Explore


beautyyuyanli / multilingual-e5-large
multilingual-e5-large: A multi-language text embedding model
65.4M runs


prunaai / p-image-edit
A sub 1 second 0.01$ multi-image editing model built for production use cases. For image generation, check out p-image here: https://replicate.com/prunaai/p-image
24.2M runs


jaaari / kokoro-82m
Kokoro v1.0 - text-to-speech (82M params, based on StyleTTS2)
85.5M runs


adirik / grounding-dino
Detect everything with language!
32.3M runs
Featured models

Highest-quality text-to-speech with <200ms latency, emotion control, and 15-language support
22K runs

 bytedance/seedream-5-lite
bytedance/seedream-5-liteSeedream 5.0 lite: image generation with built-in reasoning, example-based editing, and deep domain knowledge
618.4K runs
 runwayml/gen-4.5
runwayml/gen-4.5State-of-the-art video motion quality, prompt adherence and visual fidelity
69K runs

 recraft-ai/recraft-v4
recraft-ai/recraft-v4Recraft's latest image generation model, built around design taste. Strong prompt accuracy, art-directed composition, and integrated text rendering. Fast and cost-efficient at standard resolution.
196.8K runs
 xai/grok-imagine-video
xai/grok-imagine-videoGenerate videos using xAI's Grok Imagine Video model
356.8K runs

 moonshotai/kimi-k2.5
moonshotai/kimi-k2.5Moonshot AI's latest open model. It unifies vision and text, thinking and non-thinking modes, and single-agent and multi-agent execution into one model
28.8K runs

 google/gemini-3-flash
google/gemini-3-flashGoogle's most intelligent model built for speed with frontier intelligence, superior search, and grounding
942.8K runs
prunaai/p-videoFast video generation with built-in draft mode for rapid creative iteration. Text-to-video, image-to-video, and audio-to-video in a single endpoint.
439.7K runs

 black-forest-labs/flux-2-klein-4b
black-forest-labs/flux-2-klein-4bVery fast image generation and editing model. 4 steps distilled, sub-second inference for production and near real-time applications.
9.6M runs

 openai/gpt-image-1.5
openai/gpt-image-1.5OpenAI's latest image generation model with better instruction following and adherence to prompts
7.3M runs
 google/nano-banana-2
google/nano-banana-2Google's fast image generation model with conversational editing, multi-image fusion, and character consistency
4.8M runs

 elevenlabs/music
elevenlabs/musicCompose a song from a prompt or a composition plan
32.2K runs
Official models
Official models are always on, maintained, and have predictable pricing.

wan-video / wan-2.7-image-pro
Generate and edit high-quality images with Alibaba's Wan 2.7 Pro with 4K output, thinking mode, text-to-image, multi-image editing, and image set generation

wan-video / wan-2.7-image
Generate and edit images with Alibaba's Wan 2.7

google / veo-3.1-lite
Google's cost-efficient video generation model with native audio, optimized for high-volume applications
wan-video / wan-2.7-videoedit
Edit videos with natural language instructions using Alibaba's Wan 2.7 VideoEdit model

wan-video / wan-2.7-r2v
Generate videos from reference images or clips while preserving subject identity using Alibaba's Wan 2.7 reference-to-video model

wan-video / wan-2.7-i2v
Generate videos from images, with support for first-and-last-frame control, clip continuation, and audio synchronization using Alibaba's Wan 2.7 model
wan-video / wan-2.7-t2v
Generate videos with audio from text prompts using Alibaba's Wan 2.7 model. 1080p, up to 15 seconds, with audio synchronization.
xai / grok-imagine-r2v
Generate videos guided by reference images using xAI's Grok Imagine Video model
xai / grok-imagine-video-extension
Extend videos with xAI's Grok Imagine Video model. Provide a source video and describe what happens next.

inworld / tts-1.5-mini
Ultra-fast, cost-efficient text-to-speech with ~120ms latency and 15-language support
inworld / tts-1.5-max
Highest-quality text-to-speech with <200ms latency, emotion control, and 15-language support

prunaai / p-image-upscale
Very efficient image upscaler supporting outputs up to 8 MP. Upscales images to 4 MP in under one second.
lightricks / ltx-2.3-pro
High-fidelity video generation with portrait support, audio-to-video, retake, and extend. Text, image, and audio-driven creation up to 4K at 50 FPS.

openai / gpt-5.4
OpenAI's most capable frontier model for complex professional work, coding, and multi-step reasoning.
lightricks / ltx-2.3-fast
Lightning-fast video generation with portrait support, camera controls, and synchronized audio. Up to 20 seconds at 1080p, 4K at 50 FPS.
kwaivgi / kling-v3-motion-control
Kling 3.0 motion control: transfer motion from a reference video to any character image with improved consistency and quality.
vidu / q3-turbo
Fast video generation with text-to-video, image-to-video, and start-end-to-video modes. Up to 16 seconds at 1080p with synchronized audio.

qwen / qwen-image-2-pro
The pro version of Qwen Image 2 from Alibaba's Qwen team. Enhanced text rendering, realism, and semantic adherence for high-quality image generation and editing.

qwen / qwen-image-2
A next-generation image generation and editing model from Alibaba's Qwen team. Supports text-to-image and image editing with strong text rendering, especially for Chinese.
heygen / avatar-iv
Create realistic talking avatar videos from text with HeyGen's Avatar IV engine
I want to…
View all collectionsGenerate images
Use AI to generate images & photos with an API
Caption videos
Use AI to caption videos with an API
Generate speech
Use AI for text-to-speech or to clone your voice via API
Generate images from a face
Use AI to generate images from a face with an API
Generate videos
Use AI to generate videos with an API
Upscale images with super resolution
Use AI to upscale images with super resolution with an API
Generate music
Use AI to generate music with an API
Edit any image
Use AI to edit any image via API
Transcribe speech to text
Use AI to transcribe speech to text via API
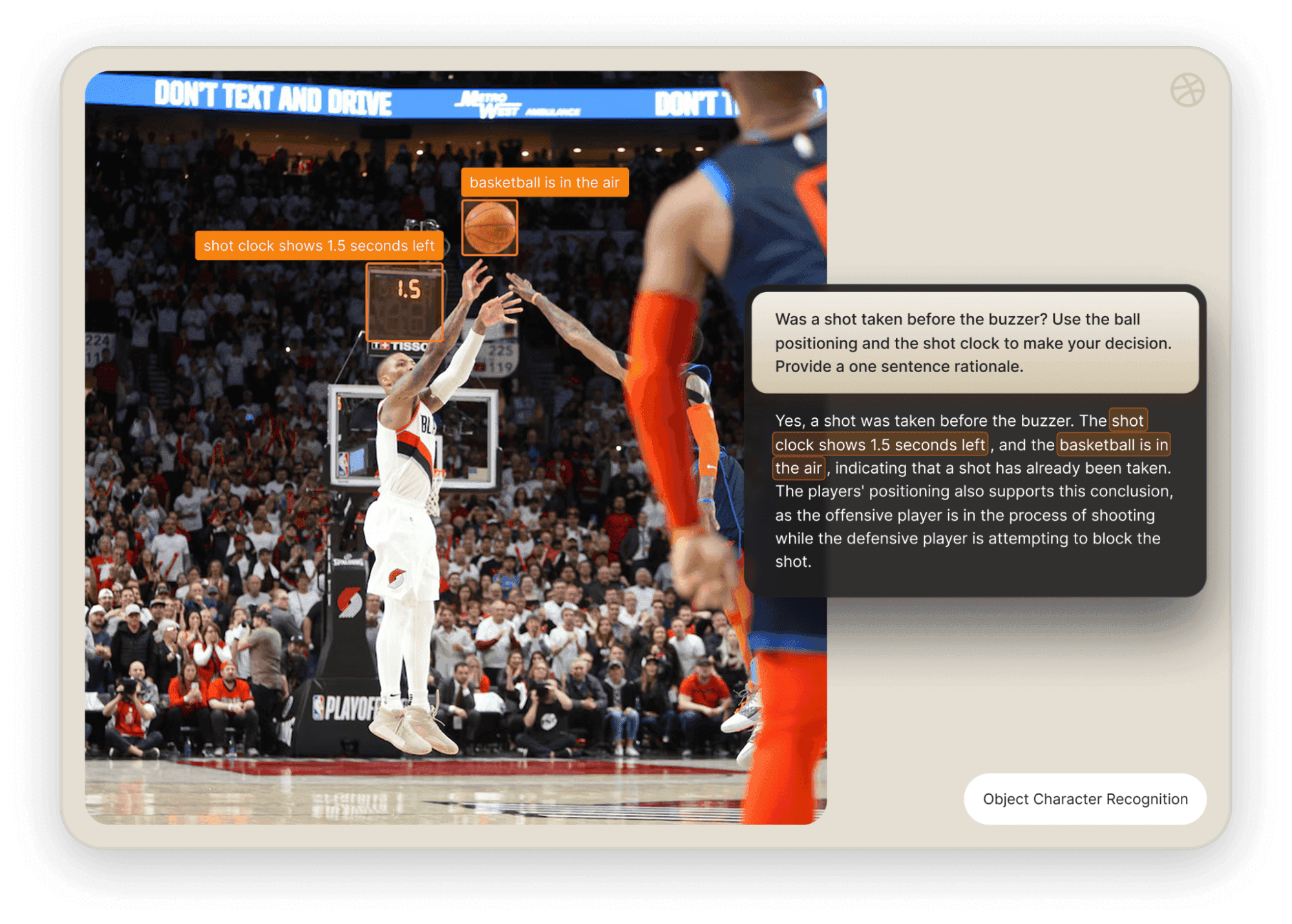
OCR to extract text from images
Use AI For Optical Character Recognition (OCR) to extract text from images via API
Remove backgrounds
Use AI to remove backgrounds from images and videos with an API
FLUX family of models
FLUX AI models: advanced image generation & editing via API
Restore images
Use AI to restore images via API
Enhance videos
Use AI to enhance videos via API - Replicate
Detect NSFW content
Detect NSFW content in images and text
Classify text
Classify text by sentiment, topic, intent, or safety
Speaker diarization
Identify speakers from audio and video inputs
Create realistic face swaps
Replace faces across images with natural-looking results.
Turn sketches into images
Transform rough sketches into polished visuals
Generate emojis
Generate custom emojis from text or images
Generate anime-style images and videos
Create anime-style characters, scenes, and animations
Generate videos from images
Use AI to Generate Videos from Images with API
Official models
Official models are always on, predictably priced, and have a stable API.
Large Language Models (LLMs)
Explore Large Language Models (LLMs) for chat, generation & NLP tasks via API
Try AI models for free
Try AI Models for free: video generation, image generation, upscaling, and photo restoration
Lipsync videos
Use AI to generate lipsync videos with an API
Create 3D content
Use AI to create 3D content with an API
Vision models
Chat with images for understanding, captioning & detection via API
Control image generation
Use AI to control image generation with an API
Embedding models
Embedding models for AI search and analysis
Edit your videos
Use AI to edit your videos with an API
Object detection and segmentation
Use AI object detection and segmentation models to distinguish objects in images & videos
Flux fine-tunes
Flux fine-tunes: build and run custom AI image models via API
Kontext fine-tunes
Kontext fine-tunes: Build custom AI image models with an API
Create songs with voice cloning
Create songs with voice cloning models via API
Media utilities
AI media utilities: auto-caption, watermark, frame extraction & more via API
Qwen-Image fine-tunes
Browse the diverse range of qwen-image fine-tunes the community has custom-trained on Replicate.
WAN family of models
WAN family of models: powerful image-to-video & text-to-video models
Caption Images
Use AI To Caption Images with an API