
Minki Hong
Hi! I’m Minki Hong. I recently graduated with an M.S. in Computer Science and Artificial Intelligence from Dongguk University, where I was advised by Prof. Jihie Kim. I was also a Visiting Scholar at the Bot Intelligence Group (BIG) at Carnegie Mellon University, working with Prof. Jean Oh.
I am currently an AI Researcher at SK Telecom, where I am contributing to a sovereign AI model development project. My work focuses on post-training large-scale models, improving multimodal reasoning, and building high-quality SFT and RL datasets at scale.
My broader research focuses on developing AI systems that align with human values and understand diverse contexts. Specifically, I am interested in:
- Generative AI & Social Norms: Modeling cultural and social contexts for safer dialogue and interaction.
- Fairness & Inclusivity: Mitigating cultural and demographic biases in generative models (e.g., image-to-image editing).
- Reasoning Capabilities: Eliciting better reasoning in LLMs and VLMs through interpretation grounding and chain-of-thought prompting.
If you would like to connect or chat, please feel free to reach out:
📧 bk123477@gmail.com | 🔗 LinkedIn | 📝 GitHub
📰 Selected News
Starting Internship at SKT 🚀
I will be joining SK Telecom (SKT) as an intern from March 16 to June 30, 2026, working on their proprietary foundation model. Excited to contribute to the development of...
🎉 SAC Highlights at EMNLP 2025 🎉
I’m honored to share that I presented my first paper at EMNLP2025, the very conference where I first read the paper that sparked my journey into AI research: “SODA: Million-scale...
Visiting Students
I will be joining Bot Intelligence Group at Carnegie Mellon University Robotics Institute as a visiting student for six months.
📚 Selected Publications
NormGenesis: Multicultural Dialogue Generation via Exemplar-Guided Social Norm Modeling and Violation Recovery
EMNLP 2025, 2025
Abstract
Social norms govern culturally appropriate behavior in communication, enabling dialogue systems to produce responses that are not only coherent but also socially acceptable. We present NormGenesis, a multicultural framework for generating and annotating socially grounded dialogues across English, Chinese, and Korean. To model the dynamics of social interaction beyond static norm classification, we propose a novel dialogue type, Violation-to-Resolution (V2R), which models the progression of conversations following norm violations through recognition and socially appropriate repair. To improve pragmatic consistency in underrepresented languages, we implement an exemplar-based iterative refinement early in the dialogue synthesis process. This design introduces alignment with linguistic, emotional, and sociocultural expectations before full dialogue generation begins. Using this framework, we construct a dataset of 10,800 multi-turn dialogues annotated at the turn level for norm adherence, speaker intent, and emotional response. Human and LLM-based evaluations demonstrate that NormGenesis significantly outperforms existing datasets in refinement quality, dialogue naturalness, and generalization performance. We show that models trained on our V2R-augmented data exhibit improved pragmatic competence in ethically sensitive contexts. Our work establishes a new benchmark for culturally adaptive dialogue modeling and provides a scalable methodology for norm-aware generation across linguistically and culturally diverse languages.

Exposing Blindspots: Cultural Bias Evaluation in Generative Image Models
IASEAI 2026, 2025
Abstract
Generative image models produce striking visuals yet often misrepresent culture. Prior work has examined cultural bias mainly in text-to-image (T2I) systems, leaving image-to-image (I2I) editors underexplored. We bridge this gap with a unified evaluation across six countries, an 8-category/36-subcategory schema, and era-aware prompts, auditing both T2I generation and I2I editing under a standardized protocol that yields comparable diagnostics. Using open models with fixed settings, we derive cross-country, cross-era, and cross-category evaluations. Our framework combines standard automatic metrics, a culture-aware retrieval-augmented VQA, and expert human judgments collected from native reviewers. To enable reproducibility, we release the complete image corpus, prompts, and configurations. Our study reveals three findings: (1) under country-agnostic prompts, models default to Global-North, modern-leaning depictions that flatten cross-country distinctions; (2) iterative I2I editing erodes cultural fidelity even when conventional metrics remain flat or improve; and (3) I2I models apply superficial cues (palette shifts, generic props) rather than era-consistent, context-aware changes, often retaining source identity for Global-South targets. These results highlight that culture-sensitive edits remain unreliable in current systems. By releasing standardized data, prompts, and human evaluation protocols, we provide a reproducible, culture-centered benchmark for diagnosing and tracking cultural bias in generative image models.
VisDoT : Enhancing Visual Reasoning through Human-Like Interpretation Grounding and Decomposition of Thought
EACL 2026 (Findings), 2026
Abstract
Large vision-language models (LVLMs) struggle to reliably detect visual primitives in charts and align them with semantic representations, which severely limits their performance on complex visual reasoning. This lack of perceptual grounding constitutes a major bottleneck for chart-based reasoning. We propose VisDoT, a framework that enhances visual reasoning through human-like interpretation grounding. We formalize four perceptual tasks based on the theory of graphical perception, including position and length. Building on this foundation, we introduce Decomposition-of-Thought (DoT) prompting, which sequentially separates questions into visual perception sub-questions and logic sub-questions. Fine-tuning InternVL with VisDoT achieves a +11.2% improvement on ChartQA and surpasses GPT-4o on the more challenging ChartQAPro benchmark. On the newly introduced VisDoTQA benchmark, the model improves by +33.2%. Furthermore, consistent zero-shot gains on diverse open-domain VQA benchmarks confirm the generalizability of the perception-logic separation strategy for visual question answering. VisDoT leverages human-like perception to enhance visual grounding, achieving state-of-the-art chart understanding and interpretable visual reasoning.
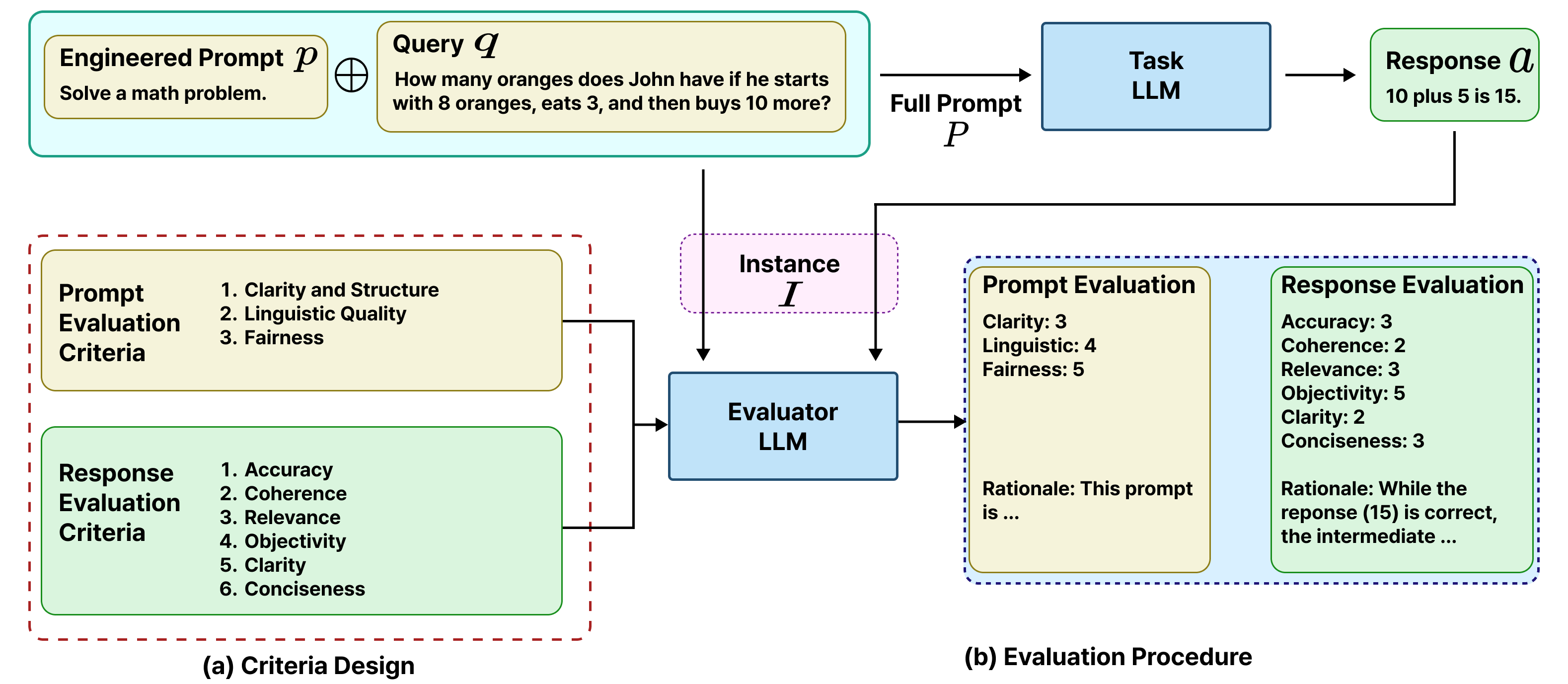
PEEM: Prompt Engineering Evaluation Metrics for Interpretable Joint Evaluation of Prompts and Responses in LLMs
IEEE Access, 2026
Abstract
Prompt design is a primary control interface for large language models (LLMs), yet standard evaluations largely reduce performance to answer correctness, obscuring why a prompt succeeds or fails and providing little actionable guidance. We propose PEEM (Prompt Engineering Evaluation Metrics), a unified framework for joint and interpretable evaluation of both prompts and responses. PEEM defines a structured rubric with 9 axes: 3 prompt criteria (clarity/structure, linguistic quality, fairness) and 6 response criteria (accuracy, coherence, relevance, objectivity, clarity, conciseness), and uses an LLM-based evaluator to output (i) scalar scores on a 1-5 Likert scale and (ii) criterion-specific natural-language rationales grounded in the rubric. Across 7 benchmarks and 5 task models, PEEM's accuracy axis strongly aligns with conventional accuracy while preserving model rankings (aggregate Spearman rho about 0.97, Pearson r about 0.94, p < 0.001). A multi-evaluator study with four models shows consistent relative judgments (pairwise rho = 0.68-0.85), supporting evaluator-agnostic deployment. Beyond alignment, PEEM captures complementary linguistic failure modes and remains informative under prompt perturbations: prompt-quality trends track downstream accuracy under iterative rewrites, semantic adversarial manipulations induce clear score degradation, and meaning-preserving paraphrases yield high stability (robustness rate about 76.7-80.6%). Finally, using only PEEM scores and rationales as feedback, a zero-shot prompt rewriting loop improves downstream accuracy by up to 11.7 points, outperforming supervised and RL-based prompt-optimization baselines. Overall, PEEM provides a reproducible, criterion-driven protocol that links prompt formulation to response behavior and enables systematic diagnosis and optimization of LLM interactions.