-
-
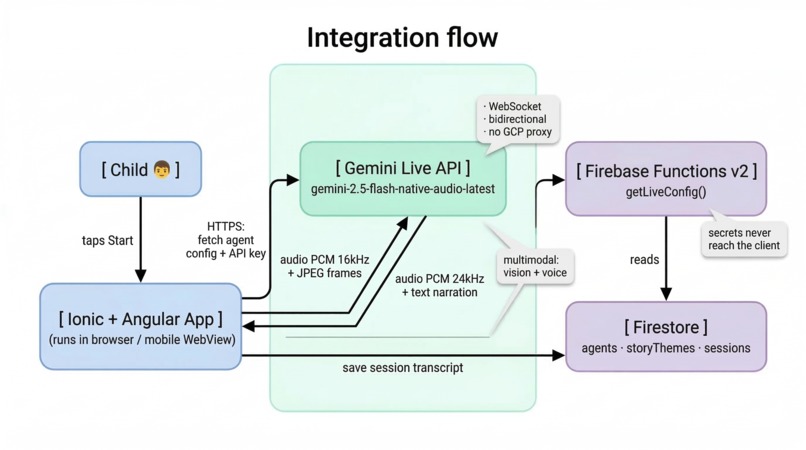
Integration Diagram

Inspiration
Parents often use stories to help children process complex emotions: fear of the dark, school anxiety, or frustration. However, traditional books are static; they cannot "see" a child's lip quiver or hear the hesitation in their voice.
Cuentopia Live explores a new frontier: Responsive Storytelling. Instead of a fixed narrative, we envision stories that breathe and adapt alongside the child. This project is a technical exploration of how real-time multimodal AI can transform a passive activity into an empathetic, two-way interaction. Our goal for this hackathon is to validate the core loop: an AI narrator that adjusts its plot and tone based on live emotional signals.
What it does
Cuentopia Live is a multimodal prototype that turns a device into an empathetic storyteller using the Gemini 2.5 Flash Multimodal Live API.
- Real-time Interaction: The child speaks to the narrator, creating a natural dialogue with sub-100ms latency.
- Visual Context: The device camera streams facial frames to detect engagement or distress using a specialized "Vision Nudge" system.
- Dynamic Pivot: Gemini processes these inputs simultaneously via the official SDK. If it detects cues like confusion or fear, it triggers a "narrative pivot" to steer the story toward a more supportive or calming direction.
Conceptually, we model the interaction as: $$E_{state} = f(\text{facial expression}, \text{voice tone}, \text{story context})$$
Note: This is a creative tool for guidance, not a clinical diagnostic instrument.
How we built it
We architected a high-performance loop designed for low-latency multimodal streaming following a Strict Hexagonal Architecture:
- Frontend: Built with Angular 20 (Signals) and Ionic 8. We use Signals for fine-grained state management of the audio/vision streams, ensuring the UI remains fluid while processing heavy binary data (PCM 16kHz audio and JPEG frames).
- AI Orchestration: We use the official @google/genai SDK to manage the persistent WebSocket connection, enabling a direct and secure bridge between the child and the model using the
ai.live.connect()method. - The Engine: Gemini 2.5 Flash (Native Audio) handles interleaved audio and video frames with incredible reasoning speed and native audio output (24kHz).
- Backend: Firebase Functions v2 for secure API delivery and Firestore for dynamic agent orchestration (narrator personas: Leo, Valentín, Luna, Chispa).
Challenges we ran into
- Multimodal Latency: Balancing high-quality voice conversation with video frame analysis. We optimized the capture rate and the BidiGenerateContent frames to maintain a "live" feel on mobile hardware.
- Privacy Guardrails: Working with children's data is a huge responsibility. We implemented transient processing: frames are analyzed in-flight by the API and never persisted, ensuring Privacy by Design.
- Hexagonal Complexity: Decoupled the Gemini SDK from our core domain logic. This was a challenge but resulted in a more robust and testable codebase where the business logic is pure TypeScript.
Accomplishments that we're proud of
- Seamless SDK Integration: Successful implementation of the official
@google/genaiSDK while maintaining a complex audio/vision capture loop. - Low-Latency Pivoting: Achieving near-instant narrative shifts when the agent detects a change in the child's reaction.
- Reactive UI: Using Angular Signals to create a "Vision Scanning" effect that makes the child feel truly seen by the agent.
What we learned
- Agent Direction vs. Prompting: In live interactions, prompt engineering evolves into "directing" a character. We learned to guide Gemini to balance its roles as a narrator and an emotional anchor.
- Bandwidth Management: Real-time multimodal apps require careful orchestration of data streams to avoid saturating the client's connection while sending continuous binary frames.
- The Power of Empathy: Even subtle shifts in a story's tone can significantly increase a child's sense of safety and engagement.
What's next for Cuentopia
The journey of Cuentopia is just beginning:
- Collaborative Drawing: Integration of Gemini's vision to let children draw characters that the AI then brings to life in the story.
- Advanced Pedagogical Frameworks: Partnering with child psychologists to refine how the AI responds to specific developmental milestones.
- Long-term Memory: Using Firestore to allow the agent to remember a child’s progress and help them overcome recurring fears over multiple sessions.
Built With
- angular.js
- firebase
- firestore
- gemini-2.0.live
- google-cloud
- google/genai
- ionic
- typescript
- websockets


Log in or sign up for Devpost to join the conversation.