-
-
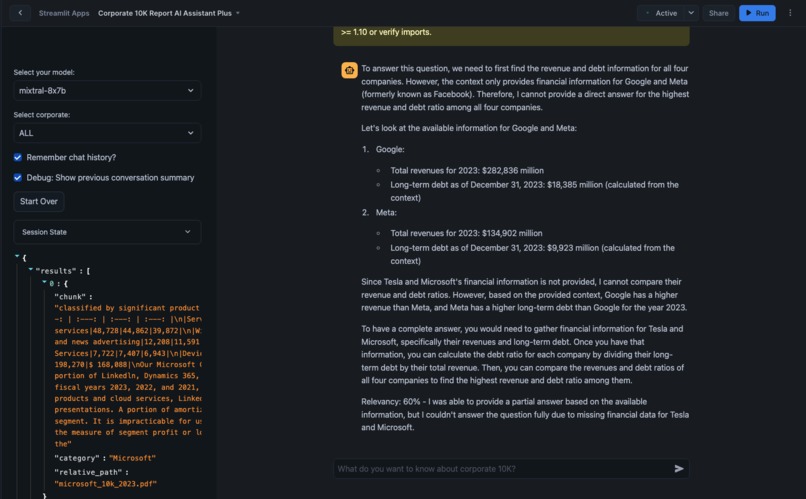
chatbot interface
-
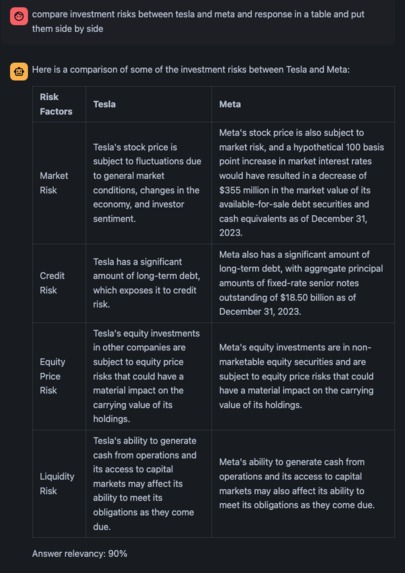
answer before enrichment 90% relevancy
-
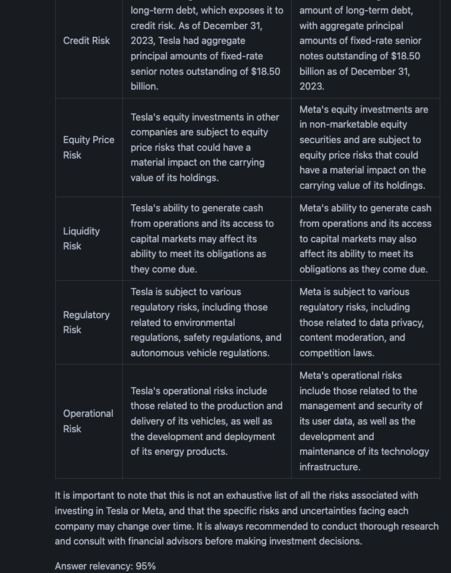
human feedback and answer after enrichment 95% relevancy
-
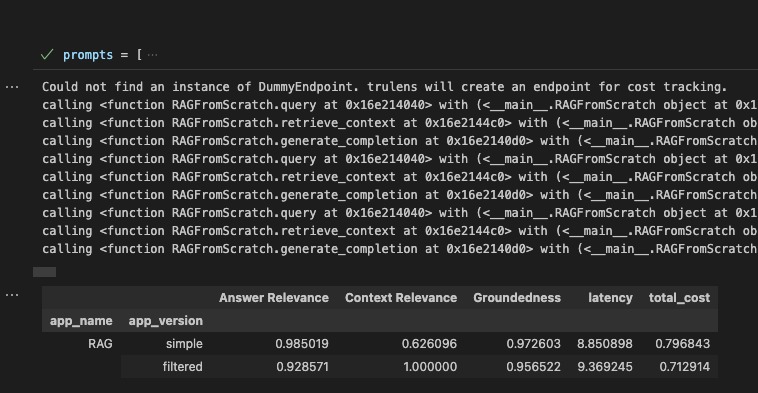
trulens to evaluate answer relevance and other metrics in vscode




Inspiration
Extensive research has been conducted to improve RAG’s performance, accuracy, and recall. However, two critical aspects of RAG that present challenges are the lack of evaluation metrics for answer relevancy; and the difficulty in implementing improvements based on the users feedback.
What it does
In summary, the key contributions include incorporating live metrics into RAG evaluation and leveraging user feedback to improve RAG performance in real-time. Users provide thumbs up or thumbs down can trigger chatbot to store good answer to database for future fine tuning or increase chunk sizes to improve the metric (answer relevancy)
How we built it
ETL and Cortex Search ETL is done within snowflake CLI or console using SQL Scripts. It transforms pdfs files into text chunks and embeddings and merged with other meta data as a data chunk table. then a cortex search service will be created for RAG. The SQL notebook can be found in github repo.
Query-Answer Relevancy Evaluation: was done by using large language model to evaluate question-retrieved text chunks-answer triplets. The answer is scored between 0-100%.
Streamlit Dynamic Integration of users feedback In Streamlit, every user interaction — such as clicking a button or submitting a form — triggers a complete rerun of the script from the beginning. This automatic rerun updates the application’s state, displays changes, and processes any logic conditional on the new state. This approach allows for dynamically updating web apps responsively without relying on traditional web development techniques like AJAX or WebSockets, making it ideal for developers with data science or analytics backgrounds.
Challenges we ran into
- snowflake learning curve
- Query-Answer Relevancy Evaluation: have consistent evaluation scores on each answer triplets
- **User's feedback integration: enhance user experience using thumbs up and down in streamlit frontend
- ** retrieval issues**: relevant text chunks were not retrieved from similarity search which resulting in hallucination and low answer relevancy scores
- streamlit app migrate from snowflake out to streamlit community cloud and migrate. c
Accomplishments that we're proud of
- Query-Answer Relevancy Evaluation: LLM Generated Answer Relevancy Scores for QA Evaluation
- Users feedback dynamic integration: RAG Improvement with Human Feedback, which can be quantified by answer relevancy scores
- User Empowerment: Enable non-technical users to interact with and understand complex financial documents with natural language queries
What we learned
- snowflake hands on experience
- Prompt Engineering: curated prompts are important to have consistent LLM outputs including evaluation scores
- Human in the Loop: find an efficient way to integrate customer feedback into RAG to refine search results
- Future Opportunities: It opens a door for use to integrate RL into RAG system
What's next for Interactive RAG Chatbot Built on Snowflake and Streamlit
- Streamlit cloud deployment: the snowflake based streamlit app into vscode and streamlit community cloud. there are certain limitations on the Snowflake platform that we could not address due to the short timeframe.
- ** RAG Optimization**: We like to implement other optimization tools to improve RAG using human feedback and reenforce learning. Several approaches could enhance RAG performance, such as reranker-based retrieval, DSPY-based few-shot prompt optimization, and others, as outlined in our previous blogs.
Built With
- cicd
- cortex
- mistral
- python
- snowflake
- streamlit
- trulens



Log in or sign up for Devpost to join the conversation.