 48kHz)
09/2025
✅ Completed research internship at Smule AI (Spatial Audio Generation and Synthesis)
06/2025
🎵 Started research internship at Smule AI (Spatial Audio Generation and Immersive Computing)
03/2025
📊 Published VERIFY benchmark (Multimodal Reasoning Verification for Video and Vision LLMs)
10/2024
🎤 Presented at SANE 2024, DeepMind Boston (Audio Understanding, Video LLMs, and Spatial Audio)
10/2024
📄 ACM Multimedia 2024: EAGLE (Egocentric Video Understanding and Language Generation)
08/2024
💼 Research presentation at Microsoft Research, Seattle (Audiovisual LLM, Video and Audio Understanding)
03/2024
📄 NAACL 2024: OSCaR (Video Object State Captioning, Autonomous Video Perception)
02/2024
📄 IEEE Transactions on Multimedia 2024: PW-VQA (Causal Visual Question Answering, Video Reasoning)
08/2023
🎯 Two ICCV 2023 papers accepted (Audiovisual Sound Separation and Autonomous AR Perception System)
04/2023
🏢 Started internship at Bosch Center for AI (Audio Language Models and Counterfactual Reasoning)
Publications

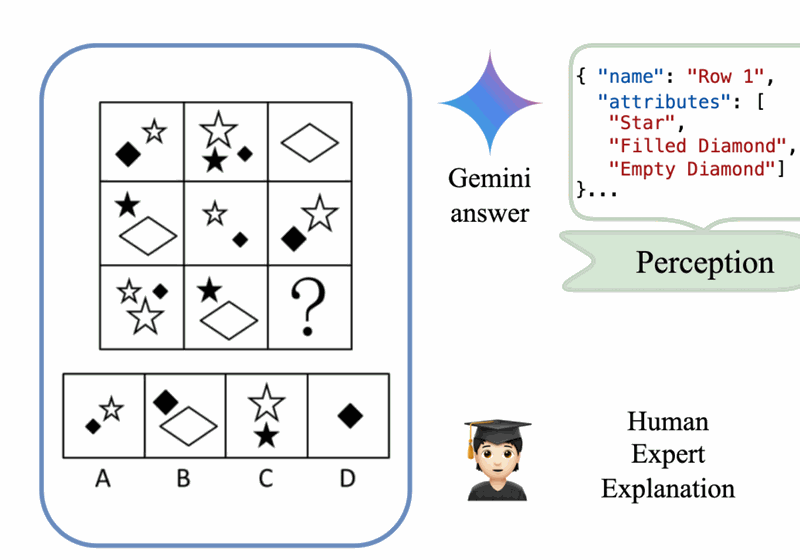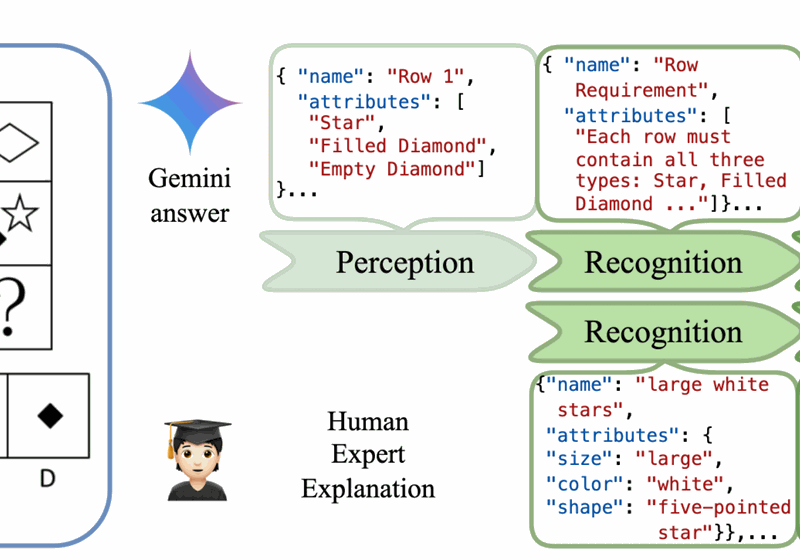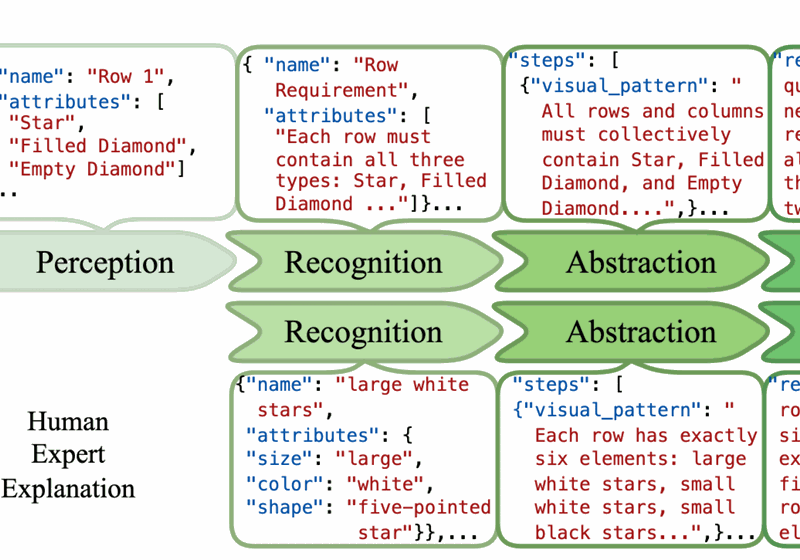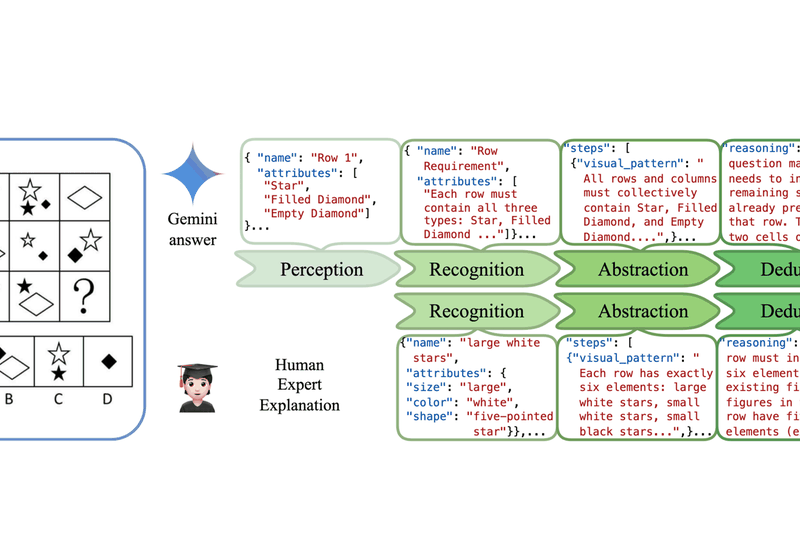
VERIFY: A Benchmark of Visual Explanation and Reasoning for Investigating Multimodal Reasoning Fidelity
Under Review’26
[Paper][Website][🤗 Hugging Face]

EAGLE: Egocentric AGgregated Language-video Engine
ACM International Conference on Multimedia (ACM MM) 2024
[Paper]


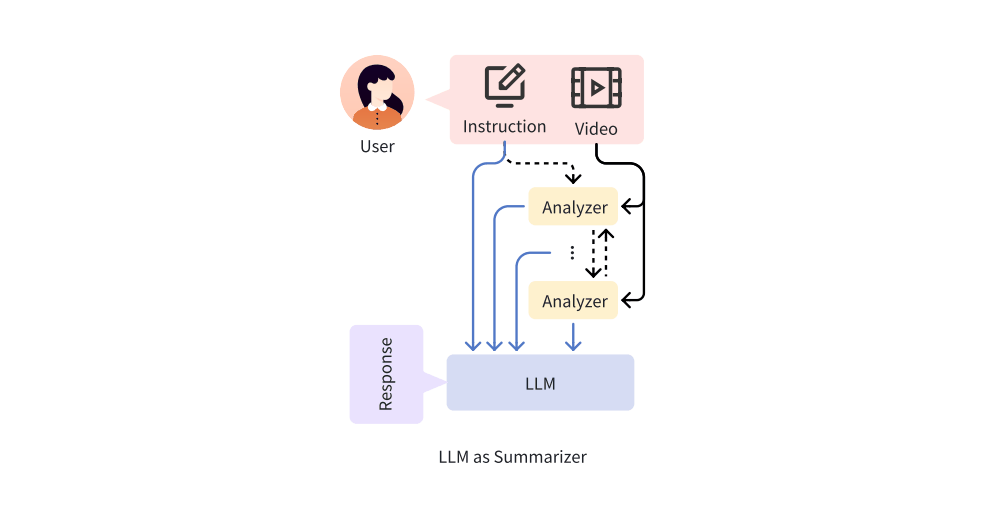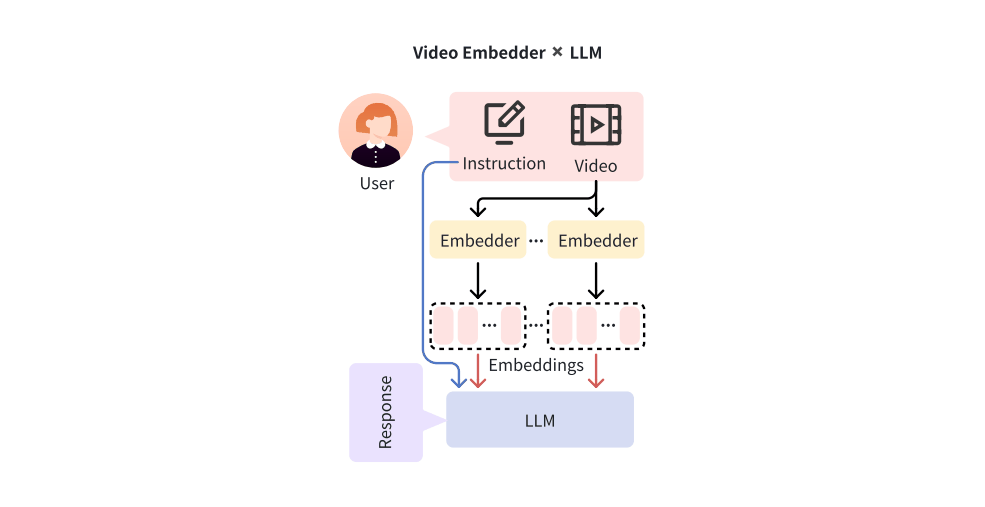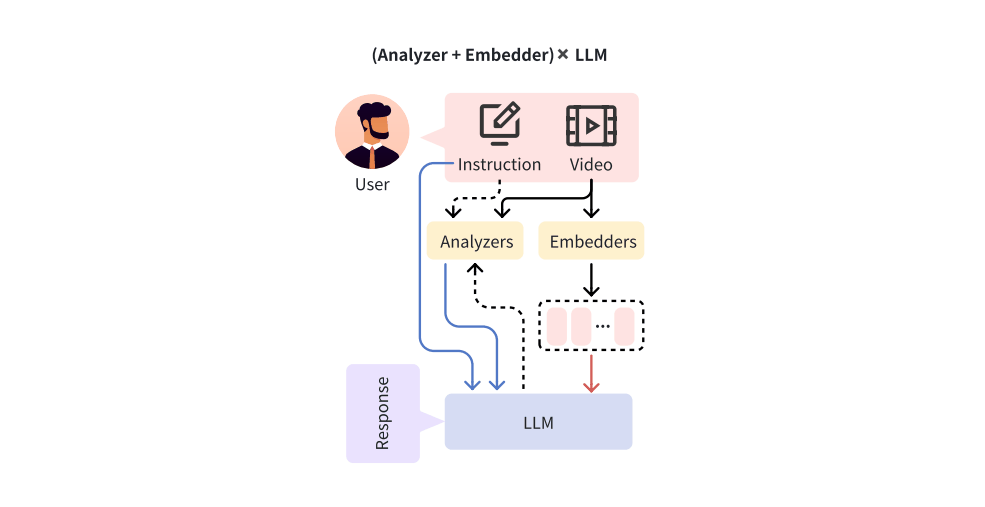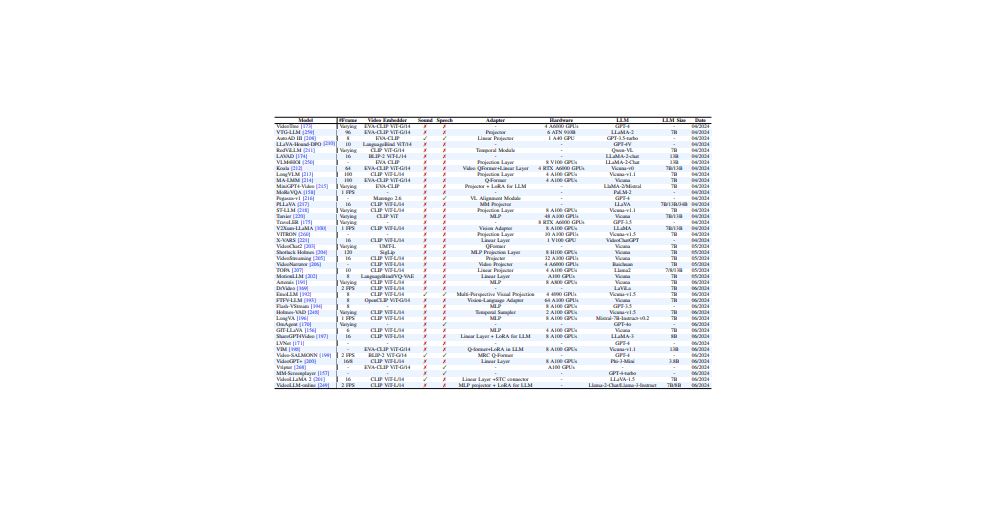

AVSA-Sep: Separating Invisible Sounds Toward Universal Audiovisual Scene-Aware Sound Separation
IEEE/CVF International Conference on Computer Vision (ICCV) 2023: ICCV AV4D Workshop
[Paper]

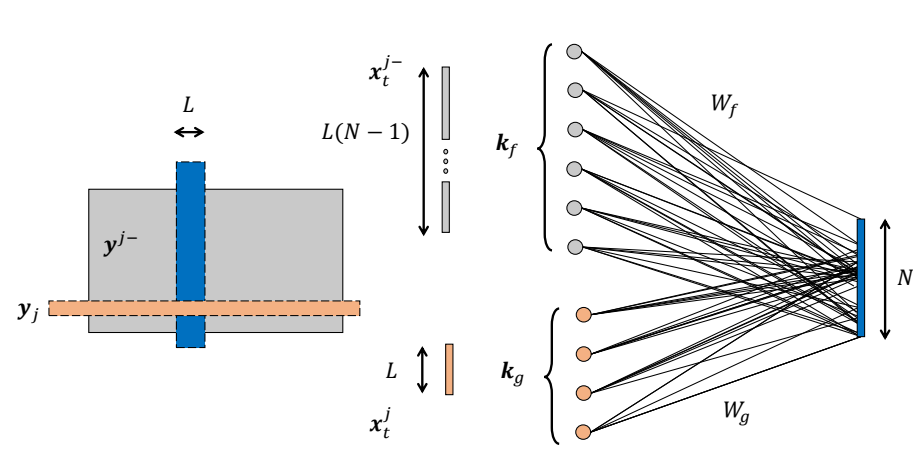
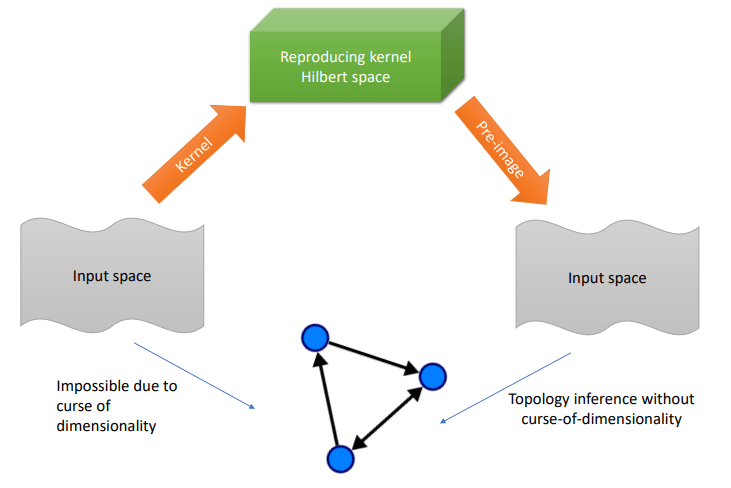
Leveraging Pre-Images to Discover Nonlinear Relationships in Multivariate Environments
European Signal Processing Conference (EUSIPCO) 2021
[Paper]

Personal Gallery


