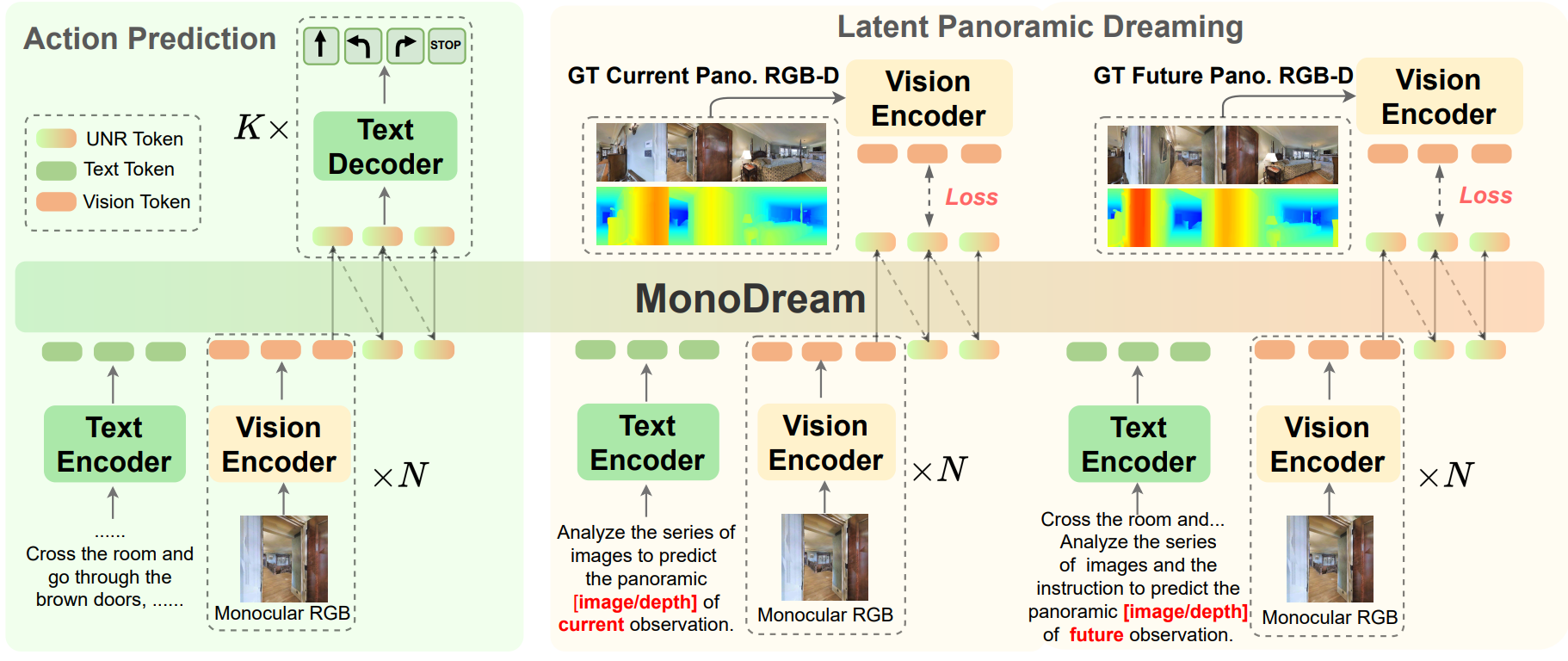
MonoDream learns to "dream" the latent features of the full panoramic image and depth from monocular images, enabling effective and efficient Vision-Language Navigation.
conda create -n monodream python=3.10
conda activate monodream
pip install ".[monodream]"
cd projects/monodream
pip install -r requirements.txt
# Install FlashAttention2
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.0.post2/flash_attn-2.8.0.post2+cu12torch2.7cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
MonoDream relies on Habitat-Sim 0.1.7 for simulation and dataset generation.
Please follow the official build-from-source guide:
https://github.com/facebookresearch/habitat-sim/blob/v0.1.7/BUILD_FROM_SOURCE.md
Then install the habitat-lab 0.1.7 dependency.
# Install habitat-lab
cd projects/monodream
git clone --branch v0.1.7 https://github.com/facebookresearch/habitat-lab.git
cd habitat-lab
pip install -r requirements.txt
python setup.py develop --all
cd projects/monodream
git clone https://github.com/markinruc/VLN_CE.git
Please download the Matterport3D scene data and R2R-CE/RxR-CE datasets following VLN-CE. You can refer to the following file structure or modify the config in ./VLN-CE
data/datasets
├─ RxR_VLNCE_v0
| ├─ train
| | ├─ train_guide.json.gz
| | ├─ train_guide_gt.json.gz
| ├─ val_unseen
| | ├─ val_unseen_guide.json.gz
| | ├─ val_unseen_guide_gt.json.gz
| ├─ ...
├─ R2R_VLNCE_v1-3_preprocessed
| ├─ train
| | ├─ train.json.gz
| | ├─ train_gt.json.gz
| ├─ val_unseen
| | ├─ val_unseen.json.gz
| | ├─ val_unseen_gt.json.gz
data/scene_dataset
├─ mp3d
| ├─ ...
| | ├─ ....glb
| | ├─ ...
| ├─ ...Please modify the model-path and result-path in run_infer.sh.
cd projects/monodream
./run_infer.sh
Results will be saved in the specified result-path. Run the following command to obtain the final metrics:
python analyze_results.py --path result-path
@inproceedings{wang2025monodream,
title={MonoDream: Monocular Vision-Language Navigation with Panoramic Dreaming},
author={Wang, Shuo and Wang, Yongcai and Fan, Zhaoxin and Li, Wanting and Wang, Yucheng and Chen, Maiyue and Wang, Kaihui and Su, Zhizhong and Cai, Xudong and Jin, Yeying and Li, Deying},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2026}
}Our code is based in part on VILA, NaVid, and VLN-CE. Thanks for their great works.