-
-

Object Segmentation
-
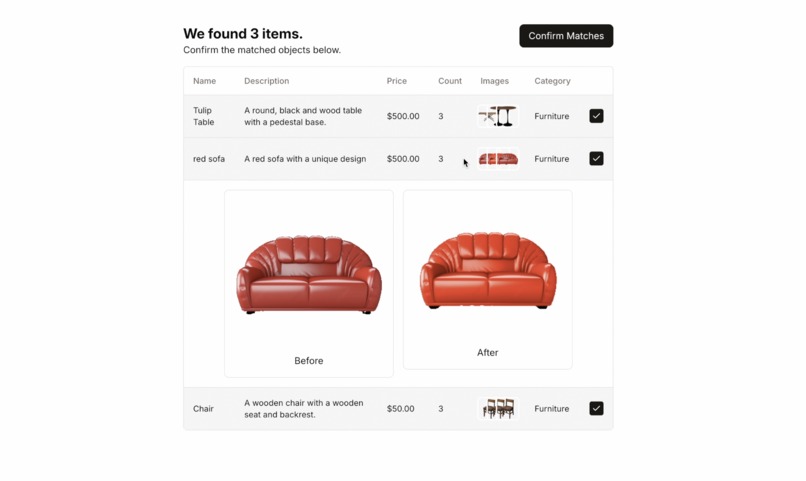
Item Matching / Identification
-
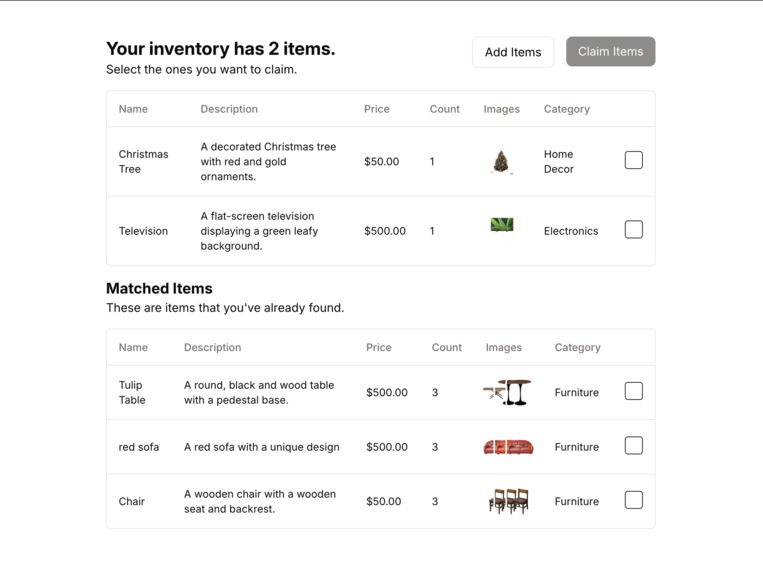
Inventory Management
-

Logo




Inspiration
After the recent hurricanes in Florida, one of our team members who is from Florida had damage to their house. Normally, the process for filing an insurance claim after disaster is extremely cumbersome, requiring proof of all items and their value that were in the house before the disaster. This is very hard for disaster victims to prove in such a tough situation, which dissuades many people from filing insurance claims that cover the full value of all the items they lost.
What it does
Our app allows homeowners to record a video of their house, while our innovative AI automatically catalogues all items in your house and their approximate value. After a disaster, you an rescan your house and we automatically suggest items that might be lost to add to your insurance claim, with image proof of the before and after.
How we built it
Our frontend is built with next.js. Our backend uses Flask and sqllite. We also use xrpl in order to put items on the blockchain for proof of their existence before the disaster. Here are the steps our AI uses to process videos and pictures into items:
- The video is stitched together into a large panorama with OpenCV
- We use YOLOv8 and Meta's segment anything model to generate areas of interest on the image.
- We use Hyperbolic's inference (Qwen2 VL7B) to analyze each area and decide if it is an object to record and find its estimated monetary value
- We place all images in ChromaDB to group/count items of the same type and match images before and after disaster. We originally used ResNet for our embedding for the vector database in order to compare items, but later found all-MiniLM-L6-v2 to work better for vector encoding. The ResNet embeddings were too high dimensional.
- We generate a pdf claim to submit to the insurance company based on items that didn't appear after the disaster and were added by the user.
Challenges we ran into
- Segmentation problem: We tried a lot of different things in order to segment images well. We tried the segment everything model, SAM+yolo, and tried asking gemini to bounding boxes (it's the only vision language model that advertises this capability). We found SAM+yolo worked the best by far but only after lots of iteration and tuning.
- System Design: lots of iteration required and thinking about the customer. For simplicity chose to host a single AWS EC2 instance although seriously considered hosting multiple servers for each general task like segmentation.
- Video Panorama: How do you do segmentation on a video without getting duplicate items across frames? Our solution was to turn the video into a large image and run our machine learning on this image.
- CORS struck us once again.
Accomplishments that we're proud of
Super fast Segment Everything + Yolo + recognition + grouping pipeline that robustly recognized and catalogued items from video. Well designed and aesthetic front-end.
What we learned
There are no power outlets in SF. We learned how to deploy an EC2 instance, and also how to use vector databases.
What's next for CLaiM
We would like to
Built With
- amazon-ec2
- amazon-web-services
- chromadb
- flask
- nextjs
- python
- s3
- segment-anything
- sqlite
- yolo






Log in or sign up for Devpost to join the conversation.