-
Light Theme
-
Chat UI
-
Council Breakdown
-
External News
-
Dark Theme





Inspiration
M&A due diligence is one of the most document-heavy, time-sensitive processes in finance. A typical deal generates hundreds of pages across financial statements, NDAs, employment agreements, and IP assignments. Analysts spend days manually reading through these, writing memos, and summarizing findings for deal committees. The bottleneck is not intelligence, it is throughput.
I wanted to build something that could sit in that workflow and compress days of reading into under 30 seconds. Not a chatbot that answers questions about documents, but an opinionated system that replicates the actual structure of a deal council: multiple specialists looking at the same deal from different angles, then a senior partner synthesizing their findings into a verdict.
What it does
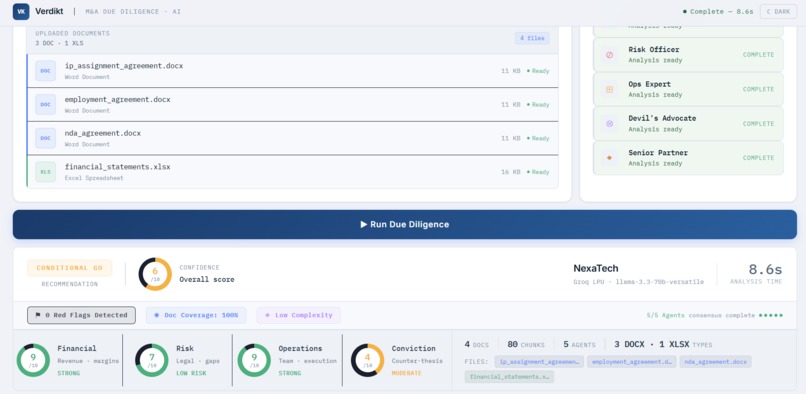
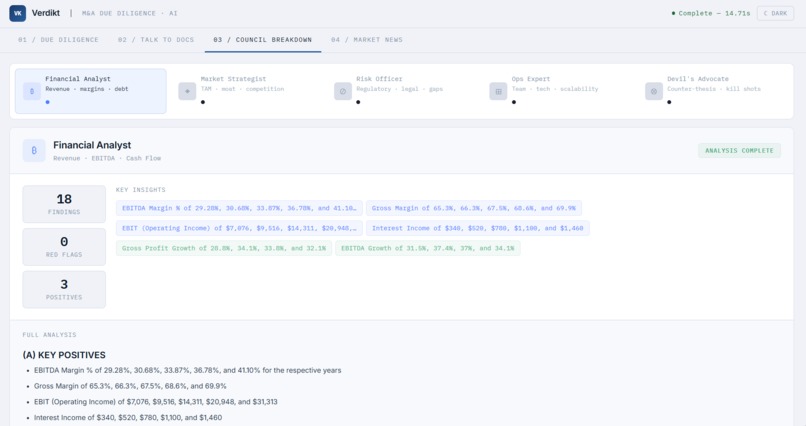
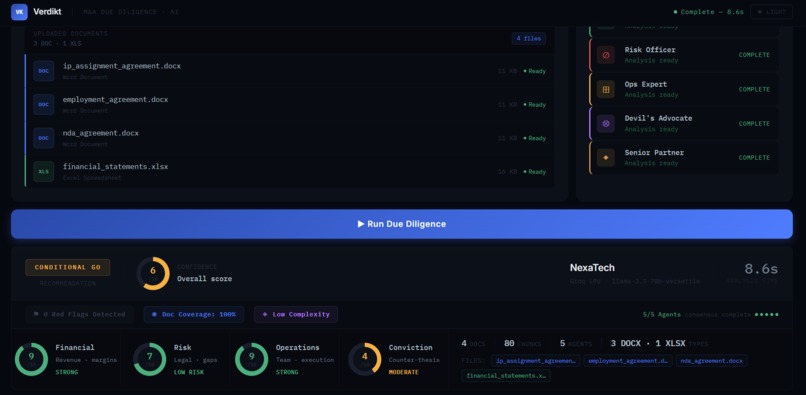
Verdikt runs a council of 5 specialist AI agents in parallel against uploaded deal documents. Each agent owns a specific dimension of the deal: the Financial Analyst covers revenue, EBITDA, margins, and cash flow; the Market Strategist looks at TAM, competitive moat, and growth trajectory; the Risk Officer flags legal, regulatory, and documentation gaps; the Ops Expert evaluates team, technology, and scalability; and the Devil's Advocate builds the counter-thesis and looks for deal-killers.
A Senior Partner agent then synthesizes all five findings into a final investment report with a scored GO / CONDITIONAL GO / NO-GO verdict and a 1-10 confidence score. The report follows the same section structure used by real deal committees: Executive Summary, Financial Analysis, Market Position, Risk Assessment, Operational Evaluation, and Deal Verdict.
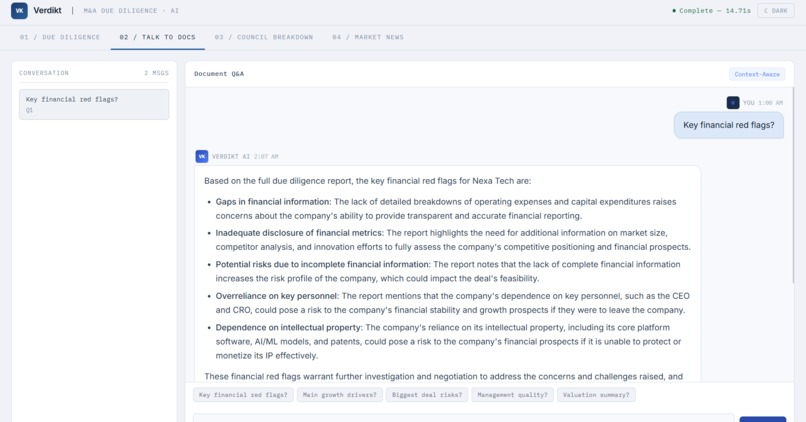
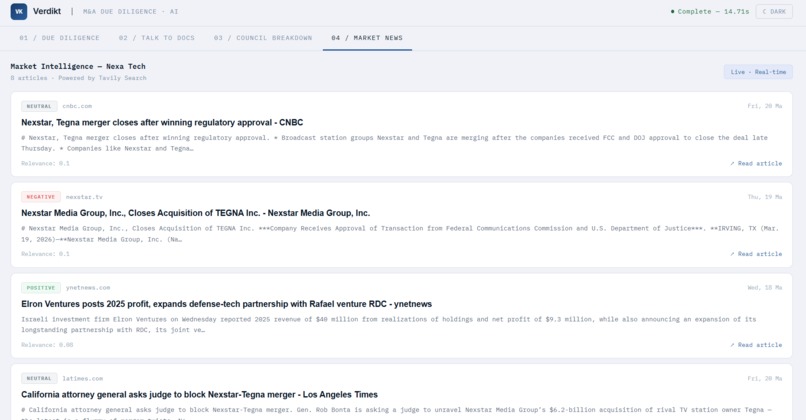
Documents are chunked and embedded into a local ChromaDB vector store. Each agent runs multi-query RAG with targeted queries for its domain, deduplicates retrieved chunks, and grounds its analysis strictly in the uploaded documents. A Tavily news fetch runs in parallel to inject live market intelligence into the Market Strategist and Risk Officer context. After the report is generated, users can switch to the Talk to Docs tab and ask follow-up questions grounded in both the vector store and the full report.
How I built it
The architecture is a single-process Python application split across a clean module hierarchy: config.py initializes shared clients, rag.py handles document ingestion and vector store management, agents.py defines the 5 system prompts and the ThreadPoolExecutor pipeline, and callbacks.py wires the Dash UI to the pipeline.
The non-blocking pipeline was the most deliberate design choice. Dash runs on Flask, which is single-threaded by default. Running a 30-second LLM pipeline inside a callback freezes the server thread and kills the loader animation. The fix was a two-phase pattern: the Run button spawns a daemon thread and writes a job ID to a Dash store, while a dcc.Interval fires every second to poll a module-level job registry until the result is ready.
The scoring agent runs in parallel with the senior synthesis agent since both only depend on the five agent findings, not on each other. Results are cached in-memory by a SHA-256 fingerprint of the uploaded files, so re-running the same analysis is instant.
Challenges I ran into
The biggest challenge was the Dash server thread freezing during the pipeline run. The loader animation is pure clientside JS, but any Python callback that fires during a blocking run gets queued and never executes. Solving this required rethinking the entire callback architecture around background threads and polling.
Getting agents to report what IS in the documents rather than defaulting to listing what is missing was harder than expected. Early prompts produced responses full of invented gaps. The fix was explicit rules in each system prompt: cite specific figures if present, only flag something as missing if it is genuinely absent after reading all context carefully.
Other challenges included ChromaDB collection naming constraints breaking on company names with special characters, hardcoded dark hex values in active UI states persisting in light mode, and the scoring LLM call adding sequential latency until I identified it could run in parallel with the senior synthesis.
Accomplishments that I'm proud of
The full pipeline runs in under 30 seconds including document embedding, 5 parallel LLM calls, a live news fetch, senior synthesis, and scoring. The modular package structure has a strict linear import chain with zero circular dependencies. The agent system prompts produce genuinely balanced analysis rather than reflexively risk-heavy output, which required significant iteration on the Devil's Advocate prompt in particular. The verdict strip UI packs the recommendation, confidence score, four dimension dials, document coverage, red flag count, and file list into a single dense panel.
What I learned
Dash is Flask. Any slow synchronous operation in a callback blocks every other callback for every connected client. The dcc.Interval polling pattern is the right solution for long-running tasks in Dash without pulling in Celery or Redis.
Multi-query RAG with domain-specific queries per agent produces dramatically better retrieval than a single query. Parallelizing LLM calls with ThreadPoolExecutor is trivially easy in Python and has a significant impact on latency since 5 agents running in parallel takes roughly the same wall-clock time as 1 running sequentially.
What's next for Verdikt
Persistent analysis cache across restarts so document re-embedding only happens once per file. Per-agent streaming output so users can watch findings appear in real time. A deal comparison mode to run the same analysis across multiple companies and render a side-by-side scorecard. Export to PDF and DOCX so the report can drop directly into a deal memo.

Log in or sign up for Devpost to join the conversation.