Wide&Deep is an industrial application model for CTR recommendation that combines Deep Neural Network and Linear model. Its model structure is as follows. Based on this structure, this project uses OneFlow distributed deep learning framework to realize training the modle in graph mode and eager mode respectively on Crioteo data set.
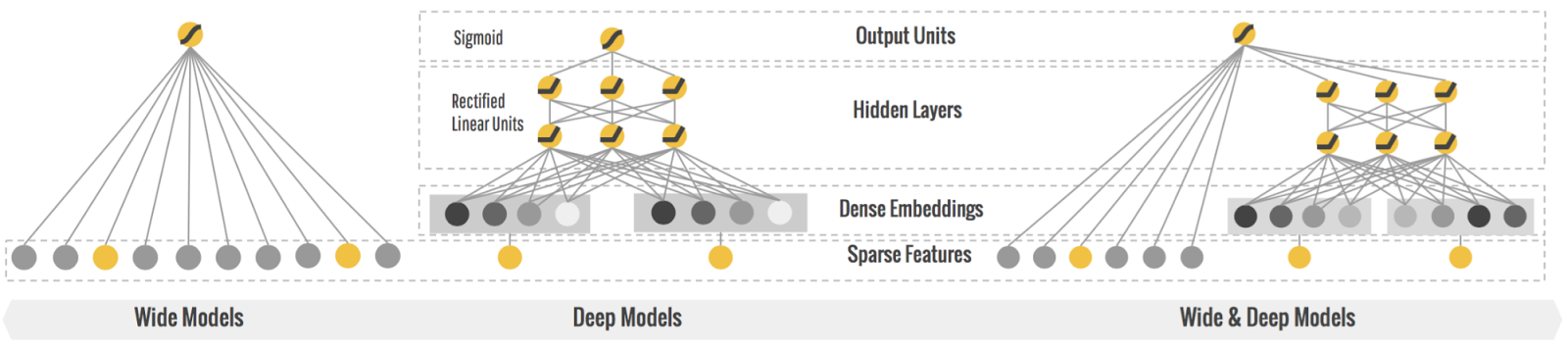
.
|-- models
|-- wide_and_deep.py #Wide&Deep model structure
|-- data.py #Read data
|-- utils
|-- logger.py #Loger info
|-- config.py #Argument configuration
|-- train.py #Python script for train mode
|-- train_global_eager.sh #Shell script for starting training in eager mode
|-- train_global_graph.sh #Shell script for starting training in graph mode
|-- train_ddp.sh #Shell script for starting training in ddp mode
|-- __init__.py
└── README.md #Documentation
| Argument Name | Argument Explanation | Default Value |
|---|---|---|
| batch_size | the data batch size in one step training | 16384 |
| data_dir | the data file directory | /dataset/wdl_ofrecord/ofrecord |
| dataset_format | ofrecord format data or onerec format data | ofrecord |
| deep_dropout_rate | the argument dropout in the deep part | 0.5 |
| deep_embedding_vec_size | the embedding dim in deep part | 16 |
| deep_vocab_size | the embedding size in deep part | 1603616 |
| wide_vocab_size | the embedding size in wide part | 1603616 |
| hidden_size | number of neurons in every nn layer in the deep part | 1024 |
| hidden_units_num | number of nn layers in deep part | 7 |
| learning_rate | argument learning rate | 0.001 |
| max_iter | maximum number of training batch times | 30000 |
| model_load_dir | model loading directory | |
| model_save_dir | model saving directory | |
| num_deep_sparse_fields | number of sparse id features | 26 |
| num_dense_fields | number of dense features | 13 |
| loss_print_every_n_iter | print train loss and validate the model after training every number of batche times | 1000 |
| save_initial_model | save the initial arguments of the modelor not | False |
Running Wide&Deep model requires downloading OneFlow, scikit-learn for caculating mertics, and tool package numpy。
Criteo dataset is the online advertising dataset published by criteo labs. It contains the function value and click feedback of millions of display advertisements, which can be used as the benchmark for CTR prediction. Each advertisement has the function of describing data. The dataset has 40 attributes. The first attribute is the label, where a value of 1 indicates that the advertisement has been clicked and a value of 0 indicates that the advertisement has not been clicked. This attribute contains 13 integer columns and 26 category columns.
Please view how_to_make_ofrecord_for_wdl
bash train_ddp.sh
bash train_global_graph.sh
bash train_global_eager.sh
Currently OneFlow-WDL supports two types of dataset format: ofrecord and onerec, both can be tranformed from HugeCTR parquet format dataset. Following two steps to process dataset:
Step 1: Preprocess the Dataset Through NVTabular
Run NVTabular docker and execute the following preprocessing command to parquet format dataset
$ bash preprocess.sh 1 criteo_data nvt 1 0 1 # parquet outputStep 2: Convert parquet format dataset to ofrecord or(and) onerec format dataset
This step needs to be executed in the spark 2.4.x environment. Please download the dependent jar package from here first, then launch spark shell environment with this jar support.
In spark shell environment, execute following scripts. You may modify db_path(parquet dataset path as input), output_path(ofrecord or onerec dataset path for output).
import org.oneflow.spark.functions._
import org.apache.spark.sql.types.{IntegerType}
def convert_parquet(input_path: String, output_path: String, db_type: String) = {
val NUM_CATEGORICAL_COLUMNS = 26
val categorical_cols = (1 to NUM_CATEGORICAL_COLUMNS).map{id=>s"C$id"}
val sparse_cols = Seq("C1_C2", "C3_C4") ++ categorical_cols
val slot_size_array = Array(225945, 354813, 202260, 18767, 14108, 6886, 18578, 4, 6348, 1247, 51, 186454, 71251, 66813, 11, 2155, 7419, 60, 4, 922, 15, 202365, 143093, 198446, 61069, 9069, 74, 34)
var df = spark.read.parquet(input_path)
df = df.withColumn("label", col("label").cast(IntegerType)).withColumnRenamed("label", "labels")
var offset: Long = 0
var i = 0
for(col_name <- sparse_cols) {
println(col_name)
df = df.withColumn(col_name, df(col_name) + lit(offset))
.withColumn(col_name, col(col_name).cast(IntegerType))
offset += slot_size_array(i)
i += 1
}
val NUM_INTEGER_COLUMNS = 13
val integer_cols = (1 to NUM_INTEGER_COLUMNS).map{id=>s"I$id"}
df = df.select($"labels", array(integer_cols map col: _*).as("dense_fields"), array(categorical_cols map col: _*).as("deep_sparse_fields"), array("C1_C2", "C3_C4").as("wide_sparse_fields"))
df = df.repartition(256)
var path = output_path + "wdl_ofrecord/" + db_type
println(path)
df.write.mode("overwrite").ofrecord(path)
sc.formatFilenameAsOneflowStyle(path)
path = output_path + "wdl_onerec/" + db_type
println(path)
df.write.mode("overwrite").onerec(path)
}
val output_path = "/dataset/8c609a13/day_0/"
val db_path = "/dataset/d4f7e679/criteo_day_0_parquet/train/part_*.parquet"
convert_parquet(db_path, output_path, "train")
val db_path = "/dataset/d4f7e679/criteo_day_0_parquet/val/part_*.parquet"
convert_parquet(db_path, output_path, "val")Note: slot_size_array is generated in step 1, please find more description here.
- We provide an option to add offset for each slot by specifying slot_size_array. slot_size_array is an array whose length is equal to the number of slots. To avoid duplicate keys after adding offset, we need to ensure that the key range of the i-th slot is between 0 and slot_size_array[i]. We will do the offset in this way: for i-th slot key, we add it with offset slot_size_array[0] + slot_size_array[1] + ... + slot_size_array[i - 1]. In the configuration snippet noted above, for the 0th slot, offset 0 will be added. For the 1st slot, offset 278899 will be added. And for the third slot, offset 634776 will be added.