-
-

Prototype Image
-

Gemini AI generated practical setup
-
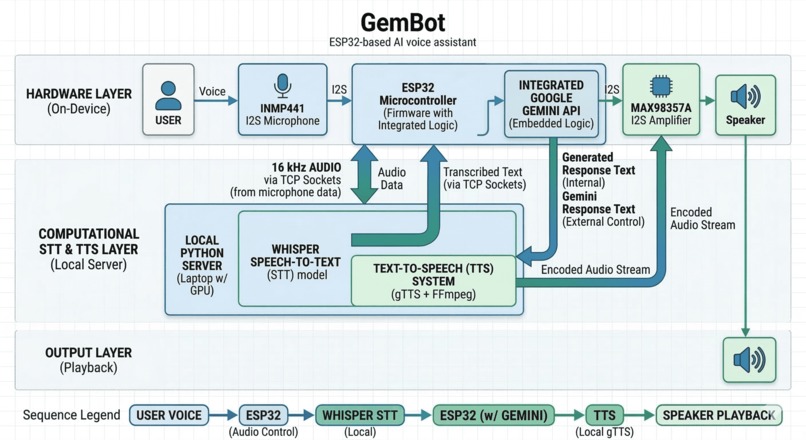
Gemini AI generated system architecture
-
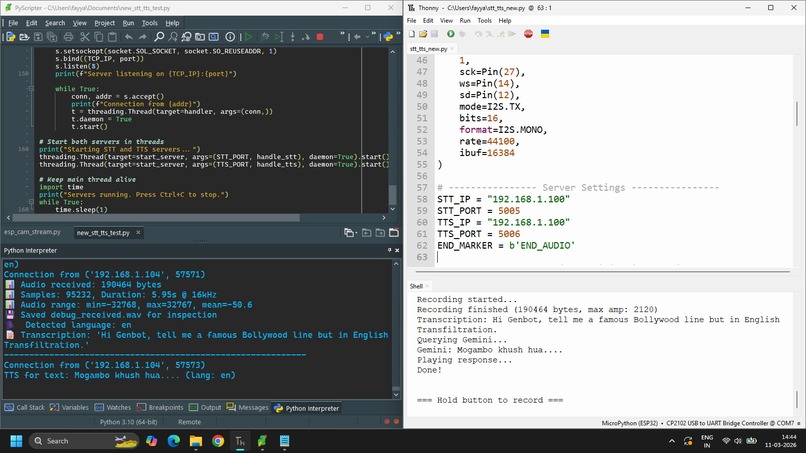
Python Local Server Running on Laptop and Micropython running on ESP32 with Gemini API
-
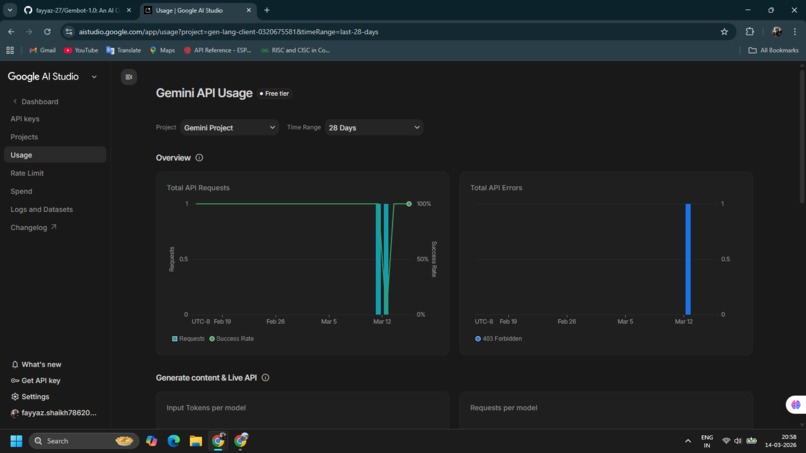
Gemini API usage proof
-
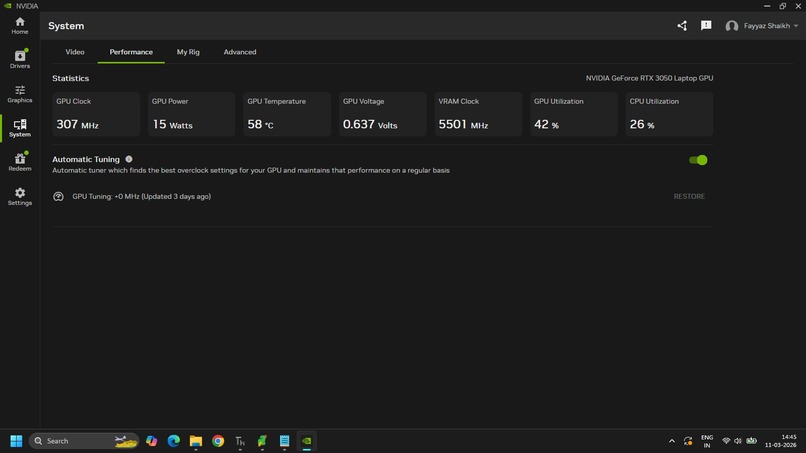
GPU Usage during Speech to Text and Google Text to Speech






Inspiration
Voice assistants like Alexa and Google Assistant feel almost magical, but they are closed systems. As an embedded systems developer, I wanted to understand how such systems actually work under the hood.
I wondered: What if I could build my own voice assistant from scratch using embedded hardware and modern AI models?
That curiosity led to GemBot — a project that connects an ESP32-based hardware device with Gemini AI to create a real-world voice agent that can listen, reason, and speak.
The idea was simple but exciting: take the intelligence of modern AI models and give them a physical interface in the real world.
What it does
GemBot is a voice-enabled AI assistant powered by Gemini.
It listens to a user's voice through an I2S microphone connected to an ESP32, converts the speech to text using a local Whisper server running on a GPU, sends the query to Gemini for reasoning, and then converts the response into speech that plays through a speaker.
In simple terms, the pipeline looks like this:
Voice → ESP32 → Whisper (STT) → Gemini → Text-to-Speech → Speaker
The result is a physical AI agent that can hold conversations using real hardware instead of just a web interface.
How I built it
The project combines embedded systems, networking, and AI models.
Hardware
- ESP32 Dev Module
- INMP441 I2S MEMS microphone
- MAX98357A I2S speaker amplifier
- Push button for recording
The ESP32 records audio from the microphone at 16 kHz, streams it to a local server over TCP, and plays audio responses through the speaker.
AI Processing
A Python server running on a laptop handles the heavy AI workloads:
- Whisper for speech-to-text transcription (running on GPU)
- Gemini for reasoning and response generation
- gTTS + FFmpeg for converting the response into audio
The ESP32 acts as the edge interface, while the GPU server provides the AI processing power.
Challenges I ran into
One of the biggest challenges was handling real-time audio streaming between embedded hardware and the AI server.
Some issues I encountered included:
- Low microphone signal levels from the INMP441
- Ensuring audio was captured at the correct 16 kHz format required by Whisper
- Managing TCP audio streaming between ESP32 and the Python server
- Handling audio buffering without introducing delays
Another challenge was designing the pipeline so that the system could move smoothly between speech recognition, AI reasoning, and speech generation.
Debugging the audio pipeline was especially tricky because even small format mismatches could cause Whisper to fail to recognize speech.
Accomplishments that I am proud of
The biggest achievement was successfully creating a working end-to-end AI voice assistant built from hardware.
GemBot demonstrates:
- Embedded systems interacting with modern AI models
- Real-time voice interaction using ESP32
- GPU-accelerated speech recognition
- A complete AI pipeline from microphone input to spoken response
Seeing a device I built listen to a question and respond with AI-generated speech was an incredibly rewarding moment.
What I learned
This project taught me a lot about the intersection of embedded systems and AI infrastructure.
Key lessons included:
- How real-time audio pipelines work
- Integrating embedded devices with cloud and GPU-based AI systems
- Managing network streaming between microcontrollers and servers
- Designing hardware that interacts with AI models in real time
It also reinforced the idea that AI becomes far more powerful when it can interact with the physical world.
What's next for GemBot
GemBot is still evolving.
Future improvements include:
- Wake word detection for hands-free activation
- Lower-latency streaming speech recognition
- Offline LLM support for edge deployments
- Better noise filtering and microphone processing
- Custom PCB hardware for a compact standalone device
The long-term goal is to turn GemBot into a fully standalone embedded AI assistant that runs locally and interacts naturally with users.


Log in or sign up for Devpost to join the conversation.