|
I am a researcher at ByteDance Seed, working at unified multimodal model. Before that, I obtained Ph.D degree from Fudan University, advised by Prof. Rui Feng. I was also a vistor in MMLab, Nanyang Technological University, advised by Prof. Ziwei Liu. From 2020 to 2024, I researched on visual perception and created the Recognize Anything Model (RAM) Family: a series of open-source and powerful image perception models that exceed OpenAI's CLIP by more than 20 points in fine-grained perception. This work was done at OPPO Research Institute & IDEA, where I was fortunate to collaborate with Youcai Zhang, Prof. Yandong Guo, and Prof. Lei Zhang. From 2024 to 2025, I co-leader the full process construction (Pretrain, SFT, RL) of large multimodal models at TikTok AI Innovation Center, which achieve or exceed Qwen2.5-VL on 30+ benchmarks. During this period, I was fortunate to work closely with Bo Li, Wei Li, and Zejun Ma. |

|
|
|
|
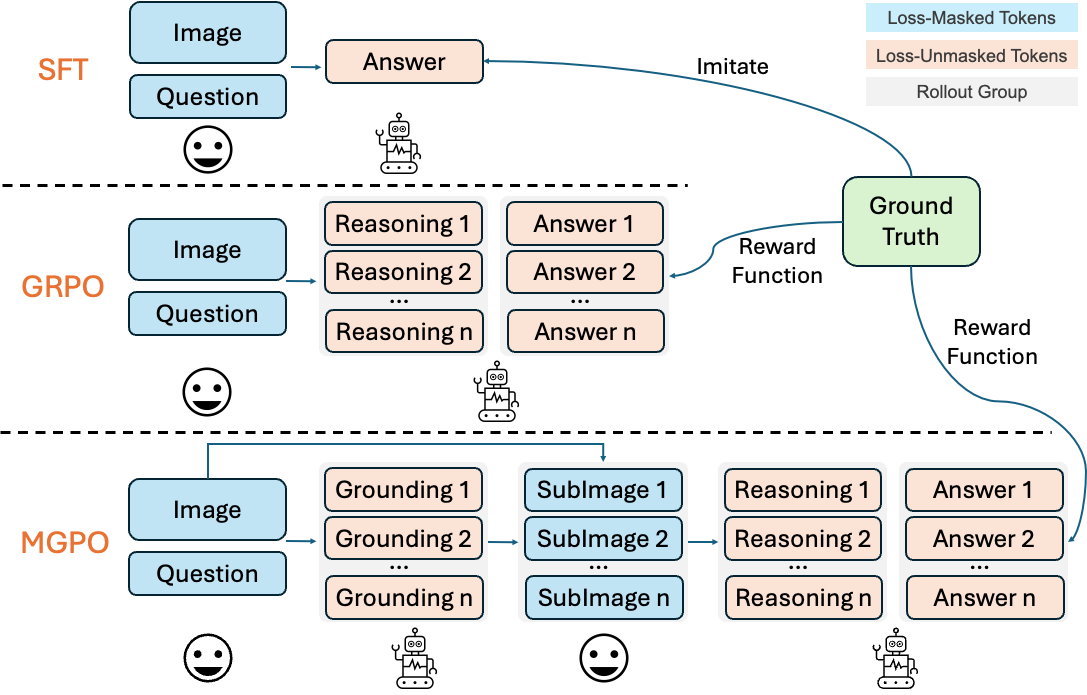
High-Resolution Visual Reasoning via Multi-Turn Grounding-Based Reinforcement Learning Xinyu Huang, Yuhao Dong, Wei Li, Jinming Wu, Zihao Deng, Weiwei Tian, Bo Li, Rui Feng, Zejun Ma, Ziwei Liu Arxiv, 2025 arXiv / code MGPO enables LMMs to iteratively focus on key image regions through automatic grounding, achieving superior performance on high-resolution visual tasks without requiring grounding annotations. |

|
Open-Set Image Tagging with Multi-Grained Text Supervision Xinyu Huang, Yi-Jie Huang, Youcai Zhang, Weiwei Tian, Rui Feng, Yuejie Zhang, Yanchun Xie, Yaqian Li, Lei Zhang Arxiv, 2023 arXiv / code RAM++ is the next generation of RAM, which can recognize any category with high accuracy, including both predefined common categories and diverse open-set categories. |

|
Recognize Anything: A Strong Image Tagging Model Youcai Zhang*, Xinyu Huang*, Jinyu Ma*, Zhaoyang Li*, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, Yandong Guo, Lei Zhang CVPR 2024, Multimodal Foundation Models Workshop project page / arXiv / demo / code RAM is an image tagging model, which can recognize any common category with high accuracy. |

|
Tag2Text: Guiding Vision-Language Model via Image Tagging Xinyu Huang, Youcai Zhang, Jinyu Ma, Weiwei Tian, Rui Feng, Yuejie Zhang, Yaqian Li, Yandong Guo, Lei Zhang ICLR 2024 project page / arXiv / demo / code Tag2Text is a vision-language model guided by tagging, which can support tagging and comprehensive captioning simultaneously. |

|
Xinyu Huang, Youcai Zhang, Ying Cheng, Weiwei Tian, Ruiwei Zhao, Rui Feng, Yuejie Zhang, Yaqian Li, Yandong Guo, Xiaobo Zhang ACM MM, 2022 arXiv / code We propose IDEA to provide more explicit textual supervision (including multiple valuable tags and texts composed by multiple tags) for visual models. |

|
Youcai Zhang*, Yuhao Cheng*, Xinyu Huang*, Fei Wen, Rui Feng, Yaqian Li, Yandong Guo Arxiv, 2021 arXiv / code Multi-label learning in the presence of missing labels(MLML) is a challenging problem. We propose two simple yet effective methods via robust loss design based on an observation. |
|
|

|
Project Creator/Owner 3.2K+ stars! We provide Recognize Anything Model Family (RAM) demonstrating superior image recognition ability! |

|
Project Co-Leader 16.3K+ stars! RAM Faimly marry Grounded-SAM, which can automatically recognize, detect, and segment for an image! RAM Family showcases powerful image recognition capabilities! |
|
|
|
CVPR, ICCV, ECCV, ICLR, NeurIPS, IJCV, WACV, ACMMM, etc. |