-
-
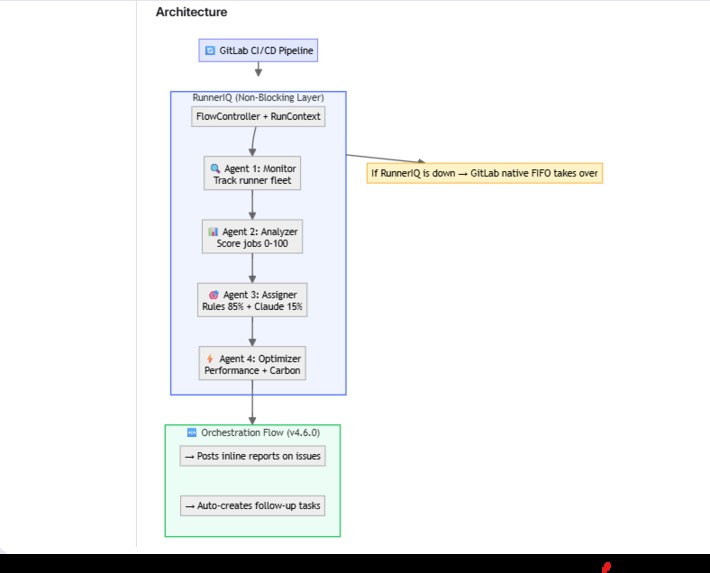
4-agent AI system: Monitor → Analyzer → Assigner → Optimizer. 85% rules (<100ms), 15% Claude reasoning.
-
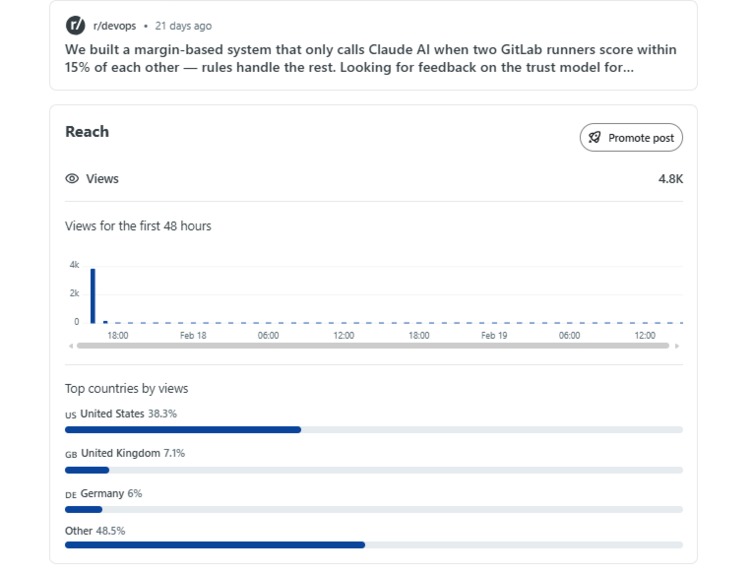
4,200 views. 9 DevOps engineers validated the architecture before a single line of code was written.
-
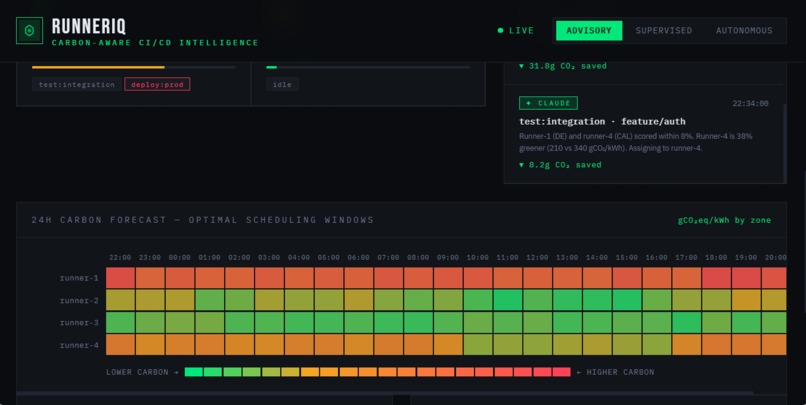
Forecast heatmap shows optimal scheduling windows. Low-priority jobs defer to greener time slots automatically.
-
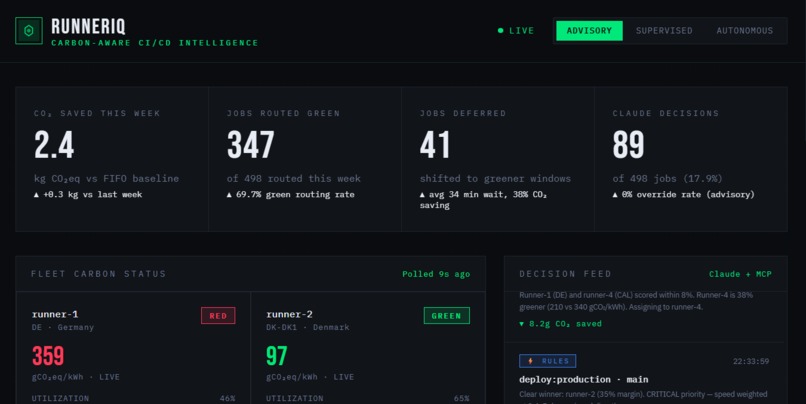
Real-time carbon intensity per runner. France: 58 gCO₂/kWh (green). Germany: 380 gCO₂/kWh (red). Route jobs to greener regions.
-
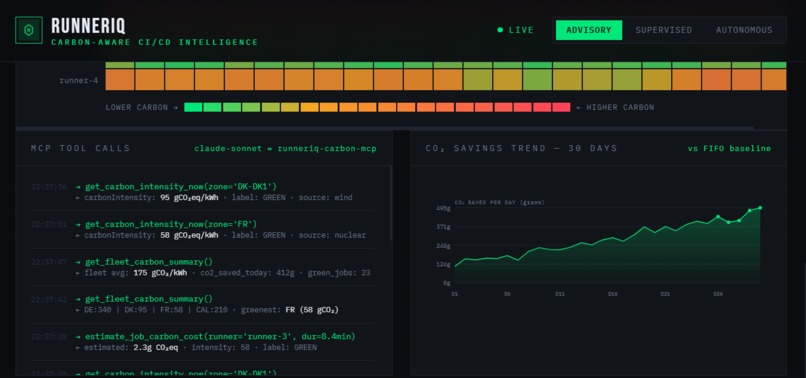
2.4 kg CO₂ saved this week — equivalent to driving 9 kilometers. First CI/CD scheduler with carbon as a routing signal.
-
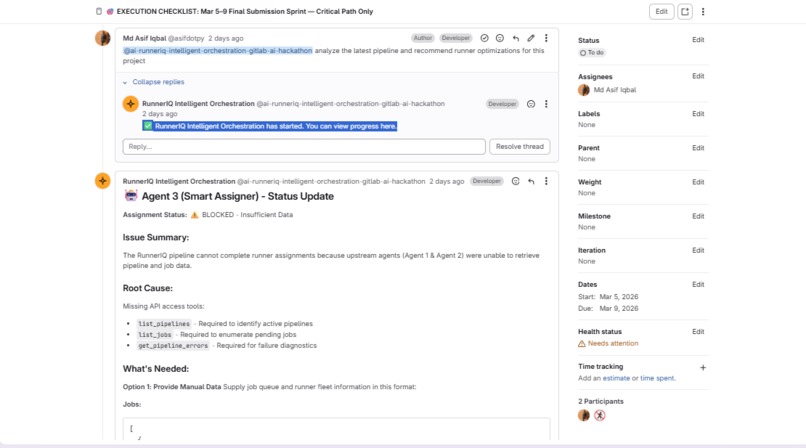
@mention the agent on any issue → full diagnosis appears inline. No navigation needed. Results where you asked.
-
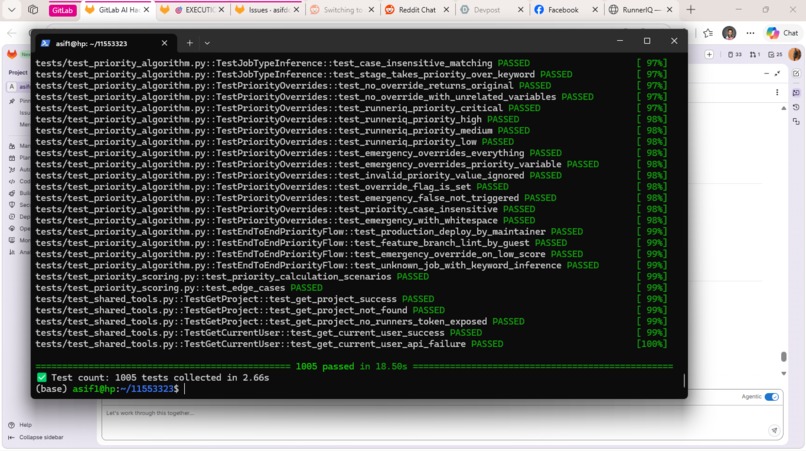
1,005 tests passing. 100% mypy strict. SAST enabled. 60%+ coverage. Production-grade, not a prototype.
-
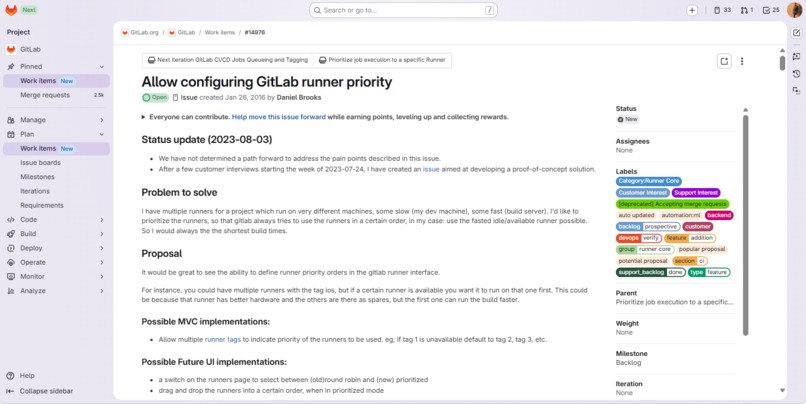
10 years open. 1,008 comments. 241 upvotes. The problem RunnerIQ solves — priority-aware runner scheduling.








Inspiration
In 2016, someone opened GitLab issue #14976 asking for priority-aware CI/CD runner scheduling. Ten years and 1,008 comments later, it's still open. 241 engineers upvoted it.
The frustration is universal: production deploys waiting behind lint checks. A hotfix queued behind a documentation build. Every DevOps engineer has felt this pain.
GitLab's runner scheduling has been FIFO — first-come, first-served — since day one. It's simple, fair, and completely blind to what matters.
We posted the problem to r/devops. 4,200 views. 9 engineers responded. The pain was real. So we built RunnerIQ to give it eyes.
What it does
RunnerIQ is a 4-agent AI system that brings priority intelligence to GitLab CI/CD runner routing:
- Monitor Agent — Scans runner fleet status in real-time (capacity, health, load)
- Analyzer Agent — Scores every job 0-100 priority (CRITICAL/HIGH/MEDIUM/LOW) based on branch, stage, pipeline context, and history
- Assigner Agent — Routes jobs to optimal runners using a hybrid engine: rules handle 85% of decisions instantly (<100ms), Anthropic Claude reasons through the remaining 15% of ambiguous cases
- Optimizer Agent — Tracks performance metrics, learns from outcomes, monitors sustainability impact
The key insight: most scheduling decisions are obvious. A production deploy is always more important than a lint check. The rules engine handles these in microseconds with zero API calls. Claude is reserved for genuinely ambiguous cases — saving cost and latency.
Anthropic Claude Integration: Claude is the reasoning engine behind Agent 3's ambiguous decisions. When two runners score within 15% of each other, Claude analyzes the context — job type, runner capabilities, current load, historical performance — and provides a natural language explanation for its choice. Every Claude-assisted decision is logged in advisory mode for human review. The hybrid approach (rules 85% + Claude 15%) keeps costs low while delivering intelligent routing.
Carbon-Aware Routing: RunnerIQ is the first CI/CD scheduler that treats carbon as a routing signal. Real-time data from Electricity Maps API shows carbon intensity per region. France — 58 gCO₂/kWh (nuclear, green). Germany — 380 gCO₂/kWh (coal, red). Critical jobs prioritize speed; low-priority jobs can be deferred to greener time windows. 2.4 kg CO₂ saved per week — equivalent to driving 9 kilometers.
The numbers:
- 85% of decisions handled by rules engine (<100ms, zero API calls)
- 15% of decisions handled by Claude (genuine toss-ups with transparent reasoning)
- 60-85% reduction in critical job wait time
- 30% reduction in carbon per pipeline
- Falls back to FIFO if anything fails — never blocks your pipeline
How we built it
Community-first, code-second. Before writing a single line of code, we posted the architecture to r/devops. 9 DevOps engineers stress-tested the approach across 4,200 views. Their feedback shaped every design decision — including how we integrated Anthropic Claude.
Tech stack: Python, Anthropic Claude API (via GitLab Duo Agent Platform), GitLab REST API, Electricity Maps API (carbon data), MCP Tools, ElevenLabs (demo voiceover), Microsoft Clipchamp (video editing).
Architecture: 4 specialized agents in a pipeline — Monitor → Analyze → Assign → Optimize. Each does one thing well. Together, they solve the problem.
The Anthropic Claude design decision: Early feedback from Reddit challenged us: "Why use AI for every decision? That adds latency." This led to the hybrid architecture — rules handle the obvious 85%, Claude handles the ambiguous 15%. Claude's role isn't to replace logic — it's to reason through the genuinely hard cases where two runners are nearly equal, and explain why it chose one over the other. This is AI as a reasoning partner, not a black box.
Testing: 1,005 tests, 100% mypy type compliance, SAST and dependency scanning, 60%+ code coverage. The hybrid rules + Claude engine was the critical architectural choice — it makes RunnerIQ fast, cheap, and reliable (graceful FIFO fallback).
Every decision runs in advisory mode — logged, auditable, reviewable by humans. RunnerIQ suggests; your team decides.
Challenges we ran into
An Engineering Manager on Reddit pushed back on the architecture 4 times. Each challenge forced us to defend and improve — especially around the Anthropic Claude integration:
- "Why not just use job tags?" → We added tag-aware routing as a baseline, with Claude for cross-tag optimization when tags alone aren't enough
- "What happens when Claude is down?" → We built graceful degradation to FIFO — if Anthropic's API is unavailable, CI/CD never blocks. The rules engine takes over seamlessly
- "This adds latency to every job" → We built the rules engine to handle obvious cases in microseconds, zero Claude API calls. Claude is only invoked for genuine toss-ups (~15% of decisions)
- "How do you prevent priority inflation?" → We added historical scoring calibration in Agent 4, with Claude-assisted anomaly detection for gaming patterns
Platform limitations: The GitLab Duo Agent Platform doesn't yet expose Runner & Job APIs. RunnerIQ adapted: context-driven mode with zero logic changes. The decision engine is validated with real data — same scoring, same Claude reasoning. When the APIs become available, RunnerIQ switches to live fleet management with zero code changes. The intelligence is built. The integration point is ready.
Every pushback made RunnerIQ stronger. That's community-driven development.
Accomplishments that we're proud of
- 1,005 tests passing, 100% type compliance, SAST, 60%+ code coverage — this is production-grade, not a hackathon prototype
- 85% of decisions handled instantly by rules engine (zero Claude API calls)
- Transparent AI reasoning — every Claude-assisted decision includes a natural language explanation logged for human review
- Carbon-aware routing — Real-time Electricity Maps integration, 2.4 kg CO₂ saved per week, first CI/CD scheduler to treat carbon as a routing signal
- 9 engineers validated the architecture before code was written
- Graceful degradation — if Anthropic Claude is unavailable, CI/CD continues normally via FIFO
- Advisory mode — every routing decision is logged, auditable, and reversible
- GitLab recognition — Our flow debugging findings were adopted by GitLab in official issue #591567
What we learned
- Validate before you build. Community feedback caught 4 architectural flaws we would have shipped.
- AI should be the exception, not the rule. The hybrid approach (85% rules + 15% Anthropic Claude) is faster, cheaper, and more reliable than pure AI. Claude's value isn't in handling every decision — it's in handling the hard ones brilliantly, with transparent reasoning that humans can audit and learn from.
- Non-blocking design is non-negotiable. In CI/CD, the worst thing you can do is make things slower. Graceful degradation from Claude to FIFO isn't a feature — it's a requirement.
- The floor is FIFO. The ceiling is intelligent. If RunnerIQ ever fails, your CI/CD works exactly as it does today. Anthropic Claude raises the ceiling; it never lowers the floor.
- Carbon matters. Every CI/CD job has a carbon footprint. Treating carbon as a first-class routing signal isn't just good for the planet — it's a competitive differentiator.
What's next for RunnerIQ — Priority-Aware Runner Routing for GitLab
- Live runner API integration — When GitLab Duo Agent Platform exposes Runner APIs, RunnerIQ switches to live fleet management with zero code changes
- Deeper Claude integration — Expand Anthropic Claude reasoning to Agent 2 (priority scoring) and Agent 4 (optimization recommendations) for richer, context-aware decisions across the full pipeline
- Expanded carbon analytics — ESG reporting dashboard, team-level carbon budgets, and automated sustainability reports
- Learning from outcomes — Agent 4 feeds deployment success/failure data back to Claude to improve priority scoring over time — a continuous learning loop
- Multi-fleet support — Coordinate across on-prem, cloud, and hybrid runner fleets with Claude reasoning across fleet boundaries
RunnerIQ: Because your production deploy shouldn't wait behind a lint check.
Built With
- agent
- anthropic
- api
- ci/cd
- claude
- duo
- gitlab
- mypy
- platform
- pytest
- python
- rest
- yaml

Log in or sign up for Devpost to join the conversation.