This research introduces Natural-Language Agent Harnesses (NLAHs) and an Intelligent Harness Runtime (IHR) to externalize and execute the control logic of AI agents in natural language. The framework facilitates systematic study and comparison of agent control patterns, demonstrating operational viability and achieving a 47.2% task success rate on OSWorld benchmarks with NLAHs compared to 30.4% for native code, while re-centering reliability mechanisms on durable, artifact-backed operations.
View blog
This paper investigates the rapidly evolving impact of AI on philosophical questions, particularly within mathematics, advocating for a human-centered approach to its development and integration. It argues that modern AI automates aspects of the creative process itself, necessitating a re-evaluation of intellectual value and the design of ethical frameworks for responsible coexistence.
View blog
Meta-Harness provides an end-to-end optimization framework for LLM harnesses, the external code that dictates how models interact with their environment. The system utilizes an agentic proposer with filesystem access to uncompressed historical code and execution traces, leading to a 7.7-point accuracy improvement in text classification, a 4.7-point average gain in math reasoning, and competitive pass rates on agentic coding benchmarks.
View blog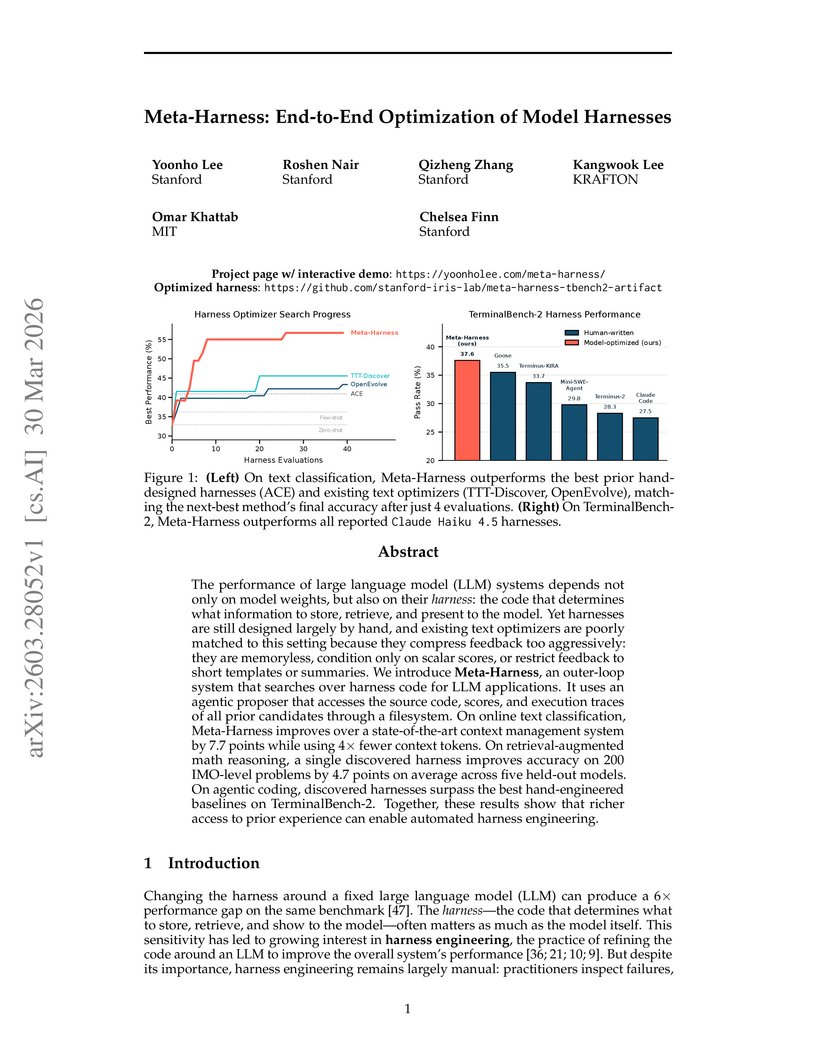
Researchers proposed a neutral-atom quantum computing architecture that executes Shor's algorithm for cryptographically relevant instances with as few as 9,739 reconfigurable atomic qubits, a two-order-of-magnitude reduction from prior estimates, achieving runtimes in days for large factorizations.
View blog
Research from Microsoft Research, KAIST, and Seoul National University reveals that while self-distillation consistently shortens LLM reasoning traces, it can degrade mathematical reasoning capabilities, particularly on out-of-distribution tasks. This performance drop is linked to the suppression of "epistemic verbalization," or expressions of uncertainty, which are found to be critical for robust generalization.
View blog
The Trace2Skill framework automates the creation and adaptation of domain-specific skills for Large Language Model agents by distilling lessons from agent execution trajectories into a single, transferable skill document. This approach, inspired by human expert methodology, improves agent performance and generalizability across different LLM scales and out-of-distribution tasks, demonstrating superior efficiency and transferability compared to existing automated methods.
View blog
VGGRPO, a framework developed at Google, enhances video generation by integrating a Latent Geometry Model with latent-space Group Relative Policy Optimization, enabling "world-consistent" videos with stable camera motion and consistent 3D scene structure. The method improves geometric consistency and overall video quality, particularly in dynamic scenes, while reducing computational overhead by 24.5% compared to RGB-based approaches.
View blog
Researchers from the Technical University of Munich developed GaussianGPT, an autoregressive framework for generating and completing 3D Gaussian scenes by converting continuous 3D scenes into discrete latent grids and modeling them with a causal transformer. The model achieved state-of-the-art performance on 3D chair generation (FID 5.68, KID 1.835) and demonstrated coherent large-scale scene outpainting and completion on indoor scene datasets.
View blog
Researchers at Peking University developed PRBench, a benchmark with 30 expert-curated physics tasks, to evaluate AI agents' ability to perform end-to-end computational result reproduction directly from scientific papers. The study found that while agents show moderate understanding of methodologies, they consistently struggle with translating this into correct code and accurately reproducing numerical data, resulting in a 0% end-to-end callback rate across all tested models.
View blog
A study analyzing on-policy distillation (OPD) for large language models uncovered empirical issues with the sampled-token approach, such as imbalanced feedback and unreliable teacher signals. It introduces a "teacher top-K local support matching" objective, which provides more stable optimization and enhances performance in long-horizon tasks like math reasoning and multi-task agentic training.
View blog
Researchers at Dexmal developed Realtime-VLA V2, a comprehensive framework that enables Vision-Language-Action (VLA) models to execute robot tasks significantly faster than human demonstrations while ensuring smooth and accurate operation. The system achieves execution speeds comparable to casual human performance on diverse manipulation tasks, including precision placement.
View blog
Composer 2 is a specialized Mixture-of-Experts model developed for agentic software engineering, designed to autonomously tackle complex coding tasks. It achieves a 61.3% accuracy on the CursorBench-3 internal benchmark (a 37% relative improvement over its predecessor), demonstrating competitive performance against frontier models on public benchmarks while maintaining a favorable cost-performance ratio.
View blog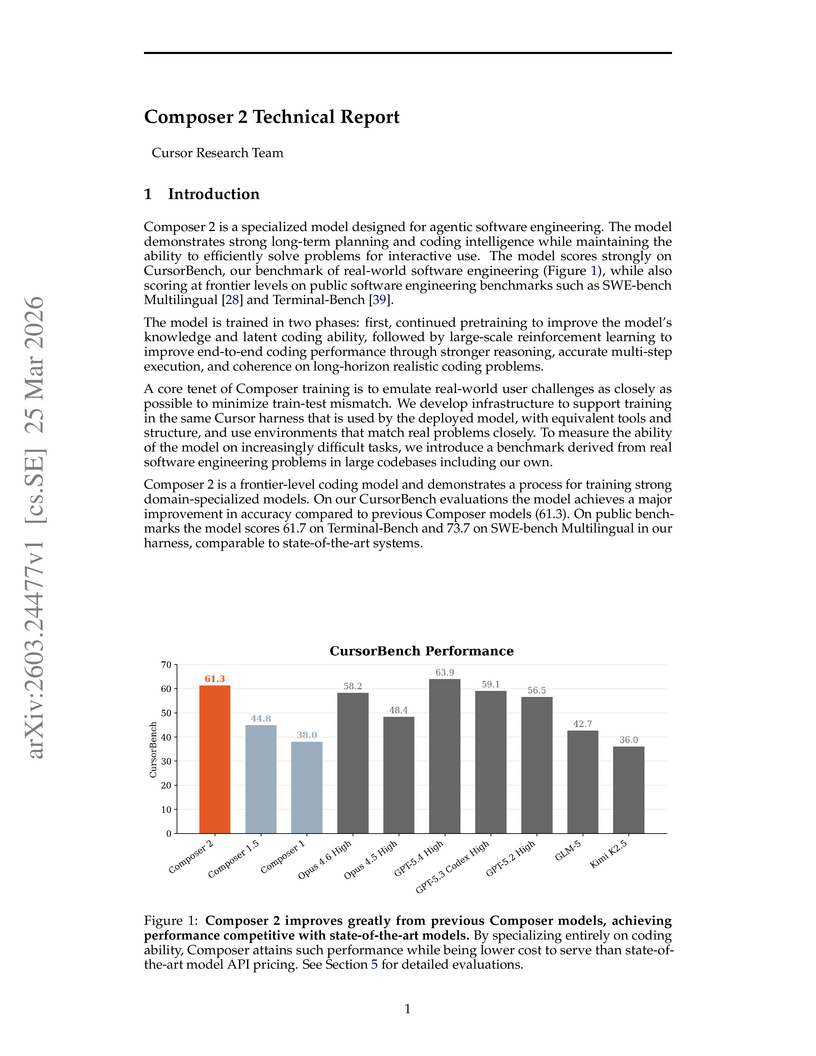
Agentic Variation Operators (AVO) empower large language models to function as autonomous, iterative optimizers in evolutionary search for high-performance code. This framework successfully discovered multi-head attention kernels on NVIDIA Blackwell B200 GPUs that achieved up to 3.5% higher throughput than cuDNN and 10.5% higher than FlashAttention-4, alongside effective transferability to grouped-query attention.
View blog

Researchers at FAIR at Meta and collaborators developed AIRA , an AI research agent designed to overcome structural bottlenecks in autonomous machine learning research. It achieved a mean Percentile Rank of 76.0% on MLE-bench-30 over 72 hours, demonstrating sustained performance improvements by enhancing compute throughput, evaluation reliability, and agent operational capabilities.
View blog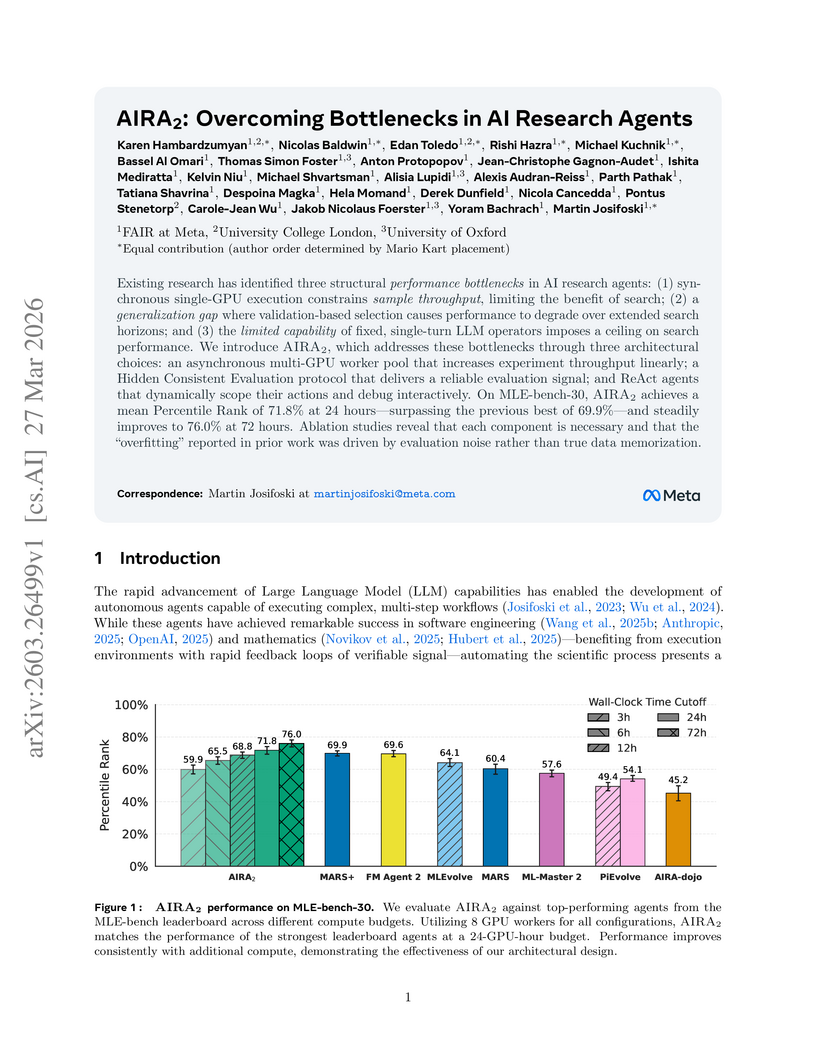
Researchers at HKUST (GZ) developed VLA-OPD, a framework that combines offline supervised fine-tuning and online reinforcement learning for Vision-Language-Action models through on-policy distillation. It utilizes a Reverse-KL divergence objective to provide dense, token-level supervision from an expert teacher on student-generated trajectories, leading to improved sample efficiency (e.g., 3x faster convergence on LIBERO-Long) and robust performance while mitigating catastrophic forgetting.
View blog
Researchers at Shanghai AI Laboratory introduced Intern-S1-Pro, the first scientific multimodal foundation model with one trillion parameters, which achieved superior performance on over 100 specialized scientific tasks and competitive results in general AI tasks. The model validated the "specializable generalist" concept, demonstrating that a large generalist model can outperform specialized counterparts in several scientific domains.
View blog
A framework called Hybrid Memory enables video world models to maintain spatiotemporal consistency for dynamic subjects moving out of and back into the camera's view. This work from Huazhong University of Science and Technology and Kuaishou Technology introduces the HM-World dataset and the HyDRA architecture, which achieved superior dynamic subject consistency and overall generation quality compared to baselines on the new dataset and outperformed a commercial model in zero-shot evaluation.
View blog
Researchers from the PAN Team at MBZUAI introduced WR-Arena, a new benchmark designed to assess advanced capabilities of world models beyond short-term prediction, including action simulation fidelity, long-horizon forecast, and simulative reasoning for planning. Evaluations revealed that current models struggle with error accumulation in long-horizon simulations and consistently performing environment-level interventions, with action-state aligned models showing improved planning performance.
View blog
