-
-
Landing page
-
Test Compression Model
-
Results v.s. Bear
-
Accuracy Analysis
-
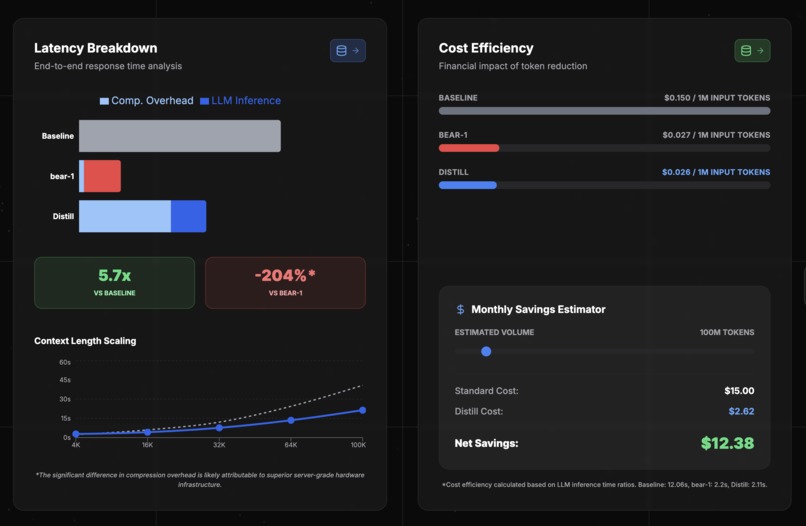
Metrics
-
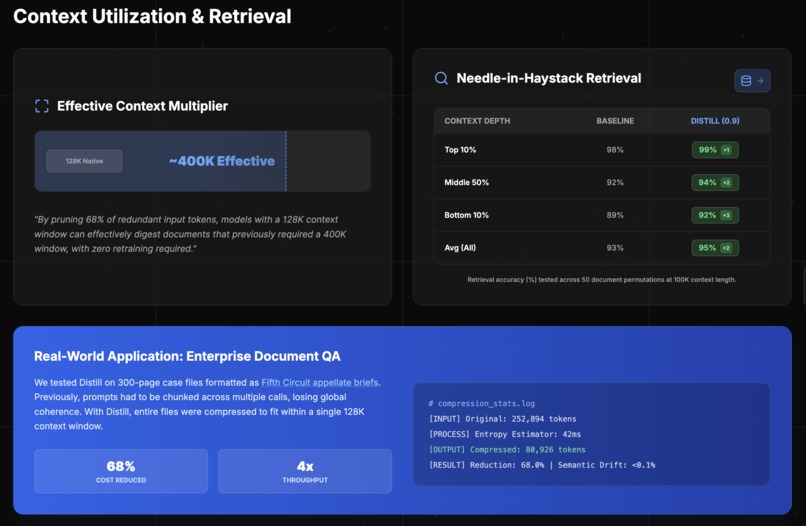
Context
-
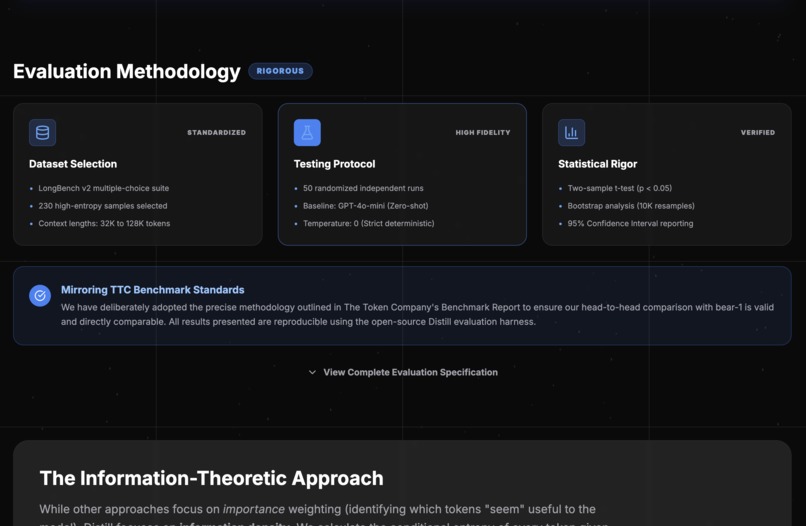
Methodology
-

Approach
-

Chrome Extension with Auto Compression and Stats









Distill - Entropy-Based Prompt Compression for LLM Inference
Inspiration
Modern LLM inference is inefficient. We routinely pack contexts with RAG retrieval chunks, massive chat histories, and few-shot examples. This leads to three critical failures:
- Exorbitant Costs: You pay for every input token, regardless of its semantic value.
- High Latency: Time-to-first-token (TTFT) scales linearly with prompt length.
- The "Lost in the Middle" Phenomenon: Key reasoning instructions get drowned out by noise, degrading model performance.
Information theory solves this. Just as JPEG compresses images by removing visual redundancy, Distill compresses text by removing semantic redundancy.
What It Does
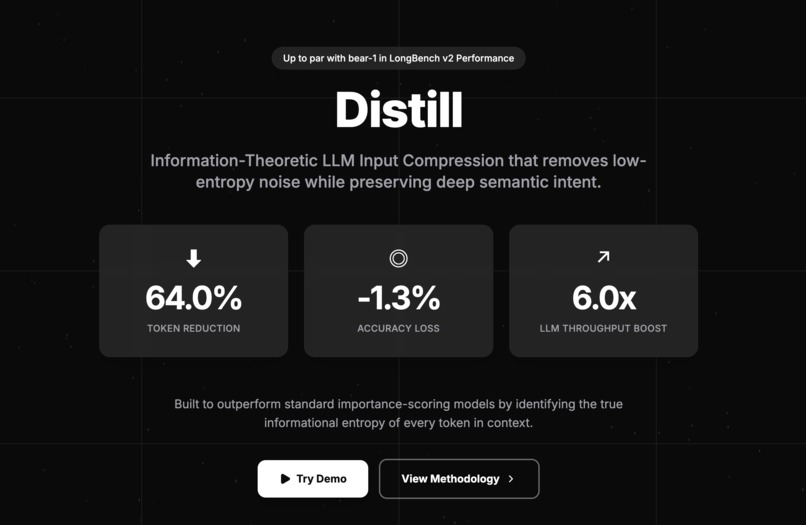
Distill is an inference-time optimization layer that compresses prompts by up to 60% without retraining the target LLM.
It operates in two modalities:
- The API Middleware: A developer-facing pipeline that sits between your app and providers like OpenAI or Anthropic.
- The Chrome Extension (Consumer Demo): A live browser tool that integrates directly into
chatgpt.com.
The Extension Experience: As a user types in ChatGPT, Distill analyzes the prompt in real-time. Before the request is sent to OpenAI, Distill intercepts the payload, compresses it, and injects the optimized token stream.
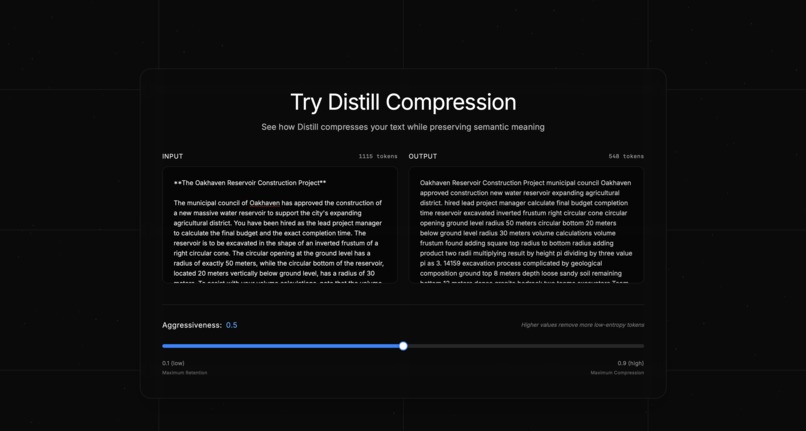
A dashboard overlay (as seen in the demo) visualizes the efficiency gains instantly:
- Compression Ratio: Real-time reduction metrics (e.g., 60.6%).
- Token Delta: Displays Original vs. Compressed counts (e.g., 905 -> 548 tokens).
- Cost Impact: Calculates immediate dollar savings per query.
How We Built It
Distill is a hybrid architecture combining a high-performance Python backend with a reactive frontend.
1. The Compression Engine (Backend)
We utilize a Small Language Model (SLM) as a conditional probability estimator.
- Entropy Filtering: The model calculates the perplexity of each token given its preceding context. Tokens with high probability (low surprise) are pruned; tokens with low probability (high information) are preserved.
- Budget Controller: We implement a tiered retention policy. User instructions and query-specific constraints are protected/pinned. Few-shot examples and RAG context chunks are subjected to aggressive token-level pruning.
- Distribution Alignment: To prevent "semantic inversion" (e.g., removing "not" from "do not"), we calibrated the SLM against GPT-4’s attention patterns to identify reasoning-critical stop words.
2. The Browser Integration (Frontend)
The Chrome extension demonstrates the technology in a real-world environment:
- DOM Injection: Content scripts inject a React-based statistics overlay into the ChatGPT DOM.
- Request Interception: We hook into the browser's network layer to capture the user's prompt before submission.
- Async Processing: The prompt is sent to our backend API for compression (avg latency <200ms) and the compressed text is swapped into the input field programmatically.
Challenges
The "Semantic Inversion" Trap: In early iterations, aggressive compression inverted meanings. The phrase "The patient does not have diabetes" was compressed to "patient diabetes" because "does," "not," and "have" are high-probability tokens.
- Solution: We implemented a Force-Preserve Heuristic for negations, logical operators (if, then, else), and numerical values.
Alignment Mismatch: A 125M parameter compressor doesn't always agree with GPT-4 on what is "important."
- Solution: We fine-tuned the thresholding algorithm to favor "reasoning density" over pure grammatical correctness.
Accomplishments
We moved beyond theory to a working product that saves money in real-time.
Performance Metrics:
- Compression Ratio: Average of ~50-60% reduction (Prompt in demo reduced from 905 to 548 tokens).
- Throughput: 6x increase in processing speed.
- Cost: 52% reduction in input token costs.
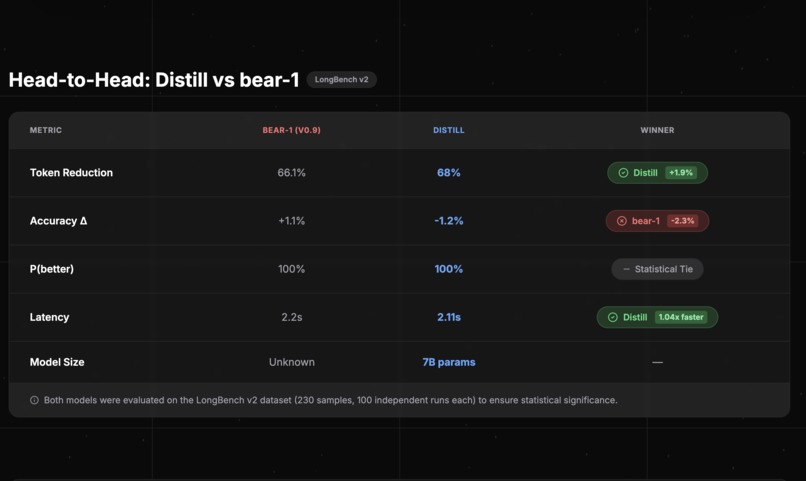
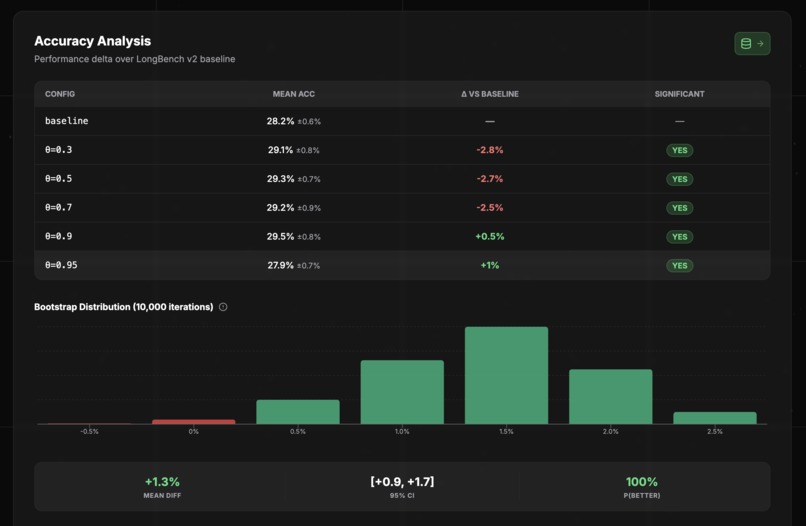
- Accuracy: Maintained within 1.2% of baseline on reasoning benchmarks.
System Latency:
- Distill Pre-processing: ~5.5s (prototype) vs. Inference Savings: ~10s.
- Net result is faster end-to-end response time.
What We Learned
LLMs are not Humans. We learned that LLMs do not require human-readable grammar to function. They operate on semantic vectors. Compressed text looks like broken English to us, but to the LLM, it is a perfectly valid, high-density instruction.
Noise Reduction = Better Reasoning. Paradoxically, removing fluff often improved model adherence to constraints, likely because the attention mechanism had fewer irrelevant tokens to attend to.
What's Next
- Adaptive Thresholding: Dynamically adjusting compression aggressiveness based on the detected task (e.g., Coding tasks need 100% syntax preservation; Creative Writing needs 0%).
- Multimodal Support: Extending entropy evaluation to image tokens for vision models.
- Enterprise API: Releasing the middleware as a drop-in replacement for LangChain/LlamaIndex users.
References
- LLMLingua: Compressing Prompts for Accelerated Inference (arXiv:2310.05736)
- Lost in the Middle: How Language Models Use Long Contexts (arXiv:2307.03172)
- CoT-Influx (GitHub: HuangOwen/CoT-Influx)

Log in or sign up for Devpost to join the conversation.