-
-
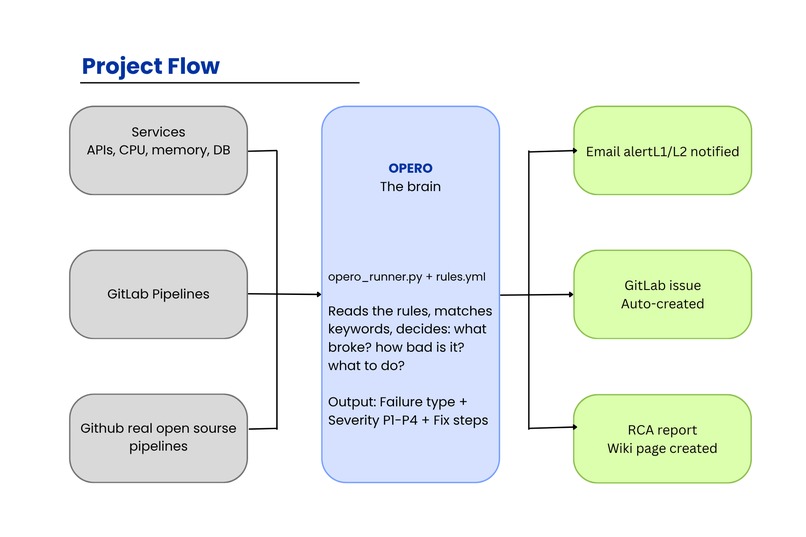
The Project Flow
-
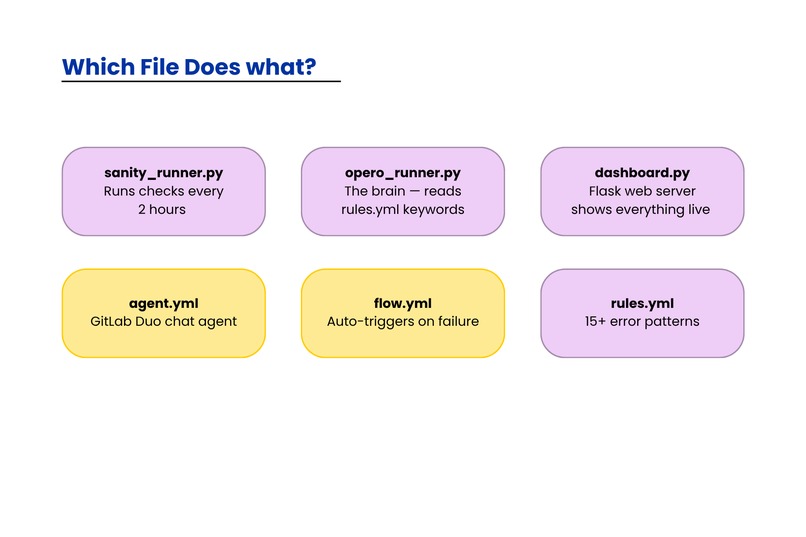
Description of Each FIle
-
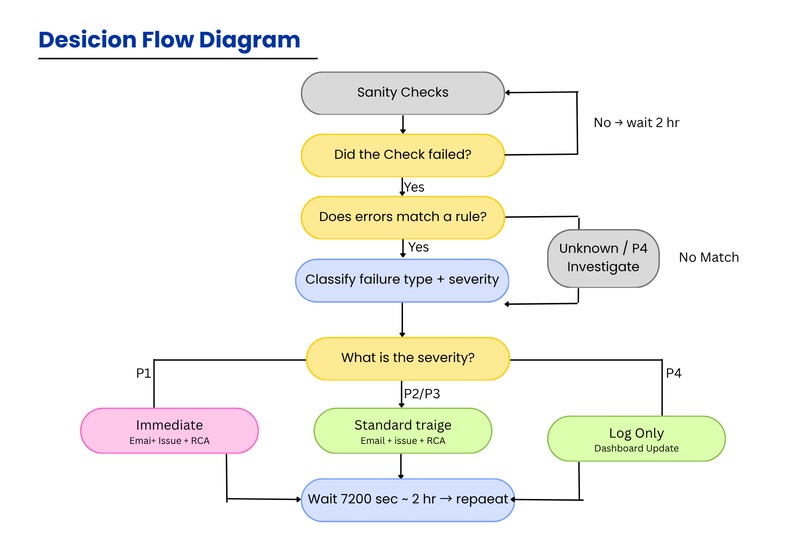
Decision Flow Diagram
-
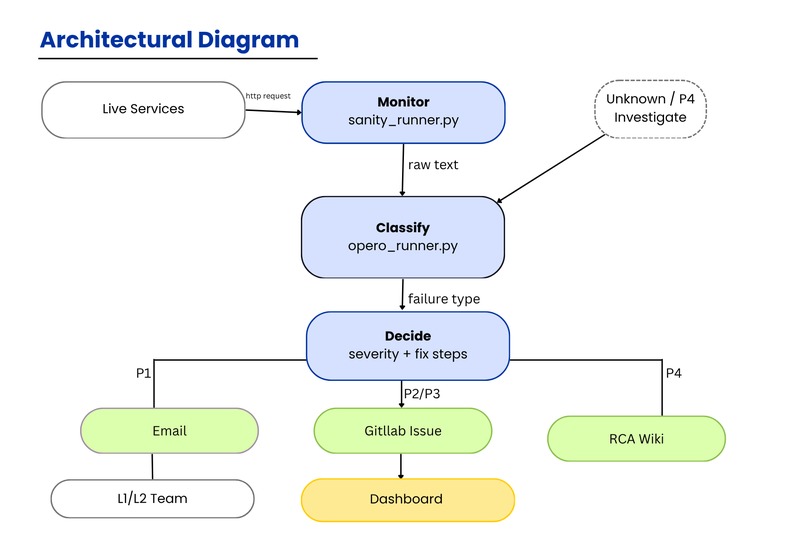
Architectural Diagram
-
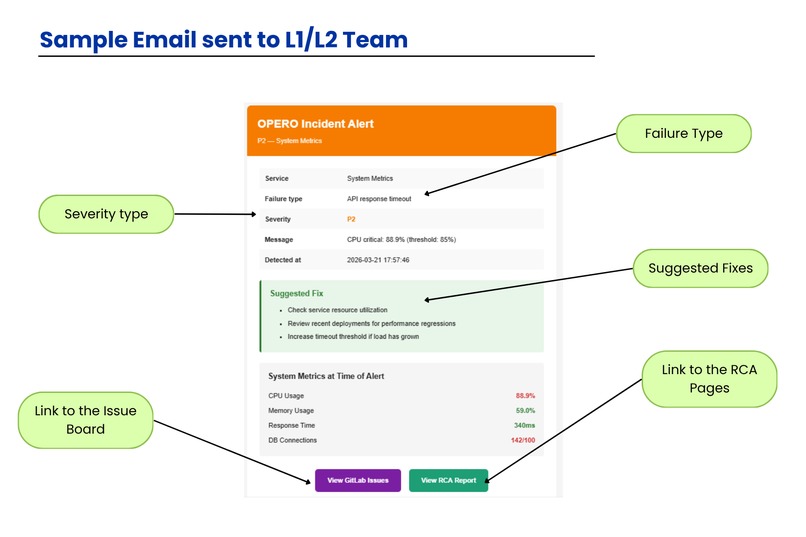
Sample Email





Inspiration
Every organization has an invisible bottleneck that nobody talks about — the L1/L2 support team.
These are the people who get paged at 2am when a service goes down. They manually check dashboards, scan hundreds of log lines, decide if something is a P1 or a P3, write up an incident report, create a GitLab issue, document a Root Cause Analysis, and notify the team — all before they can even start fixing the actual problem.
I've seen this pain firsthand. Support engineers spend 60-70% of their time on repetitive triage work that follows the same pattern every single time:
The pattern never changes. Only the specific error changes. And that's exactly the kind of repetitive, pattern-matching work that AI agents should handle.
That's what inspired OPERO — Operational Incident Response & Orchestration Agent.
Not a chatbot that answers questions. An agent that reacts, triages, and acts the moment something goes wrong
What it does
OPERO is an AI-powered incident monitoring and triage agent built on the GitLab Duo Agent Platform.
It watches your services 24/7 and the moment something fails:
- Detects — monitors API endpoints, CPU usage, memory, DB connections every 60 seconds
- Classifies — identifies the failure type from 15+ known patterns (service down, DB timeout, OOM, auth failure, etc.)
- Predicts severity — assigns P1 (Critical) to P4 (Low) with reasoning
- Emails the team — sends a beautiful HTML alert to L1/L2 engineers instantly
- Creates a GitLab issue — pre-triaged, labelled, and ready to assign
- Generates an RCA report — auto-publishes a Root Cause Analysis as a GitLab Wiki page, with a direct link in the email
- Shows everything live — real-time web dashboard at
localhost:5000
OPERO also lives inside GitLab Duo Chat as a public agent in the AI Catalog. Paste any log or error message and get an instant structured triage response powered by Anthropic Claude.
How I built it
OPERO is built in three layers that work together:
Layer 1 — GitLab Duo Agent (agent.yml)
A custom public agent published in the GitLab AI Catalog. Uses Anthropic Claude via GitLab Duo to analyze any log or error message and respond with a structured triage report — failure type, severity P1-P4, fix steps, triage summary, and whether the incident was preventable.
Layer 2 — Python automation engine
The core automation that runs locally and connects everything:
sanity_runner.py— runs API health checks, CPU/memory/DB monitoring every 60 secondsgithub_log_watcher.py— watchesfacebook/create-react-appGitHub Actions for real failed CI runsopero_runner.py— the rules engine that readsrules.ymland classifies failures by matching keywordsrules/rules.yml— 15+ YAML-defined patterns covering Java/Spring Boot, Python, PostgreSQL, MySQL, CI/CD errorsdashboard.py— Flask web server showing a live dashboard atlocalhost:5000
Layer 3 — GitLab Flow (flow.yml)
A GitLab Duo Flow that auto-triggers when a pipeline fails, runs the OPERO agent, and creates a triage issue — no human needed, no Python script required.
Challenges I ran into
GitLab flow schema kept changing — The flow.yml schema required multiple iterations.
The validator kept throwing errors about missing definition, flow, and required properties.
Eventually figured out that name, description, and public must be at the root level,
with everything else nested under definition.
GitHub API connection drops — The GitHub Actions API would sometimes drop connections mid-request.
Added timeout=30 and wrapped everything in try/except so the watcher never crashes.
rules.yml matching too broadly — Early versions of the rules engine matched "unknown" for too many errors because the keywords weren't specific enough. Refined the keyword lists and added context-enriched text to improve matching accuracy.
Accomplishments that I may be proud of
- OPERO is live in the GitLab AI Catalog as a public agent — anyone can use it right now
- End-to-end automation works — a service failure goes from detection to email + issue + RCA in under 5 seconds, with zero human action
- Monitors real CI/CD failures — pulling actual failed runs from
facebook/create-react-appon GitHub in production
What I learned
- How to build and publish custom agents on the GitLab Duo Agent Platform
- How to create GitLab Flows with the correct YAML schema —
definition, components, prompts, routers - How to use the GitLab REST API for automated issue creation, wiki management, and catalog integration
- How Anthropic Claude powers GitLab Duo agents under the hood
- How AI agents can genuinely remove friction from developer workflows, it's not just answer questions now, but take real action on behalf of the team
What's next for OPERO
- GitHub Actions CI/CD monitoring = I have already built a working prototype (
github_log_watcher.py) that watches real open source projects on GitHub for failed CI runs, pulls actual job logs via the GitHub Actions API, triages them with OPERO, and auto-creates GitLab issues with RCA reports. This currently monitorsfacebook/create-react-appin real time and is ready to be extended to any public or private GitHub repository. - Teams integration = alert engineers directly in their chat channels
- Auto-assignment = route issues to the right team/group DL based on failure type and service ownership
- Similar Issue Tracking = escalate incidents which have happened in past automatically
- Anomaly detection detect unusual patterns before they become incidents

Log in or sign up for Devpost to join the conversation.