-
-
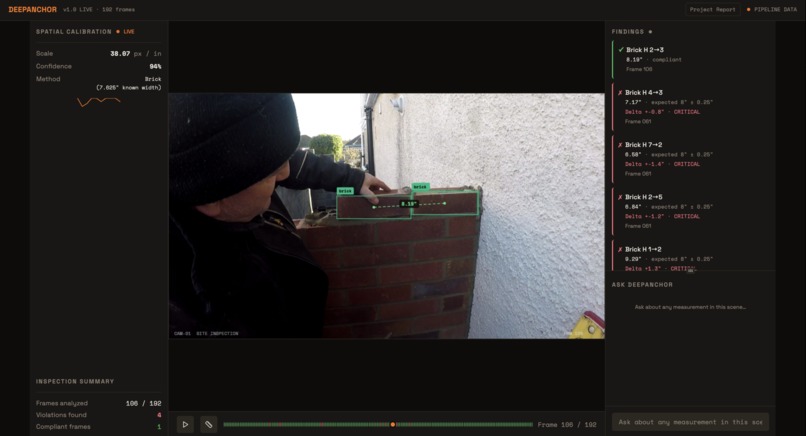
View construction footage live, with precision on measurements for live footage. Platform backed by our DeepAnchor model architecture.
-
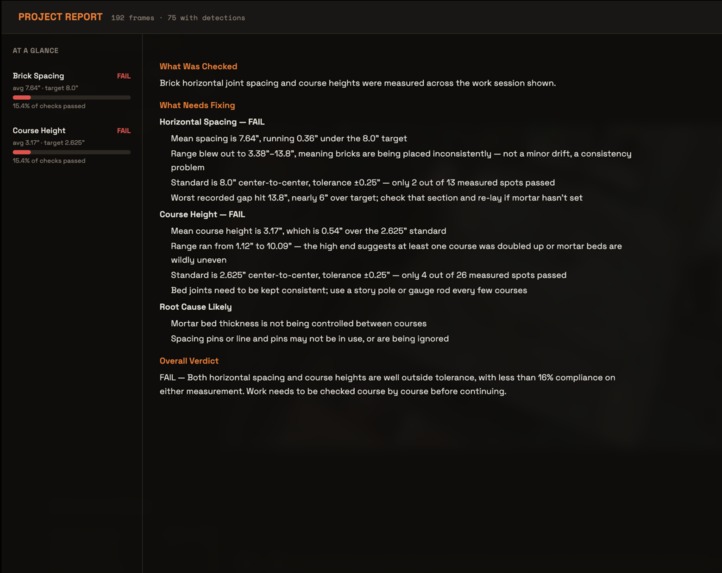
Summaries of alignment / structural issues powered by our language model. Stay aware of potential construction issues by using our model.


Inspiration
Construction inspections (stud spacing, rebar spacing, outlet heights, clearances) depend on real measurements, but vision-language models tend to hallucinate or stay qualitative when asked for distances in meters. DeepAnchor is motivated by closing this perception gap by grounding images in physical units using standardized construction objects as scale anchors.
What it does
DeepAnchor turns a monocular construction image into a measurable scene by:
- Detecting known-dimension “anchor” objects (e.g., bricks, CMU blocks, electrical boxes).
- Estimating depth structure to keep measurements consistent across planes.
- Calibrating a robust pixel-to-meter scale (median across anchors, reject outliers).
- Converting pixel distances into meters and injecting the resulting measurements as structured facts into a VLM prompt for inspection reasoning.
How we built it
Architecture / pipeline
Anchor detection: Run an object detector to get bounding boxes, classes, and confidence for anchors. Depth estimation: Produce a dense depth map (relative depth) and compute per-object depth summaries; group anchors/targets by depth plane to avoid mixing surfaces. Scale calibration: For each anchor, compute pixels-per-meter using its known real-world dimension; aggregate via robust statistics (median) and drop outliers. Measurement extraction: Convert pixel distances to meters using the calibrated scale (optionally plane-aware). VLM grounding: Provide the VLM a structured “measurement JSON” (anchors used, scale, measured distances, uncertainty) so final inspection answers are grounded.
Tech stack Language: Python Deep learning framework: PyTorch Detection: YOLO-family model (Ultralytics-style workflow) for anchor bounding boxes Depth: Depth Anything v2 (or equivalent monocular depth model) Image I/O + utilities: OpenCV, NumPy Experiment tracking / evaluation: simple scripts + metrics (MAE), optional Weights & Biases Packaging / runtime: Conda environment, CUDA GPU acceleration when available Interface (optional): a small CLI + JSON outputs; can be wrapped into a FastAPI service for a demo
Challenges we ran into
Monocular scale ambiguity: Depth from a single image is not metrically scaled; you need anchors to convert “relative depth” into real units. Plane mismatch: Anchors on one surface can’t safely calibrate measurements on another without depth-plane checks. Anchor reliability: Occlusions, partial views, orientation changes, and imperfect boxes can create bad scale estimates—requiring outlier rejection and robust aggregation. Field conditions: Motion blur, glare, dust, low light, and clutter reduce detection quality and measurement stability.
Accomplishments that we're proud of
Built an end-to-end measurement pipeline (detect → calibrate → measure → ground a VLM) that produces distances in meters from monocular images. Made calibration robust by using multiple anchors + median aggregation + outlier filtering instead of trusting one reference object. Produced structured measurement outputs that are easy to audit (what anchors were used, what scale was computed, what distances were measured).
What we learned
The main bottleneck for VLMs in construction isn’t knowledge of codes/specs—it’s lack of metric grounding. Relative depth is useful for consistency (separating planes/surfaces), but anchors are what make measurements real. Robust statistics and explicit uncertainty are necessary to make results trustworthy in messy environments.
What's next for DeepAnchor
Video-first: stabilize measurements over time with tracking + temporal filtering for bodycam/GoPro footage. Spec checking: compare measured values to project tolerances (e.g., 16” OC studs, rebar spacing) and auto-generate pass/fail reports. More anchors + trades: extend anchor library and detectors for plumbing/HVAC/electrical-specific references. BIM integration: align as-built measurements with BIM to flag deviations automatically. Better geometry: incorporate segmentation and/or multi-view cues when available to improve robustness on hard angles and partial occlusions.
Link to our paper (preprint):
https://drive.google.com/file/d/1UyB__PCuIXtESU3UvtR8nCWDwem_d02G/view?usp=sharing
Built With
- amazon-web-services
- api)
- cuda
- gpu
- nvidia
- openai
- python
- pytorch
- streamlit
- typescript

Log in or sign up for Devpost to join the conversation.