-
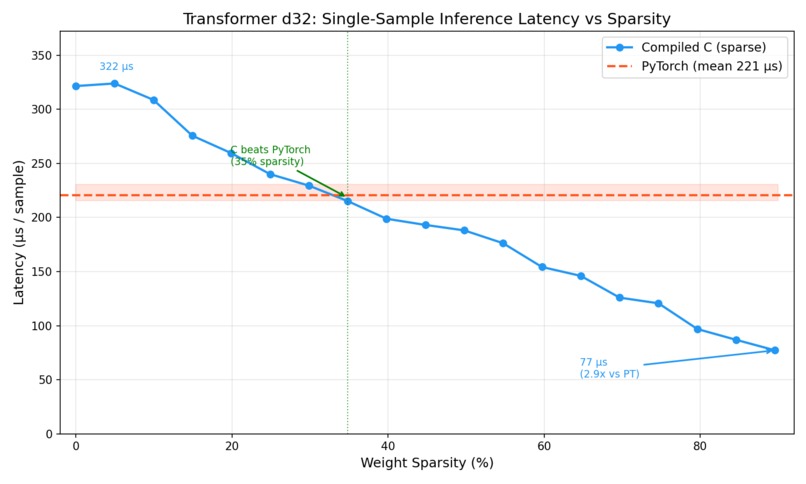
its sufficient sparsity, compilation becomes faster than PyTorch
-
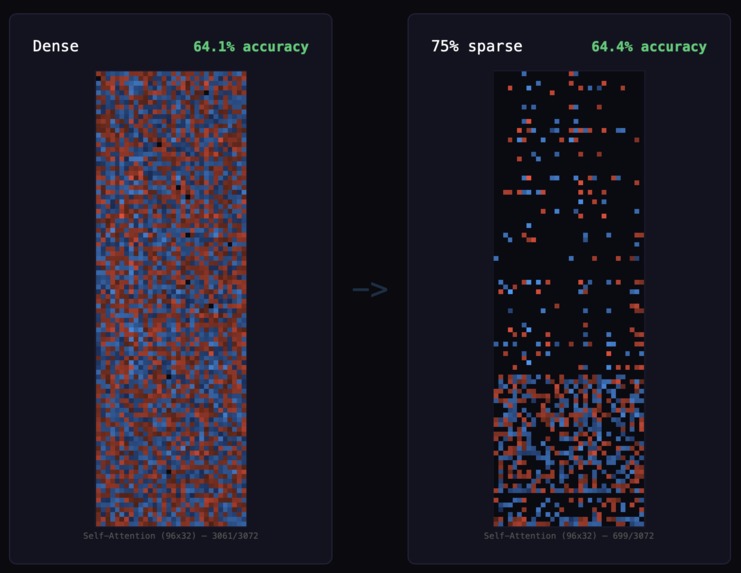
a view of the weight matrix (attn_in) before and after sparsification.
-
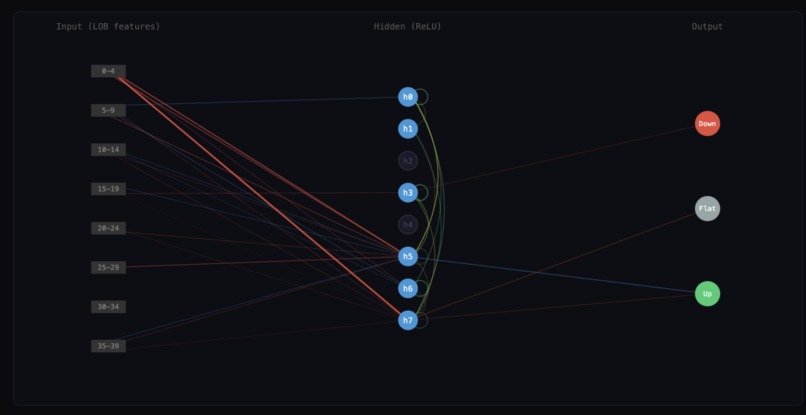
a visualisation of the sparse version of a model, before all nodes were connected to all other nodes
-
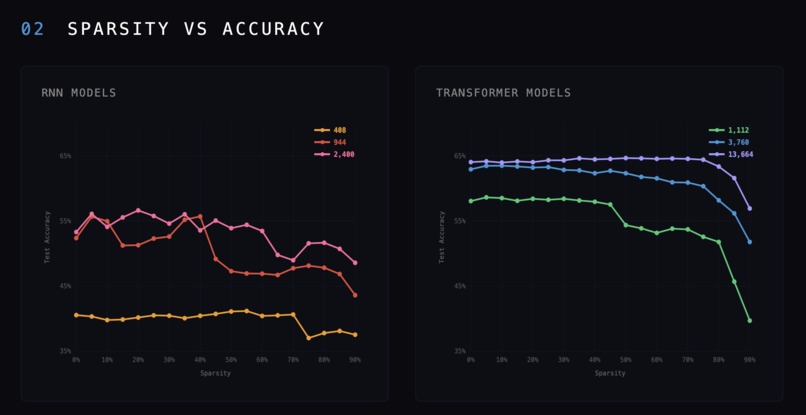
the accuracy / sparsity curves for models of varying parameter counts and architectures.




Inspiration
Leo Gao from OpenAI showed that weight sparse language models form interpretable circuits. His approach relies on OpenAI amounts of computers. I wanted to find an approach that didn't.
What it does
For any given dense model (a model where the majority / entirety of parameters are nonzero) I find an approach that, with very little compute, is capable of sparsifying the model. I demonstrate this with a suite of recurrent neural networks and transformers, trained on the FI-2010 dataset, to learn signal from a real LOB to predict up/down/constant. I then demonstrate that my technique is capable of reducing the number of parameters in those models by 75%+ with no hit to accuracy. This parameter reduction has direct effect on the speed of the algorithms execution by enabling compilation into C. I also show the scalability of this approach by transferring it to gpt2, fine-tuning on multiple datasets for sparsity and identifying fascinating specialisation dynamics, where unneeded knowledge can be removed from the model, to free up space for task-critical performance.
How we built it
I built it by directing multiple claudes to implement my ideas, test my hypotheses, and general engineering work. It implements a pipeline for training models, trains them, there are various scripts for doing mechanistic analysis, and compilation of a given sparse model into C, then benchmarking the speed of a compiled model against baselines.
The final sparsifying procedure functions like:
- identify the single weight in the model with the lowest magnitude.
- set it to 0.
- continue training on some task so the other weights pick up the slack
- if the removal caused the model to explode, undo and try again with the next smallest
- see 1
Challenges we ran into
This was basically a research project so trying 100 new ideas in 24 hours was the hard part, coming up with and directing subagents to test them.
Accomplishments that we're proud of
That it even slightly works :) there was a long period where many ideas didn't work, but then I found a successful
What we learned
Sparsity is underrated
What's next for Sparsity
I might write a paper or something.

Log in or sign up for Devpost to join the conversation.