-

Our Logo
-
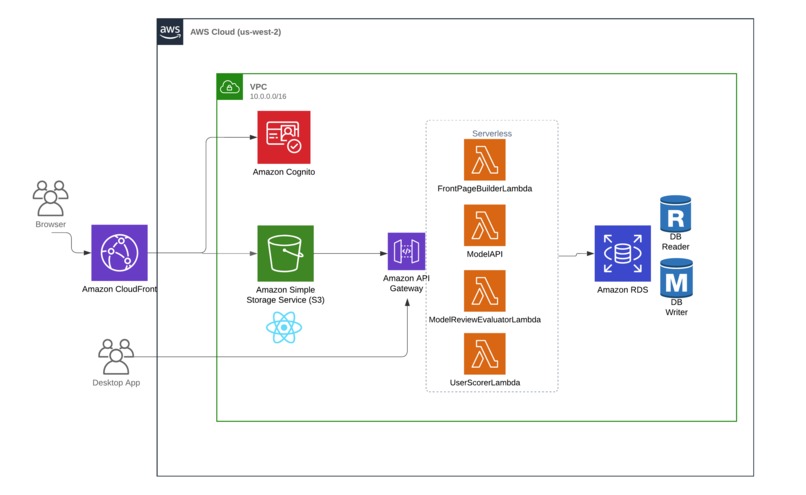
Our AWS solution architecture
-
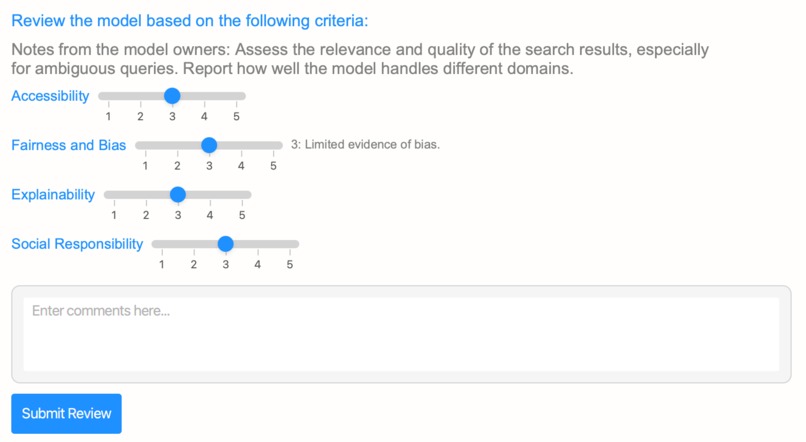
The page for reviewing a model
-

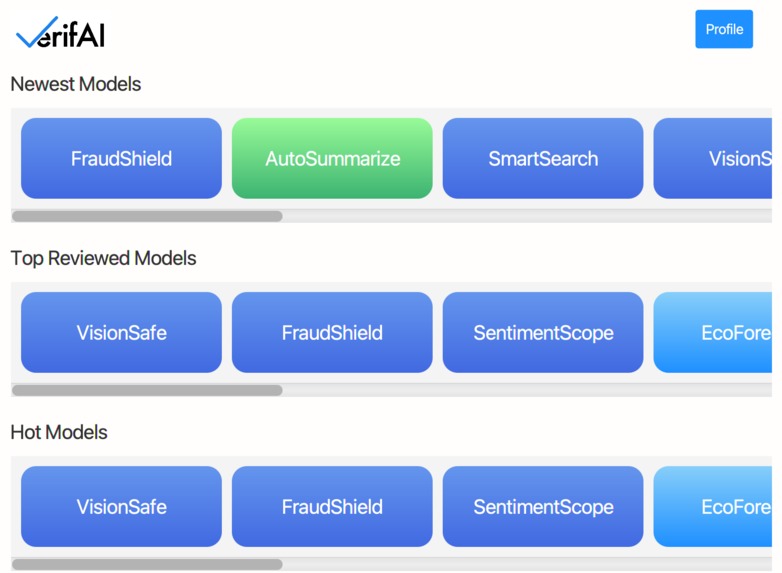
The page for one of the models on our platform
-
Our desktop app
-
Our web app
-
The page to publish a model on our web app







Inspiration
Many of the members of our team have researched ML and AI, and we've become increasingly aware of how much research is going into AI fairness and responsibility. We've experienced firsthand the bias and stereotypes that models can exhibit--even LLMs that can't even speak our language. We realized that there's a missing link in MLOps tools: platforms for developing and sharing models are there, but what about evaluating them? We wanted to build a tool to connect diverse stakeholders to ML projects from day 1.
We were particularly inspired by the concept of creating a platform where the community itself plays a central role in evaluating and certifying AI models. By leveraging the collective expertise of diverse expert stakeholders, we believed we could create a more robust and nuanced system for assessing AI fairness than any single organization could achieve alone.
What it does
Developing this project has been an incredible learning experience for our team. We delved deep into the complexities of AI ethics, bias detection, and the challenges of creating fair and inclusive AI systems. We learned about the importance of diverse perspectives in AI evaluation and the need for transparent, explainable AI.
On the technical side, we gained valuable experience in architecting complex systems using AWS services. We learned how to leverage serverless technologies like AWS Lambda and API Gateway to create scalable, cost-effective solutions. The project also deepened our understanding of machine learning operations (MLOps) and the challenges of managing AI models in production environments.
How we built it
The AI Model Certification Platform was built as a comprehensive web application leveraging various AWS services:
Frontend: We used React for the user interface, hosted on Amazon S3 and distributed via CloudFront for low-latency global access. We also build a JavaFX Desktop app.
Authentication: Amazon Cognito handles user authentication to ensure enterprise-grade security.
Backend: AWS Lambda functions, orchestrated by API Gateway, handle the core business logic. These include:
UserScorerLambdafor calculating reviewer authority scoresFrontPageBuilderLambdafor curating featured modelsModelReviewEvaluatorLambdafor assessing review quality
Data Storage: We used a combination of Amazon RDS for fast, scalable storage of user data, models, and reviews.
AI Services: We have the machine learning components, including the LLM review-reviewer system for baseline review quality assessment and the bias detection pipeline.
Challenges we ran into
Developing this platform came with its share of challenges:
Ensuring Fairness in Reviewer Scoring: Creating an unbiased system for scoring reviewer authority was a significant challenge. We had to carefully balance various factors like academic credentials, citation counts, and review quality to create a fair and transparent scoring system.
Preventing Gaming of the System: We want our platform to be a transparent, trustworthy certifier, above all. Implementing measures to prevent "horse trading" of positive reviews was crucial. We developed a report-based system instead of simple star ratings to encourage more nuanced and honest feedback. In addition, reviewers rated to be more reliable and trustworthy have greater weight in determining feedback.
Scalability: Even though our project is small right now, we built in scalability from the beginning. Leveraging AWS's serverless architecture and implementing efficient database design helped address this.
Bias in Bias Detection: Ironically, ensuring that our own bias detection systems were free from bias was a complex task. We had to thoroughly evaluate our own review-evaluation systems by red-teaming adversarial attacks
User Experience: Balancing the need for comprehensive reviews with a user-friendly interface was challenging. We worked to create an intuitive flow that guides reviewers through the process without overwhelming them.
Despite these challenges, the project has been immensely rewarding for our team. It's exciting to see how technology can be leveraged to promote fairness and inclusion in AI development. As we continue to refine and expand the platform, we're optimistic about its potential to make a real difference in the AI community and beyond.
Accomplishments that we're proud of
We are proud of the following accomplishments broadly:
- Fair Scoring System: Creating an sophisticated reviewer scoring system, which is explainable and accountable, while also being difficult to manipulate.
- Scalable Architecture: Implementing a scalable, serverless platform using AWS, using tech that many of our teammates hadn't used before.
- User-Friendly Interface: Designing an intuitive interface for easy model evaluation. Positive Impact: Promoting accountability, transparency, and inclusivity in AI development. We also ensured that our project is screen-reader friendly for accessibility.
What we learned
Technical Skills: We enhanced our skills in architecting complex systems using AWS services, including serverless technologies like AWS Lambda and API Gateway, and also React and JavaScript. AI Ethics: We gained a deep understanding of AI ethics, bias detection, and the importance of creating fair and inclusive AI systems.
What's next for VerifAI
- Increase the number of AI and ML models available on the platform, covering a wider range of use cases and industries.
- Continuously refine and expand the evaluation criteria to include more aspects of AI ethics and performance.
- Establish partnerships with academic institutions, industry leaders, and AI ethics organizations to enhance the credibility and reach of the platform.
- Develop new features such as real-time bias detection, automated model recommendations, and enhanced user analytics.
- Incentivize reviewing models using some gamifying features, keeping track of reviewers' reputation scores.
Built With
- amazon-web-services
- cloudfront
- cognito
- css
- java
- javascript
- lambda
- rds
- react
- s3



Log in or sign up for Devpost to join the conversation.