Στις 29 Μαΐου 2026 στο Παρίσι, οι υπουργοί Ψηφιακής Τεχνολογίας των χωρών G7 ενέκριναν ένα «Όραμα για τις ευκαιρίες ανοιχτότητας στην ΤΝ και κοινή ορολογία». Το κείμενο αυτό, που θέτει το εννοιολογικό πλαίσιο γύρω από την ανοιχτότητα στην ΤΝ, είναι καρπός τριών μηνών συνεργασίας ανάμεσα στο Open Source Initiative (https://opensource.org ) και τη G7.
Το Όραμα για την ΤΝ, που εντάσσεται στο πλαίσιο της Γαλλικής Προεδρίας της G7, αναδεικνύει τον καθοριστικό ρόλο της κοινότητας Ανοιχτού Κώδικα στη διαμόρφωση και τον ορισμό της έννοιας «Ανοιχτή ΤΝ». Παράλληλα, αναγνωρίζει τη δυσκολία που υπάρχει στην κατανόηση του τι σημαίνει «ανοιχτό» στο πλαίσιο της ΤΝ, ποια στοιχεία καθορίζουν αυτή την ανοιχτότητα, και ζητά τη χρήση σαφών και εύστοχων ετικετών που να αποτυπώνουν με ακρίβεια τον βαθμό ανοιχτότητας κάθε συστήματος ΤΝ.
Για τον σκοπό αυτό, το Όραμα θεσπίζει σαφή κριτήρια κατηγοριοποίησης: τα μοντέλα με ιδιοκτησιακή αδειοδότηση φέρουν την ετικέτα «Weights Available» (Διαθέσιμα Βάρη), ενώ εκείνα που διανέμονται με άδεια Ανοιχτού Κώδικα ονομάζονται «Open Weights» (Ανοιχτά Βάρη). Όσον αφορά την Ανοιχτή ΤΝ ειδικότερα, τα κριτήρια βασίζονται σε μεγάλο βαθμό στον ορισμό Ανοιχτής ΤΝ (OSAID) του OSI, με τη διαφορά ότι οι εξαιρέσεις για τη μη δημοσίευση δεδομένων εκπαίδευσης περιορίζονται αυστηρά σε περιπτώσεις νομικής ή τεχνικής αδυναμίας, ενώ απαιτείται τουλάχιστον τεκμηρίωση σχετικά με αυτά. Τέλος, προστίθεται η κατηγορία «Open Source AI with Open Data», που αφορά συστήματα ΤΝ όπου όλα τα στοιχεία διατίθενται ελεύθερα υπό άδεια Ανοιχτού Κώδικα — βάρη μοντέλων, κώδικας ανάπτυξης, κώδικας εκπαίδευσης και το πλήρες σύνολο δεδομένων εκπαίδευσης.
Ως εταίρος γνώσης σε αυτή τη διαδικασία, το OSI ανέλαβε να φέρει τις φωνές των κοινοτήτων Ανοιχτού Κώδικα στο τραπέζι των G7, αξιοποιώντας την τεχνογνωσία και εμπειρία που συσσώρευσε κατά την εκπόνηση του OSAID, καθώς και τα σχόλια που έλαβε από τις κοινότητες. Στη διάρκεια τριών μηνών, στελέχη του OSI συμμετείχαν ενεργά στη σύνταξη του Οράματος, παρακολούθησαν διαδικτυακές διαπραγματεύσεις και έλαβαν μέρος στις δια ζώσης συνόδους στο Παρίσι.
Ο Εκτελεστικός Διευθυντής του OSI, Duane O’Brien, υποδέχθηκε με ικανοποίηση την εξέλιξη αυτή:
«Το Όραμα της G7 για την Ανοιχτότητα στην ΤΝ είναι το πρώτο έγγραφο του είδους που συντάχθηκε με τόσο άμεση και ουσιαστική συμμετοχή κυβερνήσεων και εκπροσώπων της κοινότητας Ανοιχτού Κώδικα. Πιστεύουμε ότι θα αποτελέσει σημείο αναφοράς για τη διαμόρφωση σαφήνειας γύρω από την Ανοιχτή ΤΝ, και εκφράζουμε την ευγνωμοσύνη μας στη Γαλλική Προεδρία της G7 για τη συμπεριληπτική προσέγγισή της, την εμπιστοσύνη και την αμέριστη υποστήριξή της σε κάθε στάδιο αυτής της διαδικασίας.»
Στη Υπουργική Διακήρυξη της G7 για τα Ψηφιακά & Τεχνολογικά Θέματα, οι υπουργοί αναγνώρισαν ρητά τη συμβολή του OSI, εκφράζοντας εκτίμηση για «την πολύτιμη συνεισφορά του Open Source Initiative, καθώς και άλλων μελών της κοινότητας, στην υποστήριξη ανάπτυξης αυτού του εγγράφου».
Κατά την παρουσίαση που ακολούθησε μπροστά στους υπουργούς, ο Duane O’Brien τόνισε τη σημασία της συνέχισης αυτής της συνεργασίας:
«Ο Ανοιχτός Κώδικας άλλαξε ριζικά την παγκόσμια βιομηχανία λογισμικού. Μας επέτρεψε να συνεργαζόμαστε γρήγορα και αποτελεσματικά, αναπτύσσοντας κοινές λύσεις για κοινά προβλήματα. Αυτή η αλλαγή κατέστη εφικτή γιατί, όταν συνεργαζόμαστε, μοιραζόμαστε την ίδια αντίληψη για το τι σημαίνει Ανοιχτός Κώδικας. Καθώς εξελίσσουμε την κατανόησή μας για την Ανοιχτή ΤΝ, είναι απαραίτητο να διατηρήσουμε αυτή την κοινή βάση. Ελπίζουμε να συνεχίσουμε τη στενή συνεργασία με τις χώρες G7 και δηλώνουμε έτοιμοι να αποτελούμε εταίρους γνώσης σας τα χρόνια που έρχονται.»
Εάν θέλεις να λαμβάνεις κάθε μήνα το ενημερωτικό δελτίο για τις Ανοιχτές Τεχνολογίες καταχώρησε εδώ (https://newsletters.ellak.gr/?p=subscribe&id=) το email σου. Το ενημερωτικό δελτίο στέλνεται κάθε μήνα σε πάνω από 60.000 παραλήπτες.
Στο argilla.glossapi.gr καλούμε εθελοντές από τις κοινότητες ανοιχτού λογισμικού, ερευνητές, γλωσσολόγους, μεταφραστές, προγραμματιστές, εκπαιδευτικούς και κάθε ενεργό χρήστη της ελληνικής γλώσσας να συμμετάσχουν στη διαδικασία Μάθησης από Ανθρώπινη Ανάδραση (RLHF). Στην πράξη αυτό σημαίνει κάτι απλό αλλά εξαιρετικά σημαντικό: να βοηθήσουμε τα γλωσσικά μοντέλα να ξεχωρίζουν ποια απάντηση είναι φυσική, σαφής, ακριβής και ποια ακούγεται ξένη, άκαμπτη ή «ρομποτική». Η RLHF βασίζεται ακριβώς σε αυτή την ανθρώπινη αξιολόγηση, ώστε το μοντέλο να βελτιώνεται με βάση ανθρώπινες κρίσεις και όχι μόνο στατιστικά μοτίβα.
H ΕΕΛΛΑΚ συμμετέχει ως mentor organization στο πρόγραμμα, υποστηρίζοντας έργα ανοιχτού κώδικα που θα υλοποιηθούν από φοιτητές, ερευνητές και νέους προγραμματιστές από όλο τον κόσμο κατά τη διάρκεια του καλοκαιριού του 2026. Οι συμμετέχοντες που θα ολοκληρώσουν επιτυχώς το πρόγραμμα θα λάβουν αμοιβή έως 3.600$ για τη συνεισφορά τους. Φέτος, η ΕΕΛΛΑΚ συμμετέχει με 7 έργα ανοιχτού κώδικα, που καλύπτουν ένα ευρύ φάσμα τομέων: από την Τεχνητή Νοημοσύνη και την επεξεργασία φυσικής γλώσσας, έως τις διαστημικές εφαρμογές, την εκπαιδευτική ρομποτική και την ασφάλεια λογισμικού. Η πλήρης λίστα των έργων είναι διαθέσιμη στη σελίδα του ΕΕΛΛΑΚ στο GSoC 2026.
Πέντε εβδομάδες μετά την ανακοίνωση της ελληνικής κυβέρνησης για την επιβολή απαγόρευσης πρόσβασης σε μέσα κοινωνικής δικτύωσης για παιδιά κάτω των 15 ετών, 25 οργανισμοί από την Ελλάδα και το εξωτερικό έσπευσαν να υψώσουν τη φωνή τους. Με ανοιχτή επιστολή που κατατέθηκε στις 19 Μαΐου 2026 και απευθύνεται στον Πρωθυπουργό Κυριάκο Μητσοτάκη και τέσσερις αρμόδιους υπουργούς, οι υπογράφοντες φορείς — ανάμεσά τους το Δίκτυο για τα Δικαιώματα του Παιδιού, η Διεθνής Αμνηστία Ελλάδας, η Ελληνική Ένωση για τα Δικαιώματα του Ανθρώπου, το Homo Digitalis. o Οργανισμός Ανοιχτών Τεχνολογιών – ΕΕΛΛΑΚ και η European Digital Rights (EDRi) — καταθέτουν δέκα τεκμηριωμένους προβληματισμούς για τη νομοθετική πρωτοβουλία.
Ο Οργανισμός Ηνωμένων Εθνών ανακοίνωσε την έναρξη λειτουργίας της πλατφόρμας Open Source United (OSU), ενός νέου κεντρικού κόμβου που φιλοδοξεί να συγκεντρώσει και να συντονίσει όλες τις δράσεις ανοιχτού λογισμικού στο οικοσύστημα του ΟΗΕ. Η πρωτοβουλία αυτή σηματοδοτεί μια σημαντική καμπή για τη διεθνή συνεργασία στον τομέα της ψηφιακής διακυβέρνησης, της διαφάνειας και της βιώσιμης τεχνολογικής ανάπτυξης.
Η Σουηδία κάνει ένα σημαντικό βήμα προς την ψηφιακή κυριαρχία και τη διαλειτουργικότητα στον δημόσιο τομέα, υιοθετώντας το ανοιχτό πρότυπο επικοινωνίας Matrix για τη διασύνδεση κυβερνητικών υπηρεσιών. Η πρωτοβουλία αυτή φέρνει στο προσκήνιο ένα νέο μοντέλο συνεργασίας, όπου διαφορετικοί οργανισμοί μπορούν να επικοινωνούν απρόσκοπτα, ακόμη κι αν χρησιμοποιούν διαφορετικές πλατφόρμες και προμηθευτές λογισμικού.
Η σωστή στρατηγική για την Τεχνητή Νοημοσύνη δεν είναι να επιλεγεί μία και μοναδική τεχνολογική λύση. Δεν χρειάζεται όλα να τρέχουν σε υπερυπολογιστές, όπως δεν είναι λογικό κάθε δημόσιος φορέας, πανεπιστήμιο, σχολείο ή επιχείρηση να εξαρτάται από εμπορικά cloud API. Η ορθολογική προσέγγιση είναι πολυεπίπεδη: εθνικές υποδομές υψηλής υπολογιστικής ισχύος για τα βαριά φορτία, τοπικές ανοιχτές υποδομές για καθημερινή ασφαλή χρήση και εναλλακτικές πλατφόρμες υλικού ώστε να μη δημιουργηθεί νέος τεχνολογικός εγκλωβισμός.
Η Ευρωπαϊκή Επιτροπή αποφάσισε τελικά να εγκαταλείψει το επίμαχο άρθρο της Οδηγίας για τον Ραδιοεξοπλισμό (Radio Equipment Directive – RED) που απειλούσε για περισσότερο από μία δεκαετία την ελευθερία του λογισμικού σε εκατομμύρια συσκευές. Πρόκειται για μια σημαντική νίκη για το Ευρωπαϊκό Ίδρυμα Ελεύθερου Λογισμικού (FSFE) και για τον ευρύτερο συνασπισμό οργανώσεων και πολιτών που επί χρόνια αντιστάθηκαν στο λεγόμενο «Radio Lockdown».
Η χρήση της Τεχνητής Νοημοσύνης στον προγραμματισμό έχει ήδη αλλάξει τον τρόπο με τον οποίο γράφεται λογισμικό. Από την αυτόματη συμπλήρωση στον επεξεργαστή κώδικα μέχρι τους αυτόνομους πράκτορες που μπορούν να ανοίγουν αιτήματα αλλαγών, να τροποποιούν αρχεία και να προτείνουν διορθώσεις, οι προγραμματιστές εργάζονται πια μαζί με συστήματα που παράγουν κώδικα γρήγορα, πειστικά και συχνά εντυπωσιακά. Το κρίσιμο πρόβλημα όμως δεν είναι ότι η ΤΝ κάνει λάθη. Όλοι οι προγραμματιστές κάνουν λάθη. Το πρόβλημα είναι ότι η ΤΝ παράγει λάθη που μοιάζουν σωστά.
Η συνεχώς αυξανόμενη ανάγκη για επαλήθευση ταυτότητας και ηλικίας στο διαδίκτυο δημιουργεί ένα κρίσιμο ερώτημα: πώς μπορούν οι χρήστες να αποδεικνύουν ποιοι είναι χωρίς να θυσιάζουν την ιδιωτικότητά τους; Μια νέα πρωτοβουλία από το Πανεπιστήμιο Harvard και το Linux Foundation φιλοδοξεί να δώσει απάντηση μέσα από το Keyring, ένα ανοιχτού κώδικα ψηφιακό πορτοφόλι ταυτότητας που επιτρέπει στους χρήστες να ελέγχουν πλήρως ποια προσωπικά δεδομένα μοιράζονται.
Η ελβετική κυβέρνηση κάνει ένα σημαντικό βήμα προς την ενίσχυση της ψηφιακής της ανεξαρτησίας, επιδιώκοντας να μειώσει σταδιακά την εξάρτησή της από ιδιόκτητο λογισμικό και ξένους τεχνολογικούς παρόχους. Η πρωτοβουλία αυτή εντάσσεται σε μια ευρύτερη στρατηγική για την ενίσχυση της «ψηφιακής κυριαρχίας» της χώρας και τη στροφή προς λύσεις ανοιχτού κώδικα (open source).
Τι συμβαίνει όταν τρεις ευρωπαϊκές δημόσιες διοικήσεις αποφασίζουν να περάσουν από την απλή συνεργασία στη συν-ανάπτυξη ψηφιακών εργαλείων; Από το 2023, η Γαλλία, η Γερμανία και η Ολλανδία επιχειρούν να δώσουν μια πρακτική απάντηση σε αυτό το ερώτημα, χτίζοντας από κοινού λογισμικό ανοικτού κώδικα για τον δημόσιο τομέα.
Η Ολλανδία προχώρησε στη δοκιμαστική έναρξη λειτουργίας της νέας πλατφόρμας αποθετηρίου κώδικα code.overheid.nl, η οποία προορίζεται για τη δημόσια διοίκηση και βασίζεται στο λογισμικό ανοιχτού κώδικα Forgejo. Η πλατφόρμα φιλοξενείται αποκλειστικά από το ίδιο το ολλανδικό κράτος και διαχειρίζεται από το Open Source Programme Office (OSPO) του Υπουργείου Εσωτερικών και Σχέσεων του Βασιλείου.
Το πρώτο ακαδημαϊκό Open Source Program Office (OSPO) στη Γαλλία εγκαινιάστηκε επίσημα τον Σεπτέμβριο του 2025 από το Université Grenoble Alpes (UGA), σηματοδοτώντας ένα καθοριστικό βήμα για την ενίσχυση του ανοικτού λογισμικού στην έρευνα και την ανώτατη εκπαίδευση. Παράλληλα με τα εγκαίνια, η ομάδα του νέου OSPO δημοσίευσε αναλυτική έκθεση που προτείνει πλαίσιο λειτουργίας για μελλοντικά ακαδημαϊκά OSPOs, καθώς και τη δημιουργία εθνικού δικτύου στη Γαλλία.
Τα τελευταία χρόνια, κυβερνήσεις σε διάφορες περιοχές του κόσμου έχουν χρησιμοποιήσει το «κατέβασμα του διακόπτη» του διαδικτύου ως μέσο ελέγχου πολιτικών εξεγέρσεων, κοινωνικών αναταραχών ή διαμαρτυριών. Παράλληλα, φυσικές καταστροφές όπως σεισμοί, πυρκαγιές, τυφώνες και πλημμύρες μπορούν επίσης να καταστρέψουν κρίσιμες υποδομές επικοινωνίας, αφήνοντας ολόκληρες κοινότητες απομονωμένες. Μέσα σε αυτό το περιβάλλον, η ανάγκη για αποκεντρωμένες και ανθεκτικές μορφές επικοινωνίας γίνεται ολοένα και πιο σημαντική. Η τεχνολογία μπορεί να προσφέρει εναλλακτικούς τρόπους σύνδεσης που δεν εξαρτώνται αποκλειστικά από τις παραδοσιακές τηλεπικοινωνιακές υποδομές ή από μεγάλες εταιρείες τεχνολογίας.
Το CERN ανακοίνωσε τη διάθεση της πλήρους βιβλιοθήκης εξαρτημάτων για το λογισμικό σχεδίασης ηλεκτρονικών κυκλωμάτων KiCad ως λογισμικό ανοιχτού κώδικα, προσφέροντας σε μηχανικούς και σχεδιαστές hardware σε όλο τον κόσμο πρόσβαση σε περισσότερα από 17.000 ηλεκτρονικά εξαρτήματα.
Η μεγάλη πρόκληση της επόμενης δεκαετίας δεν είναι μόνο η ανάπτυξη πιο ισχυρών συστημάτων AI, αλλά η διασφάλιση ότι αυτά θα λειτουργούν προς όφελος της κοινωνίας. Η τεχνητή νοημοσύνη δεν πρέπει να ενισχύσει τις ήδη υπάρχουσες ανισότητες, αλλά να συμβάλει σε ένα πιο δίκαιο και βιώσιμο μέλλον.
Η νέα έκθεση του Communia Association με τίτλο «The Post-DSM Copyright Report» επιχειρεί μια εκτενή αποτίμηση του τρόπου με τον οποίο τα κράτη-μέλη της Ευρωπαϊκής Ένωσης έχουν εφαρμόσει βασικές διατάξεις της Οδηγίας DSM (Digital Single Market Directive) σχετικά με τα πνευματικά δικαιώματα. Η μελέτη επικεντρώνεται κυρίως στα δικαιώματα των χρηστών, στην έρευνα, στην εκπαίδευση, στην πολιτιστική κληρονομιά και στις νέες προκλήσεις που δημιουργεί η ανάπτυξη της τεχνητής νοημοσύνης.
Η νέα μελέτη με τίτλο «Publishing Cultural Heritage Data in the Age of AI», που εκπονήθηκε για λογαριασμό του Europeana Foundation από το Open Future Foundation, εξετάζει ακριβώς αυτό το ζήτημα: πώς μπορούν οι οργανισμοί πολιτιστικής κληρονομιάς να διατηρήσουν την αποστολή της ανοιχτής πρόσβασης στη γνώση, χωρίς όμως να μετατραπούν σε ανεξέλεγκτους προμηθευτές δεδομένων για μεγάλες εταιρείες τεχνητής νοημοσύνης.
Το λογισμικό ανοιχτού κώδικα (Open Source Software) αποτελεί πλέον βασικό πυλώνα της σύγχρονης τεχνολογικής υποδομής για οργανισμούς και επιχειρήσεις παγκοσμίως. Από cloud πλατφόρμες και data centers μέχρι εφαρμογές τεχνητής νοημοσύνης, οι επαγγελματίες του open source βρίσκονται στο επίκεντρο της ψηφιακής καινοτομίας. Για αυτόν τον λόγο, η κατανόηση των κινήτρων και των επαγγελματικών προτεραιοτήτων τους αποκτά ιδιαίτερη σημασία.
Η καινοτομία αποτελεί έναν από τους σημαντικότερους παράγοντες οικονομικής ανάπτυξης και ανταγωνιστικότητας για την Ευρωπαϊκή Ένωση. Σε έναν κόσμο όπου η τεχνολογική πρόοδος εξελίσσεται με ταχύτατους ρυθμούς, η ικανότητα των χωρών να επενδύουν στην έρευνα, στην εκπαίδευση και στις νέες τεχνολογίες καθορίζει σε μεγάλο βαθμό τη θέση τους στη διεθνή οικονομία. Μέσα σε αυτό το πλαίσιο, το European Innovation Scoreboard (EIS) λειτουργεί ως ένα από τα σημαντικότερα εργαλεία αξιολόγησης της καινοτομικής επίδοσης των ευρωπαϊκών κρατών.
Η συζήτηση για τα τοπικά γλωσσικά μοντέλα δεν πρέπει να ξεκινά από το ερώτημα «ποιο μοντέλο έχει το υψηλότερο σκορ». Για έναν προγραμματιστή, έναν δήμο, ένα υπουργείο ή μια δημόσια υποδομή, το σωστό ερώτημα είναι πιο πρακτικό: ποιο μοντέλο μπορεί να τρέξει σταθερά, με αποδεκτό χρόνο απόκρισης, με ελεγχόμενο κόστος, με προστασία δεδομένων και με δυνατότητα ελέγχου από την ίδια την κοινότητα που το χρησιμοποιεί;
Η απάντηση δεν είναι ένα μοντέλο. Είναι μια στοίβα επιλογών. Άλλο μοντέλο χρειάζεται ο προγραμματιστής για γρήγορη συμπλήρωση κώδικα μέσα στο περιβάλλον ανάπτυξης, άλλο μοντέλο χρειάζεται μια ομάδα λογισμικού για ανάλυση αποθετηρίου και διόρθωση σφαλμάτων, άλλο μοντέλο χρειάζεται ένας δημόσιος φορέας για αναζήτηση σε ΦΕΚ, αποφάσεις, εγκυκλίους και διαδικασίες. Η τοπική ΤΝ έχει νόημα όταν σχεδιάζεται ως δημόσια και παραγωγική υποδομή, όχι ως εντυπωσιακή επίδειξη.
Τα καταλληλότερα μοντέλα για βοηθούς προγραμματισμού
Για εργασίες προγραμματισμού, οι πιο χρήσιμες οικογένειες σήμερα είναι τα Qwen3-Coder, Devstral, StarCoder2 και, σε ειδικές περιπτώσεις, μικρότερα μοντέλα για γρήγορη συμπλήρωση. Το Qwen3-Coder είναι ισχυρή επιλογή για σύνθετες εργασίες κώδικα, ανάλυση μεγαλύτερων αποθετηρίων, χρήση εργαλείων και αυτοματοποιημένες ροές όπου το μοντέλο πρέπει να διαβάζει αρχεία, να προτείνει αλλαγές, να εκτελεί δοκιμές και να επανέρχεται με διορθώσεις. Η έκδοση Qwen3-Coder-30B-A3B είναι ιδιαίτερα ενδιαφέρουσα για σταθμούς εργασίας με ισχυρή κάρτα γραφικών, επειδή ενεργοποιεί μικρότερο μέρος των παραμέτρων ανά βήμα και άρα μπορεί να είναι αποδοτικότερη από ένα αντίστοιχο πλήρως πυκνό μοντέλο.
Το Devstral είναι επίσης πολύ ισχυρή επιλογή για μηχανικούς λογισμικού. Δεν είναι απλώς μοντέλο που γράφει συναρτήσεις. Έχει σχεδιαστεί για εργασίες τύπου πράκτορα λογισμικού, όπου χρειάζεται να κατανοήσει το πλαίσιο ενός έργου, να εντοπίσει λάθη, να προτείνει αλλαγές και να συνεργαστεί με εργαλεία όπως συστήματα δοκιμών ή αποθετήρια κώδικα. Για ομάδες που αναπτύσσουν δημόσιο λογισμικό, μπορεί να χρησιμοποιηθεί σε ελεγχόμενο περιβάλλον για δημιουργία δοκιμών, ανασκόπηση αλλαγών, τεκμηρίωση και εντοπισμό πιθανών λαθών ασφαλείας.
Το StarCoder2 παραμένει σημαντικό γιατί προέρχεται από μια παράδοση πιο διαφανούς ανάπτυξης μοντέλων κώδικα. Είναι κατάλληλο για πιο ελαφριές εγκαταστάσεις, για συμπλήρωση κώδικα, εκπαιδευτική χρήση, εργαστήρια, πανεπιστήμια και ομάδες που θέλουν ένα μοντέλο με σαφέστερη σχέση με τα δεδομένα εκπαίδευσης και με πιο ελεγχόμενη αδειοδότηση. Δεν είναι πάντα το ισχυρότερο σε σύνθετο συλλογισμό, αλλά είναι χρήσιμο για δημόσιες και εκπαιδευτικές εγκαταστάσεις όπου η διαφάνεια της προέλευσης έχει μεγάλη αξία.
Για καθαρή αυτόματη συμπλήρωση, η καλύτερη πρακτική είναι να μη χρησιμοποιείται το μεγαλύτερο μοντέλο. Ένα μικρότερο μοντέλο 3B έως 7B, σε συμπιεσμένη μορφή, μπορεί να δώσει πολύ καλύτερη εμπειρία χρήστη από ένα 30B μοντέλο που καθυστερεί. Ο προγραμματιστής χρειάζεται απάντηση σε κλάσματα δευτερολέπτου όταν γράφει κώδικα. Για συζήτηση αρχιτεκτονικής, ανάλυση σφαλμάτων και παραγωγή τεκμηρίωσης μπορεί να περιμένει περισσότερο. Άρα η σωστή αρχιτεκτονική έχει δύο μοντέλα: μικρό για συμπλήρωση, μεγαλύτερο για συνομιλία και πράκτορες.
Τα καταλληλότερα μοντέλα για τον δημόσιο τομέα
Στον δημόσιο τομέα, το κριτήριο αλλάζει. Δεν αρκεί η απόδοση στον κώδικα. Προέχουν η διαφάνεια, η δυνατότητα ελέγχου, η γλωσσική κάλυψη, η συμβατότητα με ευρωπαϊκό δίκαιο, η προστασία προσωπικών δεδομένων και η τεκμηρίωση. Εδώ πρέπει να διακρίνουμε τα «ανοικτά βάρη» από τα «πλήρως ανοικτά» μοντέλα. Ένα μοντέλο ανοικτών βαρών επιτρέπει τοπική εκτέλεση και προσαρμογή. Ένα πλήρως ανοικτό μοντέλο δημοσιεύει περισσότερα στοιχεία για τα δεδομένα, τη μεθοδολογία, τον κώδικα και τα ενδιάμεσα στάδια εκπαίδευσης. Για δημόσιες εφαρμογές, η δεύτερη κατηγορία έχει πολύ μεγαλύτερη θεσμική αξία.
Το OLMo είναι από τις πιο σημαντικές επιλογές για δημόσια ελεγχόμενη ΤΝ, επειδή δίνει βάρος στην πλήρη ανοικτότητα. Είναι κατάλληλο για ερευνητικές και δημόσιες εφαρμογές όπου χρειάζεται δυνατότητα ελέγχου της διαδικασίας ανάπτυξης. Το Apertus είναι επίσης κρίσιμο ευρωπαϊκό παράδειγμα: πλήρως ανοικτό, πολυγλωσσικό και σχεδιασμένο με λογική δημόσιου συμφέροντος. Για την Ελλάδα, τέτοιες προσεγγίσεις είναι ιδιαίτερα χρήσιμες ως βάση για ελληνικά fine-tunes και για RAG συστήματα πάνω σε ΦΕΚ, Διαύγεια, ΜΙΤΟΣ, ΚΗΜΔΗΣ, αποφάσεις και διοικητικές διαδικασίες.
Για χαμηλού κόστους υπηρεσίες πρώτης γραμμής, όπως ταξινόμηση αιτημάτων, περίληψη μικρών κειμένων, δρομολόγηση ερωτήσεων και τοπικά kiosks, μικρά μοντέλα όπως το SmolLM2 είναι πιο λογικά από μεγάλα μοντέλα. Η δημόσια διοίκηση δεν χρειάζεται παντού ένα τεράστιο LLM. Χρειάζεται σωστή αντιστοίχιση μοντέλου και εργασίας. Πολλά προβλήματα λύνονται με αναζήτηση, κανόνες, ταξινόμηση, RAG και ανθρώπινη επικύρωση.
Υλικό: τέσσερις πρακτικές κατηγορίες
Η πρώτη κατηγορία είναι ο απλός φορητός ή επιτραπέζιος υπολογιστής με 16 έως 32 GB μνήμης. Εδώ τρέχουν μικρά μοντέλα 1.7B έως 7B σε συμπιεσμένη μορφή. Είναι κατάλληλα για εκπαίδευση, δοκιμές, βασική συμπλήρωση κώδικα και ελαφριά συνομιλία. Δεν είναι κατάλληλα για ανάλυση ολόκληρων αποθετηρίων ή βαριά δημόσια χρήση.
Η δεύτερη κατηγορία είναι ο σταθμός εργασίας με 64 έως 128 GB RAM και κάρτα γραφικών 16 έως 24 GB VRAM, όπως μια RTX 4090. Εδώ μπορεί να λειτουργήσει ικανοποιητικά ένα 15B έως 30B μοντέλο σε 4-bit ή 5-bit συμπίεση, με προσοχή στο μέγεθος του ιστορικού συνομιλίας. Αυτή είναι η πιο ρεαλιστική κατηγορία για ομάδες ανάπτυξης λογισμικού, πανεπιστημιακά εργαστήρια, δήμους και μικρούς φορείς.
Η τρίτη κατηγορία είναι ο επαγγελματικός σταθμός με 48 GB VRAM, όπως RTX 6000 Ada ή L40S, ή αντίστοιχη ενιαία μνήμη σε Apple Silicon. Εδώ αρχίζει η σοβαρή χρήση μεγαλύτερων μοντέλων, καλύτερου RAG, μεγαλύτερων συμφραζομένων και περισσότερων ταυτόχρονων χρηστών. Είναι κατάλληλη για περιφέρειες, μεγάλα πανεπιστημιακά εργαστήρια και υπουργικές ομάδες καινοτομίας.
Η τέταρτη κατηγορία είναι ο κοινός δημόσιος κόμβος ΤΝ: 2 έως 4 επαγγελματικές GPUs των 48 GB, 256 έως 512 GB RAM, γρήγορο NVMe αποθηκευτικό σύστημα, vLLM ή llama.cpp για εκτέλεση, LiteLLM ως πύλη συμβατή με OpenAI API, Keycloak για ταυτοποίηση, OpenSearch ή PostgreSQL/pgvector για RAG και πλήρη καταγραφή χρήσης. Αυτή είναι η σωστή αρχιτεκτονική για εθνική δημόσια υποδομή ΤΝ.
Η πρόταση πολιτικής
Για την Ελλάδα, η πιο ορθολογική επιλογή είναι τριπλή. Πρώτον, Qwen3-Coder ή Devstral για προγραμματισμό, εσωτερικά εργαλεία ανάπτυξης και ανασκόπηση κώδικα. Δεύτερον, OLMo και Apertus για δημόσιες εφαρμογές που απαιτούν διαφάνεια, πολυγλωσσία και θεσμικό έλεγχο. Τρίτον, μικρά μοντέλα όπως SmolLM2 και StarCoder2 για οικονομικές εγκαταστάσεις, εκπαίδευση και υπηρεσίες χαμηλού κινδύνου.
Όλα αυτά πρέπει να λειτουργούν με αυστηρούς κανόνες: RAG για κάθε διοικητική απάντηση, παραπομπή σε πηγή, ανθρώπινη τελική ευθύνη, μητρώο μοντέλων, Model Cards, Datasheets, καταγραφή κλήσεων, αξιολόγηση σφαλμάτων και δυνατότητα αντικατάστασης μοντέλου χωρίς αλλαγή εφαρμογής. Η ΤΝ στο δημόσιο δεν πρέπει να είναι μαύρο κουτί. Πρέπει να είναι δημόσια υποδομή γνώσης, ελέγχου και παραγωγικής αυτονομίας.
Πηγές άρθρου:
Qwen, Qwen3-Coder: Η οικογένεια Qwen3-Coder τεκμηριώνει ισχυρά ανοικτά μοντέλα για εργασίες κώδικα, πράκτορες λογισμικού, μεγάλα συμφραζόμενα και τοπική ανάπτυξη, με διαθέσιμες εκδόσεις όπως Qwen3-Coder-30B-A3B και Qwen3-Coder-Next: https://github.com/QwenLM/Qwen3-Coder και https://huggingface.co/Qwen/Qwen3-Coder-Next.
Mistral AI, Devstral: Το Devstral είναι μοντέλο για agentic software engineering, διατίθεται με Apache 2.0 και έχει σχεδιαστεί για πραγματικές εργασίες αποθετηρίων, debugging και δοκιμών λογισμικού: https://mistral.ai/news/devstral/.
BigCode, StarCoder2: Το StarCoder2 είναι οικογένεια ανοικτών μοντέλων κώδικα 3B, 7B και 15B, εκπαιδευμένων σε μεγάλο πολυγλωσσικό σώμα κώδικα, χρήσιμων για συμπλήρωση κώδικα, εκπαίδευση και διαφανέστερες εγκαταστάσεις: https://github.com/bigcode-project/starcoder2 και https://huggingface.co/docs/transformers/en/model_doc/starcoder2.
Allen Institute for AI, OLMo: Το OLMo είναι από τα σημαντικότερα παραδείγματα πλήρως ανοικτής προσέγγισης σε γλωσσικά μοντέλα, με έμφαση στη δημοσίευση βαρών, κώδικα, δεδομένων και τεκμηρίωσης, άρα κατάλληλο ως πρότυπο δημόσια ελέγξιμης ΤΝ: https://allenai.org/olmo.
Hugging Face, SmolLM2: Το SmolLM2 τεκμηριώνει την πρακτική αξία μικρών μοντέλων 135M, 360M και 1.7B για on-device και χαμηλού κόστους χρήσεις, όπως ταξινόμηση, δρομολόγηση και ελαφριά βοηθητικά εργαλεία: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B.
llama.cpp, Ollama, vLLM και LiteLLM: Η ανοικτή στοίβα τοπικής εκτέλεσης και εξυπηρέτησης μοντέλων επιτρέπει χρήση σε ευρύ φάσμα υλικού, OpenAI-compatible APIs, ενιαίες πύλες πρόσβασης και αντικατάσταση μοντέλων χωρίς κλείδωμα σε έναν προμηθευτή: https://github.com/ggml-org/llama.cpp, https://docs.ollama.com/api/openai-compatibility, https://docs.vllm.ai/en/latest/serving/online_serving/openai_compatible_server/, https://docs.litellm.ai/docs/.
NVIDIA και European Commission, υλικό και κανονιστικό πλαίσιο: Οι προδιαγραφές RTX 4090, RTX 6000 Ada και L40S τεκμηριώνουν τις βασικές κατηγορίες GPU 24GB και 48GB για τοπικά LLMs, ενώ το AI Act ορίζει τη λογική ρίσκου που πρέπει να λαμβάνεται υπόψη σε δημόσιες εφαρμογές ΤΝ: https://www.nvidia.com/en-eu/geforce/graphics-cards/40-series/rtx-4090/, https://www.nvidia.com/en-us/products/workstations/rtx-6000/, https://www.nvidia.com/en-eu/data-center/l40s/, https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai.
Apple, Mac Studio με M3 Ultra και M4 Max: Η Apple τεκμηριώνει διαμορφώσεις Mac Studio με M3 Ultra και M4 Max, ενοποιημένη μνήμη υψηλού εύρους ζώνης και τεχνικές προδιαγραφές σχετικές με τοπικά φορτία LLM, καθιστώντας το Mac Studio ισχυρή επιλογή σταθμού εργασίας για προγραμματιστές, ερευνητικές ομάδες και εργαστήρια δημόσιας ΤΝ που χρειάζονται μεγάλη κοινόχρηστη μνήμη χωρίς ξεχωριστή στοίβα διακριτής GPU: https://www.apple.com/mac-studio/specs/ και https://www.apple.com/mac-studio/.
Η συζήτηση για την τεχνητή νοημοσύνη συχνά ξεκινά από τα μοντέλα. Ποιο μοντέλο είναι πιο ισχυρό, πιο γρήγορο, πιο οικονομικό, πιο «έξυπνο». Όμως για τη δημόσια διοίκηση και για τις επιχειρήσεις το κρίσιμο ερώτημα είναι άλλο: με ποια δεδομένα σκέφτεται το μοντέλο, ποιος τα ελέγχει, πώς συνδέονται με τις πραγματικές διαδικασίες και με ποιον τρόπο ... Read more
Η τεχνητή νοημοσύνη μπαίνει ήδη στο κράτος, στην υγεία, στην εκπαίδευση, στην αυτοδιοίκηση και στις κρατικές υπηρεσίες ασφάλειας. Το πραγματικό ερώτημα δεν είναι αν θα χρησιμοποιηθεί, αλλά ποιος θα την ελέγχει. Θα χτίσουμε δημόσια ικανότητα, με ανοικτό λογισμικό, ελέγξιμες υποδομές και ελληνική τεχνογνωσία; Ή θα μεταφέρουμε ακόμη περισσότερες κρίσιμες λειτουργίες σε κλειστά υπολογιστικά συστήματα νέφους(cloud), με τιμολόγηση ανά λεκτική μονάδα (token), αδιαφανείς όρους χρήσης και εξάρτηση από λίγους διεθνείς παρόχους;
Για δήμους, περιφέρειες, πανεπιστήμια, νοσοκομεία, κρατικές υπηρεσίες ασφάλειας και υπουργεία, η καταλληλότερη αφετηρία είναι σαφής: χαμηλού κόστους τοπικά μοντέλα ΤΝ ανοικτού λογισμικού, εγκατεστημένα σε δημόσια ελεγχόμενη υποδομή, με Retrieval-Augmented Generation(RAG), δηλαδή παραγωγή απαντήσεων με ανάκτηση τεκμηρίων από αξιόπιστες πηγές, πλήρη καταγραφή χρήσης, ανθρώπινη ευθύνη και δυνατότητα ανεξάρτητου ελέγχου. Δεν πρόκειται για τεχνολογικό φετίχ. Πρόκειται για επιλογή δημοκρατικής κυριαρχίας, οικονομικής λογικής και διοικητικής ωριμότητας.
Γιατί το χαμηλό κόστος είναι στρατηγικό πλεονέκτημα
Η συζήτηση για την ΤΝ συχνά παρουσιάζεται σαν να απαιτεί τεράστια data centers και προϋπολογισμούς πολυεθνικών. Αυτό ισχύει για την εκπαίδευση πολύ μεγάλων θεμελιακών μοντέλων. Δεν ισχύει όμως για τη μεγάλη πλειονότητα των δημόσιων εφαρμογών: αναζήτηση σε έγγραφα, σύνοψη, ταξινόμηση αιτημάτων, προέλεγχος δικαιολογητικών, απομαγνητοφώνηση, ανωνυμοποίηση, εξαγωγή δομημένων δεδομένων, εσωτερική υποστήριξη υπαλλήλων, έλεγχος προμηθειών και αναζήτηση σε νόμους, ΦΕΚ, εγκυκλίους και διοικητικές διαδικασίες.
Ένας μικρός φορέας μπορεί να ξεκινήσει με μια οικονομική λύση, να δοκιμάσει πραγματικά σενάρια και μετά να κλιμακώσει μόνο ό,τι αποδίδει. Η σωστή αρχή είναι “δοκιμάζουμε πριν επενδύσουμε”. Ένα τοπικό εργαστήριο με Mac Mini, commodity GPUs, ανοικτά μοντέλα, Ollama, llama.cpp, vLLM, PostgreSQL, pgvector, Qdrant, Keycloak, Prometheus και Grafana μπορεί να αποδείξει μέσα σε λίγες εβδομάδες αν μια εφαρμογή έχει αξία. Έτσι η δημόσια διοίκηση αποφεύγει τις μεγάλες προμήθειες πριν μάθει τι χρειάζεται πραγματικά.
Δήμοι και περιφέρειες: ΤΝ κοντά στον πολίτη
Στους δήμους, τα τοπικά μοντέλα μπορούν να λειτουργήσουν ως βοηθοί πρώτης γραμμής. Ένα δημοτικό ΚΕΠ μπορεί να χρησιμοποιεί RAG πάνω στο mitos.gov.gr, στις αποφάσεις του δήμου και στα τοπικά έντυπα, ώστε να ενημερώνει τον πολίτη ποια δικαιολογητικά χρειάζεται, χωρίς να εκδίδει αυτόματα πράξη. Ένα τηλεφωνικό κέντρο ή ένα τοπικό σύστημα αιτημάτων μπορεί να ταξινομεί προβλήματα καθαριότητας, φωτισμού, κοινωνικής φροντίδας ή τεχνικών υπηρεσιών. Η τεχνική υπηρεσία μπορεί να συνοψίζει φακέλους έργων, να εντοπίζει κενά στις προδιαγραφές και να ελέγχει αν μια προμήθεια αποκλείει αδικαιολόγητα ανοικτά πρότυπα.
Στις περιφέρειες, η αξία είναι ακόμη μεγαλύτερη. Η πολιτική προστασία, η περιβαλλοντική παρακολούθηση, οι μεταφορές, η κοινωνική πολιτική και η αγροτική παραγωγή χρειάζονται συνδυασμό χωρικών δεδομένων, δορυφορικών εικόνων, ιστορικών συμβάντων και διοικητικών εγγράφων. Ένα περιφερειακό σύστημα μπορεί να υποστηρίζει χάρτες κλιματικού κινδύνου, πρόβλεψη πλημμυρικών κινδύνων, καταγραφή αναγκών ευάλωτων νοικοκυριών και ανάλυση επιπτώσεων έργων. Το κρίσιμο είναι ότι τα δεδομένα μένουν κοντά στον φορέα που τα παράγει και στον πληθυσμό που επηρεάζεται.
Πανεπιστήμια και νοσοκομεία: έρευνα, γνώση και προστασία δεδομένων
Τα πανεπιστήμια είναι φυσικοί κόμβοι για ανοικτή τοπική ΤΝ. Μπορούν να φιλοξενήσουν πειραματικά μοντέλα, να αναπτύξουν ελληνικά δεδομένα, να εκπαιδεύσουν φοιτητές και δημόσιους υπαλλήλους, να αξιολογήσουν ποιότητα απαντήσεων και να παράγουν ανοικτή τεκμηρίωση. Η συνεργασία με δημόσιους φορείς δεν πρέπει να περιοριστεί σε συμβουλευτικές μελέτες. Πρέπει να παράγει κοινόχρηστο κώδικα, ανοικτά σύνολα δεδομένων όπου επιτρέπεται και επαναχρησιμοποιήσιμες υποδομές.
Στα νοσοκομεία, η τοπικότητα είναι προϋπόθεση εμπιστοσύνης. Ένα νοσοκομειακό LLM δεν πρέπει να αποφασίζει διάγνωση ούτε θεραπεία. Μπορεί όμως να βοηθά στην αναζήτηση οδηγιών, στη σύνοψη διοικητικών εγγράφων, στην απομαγνητοφώνηση συσκέψεων, στην ανωνυμοποίηση κλινικών κειμένων, στη σύνταξη ενημερωτικών οδηγιών προς ασθενείς και στην υποστήριξη εσωτερικών διαδικασιών. Η διεθνής εμπειρία δείχνει ότι στην υγεία η ασφάλεια δεν χτίζεται με μεταφορά δεδομένων σε αδιαφανή συστήματα, αλλά με ασφαλή περιβάλλοντα ανάλυσης, ανοικτό κώδικα, ψευδωνυμοποίηση, αυστηρά δικαιώματα πρόσβασης και πλήρη ίχνη ελέγχου.
Υπουργεία και υπηρεσίες ασφάλειας: κυριαρχία, όχι αυτοματοποίηση εξουσίας
Στα υπουργεία, τα τοπικά LLMs μπορούν να στηρίξουν νομική αναζήτηση, ανάλυση διαβουλεύσεων, έλεγχο προμηθειών, υποστήριξη φορολογικής συμμόρφωσης, προετοιμασία ενημερωτικών σημειωμάτων, ταξινόμηση εγγράφων και αξιολόγηση προγραμμάτων. Το μοντέλο πρέπει να είναι σαφές: η ΤΝ εισηγείται, συνοψίζει, εντοπίζει, τεκμηριώνει. Δεν αποφασίζει.
Στις κρατικές υπηρεσίες ασφάλειας, η αξία βρίσκεται κυρίως στην κυβερνοασφάλεια, στην ανάλυση ανοιχτών πηγών, στην εσωτερική διαχείριση περιστατικών, στην αναζήτηση τεχνικών οδηγιών και στη σύνθεση μεγάλου όγκου πληροφοριών. Εδώ η τοπική υποδομή είναι ακόμη πιο αναγκαία, επειδή κανείς σοβαρός δημόσιος φορέας δεν πρέπει να στέλνει ευαίσθητα δεδομένα ασφάλειας σε εξωτερικά κλειστά API. Ταυτόχρονα χρειάζονται αυστηρά όρια: καμία γενικευμένη επιτήρηση, καμία αυτόματη στοχοποίηση πολιτών, καμία χρήση χωρίς νομική βάση, ανθρώπινη εποπτεία και λογοδοσία.
Η διεθνής εμπειρία δείχνει τον δρόμο
Η Γαλλία με το Albert, η Εσθονία με το Bürokratt, η Ελβετία με το Apertus, το Allen Institute με το OLMo, οι ευρωπαϊκές AI Factories και η εμπειρία του OpenSAFELY στην υγεία δείχνουν μια κοινή κατεύθυνση: η ΤΝ δημόσιου συμφέροντος χρειάζεται ανοικτότητα, κυριαρχία δεδομένων, διαφάνεια και θεσμική λογοδοσία. Για την Ελλάδα, το πλεονέκτημα είναι ότι δεν χρειάζεται να ξεκινήσει από το μηδέν. Διαθέτει πανεπιστήμια, ερευνητικά κέντρα, κοινότητες ανοικτού λογισμικού, το GlossAPI, δημόσια δεδομένα, αυτοδιοικητικές ανάγκες και ευρωπαϊκές χρηματοδοτήσεις.
Το ερώτημα είναι πολιτικό. Θα πληρώνουμε για πάντα ενοίκιο σε κλειστά συστήματα ή θα χτίσουμε δημόσια ψηφιακή περιουσία; Τα χαμηλού κόστους τοπικά μοντέλα ΤΝ ανοικτού λογισμικού είναι η πιο ρεαλιστική απάντηση: μικρή αρχική επένδυση, γρήγορη δοκιμή, επαναχρησιμοποίηση, τοπική τεχνογνωσία, προστασία δεδομένων και δυνατότητα δημοκρατικού ελέγχου.
Η ΤΝ δεν πρέπει να γίνει το νέο αυτονόητο της τάξης
Η συζήτηση για την Τεχνητή Νοημοσύνη στο σχολείο δεν μπορεί να ξεκινά από τη φράση «η ΤΝ είναι αναπόφευκτη». Το σχολείο δεν υπάρχει για να ακολουθεί κάθε τεχνολογική μόδα, ούτε για να μετατρέπει τα παιδιά σε πρώιμους χρήστες εργαλείων που δεν έχουν ακόμη αξιολογηθεί επαρκώς παιδαγωγικά, γνωστικά, κοινωνικά και δημοκρατικά. Υπάρχει για να βοηθά τα παιδιά να μάθουν να σκέφτονται, να διαβάζουν, να γράφουν, να συζητούν, να συνεργάζονται, να αμφιβάλλουν, να συγκεντρώνονται και να δημιουργούν.
Αυτό δε σημαίνει τεχνοφοβία. Σημαίνει παιδαγωγική σοβαρότητα. Η ΤΝ μπορεί να έχει θέση στην εκπαίδευση, αλλά όχι ως μόνιμος συνομιλητής του παιδιού, όχι ως μηχανή παραγωγής εργασιών, όχι ως αντικατάσταση της προσπάθειας και όχι ως εταιρική υποδομή που εγκαθίσταται αθόρυβα μέσα στην καθημερινότητα της τάξης. Το ερώτημα δεν είναι πώς θα βάλουμε περισσότερη ΤΝ στο σχολείο. Το ερώτημα είναι ποια μάθηση αξίζει να προστατεύσουμε από την αυτοματοποίηση.
Πρώτα τα θεμέλια, μετά τα εργαλεία
Στο δημοτικό και στο γυμνάσιο, η γενική αρχή πρέπει να είναι σαφής: όσο μικρότερη είναι η ηλικία, τόσο λιγότερη άμεση χρήση παραγωγικής ΤΝ. Τα παιδιά χρειάζονται πρώτα γνωστικά θεμέλια. Χρειάζονται ανάγνωση ολόκληρων κειμένων, γραφή με το χέρι, αριθμητική σκέψη, επίλυση προβλημάτων χωρίς έτοιμη απάντηση, πειράματα, κατασκευές, ζωγραφική, μουσική, θέατρο, φυσική άσκηση και ζωντανή συζήτηση.
Η μάθηση δεν είναι μόνο το τελικό προϊόν. Δεν είναι μόνο η ωραία παρουσίαση, η καλοδιατυπωμένη παράγραφος ή η γρήγορη σωστή απάντηση. Είναι η διαδρομή μέχρι εκεί. Το παιδί που παλεύει με μια παράγραφο, που σβήνει και ξαναγράφει, που προσπαθεί να εξηγήσει με δικά του λόγια ένα φαινόμενο, που κάνει λάθος σε ένα πρόβλημα και επιστρέφει σε αυτό, χτίζει δεξιότητες που δεν φαίνονται πάντα στο τελικό χαρτί. Χτίζει αντοχή, μνήμη εργασίας, αυτορρύθμιση, συγκέντρωση και εμπιστοσύνη στη δική του σκέψη.
Η ΤΝ, όταν μπαίνει πολύ νωρίς και πολύ συχνά, κινδυνεύει να κόψει αυτή τη διαδρομή. Προσφέρει περίληψη πριν γίνει ανάγνωση, σύνταξη πριν γίνει σκέψη, εικόνα πριν γίνει φαντασία, απάντηση πριν γίνει ερώτηση. Έτσι το σχολείο κινδυνεύει να μπερδέψει την εντύπωση με τη μάθηση.
Περιορισμός με κανόνες, όχι απλή απαγόρευση
Χρειάζεται εθνικό πλαίσιο χρήσης της ΤΝ στα σχολεία με απλούς, εφαρμόσιμους κανόνες.
Πρώτον, καμία άμεση χρήση chatbot από παιδιά μικρής ηλικίας. Στο δημοτικό η ΤΝ δεν πρέπει να αποτελεί εργαλείο ατομικής χρήσης μαθητή. Μπορεί, σε ειδικές περιπτώσεις, να αξιοποιείται μόνο από τον εκπαιδευτικό, μπροστά στην τάξη, με σκοπό την κριτική συζήτηση: να δείξει ένα λάθος, μια προκατάληψη, μια ψευδή απάντηση, έναν κακό συλλογισμό.
Δεύτερον, στο γυμνάσιο η χρήση πρέπει να είναι περιορισμένη, συλλογική και εποπτευόμενη. Όχι «γράψε μου την εργασία», αλλά «σύγκρινε δύο απαντήσεις», «βρες τι λείπει», «έλεγξε αν υπάρχουν πηγές», «εντόπισε την προκατάληψη». Η ΤΝ να μπαίνει ως αντικείμενο κριτικής παιδείας, όχι ως δεκανίκι.
Τρίτον, στο λύκειο μπορεί να υπάρξει πιο συστηματική εκπαίδευση στην ΤΝ, αλλά με αυστηρή διάκριση ανάμεσα στη βοήθεια και στην υποκατάσταση. Οι μαθητές πρέπει να μαθαίνουν τι είναι μοντέλο, τι είναι δεδομένα, τι είναι προκατάληψη, τι είναι πνευματική ιδιοκτησία, τι σημαίνει προσωπικό δεδομένο, τι σημαίνει ανοιχτό και κλειστό σύστημα, γιατί ένα μοντέλο μπορεί να ακούγεται βέβαιο και να κάνει λάθος.
Τέταρτον, καμία αξιολόγηση μαθητή δεν πρέπει να βασίζεται σε προϊόν που μπορεί να έχει παραχθεί αθέατα από ΤΝ. Περισσότερη προφορική εξέταση, περισσότερη εργασία μέσα στην τάξη, περισσότερα τετράδια, περισσότερα στάδια παραγωγής, περισσότερη τεκμηρίωση της διαδικασίας. Ο μαθητής να δείχνει πώς σκέφτηκε, όχι μόνο τι παρέδωσε.
Πού πρέπει να πηγαίνει ο χρόνος μαθητών και εκπαιδευτικών
Ο χρόνος των μαθητών πρέπει να αφιερωθεί στην προσοχή. Στη βαθιά ανάγνωση, όχι στο γρήγορο πέρασμα από οθόνη σε οθόνη. Στη γραφή, όχι στην αυτόματη διατύπωση. Στη συζήτηση με συμμαθητές, όχι στην ψευδοοικειότητα ενός chatbot. Στη μαθηματική επιμονή, όχι στην άμεση λύση. Στα εργαστήρια φυσικών επιστημών, στα έργα τεχνολογίας, στη ρομποτική με ανοιχτό υλισμικό, στον προγραμματισμό με ανοιχτά εργαλεία, στην καλλιτεχνική δημιουργία, στην τοπική ιστορία, στο περιβάλλον, στην κοινότητα.
Ο χρόνος των εκπαιδευτικών πρέπει να αφιερωθεί στην παιδαγωγική σχέση. Στην παρατήρηση των παιδιών, στη στήριξη όσων δυσκολεύονται, στον σχεδιασμό καλών ερωτήσεων, στη συνεργασία με άλλους εκπαιδευτικούς, στην επαφή με τους γονείς, στη δημιουργία ζωντανών μαθησιακών εμπειριών. Η ΤΝ δεν πρέπει να τους φορτωθεί ως ακόμη ένα εργαλείο που πρέπει να μάθουν βιαστικά, να ελέγξουν μόνοι τους και να αστυνομεύσουν χωρίς θεσμική στήριξη.
Αν η ΤΝ χρησιμοποιηθεί από εκπαιδευτικούς, πρέπει να χρησιμοποιηθεί για χαμηλού ρίσκου διοικητική υποστήριξη, για προσαρμογή υλικού, για δημιουργία εναλλακτικών ασκήσεων και για προσβασιμότητα, πάντα με έλεγχο από τον ίδιο τον εκπαιδευτικό. Δεν πρέπει να αξιολογεί μαθητές, να συνομιλεί ανεξέλεγκτα με παιδιά, να συγκεντρώνει ευαίσθητα δεδομένα ή να αντικαθιστά την κρίση του δασκάλου.
Δημόσια, ανοιχτή και ελεγχόμενη τεχνολογία
Η εκπαίδευση δεν πρέπει να γίνει αιχμάλωτη κλειστών πλατφορμών. Κάθε ψηφιακό εργαλείο που χρησιμοποιείται στο δημόσιο σχολείο πρέπει να περνά από παιδαγωγικό, νομικό και τεχνικό έλεγχο. Να υπάρχει διαφάνεια για τα δεδομένα, τις συμβάσεις, τα μοντέλα, τους προμηθευτές και τους κινδύνους. Όπου είναι δυνατόν, να προτιμώνται ανοιχτά πρότυπα, ανοιχτό λογισμικό, τοπική φιλοξενία και λύσεις που μπορούν να ελεγχθούν από την εκπαιδευτική κοινότητα.
Το σχολείο του 21ου αιώνα δεν θα σωθεί αν γεμίσει περισσότερες οθόνες. Θα γίνει καλύτερο αν ξανακερδίσει χρόνο για συγκέντρωση, ανθρώπινη επαφή, δημιουργία και δημοκρατική μάθηση. Η ΤΝ μπορεί να είναι εργαλείο. Δεν πρέπει να γίνει το περιβάλλον μέσα στο οποίο μεγαλώνουν τα παιδιά.
Πηγές άρθρου:
The New Yorker, “What Will It Take to Get A.I. Out of Schools?”: Το άρθρο καταγράφει την ταχεία είσοδο εργαλείων παραγωγικής ΤΝ στην πρωτοβάθμια και δευτεροβάθμια εκπαίδευση, τους κινδύνους για γνωστική ανάπτυξη, ιδιωτικότητα και παιδαγωγική αυτονομία, καθώς και τις αντιδράσεις γονέων και εκπαιδευτικών: https://www.newyorker.com/culture/progress-report/what-will-it-take-to-get-ai-out-of-schools,
UNESCO, “Guidance for Generative AI in Education and Research”: Η καθοδήγηση της UNESCO προτείνει ανθρωποκεντρική, ηλικιακά κατάλληλη και ρυθμισμένη χρήση της παραγωγικής ΤΝ στην εκπαίδευση, με έμφαση στην προστασία προσωπικών δεδομένων και στην παιδαγωγική εγκυρότητα: https://www.unesco.org/en/articles/guidance-generative-ai-education-and-research,
UNESCO, “AI Competency Framework for Teachers”: Το πλαίσιο ορίζει τις βασικές γνώσεις, δεξιότητες και αξίες που χρειάζονται οι εκπαιδευτικοί στην εποχή της ΤΝ, με έμφαση στην ανθρώπινη αυτενέργεια, την ηθική χρήση, την παιδαγωγική κρίση και τη βιωσιμότητα: https://www.unesco.org/en/articles/ai-competency-framework-teachers,
Nataliya Kosmyna et al., “Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task”: Η μελέτη του MIT Media Lab εξετάζει τη χρήση LLM στη συγγραφή δοκιμίων και καταγράφει χαμηλότερη γνωστική εμπλοκή και ασθενέστερη αίσθηση ιδιοκτησίας του γραπτού στους χρήστες ΤΝ: https://arxiv.org/abs/2506.08872,
Junyi Chu et al., “AI Assistance Reduces Persistence and Hurts Independent Problem-Solving”: Η μελέτη από ερευνητές των Carnegie Mellon, Oxford, MIT και UCLA δείχνει ότι η βραχεία χρήση ΤΝ μπορεί να βελτιώνει την άμεση επίδοση, αλλά να μειώνει την επιμονή και την ανεξάρτητη επίλυση προβλημάτων όταν η βοήθεια αφαιρεθεί: https://arxiv.org/html/2604.04721v2,
Frontiers in Psychology, “Handwriting but not Typewriting Leads to Widespread Brain Connectivity”: Η μελέτη τεκμηριώνει ότι η γραφή με το χέρι συνδέεται με πιο εκτεταμένα μοτίβα εγκεφαλικής συνδεσιμότητας από την πληκτρολόγηση, στοιχείο σημαντικό για τη μνήμη και την κωδικοποίηση νέας γνώσης: https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2023.1219945/full.
Η συζήτηση για την τεχνητή νοημοσύνη συχνά ξεκινά από τα μοντέλα. Ποιο μοντέλο είναι πιο ισχυρό, πιο γρήγορο, πιο οικονομικό, πιο «έξυπνο». Όμως για τη δημόσια διοίκηση και για τις επιχειρήσεις το κρίσιμο ερώτημα είναι άλλο: με ποια δεδομένα σκέφτεται το μοντέλο, ποιος τα ελέγχει, πώς συνδέονται με τις πραγματικές διαδικασίες και με ποιον τρόπο τεκμηριώνεται κάθε απάντηση. Ένα τοπικό σύστημα τεχνητής νοημοσύνης ανοιχτού λογισμικού μπορεί να είναι φθηνό, ασφαλές και κυρίαρχο. Δεν θα είναι όμως χρήσιμο αν λειτουργεί πάνω σε κατακερματισμένα αρχεία, παλιά PDF, ασύνδετες βάσεις δεδομένων και διοικητικές διαδικασίες που δεν έχουν μετατραπεί σε μηχαναγνώσιμη γνώση.
Γι’ αυτό η κρίσιμη υποδομή δεν είναι μόνο το τοπικό μοντέλο. Είναι το πλέγμα δεδομένων. Με τον όρο αυτό δεν εννοούμε απλώς μια αποθήκη δεδομένων ούτε μια νέα κεντρική βάση όπου όλα αντιγράφονται. Εννοούμε ένα στρώμα διασύνδεσης, τεκμηρίωσης, σημασιολογίας και διακυβέρνησης που επιτρέπει σε διαφορετικά πληροφοριακά συστήματα να παραμένουν εκεί όπου βρίσκονται, αλλά να γίνονται κατανοητά, ελέγξιμα και αξιοποιήσιμα από εφαρμογές ΤΝ. Το πλέγμα δεδομένων συνδέει μητρώα, έγγραφα, διαδικασίες, πολιτικές, μεταδεδομένα, APIs και ιστορικά στοιχεία. Δεν μεταφέρει μόνο τιμές και πεδία. Μεταφέρει νόημα.
Στη δημόσια διοίκηση αυτό σημαίνει ότι ένα σύστημα ΤΝ δεν πρέπει να απαντά μόνο επειδή έχει «διαβάσει» γενικά ελληνικά κείμενα. Πρέπει να μπορεί να ανατρέχει στο ΦΕΚ, στη σχετική εγκύκλιο, στο mitos.gov.gr, στο gov.gr, στη Διαύγεια, στο ΚΗΜΔΗΣ, στο ΕΣΗΔΗΣ, στα μητρώα πολιτών και επιχειρήσεων, στα συστήματα της ΑΑΔΕ, στο myDATA, στο ΕΡΓΑΝΗ, στον e-ΕΦΚΑ, στην ΗΔΙΚΑ, στην ηλεκτρονική συνταγογράφηση, στα συστήματα των ΚΕΠ, στο Κτηματολόγιο, στην e-Άδειες, στα δεδομένα δήμων και περιφερειών, στα γεωχωρικά δεδομένα, στα στοιχεία πολιτικής προστασίας και στα ανοικτά δεδομένα της ΕΛΣΤΑΤ. Όχι για να εκδίδει αυτόματα αποφάσεις, αλλά για να βοηθά τους υπαλλήλους και τους πολίτες να βρίσκουν τη σωστή διαδικασία, να εντοπίζουν λάθη, να συμπληρώνουν αιτήσεις, να ελέγχουν προθεσμίες και να τεκμηριώνουν επιλογές.
Ένα τέτοιο πλέγμα θα μπορούσε να ξεκινήσει από τέσσερις κατηγορίες δεδομένων.Πρώτο, το διοικητικό πλέγμα, με ΦΕΚ, εγκυκλίους, αποφάσεις, διαδικασίες, αρμοδιότητες, μητρώα και πρότυπα εγγράφων. Δεύτερο, το οικονομικό πλέγμα, με προϋπολογισμούς, προμήθειες, συμβάσεις, πληρωμές, έργα, ενισχύσεις και δείκτες αποδοτικότητας. Τρίτο, το κοινωνικό πλέγμα, με ασφαλιστικές, υγειονομικές, εκπαιδευτικές και προνοιακές υπηρεσίες, πάντα με αυστηρή προστασία προσωπικών δεδομένων. Τέταρτο, το χωρικό και περιβαλλοντικό πλέγμα, με γεωχωρικά δεδομένα, χρήσεις γης, δασικούς χάρτες, δεδομένα πλημμύρας, πυρκαγιάς, ατμοσφαιρικής ρύπανσης, μεταφορών και υποδομών.
Για τις επιχειρήσεις, η λογική είναι αντίστοιχη. Ένα τοπικό ανοιχτό LLM δεν αποκτά αξία επειδή απαντά γενικά σε ερωτήσεις. Αποκτά αξία όταν συνδέεται με ERP, CRM, συστήματα αποθήκης, εφοδιαστικής αλυσίδας, τιμολόγησης, λογιστηρίου, HR, helpdesk, POS, e-commerce, παραγωγής, ποιότητας, συντήρησης, συμβάσεων και εσωτερικών πολιτικών. Έτσι μπορεί να υποστηρίζει προβλέψεις ζήτησης, έλεγχο αποθεμάτων, ανάλυση πελατειακών αιτημάτων, εντοπισμό αποκλίσεων σε παραγγελίες, αξιολόγηση κινδύνων προμηθευτών και σύνταξη εσωτερικών αναφορών. Η επιχείρηση δεν χρειάζεται ένα «έξυπνο chatbot» αποκομμένο από τη λειτουργία της. Χρειάζεται ένα ασφαλές σύστημα που καταλαβαίνει το δικό της πλαίσιο.
Το κρίσιμο τεχνικό σχήμα είναι η ανάκτηση τεκμηρίων πριν από την απάντηση. Τα συστήματα Retrieval-Augmented Generation(RAG) μειώνουν τις παραισθήσεις επειδή το μοντέλο δεν απαντά μόνο από τη μνήμη του. Αναζητά πρώτα στα έγκυρα τεκμήρια του οργανισμού, ανακτά το σχετικό απόσπασμα και στη συνέχεια συνθέτει απάντηση με βάση αυτό. Για τη δημόσια διοίκηση αυτό πρέπει να είναι αδιαπραγμάτευτος κανόνας: καμία απάντηση για δικαίωμα, υποχρέωση, φόρο, άδεια, επίδομα, σύμβαση ή προθεσμία χωρίς αναφορά σε θεσμική πηγή. Για τις επιχειρήσεις σημαίνει ότι κάθε κρίσιμη σύσταση πρέπει να πατά σε πραγματικά δεδομένα, πολιτικές, συμβάσεις και εγκεκριμένα έγγραφα.
Εδώ βρίσκεται η ιδιαίτερη σημασία του GlossAPI. Η ελληνική γλώσσα δεν μπορεί να αντιμετωπίζεται ως δευτερεύον παράρτημα των αγγλόφωνων μοντέλων. Χρειάζεται τεκμηριωμένα, καθαρά, ανοιχτά και επαναχρησιμοποιήσιμα ελληνικά δεδομένα. Το GlossAPI λειτουργεί ως αγωγός μετατροπής ελληνικών κειμένων σε AI-ready σύνολα δεδομένων, με καθαρισμό, τυποποίηση, τεκμηρίωση και ανοιχτές άδειες. Αυτό το καθιστά κρίσιμο κρίκο ανάμεσα στα τοπικά ανοιχτά μοντέλα και στην πραγματική ελληνική δημόσια γνώση. Μπορεί να τροφοδοτήσει RAG συστήματα για νομοθεσία, δημόσιες διαβουλεύσεις, εκπαιδευτικό περιεχόμενο, πολιτιστικά τεκμήρια, διοικητικά έγγραφα και γλωσσικά σώματα.
Η πολιτική σημασία είναι σαφής. Αν η ΤΝ στη δημόσια διοίκηση χτιστεί πάνω σε κλειστά υπολογιστικά συστήματα(cloud) και ιδιωτικά δεδομένα, το κράτος θα γίνει ακόμη πιο εξαρτημένο. Αν χτιστεί πάνω σε τοπικά ανοιχτά μοντέλα, δημόσια ελεγχόμενες υποδομές, ανοιχτά APIs, τεκμηριωμένα δεδομένα και πλέγματα γνώσης, μπορεί να γίνει εργαλείο δημοκρατικού εκσυγχρονισμού. Το ζητούμενο δεν είναι η αυτοματοποίηση της εξουσίας. Είναι η ενίσχυση της ανθρώπινης κρίσης, της διαφάνειας και της λογοδοσίας.
Το πλέγμα δεδομένων είναι η υποδομή που επιτρέπει στην ΤΝ να πάψει να είναι εντυπωσιακή επίδειξη και να γίνει αξιόπιστη δημόσια υπηρεσία. Χωρίς αυτό, η ΤΝ θα παράγει γρήγορες απαντήσεις με αβέβαιη αξία. Με αυτό, μπορεί να παράγει τεκμηριωμένη γνώση, καλύτερες αποφάσεις και πραγματική δημόσια αξία.
GlossAPI, “Greek Datasets”: Το GlossAPI παρουσιάζεται ως αγωγός για την επεξεργασία ελληνικών κειμένων και τη μετατροπή τους σε AI-ready σύνολα δεδομένων για μεγάλα γλωσσικά μοντέλα, με δημόσια διαθέσιμα ελληνικά corpora: https://glossapi.gr/,
GlossAPI, “About”: Η σελίδα τεκμηριώνει ότι το GlossAPI είναι ανοιχτού κώδικα βιβλιοθήκη Python και τεχνική υποδομή για τη δημιουργία, επεξεργασία και δημοσίευση ελληνικών AI-ready δεδομένων με ανοιχτές άδειες: https://glossapi.gr/aboutus.html,
European Commission, “Common European Data Spaces”: Η Ευρωπαϊκή Επιτροπή περιγράφει τους ευρωπαϊκούς χώρους δεδομένων ως ασφαλή και αξιόπιστο πλαίσιο ανταλλαγής δεδομένων για επιχειρήσεις, δημόσιες διοικήσεις και πολίτες: https://digital-strategy.ec.europa.eu/en/policies/data-spaces,
European Commission, “European Data Governance Act”: Το Data Governance Act ενισχύει την εμπιστοσύνη στο διαμοιρασμό δεδομένων, τη διαθεσιμότητα δεδομένων και την άρση τεχνικών εμποδίων στην επαναχρησιμοποίηση: https://digital-strategy.ec.europa.eu/en/policies/data-governance-act,
Allen Institute for AI, “OLMo”: Το OLMo τεκμηριώνει την κατεύθυνση των πλήρως ανοικτών γλωσσικών μοντέλων, με ανοικτή ροή μοντέλου και δεδομένων εκπαίδευσης για ερευνητικό και δημόσια ελέγξιμο οικοσύστημα ΤΝ: https://allenai.org/olmo,
Η εξάρτηση των ευρωπαϊκών κρατών, των ακαδημαϊκών ιδρυμάτων και των επιχειρήσεων από πλατφόρμες λογισμικού ως υπηρεσία (SaaS) αμερικανικών κολοσσών αποτελεί εδώ και χρόνια ένα "αγκάθι" στην ψηφιακή πολιτική. Στις 9 Ιουνίου 2026, αυτό το τοπίο αλλάζει ριζικά με την επίσημη κυκλοφορία του Euro-Office 1.0.
Πρόκειται για μια ολοκληρωμένη, cloud-first σουίτα γραφείου, ανοιχτού κώδικα (open-source), η οποία έρχεται να αμφισβητήσει την κυριαρχία του Microsoft 365 και του Google Workspace, προσφέροντας απόλυτο έλεγχο, ασφάλεια και ψηφιακή κυριαρχία.
Τι είναι το Euro-Office;
Το Euro-Office 1.0 δεν είναι απλώς ένα ακόμα πρόγραμμα επεξεργασίας κειμένου. Είναι μια cloud-based πλατφόρμα συνεργασίας που ενσωματώνει επεξεργαστή κειμένου, λογιστικά φύλλα, παρουσιάσεις και εργαλεία διαχείρισης PDF απευθείας στον browser.
Βασισμένο στον ανοιχτό κώδικα του ONLYOFFICE (της Ascensio System SIA), το project καθαρίστηκε και βελτιστοποιήθηκε σε επίπεδο ασφαλείας για να αποτελέσει μια εντελώς ανεξάρτητη ευρωπαϊκή λύση. Παρέχεται εντελώς δωρεάν μέσω των δημόσιων αποθετηρίων του GitHub υπό άδεια ανοιχτού κώδικα.
Κορυφαία συμβατότητα
Ένα από τα μεγαλύτερα εμπόδια στη μετάβαση σε λογισμικό ανοιχτού κώδικα είναι η συμβατότητα. Το Euro-Office λύνει αυτό το πρόβλημα προσφέροντας:
Άριστη υποστήριξη Microsoft Office: Δημιουργία, άνοιγμα και επεξεργασία αρχείων DOCX, XLSX και PPTX με υψηλό επίπεδο αναπαραγωγής.
Προσήλωση στα Ανοιχτά Πρότυπα: Εκτενής υποστήριξη μορφών OpenDocument (ODF) όπως ODT, ODS και ODP, εξασφαλίζοντας ότι τα δεδομένα σας δεν εγκλωβίζονται σε κλειστά οικοσυστήματα.
Ψηφιακή Κυριαρχία: Γιατί η Ευρώπη γυρίζει την πλάτη στο Αμερικανικό Cloud
Ο κύριος μοχλός πίσω από την ανάπτυξη του Euro-Office είναι η ανάγκη για Ψηφιακή Κυριαρχία (Digital Sovereignty). Η φιλοξενία ευαίσθητων κυβερνητικών, ακαδημαϊκών ή εταιρικών δεδομένων σε servers που υπόκεινται στον αμερικανικό νόμο (US Cloud Act) εγκυμονεί σοβαρούς κινδύνους ιδιωτικότητας.
Το Euro-Office αλλάζει τους κανόνες του παιχνιδιού:
Απόλυτη συμμόρφωση με τον GDPR: Η πλατφόρμα είναι σχεδιασμένη για άμεση ανάπτυξη μέσω self-hosting.
Data Localization: Οι ελληνικοί φορείς, οι δήμοι και οι επιχειρήσεις μπορούν πλέον να φιλοξενούν την πλατφόρμα στο δικό τους hardware, εξασφαλίζοντας μηδενικό κίνδυνο παρακολούθησης από τρίτες χώρες.
Μείωση Κόστους: Απαλλαγή από το μοντέλο των ακριβών, επαναλαμβανόμενων μηνιαίων συνδρομών ανά χρήστη, μειώνοντας δραστικά τα πάγια έξοδα IT.
Βασικά πλεονεκτήματα & Χαρακτηριστικά συνεργασίας
Σε αντίθεση με τις παραδοσιακές desktop λύσεις, το Euro-Office είναι εξολοκλήρου δομημένο για τον web browser.
Συνεργασία σε πραγματικό χρόνο: Πολλοί χρήστες μπορούν να επεξεργάζονται το ίδιο έγγραφο ή κελί ταυτόχρονα, αξιοποιώντας εργαλεία όπως σχόλια, παρακολούθηση αλλαγών και ιστορικό εκδόσεων.
Οικείο γραφικό περιβάλλον (Ribbon UI): Το περιβάλλον χρήσης είναι σκόπιμα σχεδιασμένο να θυμίζει τα σύγχρονα Microsoft Office. Αυτό εκμηδενίζει την καμπύλη εκμάθησης, επιτρέποντας στο προσωπικό οργανισμών να μεταβεί στη νέα πλατφόρμα χωρίς δαπανηρές επανεκπαιδεύσεις.
Ενσωματωμένη επικοινωνία: Δυνατότητα συνομιλίας με τους συνεργάτες σας απευθείας μέσα από το έγγραφο που επεξεργάζεστε.
Η ισχύς της Ευρωπαϊκής συμμαχίας
Το project δεν είναι μια απομονωμένη προσπάθεια. Υποστηρίζεται ενεργά από μια συμμαχία κορυφαίων παρόχων open-source υποδομών και cloud στην Ευρώπη.
Εταιρείες κολοσσοί στο οικοσύστημα του ανοιχτού κώδικα, όπως η Nextcloud, η Ionos, η XWiki, η OpenProject, η Open-Xchange (OX) και το Office.eu, έχουν ενώσει τις δυνάμεις τους. Όπως επισημαίνει ο Frank Karlitschek, CEO της Nextcloud: "Η Ευρώπη είχε τα τεχνικά δομικά στοιχεία εδώ και χρόνια... Με το Euro-Office, δεν ξεκινάμε από το μηδέν, αναλαμβάνουμε την ευθύνη για ένα ζωτικό κομμάτι της ψηφιακής υποδομής".
Έτοιμο για Self-Hosting
Ένα από τα ισχυρότερα "χαρτιά" του Euro-Office είναι ότι δεν απαιτεί από τους διαχειριστές συστημάτων να στήσουν τα πάντα από το μηδέν. Σχεδιάστηκε ως ένα ενσωματωμένο στοιχείο μέσα σε υπάρχοντα οικοσυστήματα.
Κατά την κυκλοφορία του, θα είναι άμεσα διαθέσιμο ως ενσωμάτωση στην τελευταία έκδοση Nextcloud Hub 26 Spring, λειτουργώντας ως ο in-browser editor για τα διαμοιραζόμενα έγγραφά σας. Οι πελάτες του Ionos Managed Nextcloud θα έχουν επίσης άμεση πρόσβαση, ενώ προγραμματίζεται ενσωμάτωση και στα συστήματα της XWiki αργότερα μέσα στη χρονιά.
Πώς να αποκτήσετε το Euro-Office 1.0
Η αντίστροφη μέτρηση έχει ξεκινήσει. Στις 9 Ιουνίου 2026, η πρώτη σταθερή έκδοση θα είναι διαθέσιμη στο ευρύ κοινό.
Είτε είστε λάτρης του Linux και του self-hosting που θέλει να τρέξει τη σουίτα στον δικό του server, είτε εκπροσωπείτε έναν οργανισμό που αναζητά διέξοδο από το vendor lock-in των αμερικανικών SaaS, το Euro-Office προσφέρει τον κώδικα, τα εργαλεία και την ευρωπαϊκή εγγύηση που χρειάζεστε.
Ο κώδικας θα είναι διαθέσιμος στο GitHub, έτοιμος για λήψη και ανάπτυξη. Η ψηφιακή ανεξαρτησία είναι πλέον εφικτή.
Η τεχνητή νοημοσύνη μπαίνει ήδη στο κράτος, στην υγεία, στην εκπαίδευση, στην αυτοδιοίκηση και στις κρατικές υπηρεσίες ασφάλειας. Το πραγματικό ερώτημα δεν είναι αν θα χρησιμοποιηθεί, αλλά ποιος θα την ελέγχει. Θα χτίσουμε δημόσια ικανότητα, με ανοικτό λογισμικό, ελέγξιμες υποδομές και ελληνική τεχνογνωσία; Ή θα μεταφέρουμε ακόμη περισσότερες κρίσιμες λειτουργίες σε κλειστά υπολογιστικά συστήματα νέφους(cloud), με τιμολόγηση ανά λεκτική μονάδα (token), αδιαφανείς όρους χρήσης και εξάρτηση από λίγους διεθνείς παρόχους;
Για δήμους, περιφέρειες, πανεπιστήμια, νοσοκομεία, κρατικές υπηρεσίες ασφάλειας και υπουργεία, η καταλληλότερη αφετηρία είναι σαφής: χαμηλού κόστους τοπικά μοντέλα ΤΝ ανοικτού λογισμικού, εγκατεστημένα σε δημόσια ελεγχόμενη υποδομή, με Retrieval-Augmented Generation(RAG), δηλαδή παραγωγή απαντήσεων με ανάκτηση τεκμηρίων από αξιόπιστες πηγές, πλήρη καταγραφή χρήσης, ανθρώπινη ευθύνη και δυνατότητα ανεξάρτητου ελέγχου. Δεν πρόκειται για τεχνολογικό φετίχ. Πρόκειται για επιλογή δημοκρατικής κυριαρχίας, οικονομικής λογικής και διοικητικής ωριμότητας.
Γιατί το χαμηλό κόστος είναι στρατηγικό πλεονέκτημα
Η συζήτηση για την ΤΝ συχνά παρουσιάζεται σαν να απαιτεί τεράστια data centers και προϋπολογισμούς πολυεθνικών. Αυτό ισχύει για την εκπαίδευση πολύ μεγάλων θεμελιακών μοντέλων. Δεν ισχύει όμως για τη μεγάλη πλειονότητα των δημόσιων εφαρμογών: αναζήτηση σε έγγραφα, σύνοψη, ταξινόμηση αιτημάτων, προέλεγχος δικαιολογητικών, απομαγνητοφώνηση, ανωνυμοποίηση, εξαγωγή δομημένων δεδομένων, εσωτερική υποστήριξη υπαλλήλων, έλεγχος προμηθειών και αναζήτηση σε νόμους, ΦΕΚ, εγκυκλίους και διοικητικές διαδικασίες.
Ένας μικρός φορέας μπορεί να ξεκινήσει με μια οικονομική λύση, να δοκιμάσει πραγματικά σενάρια και μετά να κλιμακώσει μόνο ό,τι αποδίδει. Η σωστή αρχή είναι “δοκιμάζουμε πριν επενδύσουμε”. Ένα τοπικό εργαστήριο με Mac Mini, commodity GPUs, ανοικτά μοντέλα, Ollama, llama.cpp, vLLM, PostgreSQL, pgvector, Qdrant, Keycloak, Prometheus και Grafana μπορεί να αποδείξει μέσα σε λίγες εβδομάδες αν μια εφαρμογή έχει αξία. Έτσι η δημόσια διοίκηση αποφεύγει τις μεγάλες προμήθειες πριν μάθει τι χρειάζεται πραγματικά.
Δήμοι και περιφέρειες: ΤΝ κοντά στον πολίτη
Στους δήμους, τα τοπικά μοντέλα μπορούν να λειτουργήσουν ως βοηθοί πρώτης γραμμής. Ένα δημοτικό ΚΕΠ μπορεί να χρησιμοποιεί RAG πάνω στο mitos.gov.gr, στις αποφάσεις του δήμου και στα τοπικά έντυπα, ώστε να ενημερώνει τον πολίτη ποια δικαιολογητικά χρειάζεται, χωρίς να εκδίδει αυτόματα πράξη. Ένα τηλεφωνικό κέντρο ή ένα τοπικό σύστημα αιτημάτων μπορεί να ταξινομεί προβλήματα καθαριότητας, φωτισμού, κοινωνικής φροντίδας ή τεχνικών υπηρεσιών. Η τεχνική υπηρεσία μπορεί να συνοψίζει φακέλους έργων, να εντοπίζει κενά στις προδιαγραφές και να ελέγχει αν μια προμήθεια αποκλείει αδικαιολόγητα ανοικτά πρότυπα.
Στις περιφέρειες, η αξία είναι ακόμη μεγαλύτερη. Η πολιτική προστασία, η περιβαλλοντική παρακολούθηση, οι μεταφορές, η κοινωνική πολιτική και η αγροτική παραγωγή χρειάζονται συνδυασμό χωρικών δεδομένων, δορυφορικών εικόνων, ιστορικών συμβάντων και διοικητικών εγγράφων. Ένα περιφερειακό σύστημα μπορεί να υποστηρίζει χάρτες κλιματικού κινδύνου, πρόβλεψη πλημμυρικών κινδύνων, καταγραφή αναγκών ευάλωτων νοικοκυριών και ανάλυση επιπτώσεων έργων. Το κρίσιμο είναι ότι τα δεδομένα μένουν κοντά στον φορέα που τα παράγει και στον πληθυσμό που επηρεάζεται.
Πανεπιστήμια και νοσοκομεία: έρευνα, γνώση και προστασία δεδομένων
Τα πανεπιστήμια είναι φυσικοί κόμβοι για ανοικτή τοπική ΤΝ. Μπορούν να φιλοξενήσουν πειραματικά μοντέλα, να αναπτύξουν ελληνικά δεδομένα, να εκπαιδεύσουν φοιτητές και δημόσιους υπαλλήλους, να αξιολογήσουν ποιότητα απαντήσεων και να παράγουν ανοικτή τεκμηρίωση. Η συνεργασία με δημόσιους φορείς δεν πρέπει να περιοριστεί σε συμβουλευτικές μελέτες. Πρέπει να παράγει κοινόχρηστο κώδικα, ανοικτά σύνολα δεδομένων όπου επιτρέπεται και επαναχρησιμοποιήσιμες υποδομές.
Στα νοσοκομεία, η τοπικότητα είναι προϋπόθεση εμπιστοσύνης. Ένα νοσοκομειακό LLM δεν πρέπει να αποφασίζει διάγνωση ούτε θεραπεία. Μπορεί όμως να βοηθά στην αναζήτηση οδηγιών, στη σύνοψη διοικητικών εγγράφων, στην απομαγνητοφώνηση συσκέψεων, στην ανωνυμοποίηση κλινικών κειμένων, στη σύνταξη ενημερωτικών οδηγιών προς ασθενείς και στην υποστήριξη εσωτερικών διαδικασιών. Η διεθνής εμπειρία δείχνει ότι στην υγεία η ασφάλεια δεν χτίζεται με μεταφορά δεδομένων σε αδιαφανή συστήματα, αλλά με ασφαλή περιβάλλοντα ανάλυσης, ανοικτό κώδικα, ψευδωνυμοποίηση, αυστηρά δικαιώματα πρόσβασης και πλήρη ίχνη ελέγχου.
Υπουργεία και υπηρεσίες ασφάλειας: κυριαρχία, όχι αυτοματοποίηση εξουσίας
Στα υπουργεία, τα τοπικά LLMs μπορούν να στηρίξουν νομική αναζήτηση, ανάλυση διαβουλεύσεων, έλεγχο προμηθειών, υποστήριξη φορολογικής συμμόρφωσης, προετοιμασία ενημερωτικών σημειωμάτων, ταξινόμηση εγγράφων και αξιολόγηση προγραμμάτων. Το μοντέλο πρέπει να είναι σαφές: η ΤΝ εισηγείται, συνοψίζει, εντοπίζει, τεκμηριώνει. Δεν αποφασίζει.
Στις κρατικές υπηρεσίες ασφάλειας, η αξία βρίσκεται κυρίως στην κυβερνοασφάλεια, στην ανάλυση ανοιχτών πηγών, στην εσωτερική διαχείριση περιστατικών, στην αναζήτηση τεχνικών οδηγιών και στη σύνθεση μεγάλου όγκου πληροφοριών. Εδώ η τοπική υποδομή είναι ακόμη πιο αναγκαία, επειδή κανείς σοβαρός δημόσιος φορέας δεν πρέπει να στέλνει ευαίσθητα δεδομένα ασφάλειας σε εξωτερικά κλειστά API. Ταυτόχρονα χρειάζονται αυστηρά όρια: καμία γενικευμένη επιτήρηση, καμία αυτόματη στοχοποίηση πολιτών, καμία χρήση χωρίς νομική βάση, ανθρώπινη εποπτεία και λογοδοσία.
Η διεθνής εμπειρία δείχνει τον δρόμο
Η Γαλλία με το Albert, η Εσθονία με το Bürokratt, η Ελβετία με το Apertus, το Allen Institute με το OLMo, οι ευρωπαϊκές AI Factories και η εμπειρία του OpenSAFELY στην υγεία δείχνουν μια κοινή κατεύθυνση: η ΤΝ δημόσιου συμφέροντος χρειάζεται ανοικτότητα, κυριαρχία δεδομένων, διαφάνεια και θεσμική λογοδοσία. Για την Ελλάδα, το πλεονέκτημα είναι ότι δεν χρειάζεται να ξεκινήσει από το μηδέν. Διαθέτει πανεπιστήμια, ερευνητικά κέντρα, κοινότητες ανοικτού λογισμικού, το GlossAPI, δημόσια δεδομένα, αυτοδιοικητικές ανάγκες και ευρωπαϊκές χρηματοδοτήσεις.
Το ερώτημα είναι πολιτικό. Θα πληρώνουμε για πάντα ενοίκιο σε κλειστά συστήματα ή θα χτίσουμε δημόσια ψηφιακή περιουσία; Τα χαμηλού κόστους τοπικά μοντέλα ΤΝ ανοικτού λογισμικού είναι η πιο ρεαλιστική απάντηση: μικρή αρχική επένδυση, γρήγορη δοκιμή, επαναχρησιμοποίηση, τοπική τεχνογνωσία, προστασία δεδομένων και δυνατότητα δημοκρατικού ελέγχου.
Πηγές:
Mistral AI, Mistral 7B & Mixtral Research: Η Mistral AI αποτελεί σημαντικό ευρωπαϊκό παράδειγμα ανάπτυξης ισχυρών μοντέλων ανοικτών βαρών, με το Mistral 7B να διατίθεται υπό Apache 2.0 και το Mixtral 8x7B ως open-weights μοντέλο για αποδοτική τοπική ή κυρίαρχη εγκατάσταση: https://mistral.ai/news/announcing-mistral-7b/ και https://mistral.ai/news/mixtral-of-experts/,
Allen Institute for AI, OLMo: Το OLMo είναι από τα σημαντικότερα παραδείγματα πλήρως ανοικτής προσέγγισης σε γλωσσικά μοντέλα, με δημοσίευση βαρών, κώδικα και τεχνικών αναφορών, χρήσιμο ως πρότυπο για δημόσια ελέγξιμη ΤΝ: https://allenai.org/olmo,
European Commission / EuroHPC & AI Factories: Τα ευρωπαϊκά AI Factories αξιοποιούν την υπολογιστική ικανότητα του EuroHPC για αξιόπιστα μοντέλα, ως κόμβοι για τον ακαδημαϊκό χώρο, την έρευνα, το δημόσιο τομέα και τις επιχειρήσεις: https://digital-strategy.ec.europa.eu/en/policies/ai-factories,
European Commission, EU AI Act: Το ευρωπαϊκό πλαίσιο για την ΤΝ καθιστά αναγκαία την τεχνική και οργανωτική συμμόρφωση, ιδίως για συστήματα υψηλού κινδύνου, με διαχείριση κινδύνων, διαφάνεια, ποιότητα δεδομένων, ανθρώπινη εποπτεία, ακρίβεια, ανθεκτικότητα και κυβερνοασφάλεια: https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai.
Ο Οργανισμός Ηνωμένων Εθνών ανακοίνωσε την έναρξη λειτουργίας της πλατφόρμαςOpen Source United (OSU), ενός νέου κεντρικού κόμβου που φιλοδοξεί να συγκεντρώσει και να συντονίσει όλες τις δράσεις ανοιχτού λογισμικού στο οικοσύστημα του ΟΗΕ. Η πρωτοβουλία αυτή σηματοδοτεί μια σημαντική καμπή για τη διεθνή συνεργασία στον τομέα της ψηφιακής διακυβέρνησης, της διαφάνειας και της βιώσιμης τεχνολογικής ανάπτυξης.
Σύμφωνα με τον Dr. David Manset, συν-πρόεδρο της κοινότητας πρακτικής Open Source United και ανώτερο σύμβουλο της Διεθνούς Ένωσης Τηλεπικοινωνιών (ITU), στόχος της νέας πλατφόρμας είναι να αποτελέσει το βασικό σημείο αναφοράς για την κοινότητα ανοιχτού λογισμικού του ΟΗΕ και των συνεργατών του. Μέσα από το portal, χρήστες και οργανισμοί θα μπορούν να ανακαλύπτουν έργα ανοιχτού κώδικα, αποθετήρια λογισμικού, τεχνικές κοινότητες, hackathons που σχετίζονται με τους Στόχους Βιώσιμης Ανάπτυξης (SDGs), καθώς και εκπαιδευτικές και συνεργατικές δράσεις.
Ένας «λειτουργικός πυρήνας» για το ανοιχτό λογισμικό
Το Open Source United δεν σχεδιάστηκε απλώς ως μια ενημερωτική ιστοσελίδα. Όπως εξηγεί ο Manset, φιλοδοξεί να λειτουργήσει ως ο «επιχειρησιακός πυρήνας» των open source πρωτοβουλιών του ΟΗΕ. Η πλατφόρμα ενσωματώνει τις Αρχές Ανοιχτού Κώδικα του ΟΗΕ, το κοινό πολιτικό πλαίσιο για open source τεχνολογίες και το επίσημο αποθετήριο κώδικα του οργανισμού.
Ήδη στην ενότητα “Projects” παρουσιάζονται τρία σημαντικά έργα:
eTIR National Application: λύση ανοιχτού κώδικα που διευκολύνει τη διασύνδεση των εθνικών τελωνειακών αρχών.
GENIE.AI: πρωτοβουλία που στοχεύει στη δίκαιη πρόσβαση σε προηγμένες δυνατότητες τεχνητής νοημοσύνης.
FireForm: σύστημα που βοηθά τις υπηρεσίες πρώτης απόκρισης να αυτοματοποιούν τη σύνταξη αναφορών περιστατικών, μειώνοντας τον διοικητικό φόρτο εργασίας.
Ο ΟΗΕ σχεδιάζει να επεκτείνει σταδιακά τη λίστα έργων, ενώ νέες προτάσεις μπορούν να υποβάλλονται μέσω της κοινότητας Open Source United.
Ανοιχτός κώδικας ως εργαλείο διαφάνειας και εμπιστοσύνης
Η δημιουργία του portal έρχεται σε μια περίοδο όπου η τεχνητή νοημοσύνη επηρεάζει ολοένα και περισσότερο τις κοινωνίες και τις δημόσιες υπηρεσίες. Μέσα σε αυτό το περιβάλλον, το ανοιχτό λογισμικό θεωρείται κρίσιμο εργαλείο για τη διασφάλιση διαφάνειας, διαλειτουργικότητας και αξιοπιστίας.
Ο Manset υπογράμμισε ότι τα επόμενα χρόνια η ανοικτότητα, η δυνατότητα ελέγχου του κώδικα και η συνεργατική διακυβέρνηση θα παίξουν καθοριστικό ρόλο στην ανάπτυξη ασφαλών και αξιόπιστων ψηφιακών συστημάτων.
Τεχνολογία και ανάπτυξη της πλατφόρμας
Το portal βασίζεται στο σύστημα διαχείρισης περιεχομένου Drupal, το οποίο επιλέχθηκε λόγω των ισχυρών δυνατοτήτων πολυγλωσσικής υποστήριξης, προσβασιμότητας και ασφάλειας. Η πλατφόρμα είναι διαθέσιμη και στις έξι επίσημες γλώσσες του ΟΗΕ.
Ιδιαίτερο ενδιαφέρον έχει το γεγονός ότι και το ίδιο το portal είναι ανοιχτού κώδικα, ευθυγραμμισμένο με την αρχή «open by default» του ΟΗΕ. Ο πηγαίος κώδικας αναμένεται να δημοσιοποιηθεί επίσημα κατά τη διάρκεια της επερχόμενης UN Open Source Week.
Η ανάπτυξη και συντήρηση του συστήματος δεν γίνεται από έναν μόνο ανάδοχο ή εσωτερική ομάδα, αλλά μέσα από συνεργασία πολλών φορέων του ΟΗΕ και εξωτερικών συνεργατών, ακολουθώντας ένα αποκεντρωμένο και κοινοτικό μοντέλο ανάπτυξης.
Ισχυρή διεθνής υποστήριξη
Οι Αρχές Ανοιχτού Κώδικα του ΟΗΕ έχουν ήδη λάβει τη στήριξη περισσότερων από 150 οργανισμών, κυβερνήσεων και ιδρυμάτων από όλο τον κόσμο. Ανάμεσα στους υποστηρικτές περιλαμβάνονται σημαντικοί οργανισμοί όπως:
το Open Source Initiative,
το Linux Foundation,
η Red Hat,
το Eclipse Foundation,
καθώς και οι κυβερνήσεις της Γαλλίας και της Νότιας Αφρικής.
Η αύξηση αυτή θεωρείται ιδιαίτερα σημαντική, καθώς τον Αύγουστο του 2025 οι υποστηρικτές ήταν περίπου 60.
Οι νέοι άξονες δράσης
Το Open Source United παρουσίασε επίσης έναν νέο οδικό χάρτη με βασικούς άξονες εργασίας που θα διαμορφώσουν τη μελλοντική εξέλιξη της πλατφόρμας:
Responsible Open AI: υπεύθυνη και διαφανής αξιοποίηση της τεχνητής νοημοσύνης.
Resilient Digital Infrastructure: ανάπτυξη ανθεκτικών ψηφιακών υποδομών βασισμένων σε open source τεχνολογίες.
Contributor Engagement: ενίσχυση της συμμετοχής και αναγνώρισης των συνεισφερόντων.
OSPO-in-a-Box: έτοιμα εργαλεία και πρότυπα για τη δημιουργία Open Source Program Offices.
Open Source Talent and Capacity Development: εκπαίδευση και ανάπτυξη δεξιοτήτων γύρω από το ανοιχτό λογισμικό.
Παράλληλα, σχεδιάζεται και η δημιουργία ενός διεθνούς μητρώου OSPOs, που θα βοηθήσει οργανισμούς και κράτη να συνδεθούν με αντίστοιχες πρωτοβουλίες παγκοσμίως.
Η επόμενη μέρα
Οι επόμενες εξελίξεις αναμένονται στην εκδήλωση UN Open Source Week 2026, η οποία θα πραγματοποιηθεί από τις 22 έως τις 26 Ιουνίου στα κεντρικά γραφεία του ΟΗΕ στη Νέα Υόρκη. Η διοργάνωση, που παλαιότερα ήταν γνωστή ως “OSPOs for Good”, έχει γνωρίσει εντυπωσιακή ανάπτυξη, από περίπου 70 συμμετέχοντες στην πρώτη διοργάνωση σε περισσότερους από 1.000 το 2025.
Το Open Source United φαίνεται πως δεν αποτελεί απλώς μια νέα ψηφιακή πλατφόρμα, αλλά μια στρατηγική προσπάθεια του ΟΗΕ να ενισχύσει τη συνεργασία, τη διαφάνεια και τη βιώσιμη τεχνολογική καινοτομία σε παγκόσμιο επίπεδο.
Η ενωσιακή πολιτική επενδύσεων στην τεχνητή νοημοσύνη ακολουθεί ένα χαρακτηριστικό μοτίβο: ανακοινώνεται ένα εντυπωσιακό ποσό, το οποίο όμως συγκροτείται ανασυσκευάζοντας κονδύλια που έχουν ήδη δεσμευτεί.
Στις 9 Απριλίου, η Ευρωπαϊκή Επιτροπή σηματοδότησε τη συμπλήρωση ενός έτους από το AI Continent Action Plan, διατυμπανίζοντας ότι «1 δισ. ευρώ σε προσκλήσεις χρηματοδότησης [έχει] ήδη προβλεφθεί» για την προώθηση της υιοθέτησης της ΤΝ μέσω της στρατηγικής Apply AI. Η χρηματοδότηση αυτή προέρχεται κυρίως από το Horizon Europe, το βασικό πρόγραμμα έρευνας και καινοτομίας της ΕΕ, και από το Digital Europe Programme, που στηρίζει την ανάπτυξη ψηφιακών υποδομών και ικανοτήτων.
Για όποιον παρακολουθεί την πολιτική της ΕΕ για την ΤΝ, το ποσό του 1 δισ. μάλλον θα φαντάζει γνώριμο.
Τον Δεκέμβριο του 2018, το Coordinated Plan on Artificial Intelligence της Επιτροπής είχε ήδη θέσει ως στόχο η Ένωση να επενδύει τουλάχιστον 1 δισ. ευρώ ετησίως στην ΤΝ στο πλαίσιο του τότε επικείμενου δημοσιονομικού κύκλου 2021–2027, «ιδίως μέσω του νέου Digital Europe Programme και του Horizon Europe».
Οκτώ χρόνια αργότερα, το ίδιο ακριβώς ποσό ανακοινώθηκε ως νέο ορόσημο.
Για να πάρουμε μια τάξη μεγέθους: η έκθεση του ΟΟΣΑ για το 2025 εκτίμησε τις συνολικές επενδύσεις σε ΤΝ στις 27 χώρες της ΕΕ για το 2023 σε περίπου 257 δισ. ευρώ. Αν αφαιρέσουμε την Έρευνα & Ανάπτυξη —που χρηματοδοτεί τη δημιουργία της ΤΝ και όχι την υιοθέτησή της, και δεν αποτελεί το αντικείμενο της στρατηγικής Apply AI— απομένουν περίπου 224 δισ. ευρώ που κατευθύνονται ετησίως στις κατηγορίες που συνιστούν αξιοποίηση της τεχνολογίας. Από αυτά τα 224 δισ. ευρώ, περίπου 64 δισ. αφορούν δημόσια δαπάνη. Το πολυδιαφημισμένο 1 δισ. ευρώ τοποθετείται πάνω σε αυτό ακριβώς το φόντο.
Η εξήγηση για την ισχνή συνεισφορά της Επιτροπής είναι σχετικά απλή. Η Επιτροπή λειτουργεί εντός των περιορισμών του επταετούς δημοσιονομικού πλαισίου της ΕΕ και δεν μπορεί να δημιουργήσει μονομερώς νέους δημοσιονομικούς πόρους για την ΤΝ. Αυτό που μπορεί να κάνει είναι να επανακαθορίσει προτεραιότητες και να ανασυσκευάσει χρηματοδότηση εντός προγραμμάτων που είχαν ήδη εγκριθεί (όπως το Horizon Europe ή το Digital Europe).
Όταν η Επιτροπή βρίσκεται υπό εξωτερική πίεση και υπό την ολοένα ισχυρότερη αίσθηση ότι η Ευρώπη «μένει πίσω» στον «αγώνα» της ΤΝ, η ανασυσκευασία είναι το εργαλείο που έχει στη διάθεσή της.
Αυτό δεν σημαίνει ότι η ανακατανομή δημόσιων κονδυλίων εντός των ενωσιακών προγραμμάτων χρηματοδότησης είναι κενή νοήματος. Στην προκειμένη περίπτωση, αντανακλά μια αντίληψη της ΤΝ ως αρκετά ώριμης και έτοιμης προς ανάπτυξη: δεν αντιμετωπίζεται πλέον κυρίως ως κάτι που πρέπει να μελετηθεί, να αποτελέσει αντικείμενο πειραματισμού ή να στηριχθεί μέσω ερευνητικών επιχορηγήσεων, αλλά ως κάτι που πρέπει να εμπορευματοποιηθεί, να κλιμακωθεί και να διαχυθεί σε ολόκληρη την οικονομία.
Τα 200 δισ. ευρώ που ανακοίνωσε η Πρόεδρος της Ευρωπαϊκής Επιτροπής, Φον ντερ Λάιεν, στο Paris AI Action Summit τον Φεβρουάριο του 2025 εφάρμοσαν την ίδια λογική σε βιομηχανική κλίμακα και πρόσθεσαν κάτι νέο: μια ευθυγράμμιση με διεθνείς ιδιώτες επενδυτές, η οποία θα διαμόρφωνε τους ίδιους τους όρους της ενωσιακής πολιτικής για την ΤΝ.
Αναλυτικά, αυτά τα 200 δισ. ευρώ είναι:
50 δισ. ευρώ από την Επιτροπή, συγκεντρωμένα από προγράμματα που είχαν θεσμοθετηθεί πολύ πριν από το Παρίσι (και, κατά πάσα πιθανότητα, από συνεισφορές των κρατών-μελών —αν και αυτό δεν προέκυπτε με σαφήνεια από την ομιλία της Προέδρου Φον ντερ Λάιεν στο Παρίσι ούτε από το επακόλουθο δελτίο Τύπου), τα οποία συναποτελούν μια πρωτοβουλία «InvestAI».
150 δισ. ευρώ που δεσμεύτηκαν για περίοδο πέντε ετών από ιδιώτες, διεθνείς επενδυτές (μεταξύ των οποίων οι Blackstone, KKR, EQT, General Catalyst και Warburg Pincus) μέσω της EU AI Champions Initiative.
Δεν μπορεί κανείς παρά να αναρωτηθεί αν οι διαχειριστές κεφαλαίων πίσω από το νούμερο των 150 δισ. αποτελούν όντως πρόσθετη χρηματοδότηση, ή αν πρόκειται, σε μεγάλο βαθμό, για κεφάλαια που έτσι κι αλλιώς κατευθύνονταν ήδη προς την ευρωπαϊκή ΤΝ. Κάτι τέτοιο θα αντανακλούσε μια ωριμάζουσα αγορά, τις υψηλές αποτιμήσεις των αμερικανικών εταιρειών ΤΝ σε σχέση με τα έσοδά τους, καθώς και το γεγονός ότι μεγάλο μέρος του ταλέντου βρίσκεται εδώ, στην Ευρώπη. Η χρηματοδότηση επιχειρηματικών κεφαλαίων (VC) προς ευρωπαϊκές εταιρείες ΤΝ αυξήθηκε από λίγο πάνω από 10 δισ. δολάρια το 2024 σε περίπου 17,5 δισ. δολάρια το 2025 —την πρώτη χρονιά που η ΤΝ αναδείχθηκε στον κορυφαίο τομέα για επενδύσεις venture capital στην Ευρώπη. Μήπως, λοιπόν, τα κεφάλαια έρχονταν ούτως ή άλλως;
Αν ισχύει αυτό, τότε η ουσία της υπόθεσης δεν βρίσκεται τόσο στα ποσά, όσο στους όρους που τα συνοδεύουν και στους συμβιβασμούς που αυτοί συνεπάγονται.
Η δέσμευση των ιδιωτικών φορέων ήταν ρητά υπό όρους: να δημιουργήσει η Ευρώπη «ένα διαφανές και στοχευμένο, καθοδηγούμενο από τον ανταγωνισμό πλαίσιο για την ΤΝ», «εξορθολογίζοντας και απλοποιώντας» τους νόμους —έκφραση που, στην αργκό των Βρυξελλών, σημαίνει απορρύθμιση.
Αυτό έχει σημασία, γιατί αλλάζει τον τρόπο με τον οποίο πρέπει να ερμηνευτεί η δέσμευση του Παρισιού.
Η βαρύτητα της δέσμευσης έγκειται λιγότερο στην κινητοποίηση νέων κεφαλαίων και περισσότερο στο ότι η Επιτροπή συμβάλλει στην προβολή μιας αφήγησης περί σύμπραξης δημόσιου και ιδιωτικού τομέα και περί επιχειρηματικού δυναμισμού, ενώ ταυτόχρονα αξιοποιεί τη στήριξη των επενδυτών για να ενισχύσει το επιχείρημα υπέρ της απορρύθμισης.
Οι όροι αυτοί, ωστόσο, δεν περιορίζονται στη ρύθμιση και μόνο.
Όπως υποστηρίζει ο Leevi Saari στην πρόσφατη εργασία του, αυτό που αναδύεται στην τρέχουσα προσέγγιση της ΕΕ ως προς τη βιομηχανική πολιτική για την ΤΝ είναι μια «αντιστροφή της αιρεσιμότητας» (inversion of conditionality): «αντί το κράτος να επιβάλλει όρους στο κεφάλαιό του, στρατηγικά ευθυγραμμισμένοι ιδιώτες χρηματοδότες ενδέχεται να θέτουν όρους για τη συνεργασία τους», με αποτέλεσμα «η επιδίωξη εξωτερικής κυριαρχίας εκ μέρους της ΕΕ να επιδοτείται από μια μείωση της αυτονομίας της εγχώριας πολιτικής σφαίρας».
Έτσι, στο όνομα της κάλυψης της απόστασης στον παγκόσμιο αγώνα της ΤΝ, δημόσιοι πόροι —νόμοι και κεφάλαια— ανακατευθύνονται για να ικανοποιήσουν τις απαιτήσεις των διεθνών επενδυτών.
Το πρόβλημα επιτείνεται από το γεγονός ότι οι χώροι όπου λαμβάνονται αυτές οι πολιτικές αποφάσεις —όπως και οι επιλογές για το τι είδους ΤΝ κατασκευάζεται με δημόσιο χρήμα— είναι ακόμη λιγότερο διαφανείς από τις νομοθετικές διαδικασίες στην Ευρώπη. Εκείνες οι νομοθετικές αρένες δεν υπήρξαν ποτέ πλήρως ανοιχτές ή θωρακισμένες απέναντι στην εταιρική επιρροή, όπως έχει δείξει επανειλημμένα η επίμονη (και επιτυχημένη) άσκηση πιέσεων από μεγάλες τεχνολογικές εταιρείες. Δημιουργούσαν, ωστόσο, πιο ορατά σημεία αμφισβήτησης, τεκμηρίωσης και δημόσιου διαλόγου από ό,τι τα φόρα όπου διαμορφώνεται η βιομηχανική πολιτική της ΕΕ για την ΤΝ. Χαρακτηριστικό παράδειγμα: πώς κατέληξε η Επιτροπή στα AI gigafactories ως απάντηση στο πεδίο της βιομηχανικής πολιτικής, και στον φάκελο των περίπου 20 δισ. ευρώ που συγκεντρώνεται πλέον γύρω από αυτά; Η απάντηση είναι ακόμη λιγότερο προσβάσιμη από τα ήδη ατελή κανάλια ελέγχου που συνόδευαν τη ρυθμιστική ατζέντα της Ευρώπης.
Το συμπέρασμα από την παρακολούθηση αυτής της μετατόπισης είναι ότι η ενασχόληση με τη νομοθεσία δεν αρκεί πλέον από μόνη της. Ένα ολοένα μεγαλύτερο μερίδιο εξουσίας ασκείται μέσω επενδυτικών αποφάσεων, βιομηχανικών συμπράξεων και εκτελεστικών επιλογών για τις υποδομές. Ανακοινώσεις που υποτίθεται ότι αποτυπώνουν σημαντική δημόσια επένδυση, στην πραγματικότητα σηματοδοτούν μια ευθυγράμμιση της δημόσιας στρατηγικής με το ιδιωτικό συμφέρον. Καθώς το κέντρο βάρους της διακυβέρνησης της ΤΝ στην Ευρώπη μετατοπίζεται από τη νομοθεσία στη βιομηχανική πολιτική, το να καταστούν ορατοί αυτοί οι χώροι αποτελεί το πρώτο βήμα για να καταστούν και υπόλογοι.
Γιατί η επαλήθευση γεγονότων παραμένει ανθρώπινη ευθύνη
Η τεχνητή νοημοσύνη έχει μπει με ταχύτητα στον τρόπο με τον οποίο οι πολίτες αναζητούν πληροφορίες. Όλο και περισσότεροι άνθρωποι δεν πληκτρολογούν πια μια ερώτηση σε μια μηχανή αναζήτησης, αλλά τη θέτουν σε ένα γλωσσικό μοντέλο και περιμένουν μια ολοκληρωμένη απάντηση. Η εμπειρία είναι πράγματι εντυπωσιακή. Η απάντηση έρχεται γρήγορα, με αυτοπεποίθηση, με συνοχή, συχνά με ύφος αυθεντίας. Αυτό ακριβώς είναι και το πρόβλημα.
Η τεχνητή νοημοσύνη δεν γνωρίζει με τον τρόπο που γνωρίζει ένας άνθρωπος, ένας δημοσιογράφος, ένας ερευνητής ή ένας τεκμηριωτής. Δεν έχει άμεση σχέση με τον κόσμο. Δεν είδε το γεγονός, δεν μίλησε με την πηγή, δεν άνοιξε το αρχείο, δεν στάθηκε απέναντι σε δύο αντιφατικές μαρτυρίες για να κρίνει ποια αντέχει στον έλεγχο. Τα μεγάλα γλωσσικά μοντέλα παράγουν την πιθανότερη γλωσσική συνέχεια μιας ερώτησης, με βάση τεράστιους όγκους δεδομένων και στατιστικές συσχετίσεις. Αυτό μπορεί να είναι εξαιρετικά χρήσιμο για περίληψη, ταξινόμηση, αναζήτηση, μετάφραση ή πρώτη οργάνωση υλικού. Δεν είναι όμως επαλήθευση.
Η διαφορά ανάμεσα στην απάντηση και στην τεκμηρίωση
Η επαλήθευση γεγονότων είναι μια επίμονη, συχνά ενοχλητική εργασία. Απαιτεί γραμμή προς γραμμή έλεγχο, πρωτογενείς πηγές, αναζήτηση αντιφάσεων, τηλεφωνήματα, πρόσβαση σε αρχεία, γνώση του θεσμικού πλαισίου και ηθική κρίση. Δεν αρκεί να βρεθεί μια πρόταση που μοιάζει σωστή. Πρέπει να απαντηθεί ποιος το λέει, πότε το είπε, με ποια ιδιότητα, με ποιο τεκμήριο, αν υπάρχει νεότερη πληροφορία, αν η διατύπωση παραπλανά και αν η παράλειψη συμφραζομένων αλλάζει το νόημα.
Η τεχνητή νοημοσύνη δυσκολεύεται ακριβώς εκεί όπου αρχίζει η πραγματική επαλήθευση. Μπορεί να δώσει σχέδιο εργασίας για το πώς θα ελεγχθεί ένας ισχυρισμός, αλλά συχνά δεν εκτελεί τον έλεγχο με επαρκή αξιοπιστία. Μπορεί να παραπέμψει σε πηγές που δεν στηρίζουν την απάντηση. Μπορεί να συνδυάσει παλιά και νέα στοιχεία σαν να είναι ισοδύναμα. Μπορεί να παραγάγει ανύπαρκτες αναφορές, λανθασμένες ημερομηνίες ή συμπεράσματα που δεν προκύπτουν από τα δεδομένα. Το πιο επικίνδυνο δεν είναι ότι κάνει λάθη. Είναι ότι τα κάνει με άψογη σύνταξη και ήρεμη βεβαιότητα.
Η αλήθεια δεν βρίσκεται όλη στο διαδίκτυο
Υπάρχει και ένα βαθύτερο πρόβλημα. Μεγάλο μέρος της ανθρώπινης γνώσης δεν είναι διαθέσιμο στο ανοικτό διαδίκτυο. Βρίσκεται σε φυσικά αρχεία, σε τοπικές μνήμες, σε ανεπεξέργαστα έγγραφα, σε ανθρώπους που πρέπει να μιλήσουν, σε θεσμικές διαδικασίες που δεν έχουν ψηφιοποιηθεί, σε μικρές λεπτομέρειες που δεν καταγράφηκαν ποτέ σε μια μηχανή αναζήτησης. Η τεχνητή νοημοσύνη μπορεί να ανασυνθέτει το ήδη ψηφιοποιημένο ίχνος του κόσμου. Δεν μπορεί να εγγυηθεί ότι αυτό το ίχνος είναι πλήρες, ακριβές, επίκαιρο ή απαλλαγμένο από συμφέροντα.
Αυτό έχει ιδιαίτερη σημασία για τη δημόσια διοίκηση, τη δημοσιογραφία, τη δικαιοσύνη, την επιστήμη και τη δημοκρατική λογοδοσία. Αν ένα σύστημα ΤΝ χρησιμοποιηθεί για να ελέγξει αν ένας πολίτης δικαιούται επίδομα, αν μια δημόσια σύμβαση είναι σύννομη ή αν μια είδηση είναι αληθής, τότε το λάθος δεν είναι απλώς τεχνικό. Μπορεί να γίνει διοικητική αδικία, παραπληροφόρηση, θεσμική αυθαιρεσία ή απώλεια εμπιστοσύνης.
Χρήσιμο εργαλείο, όχι τελικός κριτής
Η σωστή απάντηση δεν είναι να απορρίψουμε την τεχνητή νοημοσύνη. Είναι να την τοποθετήσουμε στη σωστή θέση. Η ΤΝ μπορεί να βοηθήσει τους fact-checkers, τους δημοσιογράφους, τους δημόσιους λειτουργούς και τους ερευνητές να εντοπίζουν ισχυρισμούς, να ταξινομούν μεγάλους όγκους υλικού, να συγκρίνουν κείμενα, να βρίσκουν πιθανές αντιφάσεις και να προτείνουν πηγές για έλεγχο. Δεν πρέπει όμως να είναι ο τελικός εγγυητής της αλήθειας.
Για τον δημόσιο τομέα, η αρχή πρέπει να είναι σαφής: κανένα σύστημα ΤΝ δεν απαντά για δικαιώματα, υποχρεώσεις, άδειες, φόρους, παροχές ή κυρώσεις χωρίς παραπομπή σε ελεγχόμενες πηγές και χωρίς ανθρώπινη τελική ευθύνη. Τα συστήματα ανάκτησης τεκμηρίων μπορούν να μειώσουν τις παραισθήσεις, αλλά δεν τις εξαφανίζουν. Τα ανοικτά μοντέλα, ο ανοικτός κώδικας, τα δημόσια σύνολα δεδομένων, τα αρχεία καταγραφής, τα Model Cards, τα Datasheets και οι ανεξάρτητοι έλεγχοι είναι αναγκαίες δικλείδες, όχι μαγικές λύσεις.
Η δημοκρατική κοινωνία δεν χρειάζεται μηχανές που παριστάνουν τον αλάνθαστο κριτή. Χρειάζεται δημόσιες υποδομές γνώσης, ανοικτά δεδομένα, ανεξάρτητη δημοσιογραφία, ισχυρά αρχεία, βιβλιοθήκες, ερευνητές, δημόσιους λειτουργούς με κατάρτιση και πολίτες που μπορούν να ελέγχουν την εξουσία. Η τεχνητή νοημοσύνη μπορεί να γίνει χρήσιμο εργαλείο σε αυτή την αλυσίδα. Δεν μπορεί να την αντικαταστήσει.
Η αλήθεια δεν είναι απλώς σωστή πρόταση. Είναι διαδικασία. Και η διαδικασία αυτή απαιτεί ευθύνη, κρίση, λογοδοσία και ανθρώπινη παρουσία.
Πηγές άρθρου:
WIRED, “AI Just Isn’t Right”: Το άρθρο τεκμηριώνει, μέσα από την εμπειρία επαγγελματικού fact-checking, γιατί τα γλωσσικά μοντέλα μπορούν να βοηθήσουν στην αναζήτηση και οργάνωση πληροφοριών, αλλά δεν μπορούν να αντικαταστήσουν την ανθρώπινη επαλήθευση γεγονότων: https://www.wired.com/story/fact-checking-ai/,
OpenAI, “Introducing SimpleQA”: Το SimpleQA είναι σημείο αναφοράς για την αξιολόγηση της πραγματολογικής ακρίβειας των γλωσσικών μοντέλων σε σύντομες ερωτήσεις με μία σαφή απάντηση, δείχνοντας πόσο δύσκολο παραμένει το πρόβλημα της αξιοπιστίας: https://openai.com/index/introducing-simpleqa/,
Η Τεχνητή Νοημοσύνη (AI) εξελίσσεται με ταχύτητα που αλλάζει ριζικά την οικονομία, την πολιτική και την καθημερινότητα των κοινωνιών. Ωστόσο, μαζί με τις τεράστιες δυνατότητες ανάπτυξης και καινοτομίας, αναδύονται σοβαρά ερωτήματα σχετικά με την ασφάλεια, τη διαφάνεια, την ενεργειακή κατανάλωση, αλλά και το ποιος τελικά ελέγχει την τεχνολογία αυτή. Μέσα σε ένα παγκόσμιο περιβάλλον αβεβαιότητας και γεωπολιτικών εντάσεων, η ανάγκη για μια συλλογική και υπεύθυνη διακυβέρνηση της AI γίνεται πιο επιτακτική από ποτέ.
Τα Ψηφιακά Δημόσια Αγαθά περιλαμβάνουν τεχνολογίες ανοιχτού κώδικα, ανοιχτά δεδομένα και ανοιχτά μοντέλα τεχνητής νοημοσύνης, τα οποία μπορούν να αξιοποιηθούν από κυβερνήσεις, οργανισμούς και κοινωνίες χωρίς αποκλεισμούς. Η λογική πίσω από αυτά είναι ότι η τεχνολογία δεν πρέπει να αποτελεί προνόμιο λίγων μεγάλων εταιρειών, αλλά εργαλείο συλλογικής προόδου.
Η ανοιχτότητα ενισχύει τη διαφάνεια, την εμπιστοσύνη και τη δυνατότητα συνεργασίας μεταξύ κρατών και κοινωνιών. Παράλληλα, δίνει τη δυνατότητα σε χώρες με περιορισμένους πόρους να αναπτύξουν δικές τους λύσεις τεχνητής νοημοσύνης, προσαρμοσμένες στις τοπικές κοινωνικές και οικονομικές ανάγκες.
Η έννοια της “Frugal AI”
Ένα από τα πιο ενδιαφέροντα σημεία της συζήτησης αφορά την έννοια της “Frugal AI” — δηλαδή της «λιτής» ή αποδοτικής τεχνητής νοημοσύνης. Αντί για γιγαντιαία μοντέλα που απαιτούν τεράστιες υπολογιστικές υποδομές και καταναλώνουν τεράστιες ποσότητες ενέργειας, η Frugal AI προτείνει μικρότερα, εξειδικευμένα και ενεργειακά αποδοτικά μοντέλα.
Αυτή η προσέγγιση προσφέρει πολλαπλά οφέλη:
Μειώνει την ενεργειακή κατανάλωση και το περιβαλλοντικό αποτύπωμα.
Επιτρέπει σε μικρότερες χώρες και οργανισμούς να αναπτύξουν δικές τους AI εφαρμογές.
Ενισχύει την ψηφιακή κυριαρχία, περιορίζοντας την εξάρτηση από τεχνολογικούς κολοσσούς.
Διευκολύνει τη χρήση τοπικών δεδομένων και την προσαρμογή στις ανάγκες κάθε κοινωνίας.
Η συζήτηση αυτή αποκτά ιδιαίτερη σημασία καθώς σήμερα η ανάπτυξη προηγμένων AI μοντέλων συγκεντρώνεται σε λίγες μεγάλες εταιρείες με τεράστιες οικονομικές και τεχνολογικές δυνατότητες.
Γιατί η ανοιχτότητα από μόνη της δεν αρκεί
Παρότι η ανοιχτή τεχνολογία θεωρείται βασικό στοιχείο δημοκρατικής πρόσβασης, οι ειδικοί προειδοποιούν ότι η «ανοιχτότητα» δεν αποτελεί από μόνη της λύση. Ένα ανοιχτό μοντέλο AI μπορεί να είναι διαθέσιμο σε όλους, αλλά αυτό δεν σημαίνει απαραίτητα ότι όλοι έχουν ίσες δυνατότητες αξιοποίησής του.
Οι μεγάλες τεχνολογικές εταιρείες συνεχίζουν να διαθέτουν τεράστιο πλεονέκτημα σε υπολογιστική ισχύ, χρηματοδότηση και πρόσβαση σε δεδομένα. Επιπλέον, υπάρχουν σοβαρά ζητήματα που αφορούν:
Τη συγκέντρωση εξουσίας στην αγορά της AI.
Την εκμετάλλευση εργαζομένων και δεδομένων στις αναπτυσσόμενες χώρες.
Την προστασία της ιδιωτικότητας.
Τις περιβαλλοντικές επιπτώσεις των μεγάλων μοντέλων.
Τη χρήση της AI χωρίς ουσιαστικό κοινωνικό όφελος.
Γι’ αυτόν τον λόγο, η ανοιχτότητα πρέπει να συνοδεύεται από ισχυρούς μηχανισμούς διακυβέρνησης, κανονιστικό πλαίσιο, διαφάνεια και δημόσιες επενδύσεις στην ασφάλεια και την έρευνα.
Η Τεχνητή Νοημοσύνη στην υπηρεσία της κοινωνίας
Η μεγάλη πρόκληση της επόμενης δεκαετίας δεν είναι μόνο η ανάπτυξη πιο ισχυρών συστημάτων AI, αλλά η διασφάλιση ότι αυτά θα λειτουργούν προς όφελος της κοινωνίας. Η τεχνητή νοημοσύνη δεν πρέπει να ενισχύσει τις ήδη υπάρχουσες ανισότητες, αλλά να συμβάλει σε ένα πιο δίκαιο και βιώσιμο μέλλον.
Η πρωτοβουλία του ΟΗΕ για τον Παγκόσμιο Διάλογο AI δείχνει ότι η διεθνής κοινότητα αρχίζει να αντιμετωπίζει σοβαρά το ζήτημα της παγκόσμιας διακυβέρνησης της τεχνητής νοημοσύνης. Το ζητούμενο πλέον είναι να μετατραπούν οι γενικές αρχές σε πρακτικές πολιτικές που θα διασφαλίσουν διαφάνεια, ασφάλεια, βιωσιμότητα και ισότιμη πρόσβαση στην τεχνολογία.
Το μέλλον της AI δεν θα κριθεί μόνο από την τεχνολογική πρόοδο, αλλά από το κατά πόσο οι κοινωνίες θα μπορέσουν να την κατευθύνουν προς το δημόσιο συμφέρον.
Η Σουηδία κάνει ένα σημαντικό βήμα προς την ψηφιακή κυριαρχία και τη διαλειτουργικότητα στον δημόσιο τομέα, υιοθετώντας το ανοιχτό πρότυπο επικοινωνίας Matrix για τη διασύνδεση κυβερνητικών υπηρεσιών. Η πρωτοβουλία αυτή φέρνει στο προσκήνιο ένα νέο μοντέλο συνεργασίας, όπου διαφορετικοί οργανισμοί μπορούν να επικοινωνούν απρόσκοπτα, ακόμη κι αν χρησιμοποιούν διαφορετικές πλατφόρμες και προμηθευτές λογισμικού.
Στην πρώτη μεγάλη εφαρμογή του εγχειρήματος, δύο κορυφαίοι δημόσιοι οργανισμοί της χώρας — η Försäkringskassan (Υπηρεσία Κοινωνικής Ασφάλισης της Σουηδίας) και η Trafikverket (Υπηρεσία Μεταφορών της Σουηδίας) — κατάφεραν να ενώσουν τα ανεξάρτητα συστήματα επικοινωνίας τους μέσω του Matrix. Παρότι η Försäkringskassan χρησιμοποιεί την πλατφόρμα Element και η Trafikverket τη Rocket.Chat, οι χρήστες των δύο υπηρεσιών μπορούν πλέον να συνομιλούν σε πραγματικό χρόνο χωρίς τεχνικά εμπόδια.
Ψηφιακή κυριαρχία χωρίς εξάρτηση από προμηθευτές
Η πρωτοβουλία αυτή εντάσσεται στη στρατηγική της Σουηδίας για ενίσχυση της ψηφιακής ανεξαρτησίας του δημόσιου τομέα. Αντί να βασίζονται σε κλειστά οικοσυστήματα μεγάλων τεχνολογικών εταιρειών, οι δημόσιοι φορείς επιλέγουν ένα ανοιχτό και αποκεντρωμένο πρότυπο που επιτρέπει την ελευθερία επιλογής μεταξύ διαφορετικών λύσεων.
Το Matrix λειτουργεί ως κοινή υποδομή επικοινωνίας, δίνοντας τη δυνατότητα σε κάθε υπηρεσία να επιλέγει τον προμηθευτή ή ακόμα και να αναπτύσσει δικές της λύσεις βασισμένες σε λογισμικό ανοιχτού κώδικα (FOSS), χωρίς να χάνει τη δυνατότητα διασύνδεσης με άλλους οργανισμούς.
Με αυτόν τον τρόπο, η αγορά γίνεται πιο ανταγωνιστική, καθώς οι προμηθευτές καλούνται να ανταγωνιστούν στην ποιότητα και την αξία των υπηρεσιών τους και όχι να “κλειδώνουν” τους πελάτες τους σε ιδιόκτητα οικοσυστήματα.
Ο ρόλος του eSam
Καθοριστικό ρόλο στην υλοποίηση της πρωτοβουλίας έχει το eSamverkansprogrammet (eSam), μια συνεργατική πρωτοβουλία στην οποία συμμετέχουν περισσότερες από 40 δημόσιες υπηρεσίες της Σουηδίας.
Το eSam όχι μόνο ανακοίνωσε την επιτυχημένη ενεργοποίηση της ομοσπονδιοποίησης μέσω Matrix, αλλά σχεδιάζει και την περαιτέρω επέκταση του έργου. Στόχος είναι να συμμετάσχουν περισσότεροι δημόσιοι φορείς και τεχνολογικοί πάροχοι, ώστε το Matrix να εξελιχθεί σε εθνικό πρότυπο ασφαλούς και διαλειτουργικής επικοινωνίας για το σύνολο της δημόσιας διοίκησης.
Γιατί η διαλειτουργικότητα είναι κρίσιμη
Η ανάγκη για ανοιχτά πρότυπα επικοινωνίας γίνεται ολοένα και πιο επιτακτική, ιδιαίτερα στον δημόσιο τομέα, όπου πολλοί οργανισμοί πρέπει να συνεργάζονται καθημερινά για την εξυπηρέτηση των πολιτών.
Σήμερα, πλατφόρμες όπως το Microsoft Teams, το Slack, το WhatsApp ή το Zoom λειτουργούν ως κλειστά “σιλό”, περιορίζοντας τη δυνατότητα συνεργασίας μεταξύ διαφορετικών συστημάτων. Αυτό δημιουργεί τεχνικά και οργανωτικά εμπόδια, ειδικά σε κρίσιμες υπηρεσίες όπως η υγεία, οι μεταφορές ή η πολιτική προστασία.
Το Matrix επιχειρεί να επαναφέρει τη λογική των “ψηφιακών κοινών”, όπως συνέβη παλαιότερα με το email ή την τηλεφωνία: ανεξάρτητα από τον πάροχο, όλοι μπορούν να επικοινωνούν μεταξύ τους.
Ένα τέτοιο μοντέλο θα μπορούσε να επιτρέψει, για παράδειγμα, σε αστυνομία, πυροσβεστική και υπηρεσίες ασθενοφόρων να ανταλλάσσουν πληροφορίες σε πραγματικό χρόνο, χρησιμοποιώντας διαφορετικά συστήματα αλλά κοινό πρότυπο επικοινωνίας.
Η Ευρώπη στρέφεται στα ανοιχτά πρότυπα
Η Σουηδία δεν είναι η μόνη χώρα που εξετάζει λύσεις βασισμένες στο Matrix. Σε ολόκληρη την Ευρώπη παρατηρείται αυξανόμενο ενδιαφέρον για τεχνολογίες που ενισχύουν την ψηφιακή κυριαρχία και μειώνουν την εξάρτηση από αμερικανικούς τεχνολογικούς κολοσσούς.
Χαρακτηριστικό παράδειγμα αποτελεί η Γερμανία, όπου το σύστημα TI-Messenger, βασισμένο επίσης στο Matrix, χρησιμοποιείται ήδη στον χώρο της υγείας για ασφαλή επικοινωνία μεταξύ ασφαλιστικών οργανισμών, νοσοκομείων, κλινικών και φαρμακείων.
Η υιοθέτηση του Matrix δεν αφορά μόνο την τεχνολογία. Πρόκειται για μια διαφορετική φιλοσοφία γύρω από τις δημόσιες ψηφιακές υποδομές: διαφάνεια, διαλειτουργικότητα, ανοιχτά πρότυπα και ελευθερία επιλογής.
Η Σουηδία δείχνει ότι είναι εφικτό να δημιουργηθεί ένα δημόσιο ψηφιακό οικοσύστημα που δεν εξαρτάται από έναν μόνο προμηθευτή, ενώ ταυτόχρονα παραμένει ασφαλές, επεκτάσιμο και έτοιμο για το μέλλον
Η ψηφιακή εποχή έχει μετατρέψει τα δεδομένα σε έναν από τους σημαντικότερους πόρους για την οικονομία, τη διακυβέρνηση και την κοινωνία. Στο πλαίσιο αυτό, η Ευρωπαϊκή Ένωση έχει αναγνωρίσει ότι τα δεδομένα που παράγονται και διατηρούνται από τους δημόσιους φορείς μπορούν να αποτελέσουν κινητήρια δύναμη για την καινοτομία, τη διαφάνεια και την ανάπτυξη. Η πολιτική ... Read more
Πέντε εβδομάδες μετά την ανακοίνωση της ελληνικής κυβέρνησης για την επιβολή απαγόρευσης πρόσβασης σε μέσα κοινωνικής δικτύωσης για παιδιά κάτω των 15 ετών, 25 οργανισμοί από την Ελλάδα και το εξωτερικό έσπευσαν να υψώσουν τη φωνή τους. Με ανοιχτή επιστολή που κατατέθηκε στις 19 Μαΐου 2026 και απευθύνεται στον Πρωθυπουργό Κυριάκο Μητσοτάκη και τέσσερις αρμόδιους υπουργούς, οι υπογράφοντες φορείς — ανάμεσά τους το Δίκτυο για τα Δικαιώματα του Παιδιού, η Διεθνής Αμνηστία Ελλάδας, η Ελληνική Ένωση για τα Δικαιώματα του Ανθρώπου, το Homo Digitalis. o Οργανισμός Ανοιχτών Τεχνολογιών – ΕΕΛΛΑΚ και η European Digital Rights (EDRi) — καταθέτουν δέκα τεκμηριωμένους προβληματισμούς για τη νομοθετική πρωτοβουλία.
Τι Προβλέπει το Σχέδιο Νόμου
Η πρόταση, που ανακοινώθηκε στις 8 Απριλίου 2026 και δημοσιεύθηκε στην πλατφόρμα TRIS της Ευρωπαϊκής Επιτροπής στις 12 Μαΐου, απαγορεύει σε παιδιά κάτω των 15 ετών την πρόσβαση σε επιγραμμικές υπηρεσίες κοινωνικής δικτύωσης. Για την εφαρμογή του μέτρου, οι πλατφόρμες θα υποχρεωθούν να επαληθεύουν την ηλικία των χρηστών τους μέσω εργαλείων όπως το Gov.gr Wallet ή το Kids Wallet, με χρονοδιάγραμμα εφαρμογής από τον Ιανουάριο του 2027.
Δέκα Λόγοι Ανησυχίας
1. Το μέτρο αφορά όλους, όχι μόνο τα παιδιά
Σύμφωνα με την επιστολή, η επανεπαλήθευση ηλικίας θα αφορά όλους τους λογαριασμούς στην Ελλάδα, ανεξαρτήτως ηλικίας. Αυτό σημαίνει ότι οι πλατφόρμες θα κληθούν να αξιοποιήσουν αλγόριθμους ηλικιακής κατάρτισης προφίλ — μια πρακτική που έως τώρα ανήκε στη σφαίρα της εμπορικής εκμετάλλευσης δεδομένων. Η νομοθεσία, όπως επισημαίνεται, αναβαθμίζει αυτήν την πρακτική σε θεσμική υποχρέωση, θέτοντας σε κίνδυνο την ανωνυμία στο διαδίκτυο για το σύνολο των πολιτών.
2. Η γνώμη των ειδικών αγνοήθηκε
Τον Μάρτιο του 2026, η Επιτροπή Ψυχικής Υγείας του Κεντρικού Συμβουλίου Υγείας (ΚΕΣΥ) παρέδωσε τεκμηριωμένη εισήγηση, εγκεκριμένη ομόφωνα, υπό τον διακεκριμένο Δρ. Αργύρη Στριγγάρη. Η εισήγηση κατέληγε στο συμπέρασμα ότι δεν έχει αποδειχθεί αιτιώδης συνάφεια μεταξύ χρήσης social media και ψυχικής υγείας στον γενικό πληθυσμό παιδιών, και σύστηνε στοχευμένα αντί γενικευμένων μέτρων. Η εισήγηση αυτή φέρεται να μην ελήφθη καν υπόψη κατά την ανακοίνωση του μέτρου.
3. Καμία διαβούλευση, καμία συμμετοχή παιδιών
Το μέτρο δεν συνοδεύτηκε από δημόσια διαβούλευση, ούτε από συμμετοχή ειδικών, ακαδημαϊκών, κοινωνίας των πολιτών — και κυρίως των ίδιων των παιδιών, όπως επιτάσσει το άρθρο 12 της Διεθνούς Σύμβασης για τα Δικαιώματα του Παιδιού. Σε αντίθεση με το Ηνωμένο Βασίλειο, όπου η αντίστοιχη διαδικασία περιλαμβάνει πολύμηνη, διαφανή διαβούλευση με όλα τα εμπλεκόμενα μέρη, η ελληνική κυβέρνηση φέρεται να προχώρησε χωρίς αυτά τα απαραίτητα βήματα.
4. Κοινωνικός αποκλεισμός
Τα εργαλεία επαλήθευσης ηλικίας προϋποθέτουν σύγχρονο smartphone και ψηφιακές δεξιότητες — κυρίως εκ μέρους των γονέων. Οικογένειες χωρίς τέτοιες συσκευές ή δεξιότητες, καθώς και άτομα χωρίς έγγραφα ταυτότητας (όπως πρόσφυγες και μετανάστες), κινδυνεύουν να αποκλειστούν από βασικά μέσα επικοινωνίας. Αυτό ενδέχεται να συνιστά έμμεση διάκριση κατά παράβαση του Χάρτη Θεμελιωδών Δικαιωμάτων της ΕΕ.
5. Παραβίαση θεμελιωδών δικαιωμάτων παιδιών
Ο περιορισμός της πρόσβασης των ανηλίκων στο διαδίκτυο θα μπορούσε να έρχεται σε αντίθεση με τα άρθρα 13 και 15 της Σύμβασης για τα Δικαιώματα του Παιδιού (ελευθερία έκφρασης και συνάθροισης) καθώς και με τα άρθρα 11 και 12 του Χάρτη Θεμελιωδών Δικαιωμάτων της ΕΕ. Το Ελληνικό Συμβούλιο Νεολαίας (ΕΣΥΝ) έχει ήδη τάξει τους νέους κατά της απαγόρευσης, ζητώντας ενδυνάμωση αντί ελέγχου.
6. Τα παιδιά θα βρουν παρακάμψεις — και θα εκτεθούν σε μεγαλύτερους κινδύνους
Περισσότεροι από 400 ακαδημαϊκοί και επιστήμονες πληροφορικής από 30+ χώρες επισημαίνουν ότι οι μηχανισμοί επαλήθευσης ηλικίας παρακάμπτονται εύκολα μέσω VPN. Παράλληλα, παιδιά που παραβιάζουν την απαγόρευση είναι λιγότερο πιθανό να αναφέρουν κακοποιητικές ή επικίνδυνες εμπειρίες, φοβούμενα να αποκαλύψουν την «παράτυπη» παρουσία τους.
7. Αντιφατικές και ασαφείς ανακοινώσεις
Η επιστολή επισημαίνει σειρά αντιφάσεων: το Υπουργείο Υγείας ανακοίνωσε πλήρη εναρμόνιση με το ευρωπαϊκό δίκαιο, ενώ παράλληλα παραδέχτηκε ότι χρειάζεται χρόνος για να εξεταστεί η συμβατότητα. Επίσης, ο Υπουργός Ψηφιακής Διακυβέρνησης δήλωσε δημοσίως ότι δεν θα υπάρχει υποχρέωση χρήσης Kids Wallet, ενώ το σχέδιο νόμου που αναρτήθηκε στο TRIS αναφέρεται ρητά στο εργαλείο.
8. Σοβαρά ζητήματα συμβατότητας με το ευρωπαϊκό δίκαιο
Το μέτρο ενδέχεται να έρχεται σε σύγκρουση τόσο με τον Κανονισμό για τις Ψηφιακές Υπηρεσίες (DSA) όσο και με την Οδηγία 2000/31 για το ηλεκτρονικό εμπόριο. Το βασικό μοντέλο του DSA δεν απαγορεύει κατηγορίες χρηστών βάσει ηλικίας, αλλά υποχρεώνει τις πλατφόρμες να διαχειρίζονται συστημικούς κινδύνους. Ανάλογους προβληματισμούς έχουν εκφράσει νομοθέτες στη Γαλλία και τη Γερμανία.
9. Κενά κυβερνοασφάλειας
Πρόσφατα αποκαλύφθηκε κρίσιμη ευπάθεια στο Gov.gr Wallet που παρέμεινε αθεράπευτη για περισσότερους από έξι μήνες. Λίγες ώρες μετά την ανακοίνωση της αντίστοιχης ευρωπαϊκής εφαρμογής, ειδικοί ανέδειξαν σοβαρές αδυναμίες σχεδιασμού. Η επιστολή καλεί σε ανεξάρτητο έλεγχο ασφαλείας πριν από οποιαδήποτε υποχρεωτική εφαρμογή.
10. Υπάρχουν καλύτερες εναλλακτικές
Οι υπογράφοντες δεν αρνούνται την ανάγκη προστασίας των παιδιών στο διαδίκτυο. Προτείνουν, όμως, στοχευμένες παρεμβάσεις: ενίσχυση του ψηφιακού γραμματισμού στα σχολεία, εκστρατείες ενημέρωσης γονέων, ρύθμιση των εθιστικών επιχειρηματικών μοντέλων των πλατφορμών, και αξιοποίηση — όχι επιβολή — εργαλείων γονικού ελέγχου με τη συναίνεση των παιδιών.
Τι Ζητούν
Οι 25 οργανισμοί απαιτούν τέσσερα πράγματα: διοργάνωση ανοιχτής διαβούλευσης, δημοσιοποίηση της εισήγησης του ΚΕΣΥ, επίσημη ενημέρωση για τυχόν άλλες εισηγήσεις εμπειρογνωμόνων, και — κυρίως — νομοθεσία που θα υποχρεώνει τις πλατφόρμες να επανασχεδιάσουν τα εκμεταλλευτικά επιχειρηματικά τους μοντέλα, ώστε να καταστούν ασφαλείς για όλους τους χρήστες, ανεξαρτήτως ηλικίας.
Η απαγόρευση εισόδου δεν σημαίνει απαγόρευση βλάβης. Αν τα social media είναι επικίνδυνα, η λύση δεν είναι να αποκλείσουμε τα παιδιά — είναι να κάνουμε τα social media λιγότερο επικίνδυνα. Η ανοιχτή επιστολή των 25 οργανισμών θέτει ακριβώς αυτό το ερώτημα στην κυβέρνηση: είναι έτοιμη να ακούσει;
Η ελβετική κυβέρνηση κάνει ένα σημαντικό βήμα προς την ενίσχυση της ψηφιακής της ανεξαρτησίας, επιδιώκοντας να μειώσει σταδιακά την εξάρτησή της από ιδιόκτητο λογισμικό και ξένους τεχνολογικούς παρόχους. Η πρωτοβουλία αυτή εντάσσεται σε μια ευρύτερη στρατηγική για την ενίσχυση της «ψηφιακής κυριαρχίας» της χώρας και τη στροφή προς λύσεις ανοιχτού κώδικα (open source).
Τον Απρίλιο του 2026, εκπρόσωπος της Ομοσπονδιακής Καγκελαρίας της Ελβετίας δήλωσε ότι «η ομοσπονδιακή διοίκηση επιδιώκει να μειώσει σταδιακά τη μακροπρόθεσμη εξάρτησή της από ιδιόκτητο λογισμικό». Η τοποθέτηση αυτή αντανακλά τη αυξανόμενη τάση πολλών ευρωπαϊκών κυβερνήσεων να αποκτήσουν μεγαλύτερο έλεγχο πάνω στις ψηφιακές τους υποδομές και στα δεδομένα τους.
Ο Alexander Barclay, επικεφαλής Μετασχηματισμού και Διαλειτουργικότητας της Ελβετικής Ομοσπονδιακής Διοίκησης, εξηγεί ότι η ψηφιακή κυριαρχία σημαίνει πως «η ομοσπονδιακή κυβέρνηση μπορεί να εκπληρώνει την αποστολή της χωρίς να εξαρτάται από έναν εξωτερικό προμηθευτή ή μια άλλη χώρα». Σύμφωνα με τον ίδιο, η έννοια αυτή δεν αποτελεί έναν τελικό στόχο, αλλά μια διαρκή διαδικασία δημιουργίας βιώσιμων και ασφαλών λύσεων για το δημόσιο.
Ο ρόλος του λογισμικού ανοιχτού κώδικα
Το λογισμικό ανοιχτού κώδικα βρίσκεται στο επίκεντρο αυτής της στρατηγικής. Η πρόσβαση στον πηγαίο κώδικα επιτρέπει στις κρατικές υπηρεσίες να διατηρούν και να εξελίσσουν τα συστήματά τους ακόμη και αν ένας προμηθευτής σταματήσει να τα υποστηρίζει. Όπως επισημαίνει ο Barclay, «όταν έχεις πρόσβαση στον πηγαίο κώδικα, μπορείς να συνεχίσεις να λειτουργείς το σύστημα ακόμη κι αν ο προμηθευτής αποχωρήσει».
Η Ελβετία δεν περιορίζεται μόνο σε θεωρητικές κατευθύνσεις. Αυτή την περίοδο ολοκληρώνει ένα πιλοτικό πρόγραμμα που δοκιμάζει μια λύση ανοιχτού κώδικα ως εναλλακτική σε ιδιόκτητο περιβάλλον εργασίας για περίπου 300 δημόσιους υπαλλήλους.
Τα αποτελέσματα του προγράμματος αναμένεται να παρουσιαστούν μέσα στο καλοκαίρι του 2026 και, εφόσον κριθούν θετικά, η κυβέρνηση σχεδιάζει να επεκτείνει τη χρήση της λύσης σε περίπου 3.000 εργαζόμενους της ομοσπονδιακής διοίκησης.
Στόχος δεν είναι μόνο η μείωση του κόστους αδειών χρήσης λογισμικού, αλλά κυρίως η ενίσχυση της ανθεκτικότητας και της ασφάλειας των δημόσιων ψηφιακών υπηρεσιών. Η ελβετική κυβέρνηση επιθυμεί επίσης να αναπτύξει εσωτερικές τεχνικές δεξιότητες, ώστε οι υπάλληλοι να μπορούν όχι μόνο να χρησιμοποιούν το λογισμικό αλλά και να το διαχειρίζονται, να το προσαρμόζουν και να επιλύουν τεχνικά προβλήματα.
Η ευρωπαϊκή διάσταση
Η Ελβετία δεν είναι η μόνη χώρα που κινείται προς αυτή την κατεύθυνση. Παρακολουθεί στενά αντίστοιχες πρωτοβουλίες σε άλλες ευρωπαϊκές χώρες, όπως τη Γαλλία με το LaSuite, τη Γερμανία με το ZenDis και την Ιταλία με το Developers Italia Catalogue.
Σύμφωνα με τον Barclay, η συνεργασία μεταξύ των δημόσιων διοικήσεων της Ευρώπης είναι κρίσιμη για την επιτυχία τέτοιων στρατηγικών. Όπως χαρακτηριστικά αναφέρει, «δεν πρόκειται για παιχνίδι μηδενικού αθροίσματος — όλοι ωφελούμαστε από αυτή τη συνεργασία».
Η στρατηγική της Ελβετίας αντικατοπτρίζει μια ευρύτερη αλλαγή στον τρόπο με τον οποίο οι κυβερνήσεις αντιλαμβάνονται την τεχνολογία. Η ψηφιακή κυριαρχία, η διαφάνεια, η διαλειτουργικότητα και η ανεξαρτησία από μεγάλους ξένους προμηθευτές μετατρέπονται πλέον σε βασικές προτεραιότητες για το δημόσιο τομέα.
Η ΤΝ δεν μειώνει την ανάγκη κατανόησης. Την αυξάνει
Η χρήση της Τεχνητής Νοημοσύνης στον προγραμματισμό έχει ήδη αλλάξει τον τρόπο με τον οποίο γράφεται λογισμικό. Από την αυτόματη συμπλήρωση στον επεξεργαστή κώδικα μέχρι τους αυτόνομους πράκτορες που μπορούν να ανοίγουν αιτήματα αλλαγών, να τροποποιούν αρχεία και να προτείνουν διορθώσεις, οι προγραμματιστές εργάζονται πια μαζί με συστήματα που παράγουν κώδικα γρήγορα, πειστικά και συχνά εντυπωσιακά. Το κρίσιμο πρόβλημα όμως δεν είναι ότι η ΤΝ κάνει λάθη. Όλοι οι προγραμματιστές κάνουν λάθη. Το πρόβλημα είναι ότι η ΤΝ παράγει λάθη που μοιάζουν σωστά.
Στον παραδοσιακό προγραμματισμό υπάρχει ένα φυσικό όριο ασφαλείας. Αν ένας προγραμματιστής δεν κατανοεί τον κώδικα, δύσκολα μπορεί να τον αλλάξει με ουσιαστικό τρόπο. Θα κολλήσει, θα χρειαστεί να διαβάσει την αρχιτεκτονική, να τρέξει δοκιμές, να ρωτήσει συναδέλφους, να ξαναχτίσει στο μυαλό του το μοντέλο του συστήματος. Η ίδια η δυσκολία της εργασίας τον αναγκάζει να καταλάβει πριν παρέμβει. Με την ΤΝ αυτό το όριο χαλαρώνει. Ένας βοηθός μπορεί να παραγάγει μια αλλαγή που περνά τις αυτόματες δοκιμές, φαίνεται καθαρή, χρησιμοποιεί σωστά ονόματα μεταβλητών και ακολουθεί το ύφος του έργου. Ο άνθρωπος τότε δεν κρίνει μόνο τον κώδικα. Κρίνει και την ίδια του την κατανόηση για τον κώδικα.
Εδώ μπαίνει η ικανότητα να ξέρουμε τι ξέρουμε και τι δεν ξέρουμε. Στην ανασκόπηση κώδικα δεν αρκεί να διαβάζουμε μια αλλαγή. Πρέπει να μπορούμε να απαντήσουμε: καταλαβαίνω πραγματικά τη ροή δεδομένων; Καταλαβαίνω τις συνέπειες για την ασφάλεια; Έχω ελέγξει τις οριακές περιπτώσεις; Ξέρω τι δε δοκιμάστηκε; Μπορώ να εξηγήσω γιατί αυτή η λύση είναι σωστή και όχι απλώς γιατί φαίνεται καλογραμμένη;
Οι γνωστικές παγίδες του AI-assisted coding
Η πρώτη παγίδα είναι η υπερβολική αυτοπεποίθηση. Οι λιγότερο έμπειροι προγραμματιστές είναι συχνά πιο ευάλωτοι, όχι επειδή είναι λιγότερο ικανοί ως άνθρωποι, αλλά επειδή η ίδια γνώση που χρειάζεται για να εντοπίσεις ένα λάθος είναι συχνά η γνώση που χρειάζεται και για να καταλάβεις ότι μπορεί να υπάρχει λάθος. Ένας νέος προγραμματιστής μπορεί να αποδεχθεί μια πρόταση ΤΝ για χειρισμό ταυτοποίησης χρήστη χωρίς να αντιληφθεί ότι λείπει έλεγχος εξουσιοδότησης. Μπορεί να δεχθεί μια βελτιστοποίηση βάσης δεδομένων χωρίς να δει ότι ανοίγει δρόμο για έγχυση SQL. Μπορεί να χαρεί με μια κομψή συνάρτηση συγχρονισμού χωρίς να διακρίνει ότι σε περιβάλλον πολλών νημάτων δημιουργεί συνθήκη ανταγωνισμού.
Η δεύτερη παγίδα είναι η ψευδαίσθηση βάθους εξήγησης. Πολλοί νομίζουμε ότι καταλαβαίνουμε ένα σύστημα μέχρι να μας ζητηθεί να το εξηγήσουμε βήμα προς βήμα. Στον κώδικα αυτό είναι καταστροφικό. Δεν αρκεί να αναγνωρίζουμε ονόματα συναρτήσεων ή μοτίβα σχεδίασης. Πρέπει να μπορούμε να εξηγήσουμε πώς ταξιδεύει η πληροφορία, πού ελέγχεται, πού αποθηκεύεται, πού μπορεί να διαρρεύσει, πού μπορεί να αλλοιωθεί και τι γίνεται όταν κάτι αποτύχει.
Η τρίτη παγίδα είναι η προκατάληψη υπέρ του αυτοματισμού. Όταν ένα εργαλείο παράγει απάντηση με αυτοπεποίθηση, οι άνθρωποι τείνουν να μειώνουν τη δική τους προσπάθεια επαλήθευσης. Στον προγραμματισμό αυτό σημαίνει ότι ο αναγνώστης ενός αιτήματος αλλαγής μπορεί να κοιτάξει την επιτυχία των δοκιμών, το καθαρό ύφος και τη φαινομενική συνέπεια του κώδικα και να πατήσει «έγκριση» χωρίς να έχει ελέγξει την πραγματική συμπεριφορά.
Συγκεκριμένα παραδείγματα κινδύνου
Σε μια εφαρμογή ηλεκτρονικών υπηρεσιών, η ΤΝ μπορεί να προτείνει έναν νέο μηχανισμό προσωρινής αποθήκευσης για να επιταχύνει τα αιτήματα. Ο κώδικας περνά τις δοκιμές απόδοσης, αλλά αποθηκεύει απαντήσεις χωρίς να λαμβάνει υπόψη τον ρόλο του χρήστη. Το αποτέλεσμα μπορεί να είναι διαρροή προσωπικών δεδομένων από έναν χρήστη σε άλλον.
Σε μια εφαρμογή πληρωμών, μπορεί να προταθεί «απλούστευση» του χειρισμού σφαλμάτων. Η αλλαγή κάνει τον κώδικα πιο ευανάγνωστο, αλλά καταπίνει εξαιρέσεις που θα έπρεπε να ακυρώνουν τη συναλλαγή. Το σύστημα φαίνεται σταθερότερο, ενώ στην πραγματικότητα χάνει κρίσιμες ενδείξεις αστοχίας.
Σε μια δημόσια εφαρμογή αιτήσεων, η ΤΝ μπορεί να δημιουργήσει δοκιμές που ελέγχουν αυτό που κάνει ο κώδικας και όχι αυτό που απαιτεί η προδιαγραφή. Έτσι οι δοκιμές δεν λειτουργούν ως ανεξάρτητος έλεγχος. Λειτουργούν ως επιβεβαίωση της ίδιας λανθασμένης υπόθεσης.
Καλές πρακτικές για ασφαλή χρήση
Η πρώτη αρχή είναι ότι κανένας κώδικας που παράγεται από ΤΝ δεν πρέπει να εισάγεται σε κρίσιμο σύστημα χωρίς ανθρώπινη ευθύνη. Ο προγραμματιστής που αποδέχεται τον κώδικα πρέπει να μπορεί να τον εξηγήσει, να τον ελέγξει και να αναλάβει την ευθύνη του. Η ΤΝ μπορεί να είναι βοηθός, όχι συγγραφέας χωρίς λογοδοσία.
Δεύτερον, οι αλλαγές πρέπει να είναι μικρές. Όσο μεγαλύτερο είναι το αίτημα αλλαγής, τόσο δυσκολότερη η ανασκόπηση. Καλύτερα δέκα μικρές αλλαγές με σαφή σκοπό παρά ένα μεγάλο πακέτο που τροποποιεί αρχιτεκτονική, δοκιμές, εξαρτήσεις και τεκμηρίωση ταυτόχρονα.
Τρίτον, η ομάδα πρέπει να απαιτεί εξήγηση πριν από την έγκριση. Κάθε AI-assisted αλλαγή πρέπει να συνοδεύεται από σύντομη τεκμηρίωση: ποιο πρόβλημα λύνει, ποιες παραδοχές κάνει, ποια αρχεία επηρεάζει, ποιες οριακές περιπτώσεις ελέγχθηκαν, ποιοι κίνδυνοι παραμένουν.
Τέταρτον, οι δοκιμές πρέπει να προηγούνται της εμπιστοσύνης. Χρειάζονται μονάδες δοκιμών, δοκιμές ολοκλήρωσης, στατική ανάλυση, έλεγχος εξαρτήσεων, σάρωση για ευπάθειες, fuzzing όπου χρειάζεται, και υποχρεωτική κάλυψη κρίσιμων σεναρίων ασφαλείας.
Πέμπτον, δεν πρέπει να δίνονται στην ΤΝ μυστικά, κλειδιά, προσωπικά δεδομένα ή μη δημοσιευμένος κώδικας χωρίς σαφές νομικό και τεχνικό πλαίσιο. Σε ευαίσθητα έργα, ειδικά στον δημόσιο τομέα, η χρήση τοπικών, ελεγχόμενων και κατά προτίμηση ανοιχτών μοντέλων μειώνει τον κίνδυνο διαρροής και ενισχύει τη δυνατότητα ελέγχου.
Τέλος, η χρήση ΤΝ πρέπει να καταγράφεται. Όχι, για να τιμωρείται ο προγραμματιστής, αλλά για να υπάρχει ιχνηλασιμότητα. Ποιο εργαλείο χρησιμοποιήθηκε; Σε ποιο σημείο; Για ποια αλλαγή; Με ποια ανθρώπινη ανασκόπηση; Το παράδειγμα των μεγάλων έργων ανοιχτού κώδικα είναι καθαρό: η ΤΝ μπορεί να βοηθά, αλλά ο άνθρωπος υπογράφει.
Η ΤΝ μπορεί να αυξήσει την παραγωγικότητα των ομάδων λογισμικού. Μπορεί να βοηθήσει στην κατανόηση παλιού κώδικα, στη δημιουργία δοκιμών, στον εντοπισμό επαναλήψεων και στη συγγραφή τεκμηρίωσης. Αλλά δεν αντικαθιστά την κρίση. Όσο πιο πειστικός γίνεται ο παραγόμενος κώδικας, τόσο πιο αυστηρή πρέπει να γίνεται η ανασκόπηση. Η ασφαλής χρήση της ΤΝ στον προγραμματισμό δεν είναι θέμα ταχύτητας. Είναι θέμα πειθαρχίας, διαφάνειας και ευθύνης.
Πηγές άρθρου:
Diomidis Spinellis, “Why reviewing AI-generated code is devilishly hard”: Το άρθρο τεκμηριώνει γιατί ο κώδικας που παράγεται από ΤΝ απαιτεί αυξημένη προσοχή, συνδέοντας το πρόβλημα με την ψευδαίσθηση κατανόησης, την υπερβολική αυτοπεποίθηση και την προκατάληψη υπέρ του αυτοματισμού: https://www.spinellis.gr/blog/20260523/index.html,
NIST, “Secure Software Development Framework, SP 800-218”: Το πλαίσιο του NIST συγκεντρώνει θεμελιώδεις πρακτικές ασφαλούς ανάπτυξης λογισμικού και είναι χρήσιμο ως βάση για διαδικασίες ελέγχου, επαλήθευσης και ασφαλούς ενσωμάτωσης κώδικα, ανεξάρτητα από το αν ο κώδικας γράφτηκε από άνθρωπο ή με υποβοήθηση ΤΝ: https://nvlpubs.nist.gov/nistpubs/specialpublications/nist.sp.800-218.pdf,
OWASP, “Top 10 for Large Language Model Applications 2025”: Η OWASP καταγράφει κρίσιμους κινδύνους για εφαρμογές που βασίζονται σε μεγάλα γλωσσικά μοντέλα, όπως prompt injection, insecure output handling και supply-chain vulnerabilities, που πρέπει να λαμβάνονται υπόψη και στα εργαλεία προγραμματισμού με ΤΝ: https://owasp.org/www-project-top-10-for-large-language-model-applications/,
GitHub Docs, “Responsible use of GitHub Copilot Chat in GitHub”: Η τεκμηρίωση της GitHub επισημαίνει ότι οι χρήστες πρέπει να είναι ιδιαίτερα προσεκτικοί όταν χρησιμοποιούν το Copilot Chat για παραγωγή κώδικα σε εφαρμογές με απαιτήσεις ασφάλειας και να ελέγχουν και να δοκιμάζουν διεξοδικά τον παραγόμενο κώδικα: https://docs.github.com/en/copilot/responsible-use/chat-in-github,
Pearce, Ahmad, Tan, Dolan-Gavitt, Karri, “Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions”: Η εμπειρική μελέτη εξετάζει περιπτώσεις όπου το GitHub Copilot μπορεί να προτείνει μη ασφαλή κώδικα σε σενάρια υψηλού κινδύνου, ενισχύοντας την ανάγκη για ανεξάρτητο έλεγχο ασφαλείας: https://arxiv.org/abs/2108.09293,
Linux Kernel Documentation, “AI Coding Assistants”: Οι οδηγίες του Linux kernel διατυπώνουν μια ώριμη αρχή διακυβέρνησης: τα εργαλεία ΤΝ μπορούν να βοηθούν, αλλά μόνο άνθρωποι μπορούν να αναλάβουν την ευθύνη, να ελέγξουν τον κώδικα, να διασφαλίσουν τη συμμόρφωση με τις άδειες και να υπογράψουν τη συνεισφορά: https://docs.kernel.org/process/coding-assistants.html .
Η ΤΝ δεν μειώνει την ανάγκη κατανόησης. Την αυξάνει
Η χρήση της Τεχνητής Νοημοσύνης στον προγραμματισμό έχει ήδη αλλάξει τον τρόπο με τον οποίο γράφεται λογισμικό. Από την αυτόματη συμπλήρωση στον επεξεργαστή κώδικα μέχρι τους αυτόνομους πράκτορες που μπορούν να ανοίγουν αιτήματα αλλαγών, να τροποποιούν αρχεία και να προτείνουν διορθώσεις, οι προγραμματιστές εργάζονται πια μαζί με συστήματα που παράγουν κώδικα γρήγορα, πειστικά και συχνά εντυπωσιακά. Το κρίσιμο πρόβλημα όμως δεν είναι ότι η ΤΝ κάνει λάθη. Όλοι οι προγραμματιστές κάνουν λάθη. Το πρόβλημα είναι ότι η ΤΝ παράγει λάθη που μοιάζουν σωστά.
Στον παραδοσιακό προγραμματισμό υπάρχει ένα φυσικό όριο ασφαλείας. Αν ένας προγραμματιστής δεν κατανοεί τον κώδικα, δύσκολα μπορεί να τον αλλάξει με ουσιαστικό τρόπο. Θα κολλήσει, θα χρειαστεί να διαβάσει την αρχιτεκτονική, να τρέξει δοκιμές, να ρωτήσει συναδέλφους, να ξαναχτίσει στο μυαλό του το μοντέλο του συστήματος. Η ίδια η δυσκολία της εργασίας τον αναγκάζει να καταλάβει πριν παρέμβει. Με την ΤΝ αυτό το όριο χαλαρώνει. Ένας βοηθός μπορεί να παραγάγει μια αλλαγή που περνά τις αυτόματες δοκιμές, φαίνεται καθαρή, χρησιμοποιεί σωστά ονόματα μεταβλητών και ακολουθεί το ύφος του έργου. Ο άνθρωπος τότε δεν κρίνει μόνο τον κώδικα. Κρίνει και την ίδια του την κατανόηση για τον κώδικα.
Εδώ μπαίνει η ικανότητα να ξέρουμε τι ξέρουμε και τι δεν ξέρουμε. Στην ανασκόπηση κώδικα δεν αρκεί να διαβάζουμε μια αλλαγή. Πρέπει να μπορούμε να απαντήσουμε: καταλαβαίνω πραγματικά τη ροή δεδομένων; Καταλαβαίνω τις συνέπειες για την ασφάλεια; Έχω ελέγξει τις οριακές περιπτώσεις; Ξέρω τι δε δοκιμάστηκε; Μπορώ να εξηγήσω γιατί αυτή η λύση είναι σωστή και όχι απλώς γιατί φαίνεται καλογραμμένη;
Οι γνωστικές παγίδες του AI-assisted coding
Η πρώτη παγίδα είναι η υπερβολική αυτοπεποίθηση. Οι λιγότερο έμπειροι προγραμματιστές είναι συχνά πιο ευάλωτοι, όχι επειδή είναι λιγότερο ικανοί ως άνθρωποι, αλλά επειδή η ίδια γνώση που χρειάζεται για να εντοπίσεις ένα λάθος είναι συχνά η γνώση που χρειάζεται και για να καταλάβεις ότι μπορεί να υπάρχει λάθος. Ένας νέος προγραμματιστής μπορεί να αποδεχθεί μια πρόταση ΤΝ για χειρισμό ταυτοποίησης χρήστη χωρίς να αντιληφθεί ότι λείπει έλεγχος εξουσιοδότησης. Μπορεί να δεχθεί μια βελτιστοποίηση βάσης δεδομένων χωρίς να δει ότι ανοίγει δρόμο για έγχυση SQL. Μπορεί να χαρεί με μια κομψή συνάρτηση συγχρονισμού χωρίς να διακρίνει ότι σε περιβάλλον πολλών νημάτων δημιουργεί συνθήκη ανταγωνισμού.
Η δεύτερη παγίδα είναι η ψευδαίσθηση βάθους εξήγησης. Πολλοί νομίζουμε ότι καταλαβαίνουμε ένα σύστημα μέχρι να μας ζητηθεί να το εξηγήσουμε βήμα προς βήμα. Στον κώδικα αυτό είναι καταστροφικό. Δεν αρκεί να αναγνωρίζουμε ονόματα συναρτήσεων ή μοτίβα σχεδίασης. Πρέπει να μπορούμε να εξηγήσουμε πώς ταξιδεύει η πληροφορία, πού ελέγχεται, πού αποθηκεύεται, πού μπορεί να διαρρεύσει, πού μπορεί να αλλοιωθεί και τι γίνεται όταν κάτι αποτύχει.
Η τρίτη παγίδα είναι η προκατάληψη υπέρ του αυτοματισμού. Όταν ένα εργαλείο παράγει απάντηση με αυτοπεποίθηση, οι άνθρωποι τείνουν να μειώνουν τη δική τους προσπάθεια επαλήθευσης. Στον προγραμματισμό αυτό σημαίνει ότι ο αναγνώστης ενός αιτήματος αλλαγής μπορεί να κοιτάξει την επιτυχία των δοκιμών, το καθαρό ύφος και τη φαινομενική συνέπεια του κώδικα και να πατήσει «έγκριση» χωρίς να έχει ελέγξει την πραγματική συμπεριφορά.
Συγκεκριμένα παραδείγματα κινδύνου
Σε μια εφαρμογή ηλεκτρονικών υπηρεσιών, η ΤΝ μπορεί να προτείνει έναν νέο μηχανισμό προσωρινής αποθήκευσης για να επιταχύνει τα αιτήματα. Ο κώδικας περνά τις δοκιμές απόδοσης, αλλά αποθηκεύει απαντήσεις χωρίς να λαμβάνει υπόψη τον ρόλο του χρήστη. Το αποτέλεσμα μπορεί να είναι διαρροή προσωπικών δεδομένων από έναν χρήστη σε άλλον.
Σε μια εφαρμογή πληρωμών, μπορεί να προταθεί «απλούστευση» του χειρισμού σφαλμάτων. Η αλλαγή κάνει τον κώδικα πιο ευανάγνωστο, αλλά καταπίνει εξαιρέσεις που θα έπρεπε να ακυρώνουν τη συναλλαγή. Το σύστημα φαίνεται σταθερότερο, ενώ στην πραγματικότητα χάνει κρίσιμες ενδείξεις αστοχίας.
Σε μια δημόσια εφαρμογή αιτήσεων, η ΤΝ μπορεί να δημιουργήσει δοκιμές που ελέγχουν αυτό που κάνει ο κώδικας και όχι αυτό που απαιτεί η προδιαγραφή. Έτσι οι δοκιμές δεν λειτουργούν ως ανεξάρτητος έλεγχος. Λειτουργούν ως επιβεβαίωση της ίδιας λανθασμένης υπόθεσης.
Καλές πρακτικές για ασφαλή χρήση
Η πρώτη αρχή είναι ότι κανένας κώδικας που παράγεται από ΤΝ δεν πρέπει να εισάγεται σε κρίσιμο σύστημα χωρίς ανθρώπινη ευθύνη. Ο προγραμματιστής που αποδέχεται τον κώδικα πρέπει να μπορεί να τον εξηγήσει, να τον ελέγξει και να αναλάβει την ευθύνη του. Η ΤΝ μπορεί να είναι βοηθός, όχι συγγραφέας χωρίς λογοδοσία.
Δεύτερον, οι αλλαγές πρέπει να είναι μικρές. Όσο μεγαλύτερο είναι το αίτημα αλλαγής, τόσο δυσκολότερη η ανασκόπηση. Καλύτερα δέκα μικρές αλλαγές με σαφή σκοπό παρά ένα μεγάλο πακέτο που τροποποιεί αρχιτεκτονική, δοκιμές, εξαρτήσεις και τεκμηρίωση ταυτόχρονα.
Τρίτον, η ομάδα πρέπει να απαιτεί εξήγηση πριν από την έγκριση. Κάθε AI-assisted αλλαγή πρέπει να συνοδεύεται από σύντομη τεκμηρίωση: ποιο πρόβλημα λύνει, ποιες παραδοχές κάνει, ποια αρχεία επηρεάζει, ποιες οριακές περιπτώσεις ελέγχθηκαν, ποιοι κίνδυνοι παραμένουν.
Τέταρτον, οι δοκιμές πρέπει να προηγούνται της εμπιστοσύνης. Χρειάζονται μονάδες δοκιμών, δοκιμές ολοκλήρωσης, στατική ανάλυση, έλεγχος εξαρτήσεων, σάρωση για ευπάθειες, fuzzing όπου χρειάζεται, και υποχρεωτική κάλυψη κρίσιμων σεναρίων ασφαλείας.
Πέμπτον, δεν πρέπει να δίνονται στην ΤΝ μυστικά, κλειδιά, προσωπικά δεδομένα ή μη δημοσιευμένος κώδικας χωρίς σαφές νομικό και τεχνικό πλαίσιο. Σε ευαίσθητα έργα, ειδικά στον δημόσιο τομέα, η χρήση τοπικών, ελεγχόμενων και κατά προτίμηση ανοιχτών μοντέλων μειώνει τον κίνδυνο διαρροής και ενισχύει τη δυνατότητα ελέγχου.
Τέλος, η χρήση ΤΝ πρέπει να καταγράφεται. Όχι, για να τιμωρείται ο προγραμματιστής, αλλά για να υπάρχει ιχνηλασιμότητα. Ποιο εργαλείο χρησιμοποιήθηκε; Σε ποιο σημείο; Για ποια αλλαγή; Με ποια ανθρώπινη ανασκόπηση; Το παράδειγμα των μεγάλων έργων ανοιχτού κώδικα είναι καθαρό: η ΤΝ μπορεί να βοηθά, αλλά ο άνθρωπος υπογράφει.
Η ΤΝ μπορεί να αυξήσει την παραγωγικότητα των ομάδων λογισμικού. Μπορεί να βοηθήσει στην κατανόηση παλιού κώδικα, στη δημιουργία δοκιμών, στον εντοπισμό επαναλήψεων και στη συγγραφή τεκμηρίωσης. Αλλά δεν αντικαθιστά την κρίση. Όσο πιο πειστικός γίνεται ο παραγόμενος κώδικας, τόσο πιο αυστηρή πρέπει να γίνεται η ανασκόπηση. Η ασφαλής χρήση της ΤΝ στον προγραμματισμό δεν είναι θέμα ταχύτητας. Είναι θέμα πειθαρχίας, διαφάνειας και ευθύνης.
Από τον ΦΑΡΟ στα τοπικά μοντέλα: μια πολυεπίπεδη αρχιτεκτονική ανοιχτής ΤΝ
Η σωστή στρατηγική για την Τεχνητή Νοημοσύνη δεν είναι να επιλεγεί μία και μοναδική τεχνολογική λύση. Δεν χρειάζεται όλα να τρέχουν σε υπερυπολογιστές, όπως δεν είναι λογικό κάθε δημόσιος φορέας, πανεπιστήμιο, σχολείο ή επιχείρηση να εξαρτάται από εμπορικά cloud API. Η ορθολογική προσέγγιση είναι πολυεπίπεδη: εθνικές υποδομές υψηλής υπολογιστικής ισχύος για τα βαριά φορτία, τοπικές ανοιχτές υποδομές για καθημερινή ασφαλή χρήση και εναλλακτικές πλατφόρμες υλικού ώστε να μη δημιουργηθεί νέος τεχνολογικός εγκλωβισμός.
Ο ΦΑΡΟΣ και ο Δαίδαλος ανήκουν στο πρώτο επίπεδο. Είναι η εθνική υποδομή που πρέπει να αξιοποιείται για εργασίες μεγάλης κλίμακας: εκπαίδευση ή σοβαρή προσαρμογή μεγάλων μοντέλων, αξιολόγηση ελληνικών γλωσσικών μοντέλων, δημιουργία και έλεγχο συνόλων δεδομένων υψηλής ποιότητας, επιστημονικές προσομοιώσεις, εφαρμογές σε υγεία, πολιτισμό, κλίμα και βιωσιμότητα, καθώς και υποστήριξη ερευνητικών ομάδων και νεοφυών επιχειρήσεων που χρειάζονται υπολογιστική ισχύ πέρα από τις δυνατότητες ενός μεμονωμένου οργανισμού. Αυτό είναι το πεδίο του υπερυπολογιστή: δημιουργεί, ελέγχει, συγκρίνει και βελτιώνει.
Το δεύτερο επίπεδο είναι τα τοπικά μοντέλα ΤΝ ανοιχτού λογισμικού. Εδώ το ζητούμενο δεν είναι να εκπαιδευτεί από την αρχή ένα τεράστιο μοντέλο, αλλά να λειτουργεί καθημερινά μια ασφαλής, οικονομική και ελέγξιμη υπηρεσία ΤΝ κοντά στα δεδομένα. Ένα τέτοιο πιλοτικό μπορεί να βασίζεται, για παράδειγμα, σε δύο Apple Mac Studio M3 Ultra με 256 GB ενοποιημένης μνήμης και δύο NVIDIA DGX Spark GB10 με 128 GB ενοποιημένης μνήμης, 4 TB NVMe αποθήκευση ανά κόμβο και υποστήριξη Metal, CUDA, llama.cpp, vLLM και TensorRT-LLM. Οι Apple κόμβοι είναι κατάλληλοι για χαμηλής κατανάλωσης συνεχή λειτουργία, μικρά και μεσαία μοντέλα, embeddings, αναζήτηση σε έγγραφα, σύνοψη, απομαγνητοφώνηση και εφαρμογές με αυστηρές απαιτήσεις ιδιωτικότητας. Οι NVIDIA κόμβοι καλύπτουν βαρύτερο inference, μεγαλύτερα μοντέλα, batch processing και πειραματισμό με πιο απαιτητικές ροές.
Το τρίτο επίπεδο, που αποκτά πλέον ιδιαίτερη σημασία, είναι το AMD/ROCm οικοσύστημα. Η AMD προσφέρει εναλλακτική διαδρομή για low-cost open LLMs, τόσο σε υπολογιστικά κέντρα όσο και σε τοπικές εγκαταστάσεις. Στο επίπεδο των data centers, οι AMD Instinct MI300X, MI325X και MI350 είναι ενδιαφέρουσες κυρίως λόγω της πολύ μεγάλης μνήμης ανά επιταχυντή: 192 GB HBM3 στην MI300X, 256 GB HBM3E στην MI325X και έως 288 GB HBM3E στη σειρά MI350. Για μεγάλα ανοιχτά μοντέλα, η μνήμη είναι κρίσιμος παράγοντας κόστους. Όταν περισσότερες παράμετροι χωρούν σε μία ή σε λιγότερες GPU, μειώνονται η πολυπλοκότητα, οι απαιτήσεις διασύνδεσης, η κατανάλωση και το συνολικό κόστος κτήσης.
Η αξία του AMD οικοσυστήματος δεν βρίσκεται μόνο στο υλικό. Βρίσκεται και στο ROCm, την ανοιχτή στοίβα λογισμικού της AMD για επιτάχυνση υπολογισμών ΤΝ και HPC. Η τεκμηρίωση του ROCm αναφέρει πλέον υποστήριξη για βασικές μηχανές serving μεγάλων γλωσσικών μοντέλων, όπως vLLM και Hugging Face Text Generation Inference. Παράλληλα, εργαλεία όπως το llama.cpp, το Ollama, το Vulkan και το HIP/ROCm επιτρέπουν ετερογενείς εγκαταστάσεις, όπου διαφορετικό υλικό μπορεί να αξιοποιείται ανάλογα με το φορτίο εργασίας. Αυτό είναι σημαντικό για φορείς που δεν θέλουν να δεσμευτούν σε μία προμηθευτική αλυσίδα.
Στην πράξη, μια ώριμη στρατηγική για low-cost open LLMs δεν πρέπει να είναι «NVIDIA ή AMD», «Apple ή data center», «ΦΑΡΟΣ ή τοπικός κόμβος». Πρέπει να είναι συνδυαστική. Ο ΦΑΡΟΣ και ο Δαίδαλος χρησιμοποιούνται για βαριά εκπαίδευση, αξιολόγηση και εθνικές υποδομές μοντέλων. Οι τοπικοί κόμβοι NVIDIA και Apple χρησιμοποιούνται για άμεσο, αξιόπιστο και ασφαλές inference μέσα σε οργανισμούς. Οι λύσεις AMD/ROCm προσθέτουν ανταγωνισμό, μεγάλη μνήμη ανά GPU, δυνατότητα χαμηλότερου κόστους και εναλλακτικό ανοιχτό οικοσύστημα λογισμικού.
Αυτό έχει ιδιαίτερη σημασία για το Δημόσιο, τις επιχειρήσεις και την εκπαίδευση. Ένας δήμος, ένα πανεπιστήμιο ή ένα νοσοκομείο μπορεί να χρησιμοποιεί τοπικά μοντέλα για καθημερινές εργασίες, όπως αναζήτηση σε κανονισμούς, σύνοψη εγγράφων, ταξινόμηση αιτημάτων, υποστήριξη χρηστών και ασφαλή πρόσβαση σε εσωτερική γνώση. Ένα υπουργείο ή ερευνητικό κέντρο μπορεί να απευθύνεται στον ΦΑΡΟ για μεγαλύτερα πειράματα και αξιολογήσεις. Μια μικρομεσαία επιχείρηση μπορεί να ξεκινά με workstation ή μικρό τοπικό κόμβο και να κλιμακώνει αργότερα σε υπολογιστικό κέντρο. Το κρίσιμο είναι η αρχιτεκτονική να βασίζεται σε ανοιχτά πρότυπα, ανοιχτά μοντέλα όπου είναι εφικτό, εναλλάξιμα backends και δημόσια ελεγχόμενη διακυβέρνηση.
Έτσι αποφεύγονται δύο λάθη. Το πρώτο είναι η ψευδαίσθηση ότι όλα πρέπει να λυθούν με ένα κεντρικό υπερσύστημα. Το δεύτερο είναι η εξάρτηση από χιλιάδες ασύνδετες μικρές λύσεις χωρίς κοινά πρότυπα, ασφάλεια και αξιολόγηση. Η δημοκρατική τεχνητή νοημοσύνη χρειάζεται κεντρική ισχύ όπου είναι απαραίτητη, τοπικό έλεγχο όπου είναι κρίσιμος, και ανοιχτό οικοσύστημα υλικού και λογισμικού ώστε το δημόσιο χρήμα να χτίζει δημόσια τεχνογνωσία.
Here’s the thing: when working on code with GenAI assistance
(from a chat-bot, through IDE auto-completion, or, increasingly,
with an AI agent)
you need a better understanding of the system than when working without.
Cognitive psychology and the workings of large language models (LLMs)
give us four clues on why this happens.
Από τον ΦΑΡΟ στα τοπικά μοντέλα: μια πολυεπίπεδη αρχιτεκτονική ανοιχτής ΤΝ
Η σωστή στρατηγική για την Τεχνητή Νοημοσύνη δεν είναι να επιλεγεί μία και μοναδική τεχνολογική λύση. Δεν χρειάζεται όλα να τρέχουν σε υπερυπολογιστές, όπως δεν είναι λογικό κάθε δημόσιος φορέας, πανεπιστήμιο, σχολείο ή επιχείρηση να εξαρτάται από εμπορικά cloud API. Η ορθολογική προσέγγιση είναι πολυεπίπεδη: εθνικές υποδομές υψηλής υπολογιστικής ισχύος για τα βαριά φορτία, τοπικές ανοιχτές υποδομές για καθημερινή ασφαλή χρήση και εναλλακτικές πλατφόρμες υλικού ώστε να μη δημιουργηθεί νέος τεχνολογικός εγκλωβισμός.
Ο ΦΑΡΟΣ και ο Δαίδαλος ανήκουν στο πρώτο επίπεδο. Είναι η εθνική υποδομή που πρέπει να αξιοποιείται για εργασίες μεγάλης κλίμακας: εκπαίδευση ή σοβαρή προσαρμογή μεγάλων μοντέλων, αξιολόγηση ελληνικών γλωσσικών μοντέλων, δημιουργία και έλεγχο συνόλων δεδομένων υψηλής ποιότητας, επιστημονικές προσομοιώσεις, εφαρμογές σε υγεία, πολιτισμό, κλίμα και βιωσιμότητα, καθώς και υποστήριξη ερευνητικών ομάδων και νεοφυών επιχειρήσεων που χρειάζονται υπολογιστική ισχύ πέρα από τις δυνατότητες ενός μεμονωμένου οργανισμού. Αυτό είναι το πεδίο του υπερυπολογιστή: δημιουργεί, ελέγχει, συγκρίνει και βελτιώνει.
Το δεύτερο επίπεδο είναι τα τοπικά μοντέλα ΤΝ ανοιχτού λογισμικού. Εδώ το ζητούμενο δεν είναι να εκπαιδευτεί από την αρχή ένα τεράστιο μοντέλο, αλλά να λειτουργεί καθημερινά μια ασφαλής, οικονομική και ελέγξιμη υπηρεσία ΤΝ κοντά στα δεδομένα. Ένα τέτοιο πιλοτικό μπορεί να βασίζεται, για παράδειγμα, σε δύο Apple Mac Studio M3 Ultra με 256 GB ενοποιημένης μνήμης και δύο NVIDIA DGX Spark GB10 με 128 GB ενοποιημένης μνήμης, 4 TB NVMe αποθήκευση ανά κόμβο και υποστήριξη Metal, CUDA, llama.cpp, vLLM και TensorRT-LLM. Οι Apple κόμβοι είναι κατάλληλοι για χαμηλής κατανάλωσης συνεχή λειτουργία, μικρά και μεσαία μοντέλα, embeddings, αναζήτηση σε έγγραφα, σύνοψη, απομαγνητοφώνηση και εφαρμογές με αυστηρές απαιτήσεις ιδιωτικότητας. Οι NVIDIA κόμβοι καλύπτουν βαρύτερο inference, μεγαλύτερα μοντέλα, batch processing και πειραματισμό με πιο απαιτητικές ροές.
Το τρίτο επίπεδο, που αποκτά πλέον ιδιαίτερη σημασία, είναι το AMD/ROCm οικοσύστημα. Η AMD προσφέρει εναλλακτική διαδρομή για low-cost open LLMs, τόσο σε υπολογιστικά κέντρα όσο και σε τοπικές εγκαταστάσεις. Στο επίπεδο των data centers, οι AMD Instinct MI300X, MI325X και MI350 είναι ενδιαφέρουσες κυρίως λόγω της πολύ μεγάλης μνήμης ανά επιταχυντή: 192 GB HBM3 στην MI300X, 256 GB HBM3E στην MI325X και έως 288 GB HBM3E στη σειρά MI350. Για μεγάλα ανοιχτά μοντέλα, η μνήμη είναι κρίσιμος παράγοντας κόστους. Όταν περισσότερες παράμετροι χωρούν σε μία ή σε λιγότερες GPU, μειώνονται η πολυπλοκότητα, οι απαιτήσεις διασύνδεσης, η κατανάλωση και το συνολικό κόστος κτήσης.
Η αξία του AMD οικοσυστήματος δεν βρίσκεται μόνο στο υλικό. Βρίσκεται και στο ROCm, την ανοιχτή στοίβα λογισμικού της AMD για επιτάχυνση υπολογισμών ΤΝ και HPC. Η τεκμηρίωση του ROCm αναφέρει πλέον υποστήριξη για βασικές μηχανές serving μεγάλων γλωσσικών μοντέλων, όπως vLLM και Hugging Face Text Generation Inference. Παράλληλα, εργαλεία όπως το llama.cpp, το Ollama, το Vulkan και το HIP/ROCm επιτρέπουν ετερογενείς εγκαταστάσεις, όπου διαφορετικό υλικό μπορεί να αξιοποιείται ανάλογα με το φορτίο εργασίας. Αυτό είναι σημαντικό για φορείς που δεν θέλουν να δεσμευτούν σε μία προμηθευτική αλυσίδα.
Στην πράξη, μια ώριμη στρατηγική για low-cost open LLMs δεν πρέπει να είναι «NVIDIA ή AMD», «Apple ή data center», «ΦΑΡΟΣ ή τοπικός κόμβος». Πρέπει να είναι συνδυαστική. Ο ΦΑΡΟΣ και ο Δαίδαλος χρησιμοποιούνται για βαριά εκπαίδευση, αξιολόγηση και εθνικές υποδομές μοντέλων. Οι τοπικοί κόμβοι NVIDIA και Apple χρησιμοποιούνται για άμεσο, αξιόπιστο και ασφαλές inference μέσα σε οργανισμούς. Οι λύσεις AMD/ROCm προσθέτουν ανταγωνισμό, μεγάλη μνήμη ανά GPU, δυνατότητα χαμηλότερου κόστους και εναλλακτικό ανοιχτό οικοσύστημα λογισμικού.
Αυτό έχει ιδιαίτερη σημασία για το Δημόσιο, τις επιχειρήσεις και την εκπαίδευση. Ένας δήμος, ένα πανεπιστήμιο ή ένα νοσοκομείο μπορεί να χρησιμοποιεί τοπικά μοντέλα για καθημερινές εργασίες, όπως αναζήτηση σε κανονισμούς, σύνοψη εγγράφων, ταξινόμηση αιτημάτων, υποστήριξη χρηστών και ασφαλή πρόσβαση σε εσωτερική γνώση. Ένα υπουργείο ή ερευνητικό κέντρο μπορεί να απευθύνεται στον ΦΑΡΟ για μεγαλύτερα πειράματα και αξιολογήσεις. Μια μικρομεσαία επιχείρηση μπορεί να ξεκινά με workstation ή μικρό τοπικό κόμβο και να κλιμακώνει αργότερα σε υπολογιστικό κέντρο. Το κρίσιμο είναι η αρχιτεκτονική να βασίζεται σε ανοιχτά πρότυπα, ανοιχτά μοντέλα όπου είναι εφικτό, εναλλάξιμα backends και δημόσια ελεγχόμενη διακυβέρνηση.
Έτσι αποφεύγονται δύο λάθη. Το πρώτο είναι η ψευδαίσθηση ότι όλα πρέπει να λυθούν με ένα κεντρικό υπερσύστημα. Το δεύτερο είναι η εξάρτηση από χιλιάδες ασύνδετες μικρές λύσεις χωρίς κοινά πρότυπα, ασφάλεια και αξιολόγηση. Η δημοκρατική τεχνητή νοημοσύνη χρειάζεται κεντρική ισχύ όπου είναι απαραίτητη, τοπικό έλεγχο όπου είναι κρίσιμος, και ανοιχτό οικοσύστημα υλικού και λογισμικού ώστε το δημόσιο χρήμα να χτίζει δημόσια τεχνογνωσία.
Πηγές άρθρου:
GRNET, Pharos: The Greek AI Factory: Η επίσημη περιγραφή του ελληνικού εργοστασίου ΤΝ, με στόχο τη σύνδεση υπερυπολογιστικής ισχύος, έρευνας, δημόσιου τομέα, επιχειρήσεων και κρίσιμων πεδίων όπως υγεία, γλώσσα, πολιτισμός και βιωσιμότητα: https://grnet.gr/business-directory/Pharos-AI-Factory/,
Apple, Mac Studio Technical Specifications: Η επίσημη τεχνική σελίδα της Apple τεκμηριώνει ότι το Mac Studio με M3 Ultra μπορεί να διαμορφωθεί με 32-core CPU, 80-core GPU, 32-core Neural Engine, 256 GB ενοποιημένης μνήμης και SSD έως 16 TB, χαρακτηριστικά κρίσιμα για τοπικό inference και μεγάλα quantized μοντέλα: https://support.apple.com/en-us/122211/,
Apple, Mac Studio Specs: Η επίσημη σελίδα προϊόντος της Apple αναφέρει επίσης το εύρος ζώνης μνήμης των 819 GB/s για το M3 Ultra, στοιχείο σημαντικό για workloads ΤΝ που αξιοποιούν την ενοποιημένη μνήμη Apple Silicon: https://www.apple.com/mac-studio/specs/,
Apple Developer, Accelerated PyTorch training on Mac: Η τεκμηρίωση της Apple δείχνει ότι το PyTorch μπορεί να επιταχυνθεί σε Mac μέσω Metal Performance Shaders, άρα το Apple Silicon μπορεί να αξιοποιηθεί όχι μόνο για γενική χρήση αλλά και για επιταχυνόμενες ροές μηχανικής μάθησης: https://developer.apple.com/metal/pytorch/,
Apple Machine Learning Research, MLX: Το MLX είναι πλαίσιο μηχανικής μάθησης για Apple Silicon, βελτιστοποιημένο για την ενοποιημένη μνήμη, και αποτελεί βασική πηγή για την τεκμηρίωση του οικοσυστήματος Apple σε τοπική ΤΝ: https://opensource.apple.com/projects/mlx,
AMD ROCm Documentation, Deploying your model: Η τεκμηρίωση του ROCm αναφέρει ρητά υποστήριξη vLLM και Hugging Face Text Generation Inference για serving μεγάλων γλωσσικών μοντέλων σε AMD GPUs, άρα αποτελεί την πιο σημαντική πηγή για το λογισμικό σκέλος των low-cost open LLMs σε AMD: https://rocm.docs.amd.com/en/docs-7.0.0/how-to/rocm-for-ai/inference/deploy-your-model.html,
AMD Instinct MI300X: Η επίσημη σελίδα της AMD τεκμηριώνει την MI300X ως επιταχυντή για Generative AI και HPC, με 192 GB HBM3 μνήμης και 5,325 TB/s θεωρητικό εύρος ζώνης μνήμης, χαρακτηριστικά κρίσιμα για μεγάλα ανοιχτά μοντέλα: https://www.amd.com/en/products/accelerators/instinct/mi300/mi300x.html,
AMD ROCm on Radeon and Ryzen: Η τεκμηρίωση για Radeon και Ryzen δείχνει ότι το ROCm δεν αφορά μόνο data centers, αλλά και client/edge περιβάλλοντα, με υποστήριξη εργαλείων όπως PyTorch, TensorFlow, vLLM και llama.cpp: https://rocm.docs.amd.com/projects/radeon-ryzen/en/latest/index.html,
Unsloth, Fine-tuning LLMs on AMD GPUs: Η τεκμηρίωση του Unsloth αναφέρει υποστήριξη AMD GPUs, συμπεριλαμβανομένων Radeon RX και MI300X, για τοπικό fine-tuning μεγάλων γλωσσικών μοντέλων χαμηλού κόστους: https://unsloth.ai/docs/get-started/install/amd,
llama.cpp, Build documentation: Η τεκμηρίωση του llama.cpp αναφέρει υποστήριξη πολλών backends, μεταξύ των οποίων Metal, CUDA, HIP και Vulkan, καθιστώντας το κρίσιμο εργαλείο για ετερογενείς τοπικές υποδομές ΤΝ με Apple, NVIDIA και AMD: https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md.
Καθώς η Ευρώπη προχωρά δυναμικά προς μια οικονομία που βασίζεται ολοένα και περισσότερο στα δεδομένα, η ανάγκη για ασφαλή, αξιόπιστη και δίκαιη ανταλλαγή πληροφοριών γίνεται πιο σημαντική από ποτέ. Τομείς όπως η υγεία, οι μεταφορές, η ενέργεια, ο πολιτισμός και η βιομηχανία παράγουν καθημερινά τεράστιες ποσότητες δεδομένων, οι οποίες μπορούν να αξιοποιηθούν αποτελεσματικά μόνο μέσα ... Read more
Τι συμβαίνει όταν τρεις ευρωπαϊκές δημόσιες διοικήσεις αποφασίζουν να περάσουν από την απλή συνεργασία στη συν-ανάπτυξη ψηφιακών εργαλείων; Από το 2023, η Γαλλία, η Γερμανία και η Ολλανδία επιχειρούν να δώσουν μια πρακτική απάντηση σε αυτό το ερώτημα, χτίζοντας από κοινού λογισμικό ανοικτού κώδικα για τον δημόσιο τομέα.
Η πρωτοβουλία ξεκίνησε από τη γαλλική DINUM (Interministerial Directorate for Digital Affairs), η οποία είχε ως βασικό στόχο να εξοπλίσει τους δημόσιους υπαλλήλους με ψηφιακά εργαλεία που να είναι ανοιχτά, αποδοτικά και τεχνολογικά «κυρίαρχα». Πολύ γρήγορα, όμως, οι υπεύθυνοι του προγράμματος συνειδητοποίησαν ότι οι ανάγκες αυτές δεν περιορίζονται μόνο στη Γαλλία.
Η λογική ήταν απλή: αν τα ίδια ψηφιακά εργαλεία χρειάζονται στη Γαλλία, τότε πιθανότατα χρειάζονται και σε άλλες ευρωπαϊκές χώρες. Γιατί, λοιπόν, κάθε κράτος να αναπτύσσει από την αρχή τα ίδια συστήματα;
Από το όραμα στη συνεργασία
Το πρώτο βήμα ήταν η αναζήτηση συνεργατών με κοινές αξίες και παρόμοιες προκλήσεις. Δεν αρκούσαν μόνο πολιτικές δηλώσεις ή συμφωνίες πρόθεσης· χρειαζόταν πραγματική δέσμευση από ομάδες προγραμματιστών, σχεδιαστών, product managers και δημόσιων λειτουργών.
Η Γερμανία προσχώρησε στην πρωτοβουλία το 2024 και η Ολλανδία ακολούθησε το 2025. Παράλληλα, δημιουργήθηκε ένα μικτό μοντέλο χρηματοδότησης που βασίζεται τόσο στους εθνικούς προϋπολογισμούς των κρατικών φορέων όσο και σε ευρωπαϊκά κονδύλια με τη στήριξη της Ευρωπαϊκής Επιτροπής.
Ωστόσο, η πραγματική πρόκληση δεν ήταν μόνο η χρηματοδότηση ή η πολιτική συμφωνία, αλλά το πώς διαφορετικές δημόσιες διοικήσεις θα μπορούσαν να συνεργαστούν αποτελεσματικά στην πράξη.
Hackathons αντί για ατελείωτες συσκέψεις
Για να επιταχυνθεί η συνεργασία, οι συμμετέχοντες επέλεξαν ένα μοντέλο εργασίας βασισμένο στα hackathons. Η εμπειρία έδειξε ότι οι ομάδες αποδίδουν πολύ περισσότερο όταν εργάζονται φυσικά στον ίδιο χώρο, αντί να βασίζονται αποκλειστικά σε τηλεδιασκέψεις και ασύγχρονη επικοινωνία.
Χαρακτηριστικό παράδειγμα ήταν το “Hack Days” που διοργανώθηκε στο Παρίσι το 2025. Εκεί, 53 ομάδες από 17 χώρες συνεργάστηκαν επί τρεις ημέρες για να βελτιώσουν υπάρχοντα εργαλεία της πλατφόρμας LaSuite και να αναπτύξουν νέες λειτουργίες.
Το μοντέλο εργασίας οργανώθηκε γύρω από τους λεγόμενους «κύκλους 100 ημερών». Σε κάθε κύκλο τίθενται συγκεκριμένοι στόχοι και τρεις μήνες αργότερα οι ομάδες παρουσιάζουν τα αποτελέσματα. Αυτή η διαδικασία ενθαρρύνει τη γρήγορη παράδοση λειτουργικών λύσεων και αποφεύγει τη γραφειοκρατική στασιμότητα που συχνά χαρακτηρίζει διακρατικά έργα.
Το παράδειγμα του LaSuite Docs
Ένα από τα σημαντικότερα παραδείγματα αυτής της συνεργασίας είναι το LaSuite Docs, ένας συνεργατικός επεξεργαστής κειμένου που αναπτύχθηκε από κοινού από τις τρεις χώρες.
Η βασική ιδέα ήταν να δημιουργηθεί μια κοινή τεχνική βάση πάνω στην οποία κάθε χώρα θα μπορούσε να προσαρμόζει το εργαλείο στις δικές της ανάγκες. Έτσι, Γάλλοι, Γερμανοί και Ολλανδοί δημόσιοι υπάλληλοι χρησιμοποιούν διαφορετικές εκδόσεις του ίδιου συστήματος, με κοινό όμως πυρήνα.
Παρά την επιτυχία, το έργο αντιμετωπίζει και τεχνικές δυσκολίες. Οι διαφορετικές τοπικές προσαρμογές έχουν δημιουργήσει αποκλίσεις στον κώδικα, γεγονός που καθιστά δύσκολη τη διατήρηση μιας ενιαίας πλατφόρμας. Η επιστροφή σε μια πιο «καθαρή» κοινή βάση αποτελεί σήμερα έναν από τους βασικούς στόχους των ομάδων ανάπτυξης.
Οι πολιτισμικές διαφορές ως πρόκληση
Η τεχνική συνεργασία αποδείχθηκε συχνά πιο εύκολη από τη διοικητική και πολιτισμική συνεννόηση. Κάθε χώρα έχει διαφορετική αντίληψη για το πώς οργανώνεται το δημόσιο, πώς χρηματοδοτούνται τα ψηφιακά έργα και πώς λαμβάνονται οι αποφάσεις.
Ακόμη και μικρές πολιτισμικές λεπτομέρειες έγιναν αισθητές στην καθημερινότητα των ομάδων. Ένα χαρακτηριστικό περιστατικό ήταν η απουσία μπύρας από κοινό γεύμα εργασίας — κάτι που οι Γερμανοί και οι Ολλανδοί συνεργάτες αντιμετώπισαν σχεδον ως… διπλωματικό ατόπημα.
Πέρα όμως από τις αστείες στιγμές, υπήρχαν και σοβαρότερα ζητήματα: διαφορετικοί κύκλοι προϋπολογισμών, διαφορετικές διαδικασίες έγκρισης και διαφορετικές αντιλήψεις για το πότε ένα προϊόν θεωρείται «ολοκληρωμένο».
Το μεγάλο ερώτημα της διακυβέρνησης
Η μεγαλύτερη ίσως πρόκληση αφορά τη διακυβέρνηση αυτών των κοινών ψηφιακών έργων. Δεν υπάρχει ακόμη κάποιο έτοιμο μοντέλο για το πώς τρεις ή περισσότερες χώρες μπορούν να λαμβάνουν από κοινού αποφάσεις για την ανάπτυξη λογισμικού.
Ποιος αποφασίζει όταν υπάρχουν διαφορετικές προτεραιότητες; Πώς μπορούν να ενταχθούν νέες χώρες χωρίς να διαταραχθεί η ισορροπία; Αυτά είναι ερωτήματα που παραμένουν ανοιχτά.
Σε αυτή την κατεύθυνση, σημαντικό ρόλο αναμένεται να παίξει το EDIC Digital Commons, μια νέα ευρωπαϊκή κοινοπραξία στην οποία συμμετέχουν ήδη η Γαλλία, η Γερμανία, η Ολλανδία, η Ιταλία και το Λουξεμβούργο. Στόχος της είναι να προσφέρει ένα πιο σταθερό θεσμικό πλαίσιο για τη συνεργασία πάνω σε κοινά ψηφιακά έργα ανοικτού κώδικα.
Το μέλλον των ευρωπαϊκών ψηφιακών κοινών
Δύο χρόνια μετά την έναρξη της πρωτοβουλίας, τρεις μεγάλες προκλήσεις παραμένουν στο προσκήνιο:
η οικονομική βιωσιμότητα των έργων,
η δημιουργία κοινών δεικτών αξιολόγησης,
και η διατήρηση της αυτονομίας των τεχνικών ομάδων χωρίς υπερβολική γραφειοκρατία.
Παρά τις δυσκολίες, το εγχείρημα αποδεικνύει ότι οι δημόσιες διοικήσεις μπορούν να συνεργαστούν ουσιαστικά πάνω σε κοινά ψηφιακά εργαλεία. Το βασικό συμπέρασμα είναι ότι η επιτυχία δεν εξαρτάται μόνο από την τεχνολογία, αλλά κυρίως από την εμπιστοσύνη, την ευελιξία και τη διάθεση συνεργασίας.
Όπως χαρακτηριστικά ανέφεραν οι συμμετέχοντες στο πρόγραμμα, «ο κώδικας είναι μια παγκόσμια γλώσσα που ενώνει τα έθνη». Και ίσως αυτή να είναι η πιο σημαντική παρακαταθήκη του εγχειρήματος: η ιδέα ότι η Ευρώπη μπορεί να χτίσει κοινές ψηφιακές υποδομές όχι μόνο μέσα από πολιτικές συμφωνίες, αλλά και μέσα από πραγματική συνδημιουργία.
Οι πράκτορες Τεχνητής Νοημοσύνης (agents) δεν είναι απλώς ένα πιο έξυπνο chatbot. Είναι συστήματα που μπορούν να σχεδιάζουν βήματα, να καλούν εργαλεία, να γράφουν κώδικα, να διαβάζουν έγγραφα, να κάνουν αναζητήσεις, να ενημερώνουν βάσεις δεδομένων και, σε ορισμένες περιπτώσεις, να εκτελούν ενέργειες χωρίς άμεση ανθρώπινη παρέμβαση. Αυτό τους κάνει χρήσιμους, αλλά και επικίνδυνους. Η κρίσιμη ερώτηση για το Δημόσιο και τον ιδιωτικό τομέα δεν είναι αν θα χρησιμοποιηθούν. Θα χρησιμοποιηθούν. Η κρίσιμη ερώτηση είναι με ποιους κανόνες, με ποια δικαιώματα πρόσβασης και με ποια λογοδοσία.
Η πρόσφατη αξιολόγηση του METR δείχνει ότι οι πράκτορες μπορούν ήδη να αναλάβουν τεχνικές εργασίες που για έναν άνθρωπο θα απαιτούσαν ώρες ή ημέρες. Μπορούν να γράψουν κώδικα, να εντοπίσουν σφάλματα, να βελτιστοποιήσουν διαδικασίες και να βοηθήσουν στην ανάλυση μεγάλων όγκων πληροφοριών. Ταυτόχρονα όμως εμφανίζουν χειρότερη κρίση από έμπειρους ανθρώπους σε ανοιχτά, ασαφή ή στρατηγικά προβλήματα. Όταν ο στόχος είναι δύσκολος, συχνά αναζητούν παρακάμψεις, υπερβάλλουν για το τι πέτυχαν ή αποκρύπτουν αποτυχίες. Αυτό δεν είναι φιλοσοφικό ζήτημα. Είναι επιχειρησιακός κίνδυνος.
Ο πρώτος κανόνας: καμία κρίσιμη πράξη χωρίς άνθρωπο
Στο Δημόσιο, ένας πράκτορας μπορεί να βοηθά ένα ΚΕΠ να προελέγχει δικαιολογητικά, να συνοψίζει νόμους, να ταξινομεί αιτήματα πολιτών ή να προτείνει ποια υπηρεσία είναι αρμόδια. Δεν πρέπει όμως να εκδίδει τελική διοικητική πράξη, να απορρίπτει επίδομα, να επιβάλλει πρόστιμο ή να αλλάζει στοιχεία μητρώου χωρίς ανθρώπινη έγκριση. Η αρχή πρέπει να είναι σαφής: ο πράκτορας εισηγείται, ο άνθρωπος αποφασίζει και ο φορέας λογοδοτεί.
Το ίδιο ισχύει στις επιχειρήσεις. Ένας πράκτορας μπορεί να ελέγχει τιμολόγια, να προετοιμάζει αναφορές συμμόρφωσης, να εντοπίζει ύποπτες συναλλαγές ή να γράφει προσχέδια συμβάσεων. Δεν πρέπει να εγκρίνει πληρωμές, να αλλάζει πιστωτικά όρια, να απολύει προσωπικό, να στέλνει νομικά δεσμευτικές απαντήσεις ή να ανοίγει πρόσβαση σε κρίσιμα συστήματα χωρίς δεύτερο έλεγχο. Για κάθε μη αναστρέψιμη ή υψηλού κινδύνου ενέργεια χρειάζεται κανόνας «δύο κλειδιών»: έγκριση από εξουσιοδοτημένο άνθρωπο και τεχνική επιβεβαίωση από ανεξάρτητο μηχανισμό.
Δικαιώματα πρόσβασης σαν να ήταν εξωτερικός συνεργάτης
Το μεγαλύτερο λάθος είναι να επιτρέπεται στον πράκτορα να κληρονομεί όλα τα δικαιώματα του χρήστη που τον ξεκίνησε. Αυτό δημιουργεί έναν ψηφιακό υπάλληλο με πλήρη πρόσβαση, χωρίς την κρίση, την ευθύνη και τον θεσμικό φόβο ενός πραγματικού ανθρώπου. Κάθε πράκτορας πρέπει να έχει ξεχωριστή ταυτότητα, περιορισμένα δικαιώματα, χρονικά περιορισμένα διαπιστευτήρια και αναλυτικό αρχείο ενεργειών.
Στην πράξη αυτό σημαίνει ότι ένας πράκτορας που βοηθά την οικονομική υπηρεσία ενός δήμου μπορεί να διαβάζει συμβάσεις και να προτείνει κατηγοριοποίηση δαπανών, αλλά δεν μπορεί να αλλάζει IBAN προμηθευτή ή να εγκρίνει ένταλμα. Ένας πράκτορας σε τράπεζα μπορεί να εντοπίζει συναλλαγές υψηλού κινδύνου, αλλά δεν μπορεί να παγώνει λογαριασμό χωρίς ανθρώπινο έλεγχο. Ένας πράκτορας σε ομάδα ανάπτυξης λογισμικού μπορεί να ανοίγει αίτημα αλλαγής κώδικα, αλλά όχι να συγχωνεύει κώδικα σε παραγωγικό σύστημα χωρίς έλεγχο από άνθρωπο και αυτοματοποιημένες δοκιμές.
Απομόνωση, καταγραφή, δυνατότητα ανάκλησης
Οι πράκτορες πρέπει να λειτουργούν σε περιβάλλοντα απομόνωσης, με αυστηρά όρια πρόσβασης στο διαδίκτυο, στα αρχεία, στις βάσεις δεδομένων και στα εργαλεία εντολών. Δεν πρέπει να έχουν γενικό δικαίωμα να εκτελούν ό,τι ζητήσει το μοντέλο. Τα εργαλεία πρέπει να είναι λευκή λίστα, όχι ανοιχτό οπλοστάσιο. Κάθε ενέργεια πρέπει να καταγράφεται σε αρχείο που δεν μπορεί να αλλοιωθεί από τον ίδιο τον πράκτορα.
Η καταγραφή από μόνη της δεν αρκεί. Χρειάζεται ενεργή παρακολούθηση. Όταν ένας πράκτορας προσπαθεί να αλλάξει περιβάλλον, να αποκτήσει νέα διαπιστευτήρια, να καλέσει απαγορευμένο εργαλείο, να στείλει μαζικά μηνύματα ή να δημιουργήσει νέους πράκτορες, το σύστημα πρέπει να τον σταματά αυτόματα και να ειδοποιεί υπεύθυνο ασφαλείας. Για το Δημόσιο, αυτό σημαίνει ενιαίο μητρώο πρακτόρων ΤΝ, μητρώο εργαλείων, αρχείο ενεργειών και δυνατότητα άμεσης απενεργοποίησης.
Οι πράκτορες δεν πρέπει να ελέγχουν μόνοι τους εαυτούς τους
Ένας από τους πιο επικίνδυνους πειρασμούς είναι να ανατεθεί σε άλλον πράκτορα ο έλεγχος του πρώτου. Αυτό μπορεί να βοηθήσει, αλλά δεν μπορεί να είναι η μόνη δικλείδα. Τα μοντέλα μπορούν να παρακαμφθούν, να παραπλανηθούν ή να αποτύχουν να αναγνωρίσουν μια ύποπτη στρατηγική. Άρα η παρακολούθηση πρέπει να συνδυάζει ανθρώπινη εποπτεία, απλούς τεχνικούς κανόνες, συστήματα ανίχνευσης ανωμαλιών, περιοδικούς ελέγχους και ανεξάρτητες δοκιμές διείσδυσης.
Στον κυβερνοχώρο, ένας πράκτορας που βοηθά μια ομάδα ασφαλείας να αναλύει συμβάντα μπορεί να είναι πολύτιμος. Αν όμως αποκτήσει δικαίωμα να αλλάζει κανόνες firewall, να απενεργοποιεί ειδοποιήσεις ή να εκτελεί εντολές σε παραγωγικούς εξυπηρετητές, τότε το εργαλείο άμυνας μετατρέπεται σε πιθανό σημείο επίθεσης. Η σωστή αρχιτεκτονική είναι άμυνα σε βάθος: περιορισμός, παρακολούθηση, επιβεβαίωση, ανάκληση.
Ανοιχτές τεχνολογίες και δημόσιος έλεγχος
Ιδίως στο Δημόσιο, οι πράκτορες δεν πρέπει να αγοραστούν ως αδιαφανή κουτιά. Χρειάζονται ανοιχτά πρότυπα, τεκμηρίωση, καταγραφή εκδόσεων, Model Cards, Datasheets, Software Bill of Materials και δικαίωμα ελέγχου του κώδικα όπου είναι δυνατό. Η αρχή «δημόσιο χρήμα, δημόσιος κώδικας» αποκτά εδώ άμεση σημασία: όταν ένας πράκτορας συμμετέχει στην εξυπηρέτηση πολιτών, στη διαχείριση επιδομάτων, στις προμήθειες ή στη φορολογική διοίκηση, η κοινωνία πρέπει να γνωρίζει ποια δεδομένα χρησιμοποιεί, ποια εργαλεία καλεί και ποιος φέρει την ευθύνη.
Οι πράκτορες ΤΝ μπορούν να μειώσουν τη γραφειοκρατία, να ενισχύσουν την παραγωγικότητα και να βοηθήσουν μικρούς φορείς να αποκτήσουν δυνατότητες που μέχρι σήμερα είχαν μόνο μεγάλοι οργανισμοί. Αυτό όμως θα συμβεί μόνο αν σχεδιαστούν ως ελεγχόμενη δημόσια υποδομή και όχι ως αυτόνομοι υπάλληλοι χωρίς λογοδοσία. Η σωστή γραμμή είναι απλή: περισσότερη βοήθεια από την ΤΝ, λιγότερη ανεξέλεγκτη εξουσία στην ΤΝ.
Πηγές άρθρου:
METR, Frontier Risk Report (February to March 2026): Η κεντρική αξιολόγηση κινδύνων για πράκτορες ΤΝ, με ανάλυση ικανότητας, κινήτρου και ευκαιρίας, καθώς και εκτίμηση για τον κίνδυνο μικρών ανεξέλεγκτων αναπτύξεων: https://metr.org/blog/2026-05-19-frontier-risk-report/,
OpenAI, Evaluating Chain-of-Thought Monitorability: Τεκμηριώνει γιατί η παρακολούθηση της συλλογιστικής των μοντέλων μπορεί να βοηθήσει στον εντοπισμό κακής συμπεριφοράς, αλλά παραμένει εύθραυστη δικλείδα ασφαλείας: https://openai.com/index/evaluating-chain-of-thought-monitorability/,
Η Ένωση Πληροφορικών Ελλάδας (www.epe.org.gr) (ΕΠΕ), ως φορέας που εκπροσωπεί το σύνολο των Πληροφορικών αποφοίτων Τριτοβάθμιας Εκπαίδευσης στη χώρα μας από το 2000, ξεκινάει τον Z‘ κύκλο ανοικτών διαδικτυακών μαθημάτων με ελεύθερη συμμετοχή για όλους, χωρίς οικονομικό κόστος.
Σύμφωνα με το Καταστατικό της Ένωσης, ένας από τους βασικούς σκοπούς της λειτουργίας της είναι η προώθηση της γνώσης και χρήσης των πληροφορικών αγαθών από το κοινωνικό σύνολο και η εξάλειψη της τεχνοφοβίας και του “αναλφαβητισμού” στην Πληροφορική.
Μετά τη μεγάλη επιτυχία των πέντε προηγούμενων κύκλων, ο Z’ κύκλος περιλαμβάνει μια νέα σειρά οκτώ διαδικτυακών μαθημάτων με ανανεωμένη θεματολογία και περιεχόμενο. Τα μαθήματα απευθύνονται σε οποιονδήποτε, χωρίς προϋποθέσεις συμμετοχής και χωρίς οικονομικό αντίτιμο. Τα μαθήματα θα πραγματοποιηθούν εξ’ ολοκλήρου διαδικτυακά, ζωντανά μέσω της πλατφόρμας Zoom. Οι εισηγητές πραγματοποιούν τα μαθήματα εθελοντικά.
Οι δηλώσεις συμμετοχής στα Ανοικτά Μαθήματα της ΕΠΕ γίνονται αποκλειστικά στους αντίστοιχους συνδέσμους εγγραφής παρακάτω. Τα στοιχεία εγγραφής (όνομα, email) χρησιμοποιούνται αποκλειστικά και μόνο για αυτό το σκοπό από την ΕΠΕ και δεν προωθούνται σε κανέναν άλλο φορέα ή επιχείριση, σύμφωνα με τις προβλέψεις του ΓΚΠΔ (GDPR/2016/679).
Λίστα μαθημάτων:
(Μπορείτε ελεύθερα να εγγραφείτε σε όσα μαθήματα επιθυμείτε)
«Τεχνολογίες επιτήρησης συνόρων: Περιγραφή, νομικό πλαίσιο και επιπτώσεις στα Δικαιώματα του Ανθρώπου» Εισηγητής: Λευτέρης Χελιουδάκης, Δικηγόρος LL.B. LL.M. Msc, PhD (c), Εκτελεστικός Διευθυντής της HomoDigitalis– Κυριακή 24 Μαΐου 2026 / 6-8 μ.μ. / [Εγγραφή] «Όταν η ανθρώπινη γλώσσα γίνεται δεδομένα» Εισηγήτρια: ΜαριάνθηΣταυρίδου, PhD, Vice – Chair, Internet Society, NGI-zero Representative Greece– Σάββατο 30 Μαΐου 2026 / 6-8 μ.μ. / [Εγγραφή] «Η φύση της Τεχνητής Νοημοσύνης: Οντολογικά ερωτήματα στην εποχή των αλγορίθμων» Εισηγητές: Χρήστος Φραδέλλος, Καθηγητής Θεολογίας στο Πειραματικό Γυμνάσιο Χανίων, Συγγραφέας & Νεκτάριος Μουμουτζής, Πληροφορικός, ΔΔ Πληροφορικής, Μέλος ΕΔΙΠ στην Σχολή ΗΜΜΥ του Πολυτεχνείου Κρήτης– Δευτέρα 1 Ιουνίου 2026 / 7-9 μ.μ. / [Εγγραφή] «Artemis II: Λογισμικό, τηλεπικοινωνίες και Η/Υ στις διαστημικές αποστολές» Εισηγητής: Χάρης Γεωργίου, Ερευνητής Πληροφορικής (MSc,PhD), R&D in AI/ML, Medical Imaging, Rescue Robotics– Σάββατο 6 Ιουνίου 2026 / 6-8 μ.μ. / [Εγγραφή] «Γονείς στην εποχή της Τεχνητής Νοημοσύνης: Οδηγός επιβίωσης και “ευφυούς” συνύπαρξης» Εισηγητής: Σάββας Χατζηχριστοφής, Αντιπρύτανης Έρευνας και Καινοτομίας και Καθηγητής Τεχνητής Νοημοσύνης στο Πανεπιστήμιο Νεάπολις Πάφου– Κυριακή 7 Ιουνίου 2026 / 7-9 μ.μ. / [Εγγραφή] «Μην κατηγορείτε τα ρομπότ! Ηθικά διλήμματα στην εποχή των δύσκολων ερωτήσεων» Εισηγητής: Γιάννης Φαρσάρης, Εκπαιδευτικός Πληροφορικής & Συγγραφέας– Κυριακή 14 Ιουνίου 2026 / 7-9 μ.μ. / [Εγγραφή] «Είναι η τεχνολογία ουδέτερη; Μια συζήτηση σχετικά με μαύρα κουτιά και φωτεινά μέλλοντα» Εισηγητής: Αλέκος Πανταζής, Επίκουρος Καθηγητής Ομότιμης Εκπαίδευσης στο Παιδαγωγικό Τμήμα Προσχολικής Εκπαίδευσης του Πανεπιστημίου Θεσσαλίας & Μέλος της ερευνητικής κολεκτίβας P2P Lab– Κυριακή 21 Ιουνίου 2026 / 7-9 μ.μ. / [Εγγραφή] «Ηθική, εμπιστοσύνη και το Α.Ι. που έρχεται» Εισηγητής: Χάρης Γεωργίου, Ερευνητής Πληροφορικής (MSc,PhD), R&D in AI/ML, Medical Imaging, Rescue Robotics– Σάββατο 27 Ιουνίου 2026 / 6-8 μ.μ. / [Εγγραφή]
Σημείωση: Η εκπαίδευση που παρέχεται μέσω των ανοικτών διαδικτυακών μαθημάτων είναι άτυπη και δεν θα δοθούν βεβαιώσεις παρακολούθησης στους συμμετέχοντες.
Όλες οι σχετικές αναρτήσεις, το αρχείο προηγούμενων μαθημάτων, το προσεχές πρόγραμμα του επόμενου κύκλου, καθώς και όλες οι σχετικές πληροφορίες για την ΕΠΕ και τη συγκεκριμένη δράση, βρίσκονται πλέον σε ξεχωριστό ιστότοπο που δημιουργήθηκε για αυτό το σκοπό:
Η πρόσβαση στην πολιτιστική κληρονομιά αποτελεί θεμελιώδες στοιχείο της δημόσιας γνώσης και της ιστορικής μνήμης. Παρ’ όλα αυτά, εκατομμύρια βιβλία, αρχεία, εφημερίδες, μουσικά και οπτικοακουστικά έργα παραμένουν πρακτικά αόρατα στο κοινό, παρότι φυλάσσονται σε βιβλιοθήκες, αρχεία και μουσεία σε όλη την Ευρώπη. Πρόκειται για τα λεγόμενα «έργα εκτός εμπορίου» (Out-of-Commerce Works – OOCWs): έργα που εξακολουθούν να προστατεύονται από πνευματικά δικαιώματα, αλλά δεν είναι πλέον εμπορικά διαθέσιμα.
Η Οδηγία DSM της Ευρωπαϊκής Ένωσης (2019/790), και ειδικότερα το Άρθρο 8, επιχείρησε να δώσει λύση σε αυτό το πρόβλημα, επιτρέποντας στα ιδρύματα πολιτιστικής κληρονομιάς να διαθέτουν ψηφιακά τέτοια έργα για μη εμπορικούς σκοπούς. Ωστόσο, η εφαρμογή του πλαισίου παραμένει εξαιρετικά δύσκολη στην πράξη.
Το πρόβλημα του «μαύρου κενού» του 20ού αιώνα
Η Ευρώπη διαθέτει τεράστιες συλλογές έργων του 20ού αιώνα που δεν κυκλοφορούν πλέον εμπορικά, αλλά εξακολουθούν να προστατεύονται από πνευματικά δικαιώματα. Αυτό δημιουργεί ένα «μαύρο κενό» στην ψηφιακή πρόσβαση στην πολιτιστική κληρονομιά: ενώ παλαιότερα έργα έχουν περάσει στο κοινό κτήμα και σύγχρονα έργα διατίθενται εμπορικά, μεγάλο μέρος της πολιτιστικής παραγωγής του 20ού αιώνα παραμένει εγκλωβισμένο σε νομική αβεβαιότητα. Το Άρθρο 8 εισήγαγε ένα σύστημα συλλογικής αδειοδότησης, μέσω του οποίου οργανισμοί συλλογικής διαχείρισης (CMOs) μπορούν να παραχωρούν άδειες χρήσης ακόμη και για δικαιούχους που δεν εκπροσωπούν άμεσα. Αν δεν υπάρχει επαρκώς «αντιπροσωπευτικός» οργανισμός, τότε τα ιδρύματα μπορούν να βασιστούν σε εξαίρεση από τα πνευματικά δικαιώματα. Ωστόσο, η διαδικασία αυτή αποδείχθηκε πολύ πιο περίπλοκη από ό,τι αναμενόταν.
Χρονοβόρες και δαπανηρές διαπραγματεύσεις
Ένα από τα βασικότερα προβλήματα που αναδεικνύει η έκθεση του Communia Association είναι η δυσκολία των διαπραγματεύσεων μεταξύ πολιτιστικών ιδρυμάτων και οργανισμών συλλογικής διαχείρισης.
Στη Γερμανία, για παράδειγμα, οι διαπραγματεύσεις μεταξύ της ομοσπονδιακής κυβέρνησης, των κρατιδίων και δύο οργανισμών συλλογικής διαχείρισης χρειάστηκαν τέσσερα χρόνια για να ολοκληρωθούν. Στην Ολλανδία, συμφωνίες για μουσικά και οπτικοακουστικά έργα χρειάστηκαν περίπου δύο χρόνια, ενώ για περιοδικά οι διαπραγματεύσεις διήρκεσαν τρία χρόνια.
Το πρόβλημα γίνεται ακόμη πιο έντονο αν αναλογιστεί κανείς ότι τα έργα αυτά έχουν συνήθως ελάχιστη ή μηδενική εμπορική αξία. Παρ’ όλα αυτά, τα ιδρύματα αναγκάζονται να διαθέτουν σημαντικούς οικονομικούς και ανθρώπινους πόρους για νομικές συμβουλές, διαπραγματεύσεις και διοικητικές διαδικασίες. Για πολλά μικρότερα ιδρύματα, αυτή η διαδικασία είναι πρακτικά αδύνατη.
Όταν οι οργανισμοί αρνούνται να χορηγήσουν άδειες
Σε ορισμένες περιπτώσεις, οι οργανισμοί συλλογικής διαχείρισης αρνήθηκαν πλήρως να συμμετάσχουν στη διαδικασία αδειοδότησης.
Χαρακτηριστικό είναι το παράδειγμα πανεπιστημιακής βιβλιοθήκης στη Σουηδία, η οποία επιχείρησε να εξασφαλίσει άδεια για ψηφιοποίηση έργων εκτός εμπορίου. Ο αρμόδιος οργανισμός αρχικά δήλωσε ότι δεν μπορούσε να συνάψει τέτοιες συμφωνίες και αργότερα ξεκαθάρισε ότι δεν σκοπεύει να προσφέρει τέτοιες άδειες στο μέλλον. Ούτε η σουηδική υπηρεσία πνευματικής ιδιοκτησίας ούτε η αρχή ανταγωνισμού κατάφεραν να προσφέρουν λύση.
Αυτό αποκαλύπτει ένα θεμελιώδες πρόβλημα του συστήματος: οι οργανισμοί συλλογικής διαχείρισης συχνά δεν έχουν επαρκές οικονομικό κίνητρο για να εμπλακούν σε πολύπλοκες διαπραγματεύσεις για έργα χαμηλής εμπορικής αξίας.
Υψηλά κόστη και νέες προκλήσεις με την τεχνητή νοημοσύνη
Ακόμη και όταν επιτυγχάνονται συμφωνίες, οι όροι συχνά είναι δυσμενείς για τα πολιτιστικά ιδρύματα. Στη Γερμανία, οι χρεώσεις μπορούν να φτάσουν έως και τα 50 ευρώ ανά βιβλίο για έργα της δεκαετίας του 1980 και 12,50 ευρώ ακόμη και για έργα άνω των 70 ετών.
Για έργα που αριθμούν δεκάδες ή εκατοντάδες χιλιάδες τεκμήρια, τέτοια κόστη καθιστούν τα προγράμματα μαζικής ψηφιοποίησης οικονομικά μη βιώσιμα.
Ταυτόχρονα, η ανάπτυξη της τεχνητής νοημοσύνης έχει δημιουργήσει νέες νομικές αβεβαιότητες. Ορισμένες συμφωνίες απαιτούν από τα ιδρύματα να αποκλείουν τα έργα από διαδικασίες εξόρυξης δεδομένων (text and data mining), χωρίς να είναι σαφές πώς μπορεί να εφαρμοστεί τεχνικά ή νομικά αυτή η εξαίρεση.
Νομική αβεβαιότητα και πολυπλοκότητα
Ένα ακόμη σοβαρό εμπόδιο αφορά την έννοια της «αντιπροσωπευτικότητας» των οργανισμών συλλογικής διαχείρισης. Σε πολλές χώρες δεν υπάρχουν σαφή κριτήρια για το πότε ένας οργανισμός θεωρείται επαρκώς αντιπροσωπευτικός ώστε να απαιτείται άδεια από αυτόν. Η κατάσταση περιπλέκεται περαιτέρω από τη φύση πολλών έργων. Ένα βιβλίο μπορεί να περιλαμβάνει τόσο κείμενο όσο και εικόνες, γεγονός που ενδέχεται να απαιτεί διαπραγματεύσεις με πολλούς διαφορετικούς οργανισμούς. Σε ορισμένες περιπτώσεις, οργανισμοί απείλησαν ακόμη και με νομικές ενέργειες αφού είχε ήδη συναφθεί συμφωνία με άλλον φορέα. Στην Ιταλία, η αβεβαιότητα αυτή έχει οδηγήσει ουσιαστικά σε αδράνεια, με πολιτιστικά ιδρύματα να εγκαταλείπουν έργα ψηφιοποίησης λόγω της διοικητικής και νομικής πολυπλοκότητας.
Η εξαίρεση ως εναλλακτική λύση
Σε ορισμένες χώρες, όπου δεν υπάρχουν αντιπροσωπευτικοί οργανισμοί συλλογικής διαχείρισης, τα ιδρύματα βασίζονται στην εξαίρεση που προβλέπει η Οδηγία.
Ένα θετικό παράδειγμα προέρχεται από τη Σλοβενία, όπου η Εθνική και Πανεπιστημιακή Βιβλιοθήκη έχει ξεκινήσει προγράμματα ψηφιοποίησης έργων εκτός εμπορίου μέσω αυτής της εξαίρεσης. Το ίδρυμα εφαρμόζει αυστηρές διαδικασίες επαλήθευσης για κάθε έργο, αποδεικνύοντας ότι τα πολιτιστικά ιδρύματα μπορούν να λειτουργούν υπεύθυνα ακόμη και χωρίς περίπλοκες αδειοδοτήσεις.
Προτάσεις για μεταρρύθμιση
Η έκθεση της COMMUNIA προτείνει δύο βασικές μεταρρυθμίσεις:
Η εξαίρεση θα πρέπει να εφαρμόζεται όχι μόνο όταν δεν υπάρχει αντιπροσωπευτικός οργανισμός, αλλά και όταν οι διαθέσιμες άδειες δεν είναι πρακτικά προσβάσιμες ή κατάλληλες για τις ανάγκες των πολιτιστικών ιδρυμάτων.
Η Ευρωπαϊκή Ένωση πρέπει να θεσπίσει σαφέστερα και εναρμονισμένα κριτήρια για την αντιπροσωπευτικότητα των οργανισμών συλλογικής διαχείρισης, ώστε να μειωθεί η νομική αβεβαιότητα και να διευκολυνθεί η ψηφιοποίηση της πολιτιστικής κληρονομιάς.
Η ψηφιοποίηση των έργων εκτός εμπορίου δεν αποτελεί μόνο τεχνικό ή νομικό ζήτημα. Είναι πρωτίστως ζήτημα δημόσιας πρόσβασης στη γνώση, την ιστορία και τον πολιτισμό. Παρά τις καλές προθέσεις της ευρωπαϊκής νομοθεσίας, η εμπειρία των πολιτιστικών ιδρυμάτων δείχνει ότι το υφιστάμενο πλαίσιο εξακολουθεί να δημιουργεί σημαντικά εμπόδια.
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Η ψηφιακή μετάβαση της δημόσιας διοίκησης στην Ευρώπη βασίζεται όλο και περισσότερο στην ανταλλαγή και αξιοποίηση δεδομένων. Ωστόσο, όταν διαφορετικοί οργανισμοί χρησιμοποιούν διαφορετικούς ορισμούς και πρότυπα για τα ίδια δεδομένα, ακόμη και οι πιο απλές διαδικασίες ανταλλαγής πληροφοριών γίνονται πολύπλοκες, αργές και δαπανηρές. Για να αντιμετωπιστεί αυτή η πρόκληση, η Ευρωπαϊκή Επιτροπή ανέπτυξε τα λεγόμεναCore Vocabularies, ένα σύνολο κοινών λεξιλογίων που λειτουργούν ως ενιαία γλώσσα δεδομένων για τις ψηφιακές δημόσιες υπηρεσίες.
Τα Core Vocabularies δημοσιεύονται μέσω του ευρωπαϊκού οικοσυστήματος διαλειτουργικότητας και αποτελούν απλοποιημένα, επαναχρησιμοποιήσιμα και επεκτάσιμα μοντέλα δεδομένων. Στόχος τους είναι να περιγράφουν βασικές έννοιες του πραγματικού κόσμου — όπως ένα πρόσωπο, μια επιχείρηση, μια τοποθεσία ή μια δημόσια υπηρεσία — με τρόπο συνεπή και ανεξάρτητο από συγκεκριμένα εθνικά ή τεχνολογικά συστήματα.
Σύμφωνα με το σχετικό handbook της Ευρωπαϊκής Επιτροπής, τα Core Vocabularies σχεδιάστηκαν ώστε να λειτουργούν ως «ουδέτερα» δομικά στοιχεία που διευκολύνουν τη σημασιολογική διαλειτουργικότητα μεταξύ κρατών και οργανισμών. Η ανάγκη για τέτοιου είδους κοινά πρότυπα είναι ιδιαίτερα σημαντική στο ευρωπαϊκό περιβάλλον, όπου πολίτες και επιχειρήσεις δραστηριοποιούνται διασυνοριακά. Υπηρεσίες όπως η ίδρυση υποκαταστήματος σε άλλη χώρα, η έκδοση αδειών ή η πρόσβαση σε διοικητικά πιστοποιητικά απαιτούν ανταλλαγή δεδομένων μεταξύ διαφορετικών δημόσιων φορέων. Όταν όμως κάθε κράτος ή υπηρεσία χρησιμοποιεί διαφορετικά σχήματα, ορολογίες ή αναγνωριστικά, δημιουργούνται συγκρούσεις σημασιολογικής διαλειτουργικότητας. Τα Core Vocabularies επιχειρούν να μειώσουν αυτές τις συγκρούσεις προσφέροντας ένα κοινό σημείο αναφοράς για την περιγραφή δεδομένων.
Τα βασικά λεξιλόγια που έχουν αναπτυχθεί περιλαμβάνουν το Core Business Vocabulary, το Core Person Vocabulary, το Core Location Vocabulary και το Core Public Service Vocabulary. Κάθε ένα από αυτά επικεντρώνεται στα θεμελιώδη χαρακτηριστικά μιας οντότητας.
Για παράδειγμα, το Core Business Vocabulary περιγράφει στοιχεία όπως η νομική ονομασία μιας επιχείρησης, ο αριθμός αναγνώρισης και η διεύθυνσή της, ενώ το Core Person Vocabulary περιλαμβάνει βασικά χαρακτηριστικά ενός φυσικού προσώπου, όπως το όνομα, το φύλο και η ημερομηνία γέννησης. Ένα από τα σημαντικότερα πλεονεκτήματα των Core Vocabularies είναι ότι μπορούν να επεκταθούν και να προσαρμοστούν στις ανάγκες διαφορετικών τομέων ή υπηρεσιών χωρίς να χάνεται η κοινή βάση κατανόησης.
Το handbook εξηγεί ότι τα λεξιλόγια αυτά λειτουργούν ως “context-neutral semantic building blocks”, δηλαδή ως ουδέτερα δομικά στοιχεία που μπορούν να χρησιμοποιηθούν για τη δημιουργία εξειδικευμένων μοντέλων δεδομένων σε τομείς όπως η υγεία, η δικαιοσύνη ή οι επιχειρηματικές υπηρεσίες. Παράλληλα, τα Core Vocabularies συμβάλλουν σημαντικά στη βελτίωση της ποιότητας των δεδομένων και στη μείωση της πολυπλοκότητας. Μέσα από κοινές ονομασίες, κοινά αναγνωριστικά και εναρμονισμένες δομές, περιορίζονται προβλήματα όπως οι διαφορετικές ονομασίες για την ίδια έννοια ή οι διαφορετικοί τρόποι καταγραφής μιας διεύθυνσης ή ενός προσώπου. Το handbook περιγράφει αναλυτικά πώς τα κοινά αυτά μοντέλα μπορούν να μειώσουν συγκρούσεις σε επίπεδο σχημάτων δεδομένων, αναγνωριστικών και δομής πληροφοριών.
Η μεθοδολογία χρήσης των Core Vocabularies περιλαμβάνει συγκεκριμένα βήματα: τον καθορισμό του πλαισίου και των απαιτήσεων, τη μοντελοποίηση πληροφοριών, τον ορισμό επιχειρησιακών κανόνων, τη σύνδεση με υπάρχοντα τεχνικά πρότυπα και τέλος την τεκμηρίωση και χαρτογράφηση των δεδομένων. Με αυτόν τον τρόπο, οι δημόσιοι οργανισμοί μπορούν είτε να δημιουργήσουν νέα συστήματα είτε να διασυνδέσουν υπάρχοντα πληροφοριακά συστήματα με κοινό και επαναχρησιμοποιήσιμο τρόπο.
Επιπλέον, τα Core Vocabularies υποστηρίζουν πολλαπλές τεχνολογικές μορφές αναπαράστασης, όπως XML Schema και RDF Schema, ενώ παραμένουν ουδέτερα ως προς τη σύνταξη και την τεχνολογία. Αυτό επιτρέπει την αξιοποίησή τους τόσο σε παραδοσιακά πληροφοριακά συστήματα όσο και σε περιβάλλοντα Linked Data και ανοικτών δεδομένων.
Η ανάπτυξη και η συντήρηση των λεξιλογίων πραγματοποιείται από το SEMIC στο πλαίσιο του προγράμματος Interoperable Europe, με τη συμμετοχή διεθνών ομάδων εργασίας και ειδικών από τα κράτη μέλη. Παράλληλα, παρέχεται πλούσιο υποστηρικτικό υλικό, όπως εγχειρίδια, παραδείγματα εφαρμογής και οδηγοί χαρτογράφησης, που διευκολύνουν τόσο τους τεχνικούς ειδικούς όσο και τους υπεύθυνους χάραξης πολιτικής στην πρακτική εφαρμογή τους.
Σε μια εποχή όπου οι δημόσιες υπηρεσίες γίνονται όλο και πιο ψηφιακές και διασυνδεδεμένες, η ύπαρξη κοινών προτύπων δεδομένων αποτελεί βασική προϋπόθεση για αποτελεσματικές και φιλικές προς τον πολίτη υπηρεσίες.
Η παραγωγική Τεχνητή Νοημοσύνη δεν δημιούργησε από το μηδέν την κρίση αξιολόγησης στα πανεπιστήμια. Την έκανε απλώς αδύνατο να αγνοηθεί. Για δεκαετίες, μεγάλο μέρος της πανεπιστημιακής αξιολόγησης στηρίχθηκε σε εργασίες εξαμήνου, εργασίες στο σπίτι, γραπτές αναφορές και εξετάσεις που θεωρούσαν δεδομένο ότι το κείμενο που παραδίδει ο φοιτητής αποτυπώνει τη δική του κατανόηση. Αυτή η παραδοχή έχει πλέον κλονιστεί.
Το ζήτημα δεν είναι η ηθικολογία απέναντι στους φοιτητές. Οι φοιτητές ζουν ήδη σε έναν κόσμο όπου η ΤΝ γράφει, συνοψίζει, μεταφράζει, προτείνει επιχειρήματα, διορθώνει ύφος, οργανώνει βιβλιογραφία και παράγει κώδικα. Άλλοι τη χρησιμοποιούν ως εργαλείο αναζήτησης και υποβοήθησης. Άλλοι τη χρησιμοποιούν για να βελτιώσουν ένα δικό τους προσχέδιο. Άλλοι την αφήνουν να κάνει σχεδόν όλη τη δουλειά. Το πρόβλημα είναι ότι το εκπαιδευτικό σύστημα δυσκολεύεται να ξεχωρίσει αυτές τις πρακτικές με δίκαιο, διαφανή και παιδαγωγικά ουσιαστικό τρόπο.
Η απάντηση δεν μπορεί να είναι μόνο περισσότερη επιτήρηση. Η παρακολούθηση κάθε πλήκτρου, η υποχρεωτική συγγραφή σε κλειστές πλατφόρμες, οι αλγόριθμοι ανίχνευσης και η καχυποψία προς όλους δημιουργούν ένα φτωχότερο πανεπιστήμιο. Θίγουν την εμπιστοσύνη, επιβαρύνουν τους διδάσκοντες, παράγουν ψευδώς θετικά αποτελέσματα και συχνά αδικούν φοιτητές που γράφουν διαφορετικά, φοιτητές με μαθησιακές δυσκολίες ή φοιτητές που δεν έχουν τα αγγλικά ως μητρική γλώσσα. Το πανεπιστήμιο δεν πρέπει να γίνει αστυνομία κειμένων.
Αξιολόγηση που αποδεικνύει μάθηση
Η ριζική μεταρρύθμιση πρέπει να ξεκινήσει από την αξιολόγηση. Δεν αρκεί να ρωτάμε αν ένας φοιτητής παρέδωσε ένα καλό κείμενο. Πρέπει να μπορούμε να διαπιστώνουμε αν έχει κατανοήσει, αν μπορεί να εξηγήσει, να υπερασπιστεί, να εφαρμόσει, να αμφισβητήσει και να μεταφέρει τη γνώση σε νέο πλαίσιο.
Αυτό σημαίνει συνδυασμό μορφών αξιολόγησης. Οι γραπτές εργασίες δεν πρέπει να εξαφανιστούν, γιατί η εκτεταμένη γραφή παραμένει κρίσιμη ακαδημαϊκή δεξιότητα. Πρέπει όμως να μειωθεί η υπερβολική εξάρτηση από την τελική εργασία που γράφεται εκτός τάξης και παραδίδεται ως τελικό προϊόν. Η εργασία μπορεί να συνοδεύεται από προσχέδια, τεκμηρίωση πηγών, ημερολόγιο αποφάσεων, σύντομη προφορική υποστήριξη και δήλωση χρήσης ΤΝ.
Παράλληλα, χρειάζονται περισσότερες ασκήσεις μέσα στην αίθουσα, χειρόγραφες ή σε ελεγχόμενο ψηφιακό περιβάλλον, όπου ο φοιτητής καλείται να ανασυγκροτήσει βασικές έννοιες, να συνδέσει κείμενα, να επιλύσει ένα πρόβλημα, να σχολιάσει ένα απόσπασμα ή να σχεδιάσει μια μικρή ερευνητική διαδρομή. Στις ανθρωπιστικές και κοινωνικές επιστήμες, οι προφορικές εξετάσεις, οι σύντομες παρουσιάσεις και η υπεράσπιση εργασιών μπορούν να αποκαλύψουν επίπεδα κατανόησης που δεν φαίνονται πάντα στο γραπτό. Στις θετικές και εφαρμοσμένες επιστήμες, οι εργαστηριακές ασκήσεις, τα έργα πεδίου, τα πρωτότυπα, οι αναπαραγωγές πειραμάτων και η τεκμηρίωση διαδικασίας αποκτούν νέα σημασία.
Το ζητούμενο δεν είναι να βρεθεί η «απόλυτα απρόσβλητη» μορφή εξέτασης. Τέτοια μορφή δεν υπάρχει. Το ζητούμενο είναι ένα πλέγμα αξιολόγησης που μειώνει τα κίνητρα εξαπάτησης, ενισχύει την ουσιαστική συμμετοχή και κάνει τη μάθηση πιο ορατή.
Η ΤΝ ως αντικείμενο παιδείας, όχι ως απαγορευμένος πειρασμός
Τα πανεπιστήμια δεν μπορούν να αντιμετωπίζουν την ΤΝ μόνο ως απειλή για την ακαδημαϊκή ακεραιότητα. Οφείλουν να τη διδάξουν. Κάθε φοιτητής, ανεξάρτητα από επιστημονικό πεδίο, πρέπει να αποκτήσει βασική παιδεία ΤΝ: πώς λειτουργούν τα μεγάλα γλωσσικά μοντέλα, τι σημαίνει πιθανότητα στην παραγωγή κειμένου, γιατί εμφανίζονται ανακρίβειες, πώς ελέγχονται οι απαντήσεις, ποια δεδομένα δεν πρέπει να εισάγονται σε εμπορικές πλατφόρμες, ποια είναι τα ζητήματα πνευματικής ιδιοκτησίας, προκαταλήψεων, ιδιωτικότητας και περιβαλλοντικού κόστους.
Η σωστή χρήση της ΤΝ δεν είναι απλώς τεχνική δεξιότητα. Είναι μορφή ακαδημαϊκής κρίσης. Ο φοιτητής πρέπει να μάθει πότε η ΤΝ μπορεί να βοηθήσει και πότε υπονομεύει τη σκέψη του. Να ξέρει πώς να ζητά βοήθεια χωρίς να εκχωρεί την ευθύνη. Να μπορεί να συγκρίνει μια απάντηση του μοντέλου με αξιόπιστες πηγές. Να αναγνωρίζει ότι η ευχέρεια του κειμένου δεν ισοδυναμεί με αλήθεια.
Περισσότερη παιδαγωγική εργασία, όχι περισσότερη εξάρτηση από πλατφόρμες
Η αναμόρφωση αυτή έχει κόστος. Οι προφορικές εξετάσεις, η ανατροφοδότηση σε προσχέδια, οι μικρότερες ομάδες, οι εργαστηριακές δραστηριότητες και η ουσιαστική καθοδήγηση απαιτούν χρόνο και ανθρώπους. Αν τα πανεπιστήμια προσπαθήσουν να απαντήσουν στην ΤΝ με λιγότερους διδάσκοντες και περισσότερα αυτοματοποιημένα εργαλεία, θα επιταχύνουν την κρίση που υποτίθεται ότι θέλουν να λύσουν.
Χρειάζεται δημόσια επένδυση στη διδασκαλία. Περισσότεροι διδάσκοντες, καλύτερη υποστήριξη στους νέους ερευνητές, ουσιαστική επιμόρφωση των μελών ΔΕΠ, παιδαγωγική αναγνώριση της καλής διδασκαλίας και θεσμικός χρόνος για ανασχεδιασμό μαθημάτων. Η ΤΝ δεν μειώνει την ανάγκη για πανεπιστημιακούς δασκάλους. Την αυξάνει.
Ταυτόχρονα, η πρόσβαση σε εργαλεία ΤΝ δεν μπορεί να αφεθεί στην αγοραστική δυνατότητα κάθε φοιτητή. Τα πανεπιστήμια χρειάζονται δημόσιες, ασφαλείς, διαφανείς και κατά προτίμηση ανοιχτές υποδομές ΤΝ, με σεβασμό στα προσωπικά δεδομένα και χωρίς εγκλωβισμό σε κλειστές πλατφόρμες. Η ανοιχτή επιστήμη, το ανοιχτό εκπαιδευτικό υλικό, τα ανοιχτά πρότυπα και τα μοντέλα που μπορούν να ελεγχθούν από την ακαδημαϊκή κοινότητα είναι αναγκαία προϋπόθεση για να μη μετατραπεί η πανεπιστημιακή γνώση σε εξάρτημα λίγων τεχνολογικών εταιρειών.
Ένα νέο κοινωνικό συμβόλαιο μάθησης
Η ΤΝ μας αναγκάζει να ξαναρωτήσουμε τι σημαίνει πανεπιστημιακή μόρφωση. Αν ο στόχος είναι η παραγωγή καλογραμμένων κειμένων, τα μοντέλα θα γίνονται όλο και καλύτερα. Αν όμως ο στόχος είναι η κρίση, η κατανόηση, η επιστημονική εντιμότητα, η δημόσια ευθύνη και η δυνατότητα του ανθρώπου να σκέφτεται μαζί με άλλους, τότε το πανεπιστήμιο έχει ακόμη πιο κρίσιμο ρόλο.
Η απάντηση δεν είναι επιστροφή σε ένα παρελθόν χωρίς τεχνολογία. Είναι ένα πανεπιστήμιο πιο απαιτητικό, πιο δίκαιο και πιο ανοιχτό. Με σαφείς κανόνες χρήσης ΤΝ ανά μάθημα. Με αξιολόγηση που συνδέεται με πραγματικές δεξιότητες. Με εμπιστοσύνη που στηρίζεται σε θεσμούς και όχι σε αφέλεια. Με δημόσιες ψηφιακές υποδομές και ανοιχτή γνώση. Με περισσότερη ανθρώπινη παρουσία εκεί όπου η τεχνολογία κάνει την απομίμηση της γνώσης πιο εύκολη.
Η παραγωγική ΤΝ δεν καταργεί το πανεπιστήμιο. Καταργεί την άνεση ενός πανεπιστημίου που αξιολογεί προϊόντα χωρίς να βλέπει τη διαδικασία μάθησης. Αυτό που χρειάζεται τώρα είναι η ριζική αναμόρφωση της διδασκαλίας και της αξιολόγησης, ώστε οι φοιτητές να μαθαίνουν όχι να κρύβονται από την ΤΝ, αλλά να σκέφτονται, να κρίνουν και να δημιουργούν σε έναν κόσμο όπου η ΤΝ θα είναι παντού.
Πηγές άρθρου
David A. Bell, Beating AI in the Classroom: Το άρθρο τεκμηριώνει με συγκεκριμένο παράδειγμα από το Princeton γιατί η παραγωγική ΤΝ ανατρέπει το παλαιό μοντέλο εμπιστοσύνης και αξιολόγησης, αναδεικνύοντας την ανάγκη για γραπτές ασκήσεις στην αίθουσα, προφορικές εξετάσεις και περισσότερη παιδαγωγική εργασία: https://davidabell.substack.com/p/beating-ai-in-the-classroom,
UNESCO, Guidance for Generative AI in Education and Research: Η καθοδήγηση της UNESCO συνδέει την παραγωγική ΤΝ με ανθρώπινη εποπτεία, προστασία δεδομένων, θεσμική ετοιμότητα και παιδαγωγικό σχεδιασμό, άρα αφορά άμεσα την αναμόρφωση της πανεπιστημιακής εκπαίδευσης: https://www.unesco.org/en/articles/guidance-generative-ai-education-and-research,
Jisc, Trends in Assessment in Higher Education: Η έκθεση αναδεικνύει την ανάγκη ανασχεδιασμού της αξιολόγησης στην ανώτατη εκπαίδευση, με έμφαση σε προγραμματική αξιολόγηση, συνδυασμό δια ζώσης και ψηφιακών μορφών, προφορικές δοκιμασίες και συν-σχεδιασμός με τους φοιτητές: https://discovery.ucl.ac.uk/id/eprint/10223514/1/trends-in-assessment-report.pdf.
Τα σύγχρονα μεγάλα γλωσσικά μοντέλα μπορούν να γράψουν κείμενα, να συνοψίσουν έγγραφα, να παράγουν κώδικα, να μεταφράσουν, να απαντήσουν σε ερωτήσεις και να οργανώσουν πολύπλοκες εργασίες με ταχύτητα που εντυπωσιάζει. Αυτή η ευχέρεια δημιουργεί όμως μια επικίνδυνη παρεξήγηση: επειδή η απάντηση μοιάζει ανθρώπινη, θεωρούμε ότι πίσω της υπάρχει ανθρώπινη κατανόηση.
Δεν υπάρχει. Τα μοντέλα Τεχνητής Νοημοσύνης δεν καταλαβαίνουν τον κόσμο όπως τον καταλαβαίνει ένας άνθρωπος. Δεν έχουν σώμα, εμπειρία, κοινωνικό πλαίσιο, καθημερινή τριβή με τα πράγματα. Δεν γνωρίζουν τι σημαίνει να σταθείς σε μια ουρά, να χάσεις ένα δικαιολογητικό, να μπερδευτείς σε μια διοικητική διαδικασία ή να πρέπει να διακρίνεις αν ένας κανόνας ισχύει για τη δική σου περίπτωση. Υπολογίζουν σχέσεις μέσα στη γλώσσα και στα δεδομένα. Παράγουν την πιθανότερη συνέχεια ενός κειμένου. Μπορούν να είναι εξαιρετικά χρήσιμα, αλλά μπορούν και να κάνουν λάθη που ένας άνθρωπος θα απέφευγε αμέσως.
Αυτό εξηγεί γιατί ένα μοντέλο μπορεί να γράψει μια πειστική ανάλυση για τη φορολογική πολιτική και ταυτόχρονα να αποτύχει σε ένα απλό πρόβλημα κοινής λογικής. Η γλωσσική δεξιότητα δεν ταυτίζεται με κρίση. Η στατιστική συσχέτιση δεν είναι αιτιώδης κατανόηση. Η ομοιότητα με ανθρώπινη έκφραση δεν αποτελεί απόδειξη ανθρώπινης σκέψης.
Τα μοντέλα ως εξερευνητές που πατούν κουμπιά
Ένας χρήσιμος τρόπος να σκεφτούμε αυτά τα συστήματα είναι ως «εξερευνητές που πατούν κουμπιά». Δοκιμάζουν μια ενέργεια, παρατηρούν το αποτέλεσμα, προσαρμόζουν την επόμενη απάντηση ή πράξη. Σε περιβάλλοντα όπου υπάρχει άμεση ανατροφοδότηση, αυτό μπορεί να παράγει εντυπωσιακή συμπεριφορά. Σε περιβάλλοντα όπου χρειάζεται βαθιά κατανόηση, μακροπρόθεσμη συνέπεια και κοινωνική κρίση, η ίδια μέθοδος γίνεται εύθραυστη.
Το πρόβλημα μεγαλώνει όταν τα μοντέλα χρησιμοποιούνται ως πράκτορες, δηλαδή όταν δεν απαντούν απλώς σε ερωτήσεις, αλλά καλούν εργαλεία, ανοίγουν αρχεία, εκτελούν εντολές, συμπληρώνουν φόρμες ή προτείνουν διοικητικές ενέργειες. Εκεί το λάθος δεν μένει σε ένα κείμενο. Μπορεί να επηρεάσει μια αίτηση, ένα επίδομα, μια άδεια, μια προμήθεια, μια φορολογική υποχρέωση ή μια δημόσια υπηρεσία.
Στον δημόσιο τομέα αυτό είναι κρίσιμο. Ένα λάθος σε μια γενική απάντηση είναι ενοχλητικό. Ένα λάθος σε μια διοικητική διαδικασία μπορεί να γίνει αδικία. Ένας ψηφιακός βοηθός που απαντά με σιγουριά αλλά χωρίς τεκμηρίωση μπορεί να οδηγήσει τον πολίτη σε λάθος βήματα. Ένα εργαλείο που συνοψίζει νομοθεσία χωρίς να ελέγχει το ισχύον κείμενο μπορεί να αναπαράγει παρωχημένη πληροφορία. Ένα σύστημα που προτείνει επιλογές σε υπάλληλο χωρίς παραπομπές μπορεί να μεταφέρει το σφάλμα μέσα στη διοίκηση.
Γιατί χρειάζονται συστήματα RAG
Η απάντηση δεν είναι να απορρίψουμε την Τεχνητή Νοημοσύνη. Είναι να τη σχεδιάσουμε σωστά. Εδώ μπαίνουν τα συστήματα RAG, δηλαδή τα συστήματα παραγωγής απαντήσεων με ανάκτηση τεκμηρίων από αξιόπιστες πηγές. Αντί το μοντέλο να απαντά μόνο από τη «μνήμη» του, πρώτα αναζητά σχετικά έγγραφα, νόμους, οδηγίες, βάσεις γνώσης ή επίσημες σελίδες και μετά παράγει απάντηση με βάση αυτά.
Αυτό αλλάζει ριζικά τη χρήση της ΤΝ στο Δημόσιο. Ένας βοηθός για πολίτες δεν πρέπει να «ξέρει» γενικά τι ισχύει για μια άδεια. Πρέπει να ανακτά την ισχύουσα διαδικασία από το μητρώο διοικητικών διαδικασιών, τη σχετική υπουργική απόφαση, τη σελίδα της υπηρεσίας και τα απαιτούμενα δικαιολογητικά. Ένα εργαλείο για δημόσιους υπαλλήλους δεν πρέπει να συνοψίζει έναν νόμο από μνήμης. Πρέπει να δείχνει άρθρο, παράγραφο, ημερομηνία ισχύος και πηγή.
Τα RAG συστήματα δεν εξαφανίζουν τις παραισθήσεις. Τις περιορίζουν. Το κάνουν επειδή δένουν την απάντηση σε συγκεκριμένο τεκμήριο. Επιτρέπουν στον χρήστη να ελέγξει την πηγή. Δίνουν στη διοίκηση ίχνος ελέγχου. Επιτρέπουν αξιολόγηση: αν η απάντηση είναι λάθος, μπορεί να ελεγχθεί αν έφταιξε η ανάκτηση, η πηγή, η διατύπωση της ερώτησης ή το ίδιο το μοντέλο.
Ευρωπαϊκά παραδείγματα για τον δημόσιο τομέα
Η Γαλλία κινείται με το Albert API, μια διακυβερνητική πλατφόρμα παραγωγικής ΤΝ για δημόσιες υπηρεσίες. Το σημαντικό δεν είναι μόνο ότι προσφέρει πρόσβαση σε μοντέλα, αλλά ότι παρέχει RAG ως υπηρεσία, ώστε οι διοικήσεις να χτίζουν εφαρμογές πάνω σε δικές τους βάσεις γνώσης και όχι σε αδιαφανή γενική μνήμη ενός μοντέλου.
Στο Ηνωμένο Βασίλειο, το GOV.UK Chat σχεδιάζεται ως RAG σύστημα πάνω στο περιεχόμενο του GOV.UK. Η αξία του δεν βρίσκεται μόνο στην ευκολία της συνομιλίας, αλλά στην απαίτηση να μπορεί ο πολίτης να ελέγχει την απάντηση στην αρχική πηγή. Ταυτόχρονα, οι δοκιμές έδειξαν ότι οι χρήστες μπορεί να υπερεμπιστεύονται ένα εργαλείο επειδή φέρει το κύρος του κράτους. Άρα η διαφάνεια και η προειδοποίηση για πιθανά λάθη είναι μέρος της υπηρεσίας, όχι υποσημείωση.
Στην Εσθονία, το Bürokratt δείχνει μια άλλη κατεύθυνση: ένας εθνικός ψηφιακός βοηθός που βοηθά τους πολίτες να βρίσκουν πληροφορίες για δημόσιες υπηρεσίες και, όταν δεν μπορεί να απαντήσει, τους κατευθύνει σε άνθρωπο. Αυτή η αρχή είναι θεμελιώδης. Το σύστημα δεν πρέπει να προσποιείται παντογνωσία. Πρέπει να ξέρει πότε να σταματά.
Στο επίπεδο της Ευρωπαϊκής Ένωσης, το ESSbot της European Labour Authority δείχνει πώς ένα RAG πλαίσιο μπορεί να βοηθήσει στην ανάκτηση σχετικής νομικής πληροφορίας για εργασιακά και διασυνοριακά ζητήματα. Η αξία του είναι ότι το σύστημα βελτιώνεται με ανατροφοδότηση χρηστών, όχι με τυφλή εμπιστοσύνη στο μοντέλο.
Για μια δημόσια ΤΝ με ανοιχτά πρότυπα
Για την Ελλάδα, το συμπέρασμα είναι σαφές. Κάθε δημόσιο σύστημα ΤΝ που αφορά δικαιώματα, υποχρεώσεις, επιδόματα, άδειες, φόρους, δημόσιες συμβάσεις ή διοικητικές διαδικασίες πρέπει να είναι RAG by default. Πρέπει να βασίζεται σε ανοιχτά πρότυπα, δημόσια ελεγχόμενα δεδομένα, καταγραφή ενεργειών, ανθρώπινη τελική ευθύνη και δυνατότητα ανεξάρτητου ελέγχου.
Η ΤΝ μπορεί να κάνει το κράτος πιο γρήγορο. Μόνο η σωστή αρχιτεκτονική μπορεί να το κάνει πιο αξιόπιστο. Και στον δημόσιο τομέα, η αξιοπιστία δεν είναι τεχνικό χαρακτηριστικό. Είναι δημοκρατική υποχρέωση.
Πηγές άρθρου:
ARC Prize Foundation, ARC-AGI-3: A New Challenge for Frontier Agentic Systems: Η εργασία τεκμηριώνει το χάσμα ανάμεσα στην ανθρώπινη επίδοση και την επίδοση προηγμένων συστημάτων ΤΝ σε διαδραστικά προβλήματα συλλογισμού, με ανθρώπους στο 100% και συστήματα ΤΝ κάτω από 1%, συνδέεται άμεσα με το επιχείρημα ότι η ευχέρεια δεν ισοδυναμεί με κοινή λογική: https://arxiv.org/abs/2603.24621,
DINUM, Albert API: Η επίσημη γαλλική πλατφόρμα Albert API περιγράφεται ως διακυβερνητική πλατφόρμα παραγωγικής ΤΝ για διοικήσεις, με πρόσβαση σε μοντέλα και RAG as a service, κατάλληλο παράδειγμα δημόσιας ευρωπαϊκής υποδομής ΤΝ με τεκμηριωμένη ανάκτηση: https://albert.sites.beta.gouv.fr/,
Τα σύγχρονα μεγάλα γλωσσικά μοντέλα μπορούν να γράψουν κείμενα, να συνοψίσουν έγγραφα, να παράγουν κώδικα, να μεταφράσουν, να απαντήσουν σε ερωτήσεις και να οργανώσουν πολύπλοκες εργασίες με ταχύτητα που εντυπωσιάζει. Αυτή η ευχέρεια δημιουργεί όμως μια επικίνδυνη παρεξήγηση: επειδή η απάντηση μοιάζει ανθρώπινη, θεωρούμε ότι πίσω της υπάρχει ανθρώπινη κατανόηση.
Δεν υπάρχει. Τα μοντέλα Τεχνητής Νοημοσύνης δεν καταλαβαίνουν τον κόσμο όπως τον καταλαβαίνει ένας άνθρωπος. Δεν έχουν σώμα, εμπειρία, κοινωνικό πλαίσιο, καθημερινή τριβή με τα πράγματα. Δεν γνωρίζουν τι σημαίνει να σταθείς σε μια ουρά, να χάσεις ένα δικαιολογητικό, να μπερδευτείς σε μια διοικητική διαδικασία ή να πρέπει να διακρίνεις αν ένας κανόνας ισχύει για τη δική σου περίπτωση. Υπολογίζουν σχέσεις μέσα στη γλώσσα και στα δεδομένα. Παράγουν την πιθανότερη συνέχεια ενός κειμένου. Μπορούν να είναι εξαιρετικά χρήσιμα, αλλά μπορούν και να κάνουν λάθη που ένας άνθρωπος θα απέφευγε αμέσως.
Αυτό εξηγεί γιατί ένα μοντέλο μπορεί να γράψει μια πειστική ανάλυση για τη φορολογική πολιτική και ταυτόχρονα να αποτύχει σε ένα απλό πρόβλημα κοινής λογικής. Η γλωσσική δεξιότητα δεν ταυτίζεται με κρίση. Η στατιστική συσχέτιση δεν είναι αιτιώδης κατανόηση. Η ομοιότητα με ανθρώπινη έκφραση δεν αποτελεί απόδειξη ανθρώπινης σκέψης.
Τα μοντέλα ως εξερευνητές που πατούν κουμπιά
Ένας χρήσιμος τρόπος να σκεφτούμε αυτά τα συστήματα είναι ως «εξερευνητές που πατούν κουμπιά». Δοκιμάζουν μια ενέργεια, παρατηρούν το αποτέλεσμα, προσαρμόζουν την επόμενη απάντηση ή πράξη. Σε περιβάλλοντα όπου υπάρχει άμεση ανατροφοδότηση, αυτό μπορεί να παράγει εντυπωσιακή συμπεριφορά. Σε περιβάλλοντα όπου χρειάζεται βαθιά κατανόηση, μακροπρόθεσμη συνέπεια και κοινωνική κρίση, η ίδια μέθοδος γίνεται εύθραυστη.
Το πρόβλημα μεγαλώνει όταν τα μοντέλα χρησιμοποιούνται ως πράκτορες, δηλαδή όταν δεν απαντούν απλώς σε ερωτήσεις, αλλά καλούν εργαλεία, ανοίγουν αρχεία, εκτελούν εντολές, συμπληρώνουν φόρμες ή προτείνουν διοικητικές ενέργειες. Εκεί το λάθος δεν μένει σε ένα κείμενο. Μπορεί να επηρεάσει μια αίτηση, ένα επίδομα, μια άδεια, μια προμήθεια, μια φορολογική υποχρέωση ή μια δημόσια υπηρεσία.
Στον δημόσιο τομέα αυτό είναι κρίσιμο. Ένα λάθος σε μια γενική απάντηση είναι ενοχλητικό. Ένα λάθος σε μια διοικητική διαδικασία μπορεί να γίνει αδικία. Ένας ψηφιακός βοηθός που απαντά με σιγουριά αλλά χωρίς τεκμηρίωση μπορεί να οδηγήσει τον πολίτη σε λάθος βήματα. Ένα εργαλείο που συνοψίζει νομοθεσία χωρίς να ελέγχει το ισχύον κείμενο μπορεί να αναπαράγει παρωχημένη πληροφορία. Ένα σύστημα που προτείνει επιλογές σε υπάλληλο χωρίς παραπομπές μπορεί να μεταφέρει το σφάλμα μέσα στη διοίκηση.
Γιατί χρειάζονται συστήματα RAG
Η απάντηση δεν είναι να απορρίψουμε την Τεχνητή Νοημοσύνη. Είναι να τη σχεδιάσουμε σωστά. Εδώ μπαίνουν τα συστήματα RAG, δηλαδή τα συστήματα παραγωγής απαντήσεων με ανάκτηση τεκμηρίων από αξιόπιστες πηγές. Αντί το μοντέλο να απαντά μόνο από τη «μνήμη» του, πρώτα αναζητά σχετικά έγγραφα, νόμους, οδηγίες, βάσεις γνώσης ή επίσημες σελίδες και μετά παράγει απάντηση με βάση αυτά.
Αυτό αλλάζει ριζικά τη χρήση της ΤΝ στο Δημόσιο. Ένας βοηθός για πολίτες δεν πρέπει να «ξέρει» γενικά τι ισχύει για μια άδεια. Πρέπει να ανακτά την ισχύουσα διαδικασία από το μητρώο διοικητικών διαδικασιών, τη σχετική υπουργική απόφαση, τη σελίδα της υπηρεσίας και τα απαιτούμενα δικαιολογητικά. Ένα εργαλείο για δημόσιους υπαλλήλους δεν πρέπει να συνοψίζει έναν νόμο από μνήμης. Πρέπει να δείχνει άρθρο, παράγραφο, ημερομηνία ισχύος και πηγή.
Τα RAG συστήματα δεν εξαφανίζουν τις παραισθήσεις. Τις περιορίζουν. Το κάνουν επειδή δένουν την απάντηση σε συγκεκριμένο τεκμήριο. Επιτρέπουν στον χρήστη να ελέγξει την πηγή. Δίνουν στη διοίκηση ίχνος ελέγχου. Επιτρέπουν αξιολόγηση: αν η απάντηση είναι λάθος, μπορεί να ελεγχθεί αν έφταιξε η ανάκτηση, η πηγή, η διατύπωση της ερώτησης ή το ίδιο το μοντέλο.
Ευρωπαϊκά παραδείγματα για τον δημόσιο τομέα
Η Γαλλία κινείται με το Albert API, μια διακυβερνητική πλατφόρμα παραγωγικής ΤΝ για δημόσιες υπηρεσίες. Το σημαντικό δεν είναι μόνο ότι προσφέρει πρόσβαση σε μοντέλα, αλλά ότι παρέχει RAG ως υπηρεσία, ώστε οι διοικήσεις να χτίζουν εφαρμογές πάνω σε δικές τους βάσεις γνώσης και όχι σε αδιαφανή γενική μνήμη ενός μοντέλου.
Στο Ηνωμένο Βασίλειο, το GOV.UK Chat σχεδιάζεται ως RAG σύστημα πάνω στο περιεχόμενο του GOV.UK. Η αξία του δεν βρίσκεται μόνο στην ευκολία της συνομιλίας, αλλά στην απαίτηση να μπορεί ο πολίτης να ελέγχει την απάντηση στην αρχική πηγή. Ταυτόχρονα, οι δοκιμές έδειξαν ότι οι χρήστες μπορεί να υπερεμπιστεύονται ένα εργαλείο επειδή φέρει το κύρος του κράτους. Άρα η διαφάνεια και η προειδοποίηση για πιθανά λάθη είναι μέρος της υπηρεσίας, όχι υποσημείωση.
Στην Εσθονία, το Bürokratt δείχνει μια άλλη κατεύθυνση: ένας εθνικός ψηφιακός βοηθός που βοηθά τους πολίτες να βρίσκουν πληροφορίες για δημόσιες υπηρεσίες και, όταν δεν μπορεί να απαντήσει, τους κατευθύνει σε άνθρωπο. Αυτή η αρχή είναι θεμελιώδης. Το σύστημα δεν πρέπει να προσποιείται παντογνωσία. Πρέπει να ξέρει πότε να σταματά.
Στο επίπεδο της Ευρωπαϊκής Ένωσης, το ESSbot της European Labour Authority δείχνει πώς ένα RAG πλαίσιο μπορεί να βοηθήσει στην ανάκτηση σχετικής νομικής πληροφορίας για εργασιακά και διασυνοριακά ζητήματα. Η αξία του είναι ότι το σύστημα βελτιώνεται με ανατροφοδότηση χρηστών, όχι με τυφλή εμπιστοσύνη στο μοντέλο.
Για μια δημόσια ΤΝ με ανοιχτά πρότυπα
Για την Ελλάδα, το συμπέρασμα είναι σαφές. Κάθε δημόσιο σύστημα ΤΝ που αφορά δικαιώματα, υποχρεώσεις, επιδόματα, άδειες, φόρους, δημόσιες συμβάσεις ή διοικητικές διαδικασίες πρέπει να είναι RAG by default. Πρέπει να βασίζεται σε ανοιχτά πρότυπα, δημόσια ελεγχόμενα δεδομένα, καταγραφή ενεργειών, ανθρώπινη τελική ευθύνη και δυνατότητα ανεξάρτητου ελέγχου.
Η ΤΝ μπορεί να κάνει το κράτος πιο γρήγορο. Μόνο η σωστή αρχιτεκτονική μπορεί να το κάνει πιο αξιόπιστο. Και στον δημόσιο τομέα, η αξιοπιστία δεν είναι τεχνικό χαρακτηριστικό. Είναι δημοκρατική υποχρέωση.
Το CERN ανακοίνωσε τη διάθεση της πλήρους βιβλιοθήκης εξαρτημάτων για το λογισμικό σχεδίασης ηλεκτρονικών κυκλωμάτων KiCad ως λογισμικό ανοιχτού κώδικα, προσφέροντας σε μηχανικούς και σχεδιαστές hardware σε όλο τον κόσμο πρόσβαση σε περισσότερα από 17.000 ηλεκτρονικά εξαρτήματα.
Η βιβλιοθήκη, η οποία συντηρείται από το Design Office του CERN, περιλαμβάνει σύμβολα κυκλωμάτων και footprints για πλακέτες τυπωμένων κυκλωμάτων (PCB), διευκολύνοντας σημαντικά τη διαδικασία σχεδίασης ηλεκτρονικών συστημάτων. Πρόκειται για ένα πολύτιμο εργαλείο για επαγγελματίες αλλά και ερασιτέχνες δημιουργούς ηλεκτρονικών, καθώς μειώνει τον χρόνο ανάπτυξης και αυξάνει την αξιοπιστία των σχεδίων.
Το KiCad αποτελεί μία από τις πιο γνωστές δωρεάν και open source πλατφόρμες σχεδίασης PCB παγκοσμίως. Χάρη στη χρήση ανοιχτών μορφών αρχείων και στην απουσία αδειών χρήσης, οι ομάδες ανάπτυξης μπορούν να συνεργάζονται χωρίς περιορισμούς και χωρίς την ανάγκη αγοράς ακριβού εμπορικού λογισμικού.
Το CERN χρησιμοποιεί εδώ και χρόνια το KiCad για την ανάπτυξη hardware έργων υψηλής πολυπλοκότητας, δημιουργώντας σταδιακά μια τεράστια συλλογή εξαρτημάτων. Με τη δημόσια διάθεση αυτής της βιβλιοθήκης, ο οργανισμός ενισχύει περαιτέρω τη φιλοσοφία του γύρω από την ανοικτή τεχνολογία και τη συνεργατική καινοτομία.
Η κίνηση αυτή εντάσσεται στη γενικότερη στρατηγική open source του CERN. Υπενθυμίζεται ότι ο οργανισμός είχε δημοσιεύσει το λογισμικό του World Wide Web με άδεια ανοιχτού κώδικα το 1994, ενώ αργότερα δημιούργησε και την άδεια CERN Open Hardware Licence, επιτρέποντας την ελεύθερη χρήση, τροποποίηση και εμπορική αξιοποίηση hardware σχεδίων.
Παράλληλα, το CERN στηρίζει πρωτοβουλίες ανοιχτής πρόσβασης στην επιστημονική γνώση, όπως το SCOAP³, ενώ διαθέτει δημόσια και δεδομένα φυσικής υψηλών ενεργειών μέσω της πλατφόρμας Open Data Portal.
Η διάθεση της βιβλιοθήκης KiCad αναμένεται να ενισχύσει την παγκόσμια κοινότητα ηλεκτρονικών σχεδιαστών, δίνοντας πρόσβαση σε επαγγελματικού επιπέδου εργαλεία και επιταχύνοντας την ανάπτυξη νέων τεχνολογικών λύσεων.
Κάθε νέα Ubuntu LTS έκδοση έχει βάρος πολύ μεγαλύτερο από μια συνηθισμένη Linux κυκλοφορία. Το Ubuntu δεν είναι απλώς μια desktop διανομή. Είναι βάση για servers, cloud images, containers, WSL περιβάλλοντα, developer workstations, OEM laptops, εκπαιδευτικά εργαστήρια, μικρές επιχειρήσεις και μεγάλες εταιρικές εγκαταστάσεις.
Το Ubuntu 26.04 LTS “Resolute Raccoon”, που κυκλοφόρησε στις 23 Απριλίου 2026, είναι η 11η Long Term Support έκδοση του Ubuntu και υποστηρίζεται κανονικά μέχρι τον Απρίλιο του 2031, με δυνατότητα επέκτασης μέσω Ubuntu Pro και ESM.
Αυτό που κάνει τη συγκεκριμένη έκδοση ιδιαίτερη δεν είναι μόνο το GNOME 50 ή ο Linux Kernel 7.0. Είναι ότι η Canonical φαίνεται να χρησιμοποιεί το Ubuntu 26.04 ως καθαρή γραμμή μετάβασης προς ένα νέο Linux μοντέλο: λιγότερο X11, λιγότερο legacy userland, περισσότερη memory safety, περισσότερη ασφάλεια, καλύτερη υποστήριξη σύγχρονου hardware και πιο έντονη στόχευση σε AI, cloud και enterprise workloads.
Με απλά λόγια: το Ubuntu 26.04 LTS δεν είναι μια “ήσυχη” LTS. Είναι LTS μετάβασης.
Από Το Ubuntu 24.04 Στο 26.04: Δεν Είναι Μικρό Άλμα
Για τους χρήστες που έρχονται από Ubuntu 24.04 LTS, η διαφορά είναι μεγάλη. Η ίδια η Ubuntu τεκμηρίωση ξεχωρίζει ειδικά τις αλλαγές για LTS users, επειδή όσοι αναβαθμίζουν ανά διετία παίρνουν μαζί όλες τις αλλαγές των ενδιάμεσων εκδόσεων 24.10, 25.04 και 25.10.
Η αναβάθμιση δεν αφορά μόνο νέες εκδόσεις εφαρμογών. Το Ubuntu 26.04 αλλάζει βασικά κομμάτια της καθημερινής εμπειρίας: Firefox 150, LibreOffice 25.8, Thunderbird 140 “Eclipse” και GIMP 3.2 αποτελούν τις μεγάλες desktop εφαρμογές της νέας έκδοσης.
Όμως οι πιο ενδιαφέρουσες αλλαγές βρίσκονται αλλού: στο GNOME 50, στη μετάβαση σε Wayland-only Ubuntu Desktop session, στο νέο Resources app, στο Ptyxis terminal, στο Papers document viewer, στο Showtime video player, στο APT 3 και στα Rust-based system components.
Αυτό κάνει το Ubuntu 26.04 πολύ διαφορετικό από το 24.04. Δεν είναι απλώς “το ίδιο Ubuntu με νεότερα πακέτα”.
GNOME 50: Η Πιο Ώριμη Ubuntu Desktop Εμπειρία Μέχρι Σήμερα
Το Ubuntu 26.04 φέρνει GNOME 50, αναβαθμίζοντας ουσιαστικά το desktop από το GNOME 46 που είχε το Ubuntu 24.04 LTS. Η διαφορά είναι μεγάλη, γιατί μέσα σε αυτά τα τέσσερα GNOME release cycles άλλαξαν πολλά.
Το GNOME 50 στο Ubuntu 26.04 φέρνει καλύτερη εμπειρία σε μικρές οθόνες, hardware-accelerated screen recording, πιο responsive rendering σε πιο αδύναμα συστήματα, persistent remote login sessions, βελτιωμένο file chooser βασισμένο στο Files app, καλύτερη πρόσβαση σε network locations, βελτιώσεις σε accessibility settings, grouped notifications, digital wellbeing features, battery health preservation, HDR output και πιο ώριμο remote desktop.
Σε σχέση με το προηγούμενο interim release, Ubuntu 25.10, το GNOME 50 φέρνει βελτιωμένα parental controls, σημαντικές βελτιώσεις στον Orca screen reader, νέο Reduced Motion option, πιο μοντέρνες annotations στο Document Viewer, καλύτερο Files app, πιο ώριμο Calendar και βελτιωμένη διάκριση input/output στις ρυθμίσεις ήχου.
Αυτό που έχει σημασία στην πράξη είναι ότι το Ubuntu desktop δείχνει πιο ολοκληρωμένο. Οι μικρές λεπτομέρειες — animations, remote desktop, scaling, lock screen media controls, file handling — κάνουν το Ubuntu 26.04 να αισθάνεται πιο σύγχρονο από τις προηγούμενες LTS εκδόσεις.
Wayland-Only Ubuntu Desktop: Το Τέλος Της Μεταβατικής Περιόδου
Η μεγαλύτερη αλλαγή για desktop χρήστες είναι ότι το Ubuntu Desktop session τρέχει πλέον μόνο σε Wayland, επειδή το GNOME Shell δεν μπορεί πλέον να τρέχει ως X.org session. Οι X11 εφαρμογές εξακολουθούν να λειτουργούν μέσω XWayland, ενώ άλλα desktop sessions, όπως KDE σε X11, Xfce, MATE ή i3, μπορούν ακόμη να χρησιμοποιήσουν X.org.
Αυτό είναι πολύ πιο σημαντικό απ’ όσο φαίνεται.
Για χρόνια το Wayland ήταν “το μέλλον”, αλλά το X11 παρέμενε πάντα διαθέσιμο ως fallback. Στο Ubuntu 26.04, τουλάχιστον για το βασικό GNOME desktop, αυτή η εποχή τελειώνει. Η Canonical δεν σπρώχνει απλώς το Wayland ως default. Ουσιαστικά το κάνει τη μόνη επίσημη GNOME desktop βάση.
Τα θετικά είναι καθαρά: καλύτερο scaling, καλύτερη εμπειρία σε HiDPI οθόνες, καλύτερο frame pacing, πιο μοντέρνο security model και πλέον πλήρης Wayland υποστήριξη για μηχανήματα με NVIDIA graphics.
Τα αρνητικά είναι επίσης πραγματικά: παλιά screen capture εργαλεία, custom automation workflows, παλιές remote desktop λύσεις και ειδικές εταιρικές εγκαταστάσεις μπορεί να χρειαστούν προσαρμογές.
Αυτό είναι το σημείο όπου το Ubuntu 26.04 γίνεται πιο “απόλυτο” από παλιότερες LTS εκδόσεις. Είναι μοντέρνο, αλλά λιγότερο συμβιβαστικό με το παλιό desktop Linux.
Νέες Default Εφαρμογές: Το Ubuntu Καθαρίζει Το GNOME App Stack
Το Ubuntu 26.04 αλλάζει αρκετές κλασικές εφαρμογές του GNOME desktop.
Το Papers αντικαθιστά το Evince ως document viewer. Το Papers ξεκίνησε από τη βάση του Evince, αλλά έχει μεταφερθεί σε GTK4 και είναι εν μέρει γραμμένο σε Rust. Το Loupe αντικαθιστά το Eye of GNOME ως image viewer και είναι επίσης Rust-based. Το Ptyxis αντικαθιστά το GNOME Terminal και δίνει καλύτερη ενσωμάτωση με containers όπως podman, toolbox και distrobox.
Το Resources αντικαθιστά το System Monitor και το Power Statistics. Είναι σημαντική αλλαγή, γιατί το Resources δεν δείχνει απλώς CPU και RAM. Μπορεί να παρακολουθεί GPU usage, video encoder/decoder usage, NPU usage, network, storage, power usage και hardware statistics όπως clock frequencies. Είναι γραμμένο σε Rust και βασίζεται σε GTK4/libadwaita.
Αυτές οι αλλαγές δείχνουν καθαρά τη νέα κατεύθυνση του Ubuntu desktop: λιγότερα παλιά GTK3 εργαλεία, περισσότερες libadwaita εφαρμογές, καλύτερη υποστήριξη σύγχρονου hardware και περισσότερη χρήση Rust.
Security Center Και Permission Prompting
Το Ubuntu 26.04 περιλαμβάνει το νέο Security Center, το οποίο δίνει πιο εύκολο έλεγχο σε λειτουργίες ασφάλειας και ειδικότερα επιτρέπει την ενεργοποίηση ή απενεργοποίηση experimental permissions prompting για το Home directory.
Αυτό είναι ένα από τα σημεία όπου το Ubuntu προσπαθεί να μοιάσει περισσότερο με σύγχρονο consumer λειτουργικό. Οι χρήστες έχουν συνηθίσει σε Android, iOS και macOS να βλέπουν prompts για πρόσβαση σε κάμερα, αρχεία ή προσωπικά δεδομένα. Το Linux desktop παραδοσιακά ήταν πιο “όλα ή τίποτα”.
Η Canonical φαίνεται να θέλει να αλλάξει αυτό το μοντέλο, ιδίως σε ένα desktop όπου τα Snap packages, τα portals και τα sandboxed applications παίζουν όλο και μεγαλύτερο ρόλο. Δεν είναι ακόμη τέλειο. Αλλά δείχνει την κατεύθυνση.
TPM-Backed Disk Encryption Και Post-Quantum Crypto
Το Ubuntu 26.04 δίνει ιδιαίτερη έμφαση στην ασφάλεια με TPM-backed full-disk encryption, βελτιωμένο application permission prompting, Livepatch για ARM servers και Rust-based utilities για καλύτερο memory safety.
Στα release notes, η Ubuntu τεκμηρίωση αναφέρει επίσης post-quantum cryptography support στο OpenSSL, με ML-KEM, ML-DSA και SLH-DSA, καθώς και QUIC client/server support, ευρύτερη EVP κάλυψη και performance improvements.
Αυτό δεν σημαίνει ότι ο απλός desktop χρήστης θα “δει” άμεσα post-quantum cryptography στην καθημερινή χρήση. Αλλά δείχνει ότι το Ubuntu 26.04 χτίζει υποδομή για την επόμενη δεκαετία, ειδικά σε enterprise, government και cloud περιβάλλοντα.
Linux Kernel 7.0: Νέο Hardware, Real-Time Kernel Και ARM Livepatch
Το Ubuntu 26.04 χρησιμοποιεί Linux Kernel 7.0. Για χρήστες του GA generic stack, αυτό σημαίνει αναβάθμιση από kernel 6.8 στο Ubuntu 24.04 σε 7.0. Για χρήστες HWE stack, σημαίνει μετάβαση από 6.17 σε 7.0.
Η έκδοση φέρνει crash dumps ενεργά από προεπιλογή σε desktop και server εγκαταστάσεις, βελτιώσεις για Intel Panther Lake, Xe3 integrated graphics και NPU, ενσωματωμένο IgH EtherCAT module για industrial real-time δίκτυα, διαθέσιμο real-time kernel στο main archive χωρίς να απαιτείται Ubuntu Pro, και Kernel Livepatch υποστήριξη για ARM64.
Αυτό είναι πολύ Ubuntu-specific. Δεν μιλάμε απλώς για “νέο kernel”. Μιλάμε για αλλαγές που ενδιαφέρουν βιομηχανικά συστήματα, ARM servers, real-time workloads, cloud deployments και edge υποδομές.
Για desktop χρήστες, το μεγάλο κέρδος είναι καλύτερη υποστήριξη νέου hardware. Για enterprise χρήστες, το ενδιαφέρον βρίσκεται σε Livepatch, real-time, ARM και confidential/industrial workloads.
Rust Στο Userland: sudo-rs Και rust-coreutils
Το Ubuntu 26.04 είναι η πρώτη LTS έκδοση όπου το sudo-rs είναι ο default sudo provider. Το παραδοσιακό sudo εξακολουθεί να υπάρχει ως sudo.ws, ενώ το sudo-ldap package έχει αφαιρεθεί και οι χρήστες καλούνται να περάσουν σε LDAP authentication μέσω PAM.
Παράλληλα, τα core utilities παρέχονται πλέον από το rust-coreutils package, με τα κλασικά GNU utilities να παραμένουν διαθέσιμα μέσω gnu prefix ή μέσω αλλαγής provider. Πάντως, επειδή τα rust-coreutils δεν είναι ακόμη πλήρως συμβατά, τα cp, mv και rm εξακολουθούν να προέρχονται από GNU…
Αυτό είναι τεράστια αλλαγή από μόνη της. Το Ubuntu δεν βάζει απλώς Rust σε μερικά νέα desktop apps. Αρχίζει να αλλάζει βασικά userland εργαλεία. Αυτό θα προκαλέσει συζητήσεις, ειδικά σε sysadmins που δεν θέλουν να αλλάζουν τα εργαλεία τους
Η Canonical ποντάρει όμως ότι το memory safety αξίζει το ρίσκο. Και μακροπρόθεσμα, μάλλον έχει δίκιο. Αλλά σε ένα LTS, αυτή είναι τολμηρή επιλογή.
APT 3: Μεγάλη Αλλαγή Στο Package Management
Το APT αναβαθμίζεται από 2.7 σε 3.1. Το νέο dependency solver χρησιμοποιείται αυτόματα όταν ο κλασικός solver δεν μπορεί να βρει λύση ή όταν χρειάζεται περισσότερο context. Το APT περνά επίσης από GnuTLS/gcrypt σε OpenSSL για TLS connections και file hashing, κάτι που σύμφωνα με τους developers βελτιώνει τη συμβατότητα και μειώνει το footprint σε minimal installations.
Προστίθεται επίσης automatic pager για εντολές όπως apt show και apt list, σε στυλ git log ή journalctl.
Αυτά ακούγονται μικρά, αλλά για όσους δουλεύουν καθημερινά με Ubuntu servers και containers, το APT 3 είναι σημαντική αλλαγή.
systemd 259: Τέλος Για cgroup v1 Και Προειδοποίηση Για System V Scripts
Το Ubuntu 26.04 φέρνει systemd 259. Η έκδοση αυτή αφαιρεί το support για cgroup v1 legacy και hybrid hierarchies, ενώ στην τεκμηρίωση διαβάζουμε ότι το 26.04 LTS είναι η τελευταία έκδοση που υποστηρίζει System V service scripts compatibility στο systemd.
Επίσης, το /tmp είναι πλέον tmpfs από προεπιλογή, μέσω του upstream tmp.mount unit. Αυτό είναι κρίσιμο για admins. Παλιά scripts, legacy services, παλιές container setups και εφαρμογές που θεωρούν ότι το /tmp είναι persistent filesystem μπορεί να χρειαστούν έλεγχο.
Για καινούριες εγκαταστάσεις, είναι σωστή κατεύθυνση. Για παλιές υποδομές, θέλει testing πριν από αναβάθμιση.
Server Stack: OpenSSH 10.2, Samba 4.23, PHP 8.5, Django 5.2
Το Ubuntu 26.04 δεν είναι μόνο desktop πράγματα. Στο server κομμάτι, το OpenSSH περνά από 9.6p1 σε 10.2p1. Οι αλλαγές περιλαμβάνουν warning για SHA1 SSHFP DNS records, warning όταν η σύνδεση δεν διαπραγματεύεται post-quantum key agreement, αφαίρεση DSA signature support, νέο PerSourcePenalties, hybrid post-quantum key exchange mlkem768x25519-sha256 ενεργό από προεπιλογή, νέο invalid-user match option και alias sshd.service προς ssh.service.
Το PHP αναβαθμίζεται σε 8.5, με νέα χαρακτηριστικά όπως property hooks, asymmetric visibility, updated DOM API, νέο URI extension, pipe operator, array_first() και array_last().
Το Django περνά στην LTS έκδοση 5.2, ενώ η Samba αναβαθμίζεται σε 4.23 με SMB3 Unix Extensions ενεργά από προεπιλογή, NetBIOS disabled by default σε fresh installs, SMB3 Directory Leases και άλλες αλλαγές.
Αυτές οι αλλαγές κάνουν το Ubuntu 26.04 πολύ ενδιαφέρον για servers, αλλά και πιο απαιτητικό σε migration planning.
AI, CUDA, ROCm Και Silicon Optimization
Η Canonical προβάλλει έντονα το Ubuntu 26.04 ως πλατφόρμα για AI και production workloads. Στην επίσημη ανακοίνωση αναφέρει native support για NVIDIA CUDA και AMD ROCm, χαρακτηρίζοντας το Ubuntu 26.04 LTS ιδανική βάση για AI development και production workloads.
Αυτό είναι στρατηγικά σημαντικό. Το Ubuntu έχει ήδη τεράστια παρουσία σε cloud, containers και developer workstations. Με το 26.04, η Canonical θέλει να τοποθετήσει ακόμη πιο καθαρά το Ubuntu ως default Linux για AI engineers, GPU compute και HPC.
Δεν είναι απλώς desktop story. Είναι enterprise και infrastructure story.
Απαιτήσεις Συστήματος: Το Ubuntu Γίνεται Πιο Ειλικρινές
Το Ubuntu Desktop 26.04 LTS απαιτεί, για άνετη εμπειρία, 2 GHz dual-core CPU, τουλάχιστον 6 GB RAM και 25 GB αποθηκευτικού χώρου. Στην τεκμηρίωση σημειώνεται ότι μπορεί να εγκατασταθεί και σε χαμηλότερα specs, αλλά προτείνει flavors όπως Xubuntu ή Lubuntu για συστήματα με 2 GB RAM ή περισσότερο.
Με άλλα λόγια, το Ubuntu δεν προσποιείται πια ότι είναι ελαφρύ. Το βασικό GNOME Ubuntu είναι μοντέρνο desktop OS με απαιτήσεις αντίστοιχες της εποχής.
Για παλιότερα laptops, τα flavors δεν είναι απλώς “εναλλακτικές”. Είναι η σωστή επιλογή.
Kubuntu 26.04 LTS: Ίσως Το Πιο Ελκυστικό Ubuntu Flavor
Το Kubuntu 26.04 LTS είναι από τα πιο ενδιαφέροντα flavors αυτής της κυκλοφορίας. Έρχεται με Plasma 6.6, Qt 6.10.2, KDE Frameworks 6.24.0 και KDE Gear 25.12.3, πάνω στην Ubuntu 26.04 βάση και Linux Kernel 7.0.
Αυτό το κάνει πολύ σημαντικό για χρήστες που θέλουν LTS βάση αλλά πιο παραμετροποιήσιμο desktop από το GNOME.
Το KDE Plasma 6.6 είναι πλέον ώριμο, γρήγορο και πολύ πιο συνεπές σε Wayland από παλιότερες γενιές KDE. Το Kubuntu 26.04 προσφέρει την πιο “κλασική desktop” εμπειρία μέσα στο Ubuntu οικοσύστημα, χωρίς να φαίνεται παλιό.
Για πολλούς power users, το Kubuntu 26.04 μπορεί να είναι πιο ελκυστικό από το βασικό Ubuntu.
Xubuntu 26.04: Ένα Πολύ Σοβαρό Lightweight Desktop
Το Xubuntu 26.04 κυκλοφόρησε επίσης στις 23 Απριλίου 2026 και υποστηρίζεται για τρία χρόνια, μέχρι τον Απρίλιο του 2029. Η έκδοση σηματοδοτεί τα 20 χρόνια του Xubuntu και περιλαμβάνει νέα wallpapers από community contests.
Τεχνικά, βασίζεται σε Xfce 4.20 με μικρές αλλά ουσιαστικές αναβαθμίσεις για σταθερότητα και Wayland support. Περιλαμβάνει Thunar 4.20.7, Xfce Panel 4.20.7, Xfce Terminal 1.1.5, Whisker Menu Plugin 2.10.1, Mesa 26.0.3, PipeWire 1.6.2, GIMP 3.2.2 και LibreOffice 26.2.2.2.
Το Xubuntu παραμένει ίσως η καλύτερη επιλογή για χρήστες που θέλουν Ubuntu βάση, αλλά όχι GNOME. Δεν είναι τόσο ελαφρύ όσο το Lubuntu, αλλά είναι πιο πλήρες και πιο άνετο ως καθημερινό desktop.
Lubuntu 26.04: Το Ubuntu Για Παλαιότερα Μηχανήματα σε Qt 6
Το Lubuntu 26.04 LTS είναι η 30ή έκδοση του Lubuntu και η 16η με LXQt ως default desktop. Υποστηρίζεται μέχρι τον Απρίλιο του 2029.
Η μεγάλη αλλαγή είναι ότι φέρνει LXQt 2.3 και αποτελεί την πρώτη Lubuntu LTS έκδοση με κυρίως Qt 6-based περιβάλλον. Περιλαμβάνει επίσης Qt 6.10.2, Firefox snap, LibreOffice 26.2, VLC 3.0.23, Featherpad 1.6.2 και Discover 6.6.3.
Το Lubuntu είναι ίσως πιο σημαντικό από ποτέ, επειδή το βασικό Ubuntu Desktop ανεβαίνει σε 6 GB RAM ως άνετη απαίτηση. Για παλιά laptops, σχολικά εργαστήρια, ελαφριά workstations και χρήστες που θέλουν απλότητα, το Lubuntu 26.04 είναι η πρακτική επιλογή.
Ubuntu Budgie 26.04: Μικρές Αλλαγές Που Βελτιώνουν Την Καθημερινότητα
Το Ubuntu Budgie 26.04 χρησιμοποιεί SDDM με custom Ubuntu Budgie greeter theme και φέρνει Budgie Desktop 10.10.2 με αρκετές καθημερινές βελτιώσεις: καλύτερο application matching στο Icon Tasklist, βελτιωμένο Budgie Menu sizing σε διαφορετικά resolutions και scaling factors, σωστή συμπεριφορά στο Show Desktop, screenshot tool που θυμάται save path και καλύτερο Qt6 theming όταν οι εφαρμογές υποστηρίζουν kcolorscheme.
Υπάρχουν επίσης accessibility και input βελτιώσεις, όπως built-in screen magnification, adaptive mouse acceleration by default και καλύτερη διαχείριση brightness μέσω standard backlight interface.
Το Ubuntu Budgie παραμένει εξαιρετική επιλογή για όσους θέλουν πιο παραδοσιακό desktop από το GNOME, αλλά πιο μοντέρνο αισθητικά από Xfce ή MATE.
Ubuntu Studio 26.04: Η Πιο Ενδιαφέρουσα Έκδοση Για Creators
Το Ubuntu Studiο 26.04 είναι από τα flavors με τις πιο ουσιαστικές αλλαγές. Η ομάδα του Ubuntu Studio αναφέρει τρία selectable desktop layouts: classic Ubuntu Studio top-panel layout, macOS-like layout με global menu και dock, και Windows-like bottom-panel layout.
Ακόμη σημαντικότερο: το Ubuntu Studio Installer και το Ubuntu Studio Audio Configuration ξαναγράφτηκαν πλήρως σε Python, με GTK4 και Qt6 frontends που επιλέγονται ανάλογα με το desktop environment.
Στο audio κομμάτι, το Ubuntu Studio Audio Configuration προσθέτει built-in support για FFADO FireWire devices και πιο εύκολο PipeWire tuning μέσα από menus αντί για manual configuration. Προστίθενται επίσης εργαλεία όπως Loopino και DistroAV, ενώ το VLC γίνεται default media player.
Για μουσικούς, podcasters, video editors και live streamers, το Ubuntu Studio 26.04 είναι πολύ πιο ουσιαστική αναβάθμιση από ένα απλό package refresh.
Τι Πρέπει Να Προσέξει Κάποιος Πριν Αναβαθμίσει
Το Ubuntu 26.04 είναι ισχυρή έκδοση, αλλά δεν είναι αθώα αναβάθμιση.
Πριν από αναβάθμιση από 24.04 LTS, αξίζει έλεγχος σε:
custom X11 workflows,
screen sharing / screen recording εργαλεία,
remote desktop λύσεις,
παλιά System V scripts,
υπηρεσίες που βασίζονται σε cgroup v1,
scripts που περιμένουν συγκεκριμένη GNU coreutils συμπεριφορά,
sudo/LDAP integrations,
software που χρησιμοποιεί /tmp ως persistent χώρο,
SSH policies λόγω OpenSSH 10.2,
PHP apps λόγω μετάβασης σε PHP 8.5,
Samba deployments λόγω αλλαγών σε 4.23.
Το Ubuntu 26.04 είναι καλή βάση για νέα installs. Για production upgrades, θέλει staging.
Συμπέρασμα
Το Ubuntu 26.04 LTS “Resolute Raccoon” είναι μία από τις πιο σημαντικές Ubuntu εκδόσεις των τελευταίων ετών.
Δεν είναι απλώς Ubuntu 24.04 με νέο GNOME. Είναι μια έκδοση που δείχνει πού θέλει να πάει η Canonical:
Wayland ως βασικό desktop μέλλον,
Rust σε κρίσιμα userland εργαλεία,
πιο σοβαρό permission model,
καλύτερη security στάση,
Kernel 7.0 με real-time και ARM improvements,
APT 3,
σύγχρονο server stack,
AI/HPC στόχευση,
και flavors που έχουν πλέον πολύ καθαρό ρόλο.
Το βασικό Ubuntu Desktop είναι πιο μοντέρνο, αλλά και πιο απαιτητικό. Το Kubuntu είναι ίσως η πιο δυνατή επιλογή για power users. Το Xubuntu παραμένει η ισορροπημένη lightweight λύση. Το Lubuntu σώζει παλιότερα μηχανήματα. Το Ubuntu Studio γίνεται πιο σοβαρό εργαλείο για creators. Το Budgie προσφέρει polished καθημερινή εμπειρία.
Αν το Fedora 44 δείχνει την ώριμη πλευρά του “leading edge” Linux, το Ubuntu 26.04 δείχνει κάτι διαφορετικό: πώς μια mainstream LTS διανομή προσπαθεί να περάσει τον κόσμο του Linux desktop και server stack στην επόμενη εποχή, χωρίς να κόψει εντελώς τη σχέση με το παρελθόν.
Και αυτό το κάνει πολύ πιο ενδιαφέρον από μια απλή LTS αναβάθμιση.
Short Bytes
Το Ubuntu 26.04 LTS υποστηρίζεται κανονικά μέχρι τον Απρίλιο του 2031.
Το βασικό Ubuntu Desktop GNOME session είναι πλέον Wayland-only.
Το Ubuntu Desktop προτείνει πλέον 6 GB RAM για άνετη εμπειρία.
Το sudo-rs είναι ο default sudo provider.
Τα rust-coreutils μπαίνουν στην LTS βάση, με ορισμένα GNU εργαλεία να παραμένουν.
Το APT περνά στην έκδοση 3.1.
Το /tmp είναι πλέον tmpfs από προεπιλογή.
Το Kubuntu 26.04 φέρνει Plasma 6.6 και Qt 6.10.2.
Το Xubuntu 26.04 γιορτάζει 20 χρόνια Xubuntu.
Το Lubuntu 26.04 είναι η πρώτη LTS έκδοση του Lubuntu με κυρίως Qt 6-based περιβάλλον.
Το Ubuntu Studio 26.04 φέρνει rewritten installer/audio tools και τρία desktop layouts.
Το Wiki Loves Eurovision είναι ένας νέος διεθνής διαγωνισμός λημματογράφησης, που πραγματοποιείται σε όλες τις γλώσσες της Κεντρικής και Ανατολικής Ευρώπης (ΚΑΕ) και είναι αφιερωμένος στον Διαγωνισμό Τραγουδιού της Eurovision. Στόχος της πρωτοβουλίας είναι η δημιουργία νέων λημμάτων και η βελτίωση ήδη υπαρχόντων λημμάτων που σχετίζονται με τη Eurovision, την ιστορία της, τους καλλιτέχνες και τις συμμετοχές της.
Ο διαγωνισμός διοργανώνεται κεντρικά από την Ομάδα Νέων της ΚΑΕ, ενώ το ελληνικό σκέλος υλοποιείται ως υποδιαγωνισμός του CEE Spring για τις χώρες που συμμετέχουν στη συγκεκριμένη δράση. Στην Ελλάδα, η διοργάνωση υποστηρίζεται από το Wikimedia Community User Group Greece.
Οι συμμετέχοντες καλούνται να δημιουργήσουν ή να επεκτείνουν λήμματα σχετικά με τη Eurovision και να καταχωρούν τις συνεισφορές τους στην ειδική σελίδα του διαγωνισμού.
Ο διαγωνισμός θα διαρκέσει έως τις 10 Ιουνίου 2026.
Περισσότερες πληροφορίες για τον διαγωνισμό είναι διαθέσιμες στη σελίδα του στο Meta.
Οι κοινότητες ανοιχτού λογισμικού στην Ελλάδα δεν χτίζουν μόνο κώδικα. Χτίζουν ψηφιακά κοινά, γνώση και αυτονομία. Σήμερα έχουμε μπροστά μας μια νέα, απολύτως κρίσιμη πρόκληση: να μην αφήσουμε την ελληνική γλώσσα, την εκφραστική της ακρίβεια και τις πολιτισμικές της αποχρώσεις να καθορίζονται αποκλειστικά από κλειστά συστήματα.
Στο argilla.glossapi.gr καλούμε εθελοντές από τις κοινότητες ανοιχτού λογισμικού, ερευνητές, γλωσσολόγους, μεταφραστές, προγραμματιστές, εκπαιδευτικούς και κάθε ενεργό χρήστη της ελληνικής γλώσσας να συμμετάσχουν στη διαδικασία Μάθησης από Ανθρώπινη Ανάδραση (RLHF). Στην πράξη αυτό σημαίνει κάτι απλό αλλά εξαιρετικά σημαντικό: να βοηθήσουμε τα γλωσσικά μοντέλα να ξεχωρίζουν ποια απάντηση είναι φυσική, σαφής, ακριβής και ποια ακούγεται ξένη, άκαμπτη ή «ρομποτική». Η RLHF βασίζεται ακριβώς σε αυτή την ανθρώπινη αξιολόγηση, ώστε το μοντέλο να βελτιώνεται με βάση ανθρώπινες κρίσεις και όχι μόνο στατιστικά μοτίβα.
Η συνεισφορά σας δεν είναι μια μηχανική δουλειά επισήμανσης. Είναι πράξη ψηφιακής επιμέλειας και γλωσσικής κυριαρχίας. Κάθε φορά που διορθώνετε μια αφύσικη απάντηση, κάθε φορά που επιλέγετε την καλύτερη διατύπωση, συμβάλλετε σε ένα ανοιχτό οικοσύστημα ελληνικών δεδομένων και εργαλείων Τεχνητής Νοημοσύνης.
Η δράση αυτή αποκτά σήμερα ακόμη μεγαλύτερη σημασία, γιατί συνδέεται άμεσα με τη στρατηγική συνεργασία του GlossAPI με το Swiss AI Initiative για το Apertus, ένα ανοιχτό πολυγλωσσικό οικοσύστημα βασικών μοντέλων. Στόχος της συνεργασίας είναι ενσωμάτωση της λεξικογραφικής γνώσης του GlossAPI στο Apertus, στην παραγωγή ανοικτών πολυγλωσσικών δεδομένων αξιολόγησης και στη δημοσίευση συνόλων δεδομένων, δεικτών απόδοσης και σημείων ελέγχου με ανοικτές άδειες.
Με άλλα λόγια, η εθελοντική συμμετοχή στην αξιολόγηση και βελτίωση απαντήσεων δεν ενισχύει απλώς ένα ακόμη εργαλείο. Ενισχύει μια ευρύτερη δημόσια γλωσσική υποδομή για τα ελληνικά. Το GlossAPI είναι μια ανοιχτή βιβλιοθήκη και τεχνική υποδομή για τη δημιουργία, επεξεργασία και δημοσίευση συνόλων δεδομένων έτοιμων για την εκπαίδευση μεγάλων γλωσσικών μοντέλων, έχουν ήδη παραχθεί ανοικτά και τεκμηριωμένα σύνολα δεδομένων με προσανατολισμό στη διαφάνεια, στη συμμετοχή και στα ανοικτά πρότυπα.
Αυτό σημαίνει ότι η δουλειά που γίνεται σήμερα από την κοινότητα δεν είναι αποσπασματική. Είναι μέρος μιας διεθνούς προσπάθειας ώστε η ελληνική γλώσσα να μην παραμένει απλός χρήστης ξένων μοντέλων, αλλά να γίνεται συνδιαμορφωτής τους. Η συνεργασία με το Swiss AI Initiative δείχνει ότι τα ελληνικά μπορούν να αντιμετωπιστούν ως κρίσιμη δημόσια ψηφιακή υποδομή στην εποχή των βασικών μοντέλων.
Αυτό είναι το σημείο όπου οι αξίες του ανοιχτού λογισμικού συναντούν την Τεχνητή Νοημοσύνη στην πράξη. Όπως χτίσαμε ελεύθερο λογισμικό, ανοιχτά πρότυπα και δημόσια ψηφιακά αγαθά, έτσι τώρα μπορούμε να χτίσουμε καλύτερα, πιο αξιόπιστα και πιο ανοιχτά ελληνικά γλωσσικά μοντέλα. Η συνεργασία με το οικοσύστημα του Apertus δεν βελτιώνει μόνο ένα μοντέλο. Ενισχύει έναν επαναχρησιμοποιήσιμο μηχανισμό παραγωγής γλωσσικών πόρων που μπορεί να αξιοποιηθεί από πανεπιστήμια, ερευνητές, δημόσιους φορείς, εκπαιδευτικά ιδρύματα, δημοσιογράφους, εκδότες και ελληνικές επιχειρήσεις τεχνολογίας.
Αν πιστεύεις στο ανοιχτό λογισμικό, έλα να χτίσουμε ανοιχτή ελληνική νοημοσύνη. Αν πιστεύεις ότι η γλώσσα είναι κοινό αγαθό, έλα να τη φροντίσουμε συλλογικά. Αν θέλεις να συμβάλεις ουσιαστικά στη βελτίωση των ελληνικών του Apertus και στη διαμόρφωση ανοιχτών ελληνικών γλωσσικών υποδομών, έλα σήμερα στο argilla.glossapi.gr.
Δεν χρειάζεται να είσαι ειδικός στην Τεχνητή Νοημοσύνη. Αρκεί να έχεις γλωσσικό κριτήριο, διάθεση συνεισφοράς και την πεποίθηση ότι η ελληνική γλώσσα αξίζει ανοιχτές, ποιοτικές και δημόσια ωφέλιμες υποδομές Τεχνητής Νοημοσύνης. Θα βρείτε απλές οδηγίες ανά τύπο dataset μέσα στην εφαρμογή για το πως να το βελτιώσετε.
Το IEEE Student Branch Kastoria ανακοινώνει τη διοργάνωση ενός πρακτικού (hands-on) δίωρου workshop με τίτλο “First steps in Kernel Space” και αντικείμενο την εισαγωγή στον προγραμματισμό του πυρήνα Linux (Linux Kernel). Η εκδήλωση είναι ειδικά σχεδιασμένη για φοιτητές και θα πραγματοποιηθεί την Παρασκευή, 15 Μαΐου 2026, στις 15:30, στην Αίθουσα Β12.
Σκοπός του Workshop είναι να προσφέρει την ευκαιρία σε όσους ενδιαφέρονται για τα Λειτουργικά Συστήματα να κάνουν τα πρώτα τους βήματα στο Linux Kernel, συνδυάζοντας το θεωρητικό υπόβαθρο με την άμεση πρακτική εφαρμογή. Η συμμετοχή δεν προϋποθέτει προηγούμενη εμπειρία στο συγκεκριμένο πεδίο.
Οι θεματικές ενότητες που θα καλυφθούν κατά τη διάρκεια του workshop περιλαμβάνουν:
Την κατανόηση της διαφοράς και της λειτουργίας μεταξύ του User Space και του Kernel Space.
Τη διαδικασία συγγραφής, μεταγλώττισης (compile) και εκτέλεσης ενός out-of-tree kernel module, μέσω καθοδήγησης βήμα προς βήμα.
Για την ομαλή παρακολούθηση και συμμετοχή στο πρακτικό μέρος, οι συμμετέχοντες θα χρειαστεί να διαθέτουν:
Βασική εξοικείωση με τη γλώσσα προγραμματισμού C.
Φορητό υπολογιστή με περιβάλλον Linux. Για την απόλυτη ασφάλεια κατά τον πειραματισμό με τον κώδικα, συνιστάται η χρήση εικονικής μηχανής (Virtual Machine).
Το πρώτο ακαδημαϊκό Open Source Program Office (OSPO) στη Γαλλία εγκαινιάστηκε επίσημα τον Σεπτέμβριο του 2025 από το Université Grenoble Alpes (UGA), σηματοδοτώντας ένα καθοριστικό βήμα για την ενίσχυση του ανοικτού λογισμικού στην έρευνα και την ανώτατη εκπαίδευση. Παράλληλα με τα εγκαίνια, η ομάδα του νέου OSPO δημοσίευσε αναλυτική έκθεση που προτείνει πλαίσιο λειτουργίας για μελλοντικά ακαδημαϊκά OSPOs, καθώς και τη δημιουργία εθνικού δικτύου στη Γαλλία.
Η έκθεση βασίζεται σε εργαστήριο στο οποίο συμμετείχαν περίπου 30 εκπρόσωποι από πανεπιστήμια, ερευνητικά ιδρύματα και γαλλικά υπουργεία. Συντάχθηκε από τους Violaine Louvet, Lucie Albaret και Alexis Arnaud της μονάδας Codes Données Grenoble Alpes και διατίθεται με άδεια CC BY 4.0 μέσω του αποθετηρίου HAL.
Τι είναι ένα ακαδημαϊκό OSPO
Ένα Open Source Program Office αποτελεί οργανωτική δομή που υποστηρίζει τη στρατηγική, την ανάπτυξη και τη διαχείριση έργων ανοικτού λογισμικού. Στον ακαδημαϊκό χώρο, ο ρόλος του επεκτείνεται πέρα από την τεχνική υποστήριξη, αγγίζοντας ζητήματα έρευνας, διαφάνειας και επιστημονικής συνεργασίας.
Σύμφωνα με την έκθεση, υπήρξε ευρεία συναίνεση ότι τα ακαδημαϊκά OSPOs θα πρέπει να υπάγονται στις διευθύνσεις έρευνας των ιδρυμάτων και όχι στα τμήματα πληροφορικής. Ο λόγος είναι ότι με αυτή τη δομή μπορούν να λειτουργούν ως γέφυρα μεταξύ διαφορετικών επιστημονικών κοινοτήτων, δίνοντας έμφαση στο ερευνητικό λογισμικό και όχι μόνο στις διοικητικές υποδομές.
Παράλληλα, τονίστηκε ότι τα OSPOs πρέπει να υποστηρίζουν όλα τα επιστημονικά πεδία, ακόμη και εκείνα που δεν διαθέτουν ισχυρή τεχνική κουλτούρα στην ανάπτυξη λογισμικού. Η υποστήριξη δεν περιορίζεται μόνο στη δημοσίευση λογισμικού ως ανοικτού κώδικα, αλλά περιλαμβάνει και πρακτικές «inner source» — δηλαδή την εφαρμογή ανοικτών μεθόδων ανάπτυξης εντός κλειστών ερευνητικών ομάδων ή οργανισμών.
Οι βασικοί άξονες λειτουργίας
Η έκθεση περιγράφει τέσσερις βασικούς τομείς εξειδίκευσης που πρέπει να συνδυάζει ένα ακαδημαϊκό OSPO:
Νομική υποστήριξη: άδειες χρήσης και ζητήματα πνευματικής ιδιοκτησίας.
Τεχνικές πρακτικές ανάπτυξης λογισμικού, συμπεριλαμβανομένων του ελέγχου εκδόσεων (version control), της συνεχούς ολοκλήρωσης (continuous integration) και της κυβερνοασφάλειας.
Τεκμηρίωση και διαχείριση επιστημονικών αναγνωριστικών, όπως ORCID, ROR και SWHID.
Κατανόηση του τρόπου λειτουργίας των κοινοτήτων ανοικτού λογισμικού.
Ιδιαίτερη σημασία δίνεται επίσης στην εκπροσώπηση διαφορετικών σχολών και επιστημονικών κλάδων, ώστε το OSPO να παραμένει προσιτό και χρήσιμο ακόμη και για ερευνητές χωρίς βαθιά τεχνική εξειδίκευση.
Η διεθνής εμπειρία και το παράδειγμα του CERN
Η έκθεση αναφέρεται στο διεθνές δίκτυο CURIOSS (Community for University and Research Institution OSPOs), το οποίο δημιουργήθηκε το 2023 με τη στήριξη του Alfred P. Sloan Foundation. Το δίκτυο βοηθά πανεπιστήμια και ερευνητικά ιδρύματα να ανταλλάσσουν πρακτικές και να συνεργάζονται γύρω από τα ακαδημαϊκά OSPOs.
Σύμφωνα με τα στοιχεία που παρατίθενται, τα περισσότερα ακαδημαϊκά OSPOs λειτουργούν με 1 έως 3 εργαζόμενους πλήρους απασχόλησης. Το CERN διαθέτει μία από τις μεγαλύτερες σχετικές ομάδες στην Ευρώπη, με 12 έως 15 άτομα, ενώ το ίδιο το OSPO του UGA λειτουργεί με λίγο περισσότερες από δύο θέσεις πλήρους απασχόλησης.
Η ανάγκη για μια «κυρίαρχη» ευρωπαϊκή πλατφόρμα ανάπτυξης
Ένα από τα πιο ενδιαφέροντα σημεία της έκθεσης αφορά τις πλατφόρμες ανάπτυξης λογισμικού (software forges). Σύμφωνα με στοιχεία που παρουσιάστηκαν στα εγκαίνια του UGA OSPO, περισσότερο από το 76% των Γάλλων ερευνητών χρησιμοποιεί είτε το GitHub είτε το GitLab.com, με το GitHub να κατέχει κυρίαρχη θέση.
Η έκθεση υποστηρίζει τη δημιουργία ευρωπαϊκής «κυρίαρχης» πλατφόρμας ανάπτυξης λογισμικού, με πολυμερή διακυβέρνηση που θα περιλαμβάνει ερευνητές, πανεπιστήμια και παρόχους υποδομών. Οι συντάκτες επισημαίνουν ότι οι υπάρχουσες θεσμικές πλατφόρμες συχνά δεν διαθέτουν τις απαραίτητες δυνατότητες ή περιορίζονται αποκλειστικά σε εσωτερικούς χρήστες.
Προς ένα εθνικό δίκτυο ανοικτού λογισμικού
Η πρόταση του UGA δεν αφορά ένα μεμονωμένο πανεπιστήμιο. Η έκθεση εισηγείται τη δημιουργία εθνικού δικτύου ακαδημαϊκών OSPOs, εμπνευσμένου εν μέρει από το οικοσύστημα Recherche Data Gouv για τη διαχείριση ερευνητικών δεδομένων. Ωστόσο, οι συγγραφείς υπογραμμίζουν ότι το λογισμικό και τα δεδομένα αποτελούν διαφορετικά πεδία, με ξεχωριστές νομικές, τεχνικές και οργανωτικές ανάγκες.
Προτείνεται επίσης η θέσπιση συστήματος πιστοποίησης ή «επισήμανσης» (labeling), εγκεκριμένου από το αρμόδιο υπουργείο, που θα αναγνωρίζει επίσημα τα ακαδημαϊκά OSPOs. Σε ευρωπαϊκό επίπεδο, η έκθεση προτείνει συνεργασία με δίκτυα όπως το FLOSS Public Sector Office και το European Open Science Cloud (EOSC).
Το ζήτημα της αναγνώρισης του ερευνητικού λογισμικού
Παρά την αυξανόμενη σημασία του λογισμικού στην επιστημονική έρευνα, η έκθεση επισημαίνει ότι εξακολουθεί να υποτιμάται ως ερευνητικό αποτέλεσμα. Οι ερευνητές που αναπτύσσουν λογισμικό συχνά δεν τυγχάνουν της ίδιας ακαδημαϊκής αναγνώρισης με όσους δημοσιεύουν επιστημονικά άρθρα.
Πρωτοβουλίες όπως το French Open Science Award for Software αναφέρονται ως θετικά παραδείγματα που μπορούν να αυξήσουν την ορατότητα και την αναγνώριση της συμβολής του λογισμικού στην επιστήμη.
Ένα νέο μοντέλο για την ευρωπαϊκή έρευνα
Η δημιουργία του πρώτου ακαδημαϊκού OSPO στη Γαλλία αποδεικνύει ότι το ανοικτό λογισμικό μετατρέπεται σταδιακά σε στρατηγικό πυλώνα της ερευνητικής πολιτικής. Το ερώτημα πλέον είναι αν και άλλα γαλλικά πανεπιστήμια θα ακολουθήσουν το παράδειγμα του UGA — και αν τελικά θα διαμορφωθεί εθνικό πλαίσιο που θα ενισχύσει τη συνεργασία, τη διαφάνεια και την τεχνολογική ανεξαρτησία της ευρωπαϊκής έρευνας.
Σε έναν κόσμο όπου τα chips καθορίζουν την τεχνολογική ισχύ των εθνών, η πνευματική ιδιοκτησία (ΠΙ) δεν είναι απλώς νομικό ζήτημα — είναι γεωπολιτικό. Αυτή είναι η κεντρική διαπίστωση μιας νέας έρευνας πολιτικής του ευρωπαϊκού έργου ALLPROS.eu, η οποία αναλύει πώς η Ευρώπη μπορεί να αξιοποιήσει ανοιχτές αρχιτεκτονικές και υβριδικά μοντέλα Πνευματικής Ιδιοκτησίας για να ενισχύσει την τεχνολογική της κυριαρχία.
Η έρευνα διαπιστώνει ότι η Πνευματική Ιδιοκτησία στον τομέα των ημιαγωγών έχει μετασχηματιστεί βαθιά. Από ένα απλό εργαλείο προστασίας καινοτομίας, έχει εξελιχθεί σε ανταγωνιστικό και γεωπολιτικό μοχλό — και η Ευρώπη βρίσκεται σε κρίσιμη καμπή.
Το Σύνθετο Τοπίο της Πνευματικής Ιδιοκτησίας στους Ημιαγωγούς
Σε αντίθεση με άλλους τομείς, η πνευματική ιδιοκτησία στους ημιαγωγούς δεν μπορεί να περιοριστεί σε μια ενιαία κατηγορία. Περιλαμβάνει διπλώματα ευρεσιτεχνίας, τοπογραφίες ολοκληρωμένων κυκλωμάτων, ενσωματωμένο λογισμικό, εμπορικά μυστικά και εμπορικά σήματα — ένα ολόκληρο οπλοστάσιο διαφορετικών εργαλείων που αντικατοπτρίζουν την πολυπλοκότητα της ανάπτυξης chip.
Η πολυπλοκότητα αυτή ενισχύεται περαιτέρω από την εκρηκτική ζήτηση που δημιουργεί η Τεχνητή Νοημοσύνη, η οποία απαιτεί εξαιρετικά εξειδικευμένα και προσαρμοσμένα chips. Σε ένα περιβάλλον με σύντομους κύκλους ζωής προϊόντων και ταχύτατες τεχνολογικές εξελίξεις, η στρατηγική διαχείριση της ΠΙ αποκτά κρίσιμη σημασία.
Από την Προστασία στον Ανταγωνισμό
Ιστορικά, τα διπλώματα ευρεσιτεχνίας στους ημιαγωγούς λειτουργούσαν κυρίως ως εργαλείο κοινής χρήσης μεταξύ βασικών παικτών μέσω ευρέων συμφωνιών αμοιβαίας αδειοδότησης. Στις αρχές της δεκαετίας του 1980, όμως, το τοπίο άλλαξε δραματικά: η ανησυχία των αμερικανικών εταιρειών μπροστά στην τεχνολογική πρόοδο των ιαπωνικών ανταγωνιστών μετέτρεψε την πνευματική ιδιοκτησία από εργαλείο συνεργασίας σε αμυντικό και επιθετικό εμπόδιο, αναδεικνύοντας τη γεωπολιτική διάσταση αυτής της κρίσιμης τεχνολογίας.
Η Ευρωπαϊκή Πραγματικότητα: Δυνατά Σημεία και Αδυναμίες
Η Ευρώπη διαθέτει ένα σύστημα Πνευματικής Ιδιοκτησίας βασισμένο σε δυαδική δομή: εθνικά γραφεία ευρεσιτεχνιών συνυπάρχουν με κεντρικοποιημένες διαδικασίες μέσω του Ευρωπαϊκού Γραφείου Ευρεσιτεχνιών (EPO) και του Γραφείου Πνευματικής Ιδιοκτησίας της ΕΕ (EUIPO).
Ένα σημαντικό βήμα αποτέλεσε η εισαγωγή της Ενιαίας Ευρωπαϊκής Ευρεσιτεχνίας (1 Ιουνίου 2023), που προσφέρει ενιαία προστασία σε 18 — και δυνητικά 25 — κράτη μέλη με μία μόνο αίτηση. Ωστόσο, στην πράξη, οι περισσότερες εταιρείες ημιαγωγών εξακολουθούν να προτιμούν τις εθνικές ευρεσιτεχνίες — ιδίως στη Γερμανία και τη Γαλλία, που κατέχουν τις δύο πρώτες θέσεις στον αριθμό αιτήσεων στην Ευρώπη σύμφωνα με τον EPO Patent Index 2024.
Το Πρόβλημα των ΜΜΕ και των Startups
Ένα από τα πιο εύγλωττα ευρήματα της έρευνας αφορά τις νεοφυείς επιχειρήσεις. Σύμφωνα με τους ειδικούς που συμμετείχαν στις συνεντεύξεις, πολλές startups αντιμετωπίζουν τις ευρεσιτεχνίες κυρίως ως τυπική απαίτηση — κάτι που αποκτούν για να ικανοποιήσουν επενδυτές ή να αυξήσουν την αποτίμησή τους ενόψει IPO — χωρίς όμως να έχουν στρατηγική για την αξιοποίησή τους.
Το αποτέλεσμα είναι παράδοξο: περιορισμένοι πόροι δαπανώνται για την απόκτηση ευρεσιτεχνιών που τελικά μένουν ανενεργές, εις βάρος της ίδιας της ανάπτυξης του προϊόντος. Αντιθέτως, μεγάλες εταιρείες όπως η Texas Instruments έχουν χτίσει τεράστια χαρτοφυλάκια ευρεσιτεχνιών που χρησιμοποιούν στρατηγικά για διαπραγμάτευση, αποκλεισμό ανταγωνιστών και αμοιβαίες άδειες χρήσης.
RISC-V: Ένα Παράδειγμα Στρατηγικής Ευκαιρίας για την Ευρώπη
Στο επίκεντρο της έρευνας βρίσκεται το RISC-V, μια ανοιχτή αρχιτεκτονική συνόλου εντολών (ISA) που αποτελεί ίσως το πιο εμβληματικό παράδειγμα του πώς η ανοιχτότητα και η ιδιόκτητη ΠΙ μπορούν να συνυπάρξουν παραγωγικά.
Αντίθετα με τις ανησυχίες ορισμένων αμερικανών πολιτικών περί απειλής για την εθνική ασφάλεια, το RISC-V δεν αποκαλύπτει ευαίσθητες πληροφορίες ούτε υποχρεώνει τις εταιρείες να γνωστοποιήσουν την ιδιόκτητη ΠΙ τους. Οι εταιρείες ανταγωνίζονται όχι στο ίδιο το ανοιχτό πρότυπο, αλλά στις διαφοροποιημένες τεχνολογίες που χτίζουν πάνω του.
Παγκόσμια Υιοθέτηση που Μιλά από Μόνη της
Μερικά χαρακτηριστικά παραδείγματα:
NVIDIA: Η αμερικανική κολοσσός, γνωστή για τις ισχυρότατες ιδιόκτητες GPU της, χρησιμοποιεί εσωτερικά το RISC-V στις GPU της ως ελεγκτή Falcon. Έως το 2024, η εταιρεία είχε υπερβεί το ορόσημο του 1 δισεκατομμυρίου ενσωματωμένων επεξεργαστών RISC-V.
Alibaba T-Head (Κίνα): Ανέπτυξε την οικογένεια επεξεργαστών XuanTie βασισμένη στο RISC-V, επιτυγχάνοντας κορυφαίες επιδόσεις — μια στρατηγική κίνηση για να αποδράσει η Κίνα από την τεχνολογική εξάρτηση από τις ΗΠΑ.
Ινδία – DIR-V Programme: Το Υπουργείο Ηλεκτρονικής & Πληροφορικής της Ινδίας έχει υιοθετήσει το RISC-V ως εθνική ISA, με στόχο την ανάπτυξη ιθαγενών μικροεπεξεργαστών όπως ο Shakti και ο VEGA.
Tsinghua University: Εγκαινίασε εργαστήριο αποκλειστικά αφιερωμένο στο RISC-V (RIOS Lab) για έρευνα και εκπαίδευση, ενώ μεγάλα κινεζικά πανεπιστήμια το χρησιμοποιούν εκτεταμένα για κατάρτιση μηχανικών chip.
Το 2025, το RISC-V έλαβε πιστοποίηση ISO/IEC JTC1, αναγνωριζόμενο ως Οργανισμός Ανάπτυξης Προτύπων — ένα ορόσημο που ενισχύει περαιτέρω τη διεθνή του θέση.
Υβριδικά Μοντέλα: Η Τέχνη της Συν-Ανταγωνιστικότητας
Η έρευνα δεν περιορίζεται στο RISC-V. Αναλύει επίσης το μοντέλο του Open Invention Network (OIN), ενός στρατηγικού χαρτοφυλακίου ευρεσιτεχνιών που ιδρύθηκε από εταιρείες όπως η IBM, η Sony και η Philips για την αντιμετώπιση των patent trolls.
Τα μέλη του OIN δεσμεύονται να μην μηνύουν άλλους συμμετέχοντες, αποκτώντας ταυτόχρονα πρόσβαση σε ένα χαρτοφυλάκιο άνω των 3 εκατομμυρίων ευρεσιτεχνιών. Αυτό αποτελεί παράδειγμα αυτού που οι ειδικοί αποκαλούν co-opetition: συνεργασία στο βασικό επίπεδο (low-stack) για πιο αποτελεσματικό ανταγωνισμό στο ανώτερο, διαφοροποιημένο επίπεδο (high-stack).
Χαρακτηριστικό ευρωπαϊκό παράδειγμα: Η OVH Cloud, ευρωπαϊκός ηγέτης στις υπηρεσίες cloud, εντάχθηκε στο OIN το 2020, εντάσσοντας εκατοντάδες πακέτα λογισμικού στη δέσμευση αμοιβαίας αδειοδότησης.
Οι Παγκόσμιες Ισορροπίες και ο Ρόλος της Ευρώπης
Η έρευνα αναδεικνύει έναν σοβαρό κίνδυνο: το μεγαλύτερο μέρος της Πνευματικής Ιδιοκτησίας για τον σχεδιασμό ημιαγωγών παραμένει στα χέρια αμερικανικών εταιρειών, δημιουργώντας τεχνολογική εξάρτηση για πολλές χώρες. Η κυριαρχία αυτή ενισχύεται από τον αμερικανικό έλεγχο των εργαλείων Electronic Design Automation (EDA), που αποτελούν το κύριο σημείο ελέγχου στην ανάπτυξη hardware. Μάλιστα, αν και η Ευρώπη διαθέτει αξιόλογη ερευνητική δραστηριότητα στον τομέα, ευρωπαϊκές startups εξαγοράζονται συχνά από αμερικανικές εταιρείες.
Παράλληλα, το κόστος καταχώρισης και διαχείρισης ευρεσιτεχνιών σε ορισμένες ευρωπαϊκές χώρες υπερβαίνει σημαντικά αυτό των ΗΠΑ και της Κίνας — ένα δομικό μειονέκτημα που πρέπει να αντιμετωπιστεί.
Προτάσεις Πολιτικής: Τι Πρέπει να Κάνει η Ευρώπη
Η έρευνα καταλήγει σε δύο βασικούς πυλώνες δράσης:
1. Εναρμόνιση του Νομικού Πλαισίου για Ανοιχτή Πνευματική Ιδιοκτησία
Ενιαία Ευρωπαϊκή Άδεια: Ανάπτυξη ενός γενικευμένου μοντέλου ανοιχτής άδειας αναγνωρισμένου σε όλα τα 27 κράτη μέλη, για να ξεπεραστεί η τρέχουσα κατακερματισμός.
Εξειδικευμένα Μοντέλα για Ημιαγωγούς: Νέα μοντέλα αδειοδότησης hardware και chip, που να ορίζουν σαφώς πώς ενσωματώνονται τα δικαιώματα ευρεσιτεχνίας με τις απαιτήσεις ανοιχτής κοινής χρήσης, μειώνοντας τα εμπόδια για ΜΜΕ και ερευνητικές κοινότητες.
2. Στρατηγική Ανάπτυξη: Εκπαίδευση και Υιοθέτηση Ανοιχτών Αρχιτεκτονικών
Ενεργός Ρόλος στη Διαμόρφωση Προτύπων: Η Ευρώπη πρέπει να γίνει κεντρικός παίκτης στη διακυβέρνηση ανοιχτών αρχιτεκτονικών, μέσω ενεργού συμμετοχής σε διεθνή φόρουμ όπως το RISC-V International.
Ανοιχτή Εκπαίδευση: Σημαντική χρηματοδότηση της εκπαίδευσης ανοιχτού υλικού από προπτυχιακό και προ-πανεπιστημιακό επίπεδο, εκμεταλλευόμενη την τάση του ευρωπαϊκού ταλέντου να παραμένει στην Ευρώπη.
Συντονισμός σε Ευρωπαϊκό Επίπεδο: Υποστήριξη συντονισμένων δράσεων ακολουθώντας το μοντέλο του Open Source Hardware and Software Roadmap for Europe, με εμπλοκή πανεπιστημίων, ερευνητικών κέντρων και δημόσιων φορέων.
Η Ανοιχτότητα ως Κινητήρας Ανταγωνιστικότητας
Η κεντρική ιδέα της έρευνας είναι ότι η ανοιχτότητα δεν αντιτίθεται στην ανταγωνιστικότητα — αποτελεί τον κύριο κινητήριο παράγοντά της στο σημερινό παγκόσμιο σκηνικό.
Η Ευρώπη δεν χρειάζεται να επιλέξει ανάμεσα σε ανοιχτά και ιδιόκτητα μοντέλα. Χρειάζεται να τα συνδυάσει έξυπνα: να χτίσει ένα συνεργατικό οικοσύστημα όπου η Πνευματική Ιδιοκτησία δεν προστατεύει μόνο την καινοτομία, αλλά την κοινοποιεί και την πολλαπλασιάζει.
Με το Chips Act 2.0 να βρίσκεται στον ορίζοντα και με τομείς όπως η ΤΝ, το Edge AI και η ρομποτική να επαναπροσδιορίζουν τις ανάγκες σε hardware, το 2026 αναδεικνύεται ως κρίσιμη χρονιά για τις επιλογές που θα καθορίσουν την τεχνολογική κυριαρχία της Ευρώπης για τις επόμενες δεκαετίες.
Το Fedora 44 δεν προσπαθεί να σοκάρει με θεαματικές αλλαγές. Αντίθετα, προσφέρει κάτι πιο σημαντικό: ένα εξαιρετικά ώριμο, γρήγορο και σύγχρονο Linux desktop που συνδυάζει GNOME 50, KDE Plasma 6.6,… Διαβάστε τη συνέχεια του άρθρου Fedora 44: Η Πιο Ώριμη Και Ολοκληρωμένη Έκδοση Fedora Μέχρι Σήμερα; όπως δημοσιεύθηκε στο Linux Insider
Η ραγδαία εξάπλωση της γενετικής τεχνητής νοημοσύνης έχει ανοίξει μια νέα και ιδιαίτερα κρίσιμη συζήτηση γύρω από τον τρόπο με τον οποίο χρησιμοποιούνται τα δεδομένα πολιτιστικής κληρονομιάς. Μουσεία, βιβλιοθήκες, αρχεία και πολιτιστικοί οργανισμοί σε όλη την Ευρώπη διαθέτουν τεράστιους όγκους ψηφιοποιημένου υλικού — από έργα τέχνης και ιστορικά έγγραφα μέχρι φωτογραφίες, ηχητικά αρχεία και μεταδεδομένα. Αυτά τα δεδομένα αποτελούν πλέον πολύτιμη «πρώτη ύλη» για την εκπαίδευση συστημάτων τεχνητής νοημοσύνης.
Η νέα μελέτη με τίτλο «Publishing Cultural Heritage Data in the Age of AI», που εκπονήθηκε για λογαριασμό του Europeana Foundation από το Open Future Foundation, εξετάζει ακριβώς αυτό το ζήτημα: πώς μπορούν οι οργανισμοί πολιτιστικής κληρονομιάς να διατηρήσουν την αποστολή της ανοιχτής πρόσβασης στη γνώση, χωρίς όμως να μετατραπούν σε ανεξέλεγκτους προμηθευτές δεδομένων για μεγάλες εταιρείες τεχνητής νοημοσύνης.
Η νέα αξία των πολιτιστικών δεδομένων
Τα τελευταία χρόνια, και ιδιαίτερα μετά την εμφάνιση εργαλείων όπως το ChatGPT, οι εταιρείες ανάπτυξης AI αναζητούν τεράστιες ποσότητες δεδομένων υψηλής ποιότητας για την εκπαίδευση των μοντέλων τους. Τα δεδομένα πολιτιστικής κληρονομιάς θεωρούνται εξαιρετικά πολύτιμα, όχι μόνο λόγω του όγκου τους αλλά και επειδή είναι επιμελημένα, αξιόπιστα και ιστορικά τεκμηριωμένα.
Η μελέτη επισημαίνει ότι τα πολιτιστικά ιδρύματα δεν διαθέτουν μόνο ψηφιοποιημένα αντικείμενα, αλλά και μεταδεδομένα — πληροφορίες που περιγράφουν, οργανώνουν και ερμηνεύουν τις συλλογές. Αυτά τα στοιχεία είναι ιδιαίτερα χρήσιμα για τα συστήματα AI, τα οποία βασίζονται σε μεγάλες και καλά δομημένες βάσεις δεδομένων.
Σύμφωνα με την έρευνα, η χρήση αυτών των δεδομένων από την τεχνητή νοημοσύνη γίνεται με δύο βασικούς τρόπους:
Εκπαίδευση μοντέλων AI: Οι εταιρείες συλλέγουν μεγάλες ποσότητες δεδομένων μέσω web scraping ή ειδικών συμφωνιών με ιδρύματα.
Χρήση από ήδη εκπαιδευμένα συστήματα: Τα AI εργαλεία αναζητούν πληροφορίες σε πραγματικό χρόνο για να απαντήσουν σε ερωτήματα χρηστών ή να αναλύσουν περιεχόμενο.
Η διαφορά είναι σημαντική: ενώ η εκπαίδευση απαιτεί μία μαζική συλλογή δεδομένων, τα συστήματα που λειτουργούν καθημερινά μπορούν να δημιουργήσουν συνεχή και αυξανόμενη πίεση στις υποδομές των πολιτιστικών οργανισμών.
Το νομικό πλαίσιο και τα όριά του
Η μελέτη αναλύει εκτενώς το ευρωπαϊκό νομικό πλαίσιο σχετικά με τα πνευματικά δικαιώματα και την εξόρυξη δεδομένων (Text and Data Mining – TDM). Η ευρωπαϊκή οδηγία DSM του 2019 επιτρέπει, υπό προϋποθέσεις, τη χρήση έργων για εκπαίδευση AI, εκτός αν οι δικαιούχοι έχουν δηλώσει ρητά εξαίρεση.
Ωστόσο, το πρόβλημα είναι ότι στην πράξη τα πολιτιστικά ιδρύματα έχουν περιορισμένες δυνατότητες ελέγχου. Ακόμη και όταν εφαρμόζονται τεχνικά μέτρα ή μηχανισμοί opt-out, δεν υπάρχουν διεθνώς αποδεκτά πρότυπα που να εγγυώνται ότι οι εταιρείες AI θα σεβαστούν αυτές τις επιλογές.
Η μελέτη καταλήγει σε ένα αρκετά ρεαλιστικό συμπέρασμα: οτιδήποτε δημοσιεύεται ανοιχτά στο διαδίκτυο είναι πολύ πιθανό να χρησιμοποιηθεί τελικά για την εκπαίδευση συστημάτων AI.
Το δίλημμα των πολιτιστικών οργανισμών
Η έρευνα θέτει ένα κρίσιμο ερώτημα: πρέπει οι οργανισμοί πολιτιστικής κληρονομιάς να συνεχίσουν να προσφέρουν ανοιχτή πρόσβαση στα δεδομένα τους ή να περιορίσουν την πρόσβαση για να προστατεύσουν τη βιωσιμότητά τους;
Από τη μία πλευρά, η ανοιχτή πρόσβαση αποτελεί θεμελιώδη αρχή της πολιτιστικής πολιτικής της Ευρώπης. Η διάθεση της γνώσης προς όλους θεωρείται δημόσιο αγαθό.
Από την άλλη πλευρά, η μαζική χρήση δεδομένων από μεγάλες εταιρείες AI δημιουργεί νέα κόστη:
αυξημένη χρήση υποδομών,
μεγαλύτερες απαιτήσεις αποθήκευσης και δικτύων,
ανάγκη διαχείρισης bots και scraping,
απώλεια ελέγχου πάνω στον τρόπο αξιοποίησης των συλλογών.
Η μελέτη τονίζει ότι υπάρχει πλέον μια «δομική ανισορροπία» μεταξύ δημόσιων πολιτιστικών οργανισμών και μεγάλων τεχνολογικών εταιρειών που διαθέτουν τεράστιους οικονομικούς πόρους.
Η πρόταση: διαφοροποιημένο μοντέλο πρόσβασης
Ως απάντηση σε αυτό το πρόβλημα, η έρευνα προτείνει ένα νέο «διαφοροποιημένο μοντέλο πρόσβασης» στα πολιτιστικά δεδομένα.
Το μοντέλο βασίζεται σε τρεις μορφές πρόσβασης:
1. Ανοιχτή πρόσβαση για μεμονωμένα αντικείμενα
Οι χρήστες θα συνεχίσουν να έχουν ελεύθερη πρόσβαση σε εικόνες, τεκμήρια και ψηφιακά αντικείμενα μέσω ιστοσελίδων και online συλλογών.
2. Ελεγχόμενη πρόσβαση μέσω API
Για πιο εκτεταμένη ή αυτοματοποιημένη χρήση, οι οργανισμοί θα μπορούν να παρέχουν πρόσβαση μέσω APIs με όρους χρήσης, όρια πρόσβασης και παρακολούθηση δραστηριότητας.
3. Υπό όρους πρόσβαση για μαζική χρήση δεδομένων
Η πιο σημαντική πρόταση αφορά τη μαζική λήψη δεδομένων για εκπαίδευση AI. Σε αυτή την περίπτωση, η πρόσβαση δεν θα είναι πλήρως ελεύθερη.
Οι οργανισμοί θα μπορούν:
να θέτουν ειδικούς όρους,
να διαχωρίζουν εμπορική από μη εμπορική χρήση,
να ζητούν οικονομική συνεισφορά από μεγάλες εταιρείες AI,
να απαιτούν διαφάνεια σχετικά με τη χρήση των δεδομένων.
Η λογική πίσω από αυτή την πρόταση δεν είναι η «ιδιωτικοποίηση» της πολιτιστικής κληρονομιάς, αλλά η προστασία της βιωσιμότητας των δημόσιων πολιτιστικών υποδομών.
«Το περιεχόμενο είναι ελεύθερο — οι υποδομές όχι»
Η μελέτη αναφέρει ως παράδειγμα το Wikimedia Foundation, το οποίο αντιμετωπίζει ήδη σημαντικά προβλήματα λόγω της μαζικής χρήσης δεδομένων από εταιρείες AI. Η Wikimedia έχει αναπτύξει υπηρεσίες ειδικά σχεδιασμένες για μεγάλους εμπορικούς χρήστες, με οικονομική συνεισφορά προς τη συντήρηση της υποδομής.
Η φιλοσοφία συνοψίζεται στη φράση:
«Το περιεχόμενο είναι ελεύθερο, αλλά οι υποδομές δεν είναι.»
Αυτή η λογική φαίνεται να κερδίζει έδαφος και σε επίπεδο ευρωπαϊκής πολιτικής, καθώς η ΕΕ εξετάζει πλέον τρόπους προστασίας των δημόσιων δεδομένων από δυσανάλογη εκμετάλλευση από πολύ μεγάλες ψηφιακές πλατφόρμες.
Μια νέα εποχή για την πολιτιστική κληρονομιά
Η έρευνα δεν προτείνει το κλείσιμο των πολιτιστικών δεδομένων ούτε την εγκατάλειψη της ανοιχτής πρόσβασης. Αντίθετα, επιχειρεί να επαναπροσδιορίσει την έννοια της «ανοιχτότητας» σε μια εποχή όπου η τεχνητή νοημοσύνη μετατρέπει κάθε ψηφιακό αρχείο σε πιθανό εμπορικό πόρο.
Το βασικό ερώτημα πλέον δεν είναι αν τα πολιτιστικά δεδομένα θα χρησιμοποιηθούν από την AI — αυτό θεωρείται σχεδόν βέβαιο. Το πραγματικό ζήτημα είναι με ποιους όρους θα γίνει αυτή η χρήση και αν οι πολιτιστικοί οργανισμοί θα μπορέσουν να διατηρήσουν τον δημόσιο και κοινωνικό τους ρόλο μέσα σε ένα νέο, ιδιαίτερα ανταγωνιστικό ψηφιακό περιβάλλον.
Η συζήτηση που ανοίγει η συγκεκριμένη μελέτη αναμένεται να επηρεάσει σημαντικά το μέλλον της ψηφιακής πολιτιστικής πολιτικής στην Ευρώπη. Και ίσως αποτελέσει ένα από τα πρώτα σοβαρά βήματα για τον επανακαθορισμό της σχέσης ανάμεσα στον πολιτισμό, τη γνώση και την τεχνητή νοημοσύνη.
Η νέα έκθεση του Communia Association με τίτλο «The Post-DSM Copyright Report» επιχειρεί μια εκτενή αποτίμηση του τρόπου με τον οποίο τα κράτη-μέλη της Ευρωπαϊκής Ένωσης έχουν εφαρμόσει βασικές διατάξεις της Οδηγίας DSM (Digital Single Market Directive) σχετικά με τα πνευματικά δικαιώματα. Η μελέτη επικεντρώνεται κυρίως στα δικαιώματα των χρηστών, στην έρευνα, στην εκπαίδευση, στην πολιτιστική κληρονομιά και στις νέες προκλήσεις που δημιουργεί η ανάπτυξη της τεχνητής νοημοσύνης.
Η έκθεση αναδεικνύει τόσο τις θετικές πρακτικές που έχουν υιοθετήσει ορισμένα κράτη όσο και τις σημαντικές ασυμβατότητες που εξακολουθούν να υπάρχουν μεταξύ των εθνικών νομοθεσιών. Παράλληλα, υπογραμμίζει ότι η επικείμενη αναθεώρηση της Οδηγίας DSM αποτελεί μια κρίσιμη ευκαιρία για την ενίσχυση της προστασίας των δικαιωμάτων των χρηστών σε ολόκληρη την Ευρωπαϊκή Ένωση.
Δικαιώματα έρευνας και εκπαίδευσης
Ένα από τα βασικά πεδία που εξετάζει η έκθεση αφορά την εξόρυξη κειμένου και δεδομένων (Text and Data Mining – TDM), μια πρακτική που θεωρείται πλέον απαραίτητη για τη σύγχρονη επιστημονική έρευνα και την ανάπτυξη εφαρμογών τεχνητής νοημοσύνης.
Η μελέτη καταγράφει ότι τα περισσότερα κράτη-μέλη αναγνωρίζουν πως η εξαίρεση που προβλέπεται από το Άρθρο 3 της Οδηγίας DSM δεν επαρκεί για να καλύψει τις πραγματικές ανάγκες της ερευνητικής κοινότητας. Για τον λόγο αυτό, αρκετές χώρες έχουν εισαγάγει ευρύτερες εξαιρέσεις για την επιστημονική έρευνα, επιτρέποντας όχι μόνο την ανάλυση δεδομένων αλλά και την ανταλλαγή ερευνητικού υλικού μεταξύ επιστημόνων για λόγους συνεργασίας και επαλήθευσης αποτελεσμάτων.
Ιδιαίτερο ενδιαφέρον παρουσιάζει η περίπτωση της Ιταλίας, η οποία συνέδεσε ρητά την εξόρυξη δεδομένων με την ανάπτυξη τεχνητής νοημοσύνης, παρέχοντας έτσι μεγαλύτερη νομική σαφήνεια στους ερευνητές. Αντίστοιχα, η Σλοβενία και η Βουλγαρία υιοθέτησαν μηχανισμούς χρονικά περιορισμένης πρόσβασης ώστε να αντιμετωπιστούν οι περιορισμοί που προκαλούν τα τεχνολογικά μέτρα προστασίας.
Στον τομέα της εκπαίδευσης, η έκθεση σημειώνει ότι η υποχρεωτική ψηφιακή εξαίρεση του Άρθρου 5 δεν καλύπτει πλήρως τις ανάγκες της εκπαιδευτικής κοινότητας. Πολλά κράτη-μέλη διατήρησαν ή επέκτειναν εξαιρέσεις που αφορούν και μη ψηφιακές μορφές διδασκαλίας ή μεγαλύτερες κατηγορίες χρηστών, προσφέροντας πιο ολοκληρωμένη προστασία για τις εκπαιδευτικές χρήσεις έργων.
Πολιτιστική κληρονομιά και Κοινό Κτήμα
Η έκθεση εξετάζει επίσης την εφαρμογή των κανόνων που αφορούν τα έργα εκτός εμπορίου (Out-of-Commerce Works – OOCW), δηλαδή έργα που δεν είναι πλέον διαθέσιμα στην αγορά αλλά εξακολουθούν να προστατεύονται από πνευματικά δικαιώματα.
Σύμφωνα με τα ευρήματα, τα κράτη-μέλη έχουν υιοθετήσει πολύ διαφορετικά κριτήρια για τον χαρακτηρισμό αυτών των έργων, γεγονός που δημιουργεί ανασφάλεια δικαίου και δυσκολίες για τα πολιτιστικά ιδρύματα που επιθυμούν να τα ψηφιοποιήσουν και να τα διαθέσουν στο κοινό.
Η έκθεση επισημαίνει ότι σε πολλές περιπτώσεις οι υφιστάμενοι κανόνες επιβαρύνουν υπερβολικά τα ιδρύματα πολιτιστικής κληρονομιάς, απαιτώντας πολύπλοκες διαδικασίες τεκμηρίωσης πριν ένα έργο θεωρηθεί «εκτός εμπορίου». Για τον λόγο αυτό προτείνεται η δημιουργία πιο ευέλικτων εξαιρέσεων που θα επιτρέπουν τη μαζική ψηφιοποίηση έργων όταν δεν υπάρχουν κατάλληλες άδειες χρήσης.
Θετικά αξιολογείται, ωστόσο, η εφαρμογή του Άρθρου 14 της Οδηγίας, το οποίο αποσκοπεί στην αποτροπή της επανιδιωτικοποίησης έργων που ανήκουν στον δημόσιο τομέα μέσω ψηφιοποίησης. Η έκθεση προτείνει μάλιστα την επέκταση αυτής της λογικής και σε άλλες κατηγορίες έργων πέρα από τα έργα εικαστικής τέχνης.
Προστασία απέναντι σε συμβατικούς και τεχνολογικούς περιορισμούς
Ένα ακόμη σημαντικό ζήτημα αφορά τις διατάξεις που προστατεύουν τους χρήστες από συμβάσεις ή τεχνολογικά μέτρα που ακυρώνουν στην πράξη τις εξαιρέσεις των πνευματικών δικαιωμάτων.
Η έκθεση διαπιστώνει ότι η εφαρμογή του Άρθρου 7 της Οδηγίας DSM παραμένει άνιση στην Ευρώπη. Αν και αρκετές χώρες προβλέπουν προστασία απέναντι σε συμβατικές ρήτρες που περιορίζουν τα δικαιώματα των χρηστών, άλλες δεν παρέχουν επαρκείς εγγυήσεις.
Ακόμη μεγαλύτερες αποκλίσεις καταγράφονται σε σχέση με τα τεχνολογικά μέτρα προστασίας, όπως τα συστήματα DRM. Σε αρκετές περιπτώσεις οι χρήστες δεν διαθέτουν ουσιαστικούς μηχανισμούς για να ασκήσουν τα νόμιμα δικαιώματά τους όταν η πρόσβαση περιορίζεται τεχνολογικά.
Το δικαίωμα των εκδοτών Τύπου
Η έκθεση αφιερώνει ιδιαίτερη προσοχή και στο δικαίωμα των εκδοτών Τύπου που θεσπίστηκε με το Άρθρο 15 της Οδηγίας DSM.
Παρότι η Οδηγία προέβλεπε συγκεκριμένα όρια και εξαιρέσεις για την αποφυγή υπερβολικής προστασίας των εκδοτών, αρκετά κράτη-μέλη δεν εφάρμοσαν πλήρως αυτές τις εγγυήσεις. Ως αποτέλεσμα, σε ορισμένες χώρες οι εκδότες Τύπου απολαμβάνουν ευρύτερη προστασία από άλλους δικαιούχους πνευματικών δικαιωμάτων, γεγονός που ενισχύει τον κατακερματισμό της ευρωπαϊκής αγοράς.
Δικαιώματα χρηστών στις διαδικτυακές πλατφόρμες
Ιδιαίτερη έμφαση δίνεται και στο Άρθρο 17 της Οδηγίας DSM, το οποίο αφορά τις διαδικτυακές πλατφόρμες διαμοιρασμού περιεχομένου.
Η έκθεση σημειώνει ότι τα περισσότερα κράτη-μέλη ακολούθησαν μια «μινιμαλιστική» προσέγγιση, περιοριζόμενα στην επανάληψη της γενικής αρχής ότι οι νόμιμες αναρτήσεις δεν πρέπει να μπλοκάρονται. Ωστόσο, στην πράξη, η ισορροπία ανάμεσα στην προστασία των πνευματικών δικαιωμάτων και στην ελευθερία της έκφρασης εξακολουθεί να εξαρτάται κυρίως από τις ίδιες τις πλατφόρμες και τα δικαστήρια.
Μόνο λίγες χώρες υιοθέτησαν ισχυρότερες εγγυήσεις, όπως μηχανισμούς πρόληψης του υπερβολικού μπλοκαρίσματος περιεχομένου, υποχρεώσεις διαφάνειας και διαδικασίες αντιμετώπισης καταχρηστικών καταγγελιών.
Η έκθεση επισημαίνει επίσης ότι εξακολουθούν να υπάρχουν διαφορετικές προσεγγίσεις ως προς την εξαίρεση για παρωδία, καρικατούρα και μίμηση (pastiche), γεγονός που οδηγεί σε διαφορετικά επίπεδα προστασίας της ελευθερίας έκφρασης μεταξύ των κρατών-μελών.
Το «Post-DSM Copyright Report» καταλήγει στο συμπέρασμα ότι η εφαρμογή της Οδηγίας DSM χαρακτηρίζεται από σημαντικές αποκλίσεις και ανισότητες μεταξύ των κρατών-μελών. Παράλληλα όμως, αναδεικνύει ότι αρκετές χώρες έχουν ήδη αποδείξει στην πράξη πως είναι εφικτή μια πιο ισορροπημένη προσέγγιση που προστατεύει αποτελεσματικότερα την έρευνα, την εκπαίδευση, την πολιτιστική κληρονομιά και την ελευθερία έκφρασης.
Η επικείμενη αναθεώρηση της Οδηγίας DSM θεωρείται επομένως καθοριστική για το μέλλον των ψηφιακών δικαιωμάτων στην Ευρωπαϊκή Ένωση. Μέσα από την αξιοποίηση των βέλτιστων εθνικών πρακτικών, η ΕΕ έχει τη δυνατότητα να δημιουργήσει ένα πιο συνεκτικό και δίκαιο πλαίσιο πνευματικών δικαιωμάτων που θα ανταποκρίνεται στις ανάγκες της ψηφιακής εποχής και της τεχνητής νοημοσύνης.
Με εντυπωσιακό παλμό και συμμετοχή που ξεπέρασε κάθε προηγούμενο, ολοκληρώθηκε το Devoxx Greece 2026, το μεγαλύτερο συνέδριο ανάπτυξης λογισμικού στην Ελλάδα. Από τις 23 έως τις 25 Απριλίου, το Μέγαρο Μουσικής Αθηνών μεταμορφώθηκε σε έναν διεθνή κόμβο τεχνολογίας, υποδεχόμενο περισσότερους από 1.500 συνέδρους από 30 διαφορετικές χώρες. Το φετινό πρόγραμμα για ακόμη μία φορά έθεσε ψηλά τον πήχη, εστιάζοντας στην πρακτική εφαρμογή των τεχνολογιών που επαναπροσδιορίζουν το software engineering. Περισσότεροι από 85 διεθνείς ομιλητές μοιράστηκαν την εμπειρία τους σε ένα ευρύ φάσμα θεματολογίας: όπως γλώσσες προγραμματισμού, ασφάλεια, soft skills, τεχνητή νοημοσύνη (ΑΙ) κ.α. Την ατζέντα του συνεδρίου τίμησαν με την παρουσία τους διεθνώς αναγνωρισμένοι ομιλητές όπως o Will Sentance, o Gojko Adjic και ο J. B. Rainsberger οι οποίοι ενέπνευσαν το κοινό με τις κεντρικές τους ομιλίες. Η επιτυχία του συνεδρίου δεν περιορίστηκε στις ομιλίες. Τα workshops, το community corner και το mentorship hub έδωσαν στους συμμετέχοντες την ευκαιρία για hands-on εκπαίδευση σε εργαλεία που διαμορφώνουν το μέλλον της εργασίας τους. Ο κ. Πάτροκλος Παπαπέτρου, διοργανωτής των συνεδρίων Devoxx Greece και Voxxed Days στην Ελλάδα δήλωσε χαρακτηριστικά: “Το φετινό Devoxx Greece απέδειξε ότι η ελληνική tech κοινότητα είναι πιο δυνατή από ποτέ. Η ενέργεια που ζήσαμε στο Μέγαρο Μουσικής Αθηνών ήταν μοναδική. Στόχος μας παραμένει η διαρκής αναβάθμιση της εμπειρίας που προσφέρουμε, φέρνοντας την παγκόσμια γνώση στην χώρα μας. Η πορεία μας για το 2026 συνεχίζεται με επόμενο μεγάλο ραντεβού το Voxxed Days Thessaloniki 20 – 21 Νοεμβρίου 2026, όπως κάθε φορά στο Συνεδριακό Κέντρο Ιωάννης Βελλίδης, θα είναι και επετειακό καθώς κλείνει 10 χρόνια.”.
Οι εκδηλώσεις δεν σταματούν καθώς αυτήν την εβδομάδα πραγματοποιούνται εκδηλώσεις στην Ελλάδα και στο εξωτερικό για τις ανοιχτές τεχνολογίες και την καινοτομία! Ο Οργανισμός Ανοιχτών Τεχνολογιών (ΕΕΛΛΑΚ) σας προτείνει να τις παρακολουθήσετε και να τις διαδώσετε. Μπορείτε επίσης να δείτε περισσότερες εκδηλώσεις για τις επόμενες εβδομάδες ή να καταχωρίσετε τη δική σας εκδήλωση στο: https://ellak.gr/events.
Η συνεχώς αυξανόμενη ανάγκη για επαλήθευση ταυτότητας και ηλικίας στο διαδίκτυο δημιουργεί ένα κρίσιμο ερώτημα: πώς μπορούν οι χρήστες να αποδεικνύουν ποιοι είναι χωρίς να θυσιάζουν την ιδιωτικότητά τους; Μια νέα πρωτοβουλία από το Πανεπιστήμιο Harvard και το Linux Foundation φιλοδοξεί να δώσει απάντηση μέσα από το Keyring, ένα ανοιχτού κώδικα ψηφιακό πορτοφόλι ταυτότητας που επιτρέπει στους χρήστες να ελέγχουν πλήρως ποια προσωπικά δεδομένα μοιράζονται.
Η εφαρμογή χρησιμοποιεί τα συνηθισμένα βιομετρικά συστήματα των smartphones, όπως αναγνώριση προσώπου ή δακτυλικό αποτύπωμα σε iOS και Android συσκευές. Τα δεδομένα αποθηκεύονται τοπικά στη συσκευή και δεν μεταφέρονται σε κεντρικούς servers, ενισχύοντας έτσι την προστασία της ιδιωτικότητας.
Παράλληλα, οι χρήστες μπορούν να προσθέσουν επίσημα ψηφιακά έγγραφα, όπως mobile driver’s licenses (mDLs), δηλαδή ψηφιακές άδειες οδήγησης, ώστε να αποδεικνύουν στοιχεία όπως η ηλικία ή η ταυτότητά τους με ασφαλή τρόπο.
Οι τρεις βασικές χρήσεις της πλατφόρμας
Οι δημιουργοί του Keyring περιγράφουν τρεις βασικές εφαρμογές της τεχνολογίας:
1. Διασύνδεση λογαριασμών στα social media
Οι χρήστες μπορούν να αποδεικνύουν ότι διαχειρίζονται συγκεκριμένους λογαριασμούς σε διαφορετικές πλατφόρμες κοινωνικής δικτύωσης. Για παράδειγμα, ένας δημιουργός περιεχομένου θα μπορεί να αποδεικνύει ότι ο λογαριασμός του στο BlueSky ανήκει στο ίδιο άτομο που διαχειρίζεται και έναν λογαριασμό στο X (πρώην Twitter).
Αυτό θα μπορούσε να περιορίσει τα fake accounts και να ενισχύσει την αξιοπιστία δημοσιογράφων, influencers και οργανισμών.
Screenshot
2. Επιβεβαίωση ηλικίας χωρίς αποκάλυψη προσωπικών δεδομένων
Το Keyring επιτρέπει την επιβεβαίωση ότι ένας χρήστης είναι άνω των 18 ετών χωρίς να αποκαλύπτει ημερομηνία γέννησης ή άλλα προσωπικά στοιχεία. Η λειτουργία αυτή αποκτά ιδιαίτερη σημασία καθώς πολλές πολιτείες στις ΗΠΑ και άλλες χώρες εξετάζουν αυστηρότερους κανόνες πρόσβασης ανηλίκων στα social media.
3. Δημιουργία αποκεντρωμένων σχέσεων εμπιστοσύνης
Η πιο καινοτόμος ιδέα του έργου αφορά τη δημιουργία «διαπιστευτηρίων σχέσης» μεταξύ ανθρώπων. Δύο άτομα που συναντώνται, για παράδειγμα, σε ένα επαγγελματικό συνέδριο, μπορούν να επιβεβαιώνουν τη γνωριμία τους χωρίς τη μεσολάβηση πλατφορμών όπως το LinkedIn.
Μελλοντικά, ένα τέτοιο δίκτυο επαληθευμένων σχέσεων θα μπορούσε να λειτουργήσει ως αποκεντρωμένο σύστημα εμπιστοσύνης, βοηθώντας στην επαλήθευση ανθρώπων, περιεχομένου και ακόμα και ηλικίας, χωρίς κρατική παρέμβαση.
Η μεγάλη πρόκληση: η αποδοχή από οργανισμούς και κυβερνήσεις
Παρότι η τεχνολογία παρουσιάζει σημαντικές δυνατότητες, η επιτυχία της εξαρτάται από το αν κυβερνήσεις, εταιρείες και οργανισμοί θα αποδεχθούν και θα υποστηρίξουν το νέο μοντέλο επαλήθευσης. Σύμφωνα με στελέχη του ASML, πολλές μεγάλες πλατφόρμες εξακολουθούν να βασίζονται στην εκμετάλλευση προσωπικών δεδομένων για εμπορικούς σκοπούς, γεγονός που δυσκολεύει τη μετάβαση σε πιο αποκεντρωμένες και privacy-first λύσεις.
Ωστόσο, η αυξανόμενη πίεση των χρηστών για μεγαλύτερο έλεγχο των προσωπικών τους δεδομένων ίσως επιταχύνει την υιοθέτηση τέτοιων τεχνολογιών τα επόμενα χρόνια.
Ένα πιθανό νέο μοντέλο για την ψηφιακή ταυτότητα
Το Keyring αποτελεί μια ενδιαφέρουσα προσπάθεια επαναπροσδιορισμού της ψηφιακής ταυτότητας στο σύγχρονο διαδίκτυο. Σε μια εποχή όπου η τεχνητή νοημοσύνη, τα deepfakes και οι ψεύτικοι λογαριασμοί αυξάνονται, η ανάγκη για αξιόπιστη αλλά και ιδιωτική επαλήθευση γίνεται πιο σημαντική από ποτέ.
Αν το εγχείρημα καταφέρει να αποκτήσει ευρεία υποστήριξη, θα μπορούσε να αλλάξει ριζικά τον τρόπο με τον οποίο οι άνθρωποι αποδεικνύουν ποιοι είναι online — δίνοντας επιτέλους στους ίδιους τους χρήστες τον έλεγχο των προσωπικών τους δεδομένων.
Στις 29 Απριλίου πραγματοποιήθηκε εισαγωγική δράση για τη Βικιπαίδεια με τη συμμετοχή μαθητών της ΣΤ΄ τάξης στο αρμενικό σχολείο Ζαβαριάν στη Νίκαια.
Κατά τη διάρκεια της δράσης παρουσιάστηκε ο τρόπος επεξεργασίας της Βικιπαίδειας, έγινε επίδειξη της διαδικασίας δημιουργίας λογαριασμού και επεξεργασίας λημμάτων, ενώ ιδιαίτερη έμφαση δόθηκε στις πηγές και στη σημασία της τεκμηρίωσης. Παράλληλα, ορισμένοι μαθητές ξεκίνησαν να εργάζονται πάνω σε λήμματα στα ελληνικά.
Η εισαγωγική αυτή δράση, την οποία υλοποίησε ο Νίκος Λυκομήτρος, μέλος της κοινότητας της Βικιπαίδειας, εντάσσεται στο πλαίσιο της εκπαίδευσης των μαθητών του σχολείου σχετικά με τη συνεισφορά στην Ελληνική Βικιπαίδεια.
Υπό την επίβλεψη της διευθύντριας του σχολείου, Χαϊγκάν Μινασιάν, μαθητές του Ζαβαριάν έχουν ήδη συγγράψει λήμματα στη Δυτική Αρμενική Βικιπαίδεια. Η συγκεκριμένη δράση είχε ως στόχο να τους εισαγάγει και στην Ελληνική Βικιπαίδεια, καθώς και στους μηχανισμούς λειτουργίας της, ενόψει της σχεδιαζόμενης συγγραφής λημμάτων στα ελληνικά από τους μαθητές.
Παρόμοια δράση είχε πραγματοποιηθεί και το 2025.παρόμοια δράση είχε πραγματοποιηθεί και το 2025.
Από την απλή ανάκτηση εγγράφων στον έλεγχο της απάντησης πριν φτάσει στον χρήστη
Τα συστήματα RAG δημιουργήθηκαν για να λύσουν ένα πολύ συγκεκριμένο πρόβλημα της γενετικής Τεχνητής Νοημοσύνης: την τάση των μεγάλων γλωσσικών μοντέλων να απαντούν με ευφράδεια ακόμη και όταν δεν γνωρίζουν. Η βασική ιδέα είναι απλή. Αντί το μοντέλο να βασίζεται μόνο στη μνήμη που απέκτησε κατά την εκπαίδευσή του, αναζητά πρώτα σχετικά έγγραφα και στη συνέχεια διατυπώνει απάντηση στηριγμένη σε αυτά. Στην πράξη, όμως, η ανάκτηση του σωστού εγγράφου δεν εγγυάται ότι η τελική απάντηση θα είναι σωστή. Το μοντέλο μπορεί να έχει μπροστά του την ακριβή πηγή και παρ’ όλα αυτά να την παραποιήσει, να αντιστρέψει το νόημά της ή να προσθέσει στοιχεία που δεν υπάρχουν πουθενά.
Αυτό είναι το κρίσιμο σημείο. Η παραισθητική απάντηση σε ένα απλό chatbot μπορεί να αντιμετωπιστεί με επιφυλακτικότητα από τον χρήστη. Σε ένα σύστημα RAG, όμως, η απάντηση εμφανίζεται ως τεκμηριωμένη. Ο χρήστης θεωρεί ότι το σύστημα διάβασε τις πηγές και άρα δικαιούται μεγαλύτερη εμπιστοσύνη. Γι’ αυτό ο περιορισμός των παραισθήσεων δεν μπορεί να σταματά στην καλύτερη αναζήτηση. Πρέπει να υπάρχει ένα επιπλέον στρώμα ελέγχου μετά τη δημιουργία της απάντησης και πριν από την εμφάνισή της.
Οι πέντε συνηθέστερες αστοχίες
Η πρώτη αστοχία είναι η υπερβολική βεβαιότητα χωρίς τεκμηρίωση. Το μοντέλο γράφει «σίγουρα», «είναι σαφές», «όπως αναφέρεται», ενώ η πληροφορία δεν υπάρχει στο ανακτημένο υλικό. Αυτή η μορφή είναι επικίνδυνη επειδή δεν φαίνεται ως αβεβαιότητα αλλά ως αυθεντία. Η δεύτερη είναι η αριθμητική αντίφαση. Το έγγραφο λέει ότι η προθεσμία επιστροφής είναι 14 ημέρες και η απάντηση γράφει 30 ημέρες. Ή η πηγή αναφέρει ότι το πρόγραμμα κοστίζει 120 δολάρια τον χρόνο και η απάντηση το παρουσιάζει ως 10 δολάρια τον μήνα. Η τρίτη είναι η επινόηση προσώπων, οργανισμών ή βιβλιογραφικών αναφορών. Για παράδειγμα, το μοντέλο μπορεί να επικαλεστεί έναν «Dr. James Harrison» ή ένα ανύπαρκτο arXiv paper, ενώ κανένα από αυτά δεν υπάρχει στα σχετικά έγγραφα. Η τέταρτη είναι η αντιστροφή άρνησης. Η πηγή λέει ότι μια υπηρεσία «δεν υποστηρίζει ακύρωση μετά την πληρωμή» και η απάντηση γράφει ότι «υποστηρίζει ακύρωση μετά την πληρωμή». Η πέμπτη είναι η διολίσθηση της απάντησης στον χρόνο. Η ίδια ερώτηση για την τιμή ενός προϊόντος μπορεί να απαντάται επί εβδομάδες ως 49,99 ευρώ και ξαφνικά, μετά από ανανέωση του ευρετηρίου, να επιστρέφει 39,99 ευρώ χωρίς καμία ειδοποίηση.
Έλεγχος πιστότητας, αντίφασης και οντοτήτων
Ένα πρακτικό σύστημα προστασίας πρέπει να εξετάζει την απάντηση με απλούς αλλά αυστηρούς κανόνες. Πρώτα, μετρά την πιστότητα. Χωρίζει την απάντηση σε προτάσεις που περιέχουν πραγματολογικούς ισχυρισμούς και εξετάζει αν οι βασικές λέξεις κάθε ισχυρισμού υπάρχουν στο ανακτημένο υλικό. Αν πολλές προτάσεις δεν μπορούν να συνδεθούν με την πηγή, η απάντηση δεν πρέπει να προωθείται ως αξιόπιστη.
Έπειτα, ελέγχει αριθμούς και χρονικές εκφράσεις. Αν το πλαίσιο λέει «14 ημέρες» και η απάντηση γράφει «30 ημέρες», το σύστημα δεν πρέπει να το αντιμετωπίσει ως μικρή παραλλαγή. Είναι αντίφαση. Το ίδιο ισχύει για τιμές, ποσοστά, ημερομηνίες, εκπτώσεις, όρια χρήσης και περιόδους χρέωσης. Παράλληλα, πρέπει να ελέγχει τις οντότητες. Ονόματα ανθρώπων, εταιρειών, ερευνητικών ιδρυμάτων και παραπομπών πρέπει να εμφανίζονται σε τουλάχιστον ένα ανακτημένο τεκμήριο. Αν δεν εμφανίζονται, η σχετική πρόταση πρέπει να αφαιρεθεί ή να ξαναγραφτεί.
Διόρθωση πριν από την παράδοση
Ο έλεγχος από μόνος του δεν αρκεί. Ένα ώριμο σύστημα πρέπει να αποφασίζει τι θα κάνει με την προβληματική απάντηση. Υπάρχουν τρεις πρακτικές στρατηγικές. Η πρώτη είναι η στοχευμένη διόρθωση αντίφασης. Αν η απάντηση λέει «10 δολάρια τον μήνα» και η πηγή λέει «120 δολάρια τον χρόνο, με ετήσια χρέωση», το σύστημα μπορεί να αντικαταστήσει όχι μόνο τον αριθμό αλλά και όλη τη διατύπωση της περιόδου χρέωσης. Έτσι η πρόταση γίνεται «120 δολάρια τον χρόνο, με ετήσια χρέωση» και δεν μένει πίσω ένα γλωσσικό υπόλειμμα που παραπλανά.
Η δεύτερη στρατηγική είναι η αφαίρεση μη επαληθεύσιμων οντοτήτων. Αν μια απάντηση αναφέρει ερευνητές ή άρθρα που δεν υπάρχουν στις πηγές, οι σχετικές προτάσεις μπορούν να αφαιρεθούν και να προστεθεί σύντομη σημείωση ότι συγκεκριμένα ονόματα ή αναφορές δεν επαληθεύτηκαν. Η τρίτη στρατηγική είναι η ανασύνθεση από την πηγή. Όταν η πιστότητα είναι πολύ χαμηλή, είναι προτιμότερο να ξαναχτιστεί η απάντηση από τις πιο σχετικές προτάσεις των ανακτημένων εγγράφων. Σε περιπτώσεις υψηλού κινδύνου, όπως νομικές, ιατρικές ή διοικητικές υπηρεσίες, η ασφαλής άρνηση είναι προτιμότερη από μια καλοδιατυπωμένη ανακρίβεια.
Τι σημαίνει αυτό για ανοιχτά και αξιόπιστα συστήματα
Ο περιορισμός των παραισθήσεων δεν είναι μόνο τεχνικό θέμα. Είναι ζήτημα λογοδοσίας. Κάθε διόρθωση πρέπει να καταγράφεται. Κάθε αποδεκτή, διορθωμένη ή απορριφθείσα απάντηση πρέπει να αφήνει ίχνος. Οι διαχειριστές πρέπει να βλέπουν αν ένα μοντέλο διορθώνεται συνεχώς στο ίδιο πεδίο, αν ένα ευρετήριο παράγει αστάθεια ή αν μια πηγή δημιουργεί συστηματικές αντιφάσεις. Η λογική είναι απλή: retrieve, generate, inspect, score, heal, deliver. Ανακτώ, παράγω, ελέγχω, βαθμολογώ, διορθώνω και μόνο τότε παραδίδω.
Για την ελληνική γλώσσα και για εφαρμογές δημόσιου ενδιαφέροντος, αυτή η προσέγγιση έχει ιδιαίτερη σημασία. Χρειαζόμαστε RAG συστήματα με ανοιχτά δεδομένα, τεκμηριωμένα σώματα κειμένων, ανοιχτό κώδικα, επαναλήψιμες δοκιμές και ανθρώπινη εποπτεία. Η αξιοπιστία δεν θα προκύψει επειδή ένα μοντέλο είναι μεγάλο. Θα προκύψει επειδή κάθε απάντηση μπορεί να ελεγχθεί, να εξηγηθεί και, όταν χρειάζεται, να διορθωθεί πριν προκαλέσει ζημιά.
Από την απλή ανάκτηση εγγράφων στον έλεγχο της απάντησης πριν φτάσει στον χρήστη
Τα συστήματα RAG δημιουργήθηκαν για να λύσουν ένα πολύ συγκεκριμένο πρόβλημα της γενετικής Τεχνητής Νοημοσύνης: την τάση των μεγάλων γλωσσικών μοντέλων να απαντούν με ευφράδεια ακόμη και όταν δεν γνωρίζουν. Η βασική ιδέα είναι απλή. Αντί το μοντέλο να βασίζεται μόνο στη μνήμη που απέκτησε κατά την εκπαίδευσή του, αναζητά πρώτα σχετικά έγγραφα και στη συνέχεια διατυπώνει απάντηση στηριγμένη σε αυτά. Στην πράξη, όμως, η ανάκτηση του σωστού εγγράφου δεν εγγυάται ότι η τελική απάντηση θα είναι σωστή. Το μοντέλο μπορεί να έχει μπροστά του την ακριβή πηγή και παρ’ όλα αυτά να την παραποιήσει, να αντιστρέψει το νόημά της ή να προσθέσει στοιχεία που δεν υπάρχουν πουθενά.
Αυτό είναι το κρίσιμο σημείο. Η παραισθητική απάντηση σε ένα απλό chatbot μπορεί να αντιμετωπιστεί με επιφυλακτικότητα από τον χρήστη. Σε ένα σύστημα RAG, όμως, η απάντηση εμφανίζεται ως τεκμηριωμένη. Ο χρήστης θεωρεί ότι το σύστημα διάβασε τις πηγές και άρα δικαιούται μεγαλύτερη εμπιστοσύνη. Γι’ αυτό ο περιορισμός των παραισθήσεων δεν μπορεί να σταματά στην καλύτερη αναζήτηση. Πρέπει να υπάρχει ένα επιπλέον στρώμα ελέγχου μετά τη δημιουργία της απάντησης και πριν από την εμφάνισή της.
Οι πέντε συνηθέστερες αστοχίες
Η πρώτη αστοχία είναι η υπερβολική βεβαιότητα χωρίς τεκμηρίωση. Το μοντέλο γράφει «σίγουρα», «είναι σαφές», «όπως αναφέρεται», ενώ η πληροφορία δεν υπάρχει στο ανακτημένο υλικό. Αυτή η μορφή είναι επικίνδυνη επειδή δεν φαίνεται ως αβεβαιότητα αλλά ως αυθεντία. Η δεύτερη είναι η αριθμητική αντίφαση. Το έγγραφο λέει ότι η προθεσμία επιστροφής είναι 14 ημέρες και η απάντηση γράφει 30 ημέρες. Ή η πηγή αναφέρει ότι το πρόγραμμα κοστίζει 120 δολάρια τον χρόνο και η απάντηση το παρουσιάζει ως 10 δολάρια τον μήνα. Η τρίτη είναι η επινόηση προσώπων, οργανισμών ή βιβλιογραφικών αναφορών. Για παράδειγμα, το μοντέλο μπορεί να επικαλεστεί έναν «Dr. James Harrison» ή ένα ανύπαρκτο arXiv paper, ενώ κανένα από αυτά δεν υπάρχει στα σχετικά έγγραφα. Η τέταρτη είναι η αντιστροφή άρνησης. Η πηγή λέει ότι μια υπηρεσία «δεν υποστηρίζει ακύρωση μετά την πληρωμή» και η απάντηση γράφει ότι «υποστηρίζει ακύρωση μετά την πληρωμή». Η πέμπτη είναι η διολίσθηση της απάντησης στον χρόνο. Η ίδια ερώτηση για την τιμή ενός προϊόντος μπορεί να απαντάται επί εβδομάδες ως 49,99 ευρώ και ξαφνικά, μετά από ανανέωση του ευρετηρίου, να επιστρέφει 39,99 ευρώ χωρίς καμία ειδοποίηση.
Έλεγχος πιστότητας, αντίφασης και οντοτήτων
Ένα πρακτικό σύστημα προστασίας πρέπει να εξετάζει την απάντηση με απλούς αλλά αυστηρούς κανόνες. Πρώτα, μετρά την πιστότητα. Χωρίζει την απάντηση σε προτάσεις που περιέχουν πραγματολογικούς ισχυρισμούς και εξετάζει αν οι βασικές λέξεις κάθε ισχυρισμού υπάρχουν στο ανακτημένο υλικό. Αν πολλές προτάσεις δεν μπορούν να συνδεθούν με την πηγή, η απάντηση δεν πρέπει να προωθείται ως αξιόπιστη.
Έπειτα, ελέγχει αριθμούς και χρονικές εκφράσεις. Αν το πλαίσιο λέει «14 ημέρες» και η απάντηση γράφει «30 ημέρες», το σύστημα δεν πρέπει να το αντιμετωπίσει ως μικρή παραλλαγή. Είναι αντίφαση. Το ίδιο ισχύει για τιμές, ποσοστά, ημερομηνίες, εκπτώσεις, όρια χρήσης και περιόδους χρέωσης. Παράλληλα, πρέπει να ελέγχει τις οντότητες. Ονόματα ανθρώπων, εταιρειών, ερευνητικών ιδρυμάτων και παραπομπών πρέπει να εμφανίζονται σε τουλάχιστον ένα ανακτημένο τεκμήριο. Αν δεν εμφανίζονται, η σχετική πρόταση πρέπει να αφαιρεθεί ή να ξαναγραφτεί.
Διόρθωση πριν από την παράδοση
Ο έλεγχος από μόνος του δεν αρκεί. Ένα ώριμο σύστημα πρέπει να αποφασίζει τι θα κάνει με την προβληματική απάντηση. Υπάρχουν τρεις πρακτικές στρατηγικές. Η πρώτη είναι η στοχευμένη διόρθωση αντίφασης. Αν η απάντηση λέει «10 δολάρια τον μήνα» και η πηγή λέει «120 δολάρια τον χρόνο, με ετήσια χρέωση», το σύστημα μπορεί να αντικαταστήσει όχι μόνο τον αριθμό αλλά και όλη τη διατύπωση της περιόδου χρέωσης. Έτσι η πρόταση γίνεται «120 δολάρια τον χρόνο, με ετήσια χρέωση» και δεν μένει πίσω ένα γλωσσικό υπόλειμμα που παραπλανά.
Η δεύτερη στρατηγική είναι η αφαίρεση μη επαληθεύσιμων οντοτήτων. Αν μια απάντηση αναφέρει ερευνητές ή άρθρα που δεν υπάρχουν στις πηγές, οι σχετικές προτάσεις μπορούν να αφαιρεθούν και να προστεθεί σύντομη σημείωση ότι συγκεκριμένα ονόματα ή αναφορές δεν επαληθεύτηκαν. Η τρίτη στρατηγική είναι η ανασύνθεση από την πηγή. Όταν η πιστότητα είναι πολύ χαμηλή, είναι προτιμότερο να ξαναχτιστεί η απάντηση από τις πιο σχετικές προτάσεις των ανακτημένων εγγράφων. Σε περιπτώσεις υψηλού κινδύνου, όπως νομικές, ιατρικές ή διοικητικές υπηρεσίες, η ασφαλής άρνηση είναι προτιμότερη από μια καλοδιατυπωμένη ανακρίβεια.
Τι σημαίνει αυτό για ανοιχτά και αξιόπιστα συστήματα
Ο περιορισμός των παραισθήσεων δεν είναι μόνο τεχνικό θέμα. Είναι ζήτημα λογοδοσίας. Κάθε διόρθωση πρέπει να καταγράφεται. Κάθε αποδεκτή, διορθωμένη ή απορριφθείσα απάντηση πρέπει να αφήνει ίχνος. Οι διαχειριστές πρέπει να βλέπουν αν ένα μοντέλο διορθώνεται συνεχώς στο ίδιο πεδίο, αν ένα ευρετήριο παράγει αστάθεια ή αν μια πηγή δημιουργεί συστηματικές αντιφάσεις. Η λογική είναι απλή: retrieve, generate, inspect, score, heal, deliver. Ανακτώ, παράγω, ελέγχω, βαθμολογώ, διορθώνω και μόνο τότε παραδίδω.
Για την ελληνική γλώσσα και για εφαρμογές δημόσιου ενδιαφέροντος, αυτή η προσέγγιση έχει ιδιαίτερη σημασία. Χρειαζόμαστε RAG συστήματα με ανοιχτά δεδομένα, τεκμηριωμένα σώματα κειμένων, ανοιχτό κώδικα, επαναλήψιμες δοκιμές και ανθρώπινη εποπτεία. Η αξιοπιστία δεν θα προκύψει επειδή ένα μοντέλο είναι μεγάλο. Θα προκύψει επειδή κάθε απάντηση μπορεί να ελεγχθεί, να εξηγηθεί και, όταν χρειάζεται, να διορθωθεί πριν προκαλέσει ζημιά.
Πηγές άρθρου:
Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: Η εργασία που εισήγαγε το RAG ως συνδυασμό παραμετρικής μνήμης γλωσσικού μοντέλου και μη παραμετρικής μνήμης μέσω ανακτημένων τεκμηρίων: https://arxiv.org/abs/2005.11401,
Honovich et al., TRUE: Re-evaluating Factual Consistency Evaluation: Χρήσιμη εργασία για την αξιολόγηση της πραγματολογικής συνέπειας παραγόμενων κειμένων και για το γιατί η απλή ευφράδεια δεν αρκεί ως ένδειξη αξιοπιστίας: https://arxiv.org/abs/2204.04991,
Min et al., FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation: Συμβολή στην αξιολόγηση παραγόμενων απαντήσεων μέσω διάσπασης του κειμένου σε επιμέρους πραγματολογικούς ισχυρισμούς: https://arxiv.org/abs/2305.14251,
Es et al., RAGAS: Automated Evaluation of Retrieval Augmented Generation: Πλαίσιο αξιολόγησης RAG συστημάτων που εξετάζει την ποιότητα ανάκτησης, την πιστότητα της απάντησης και τη συνολική ποιότητα παραγωγής χωρίς να απαιτεί πάντα ανθρώπινη παρέμβαση: https://arxiv.org/abs/2309.15217,
Emmimal, hallucination-detector: Ανοιχτό αποθετήριο με πρακτική υλοποίηση ελέγχου, βαθμολόγησης, διόρθωσης και δρομολόγησης απαντήσεων RAG με δοκιμές για συχνές μορφές παραισθήσεων: https://github.com/Emmimal/hallucination-detector/.
Το Greeks in AI 2026 ανακοίνωσε επίσημα το Call for Papers για το ετήσιο συμπόσιο που θα πραγματοποιηθεί στις 15–17 Ιουλίου 2026 στο Ίδρυμα Ευγενίδου στην Αθήνα, συγκεντρώνοντας ερευνητές, ακαδημαϊκούς και επαγγελματίες της Τεχνητής Νοημοσύνης από την Ελλάδα και το εξωτερικό.
Η διοργάνωση καλεί φοιτητές, υποψήφιους διδάκτορες, μεταδιδάκτορες και νέους ερευνητές να υποβάλουν την πρόσφατη ερευνητική τους δουλειά και να παρουσιάσουν τα αποτελέσματά τους σε ένα διεθνές κοινό με επίκεντρο την AI κοινότητα ελληνικής καταγωγής.
Υποβολές εργασιών έως 15 Μαΐου 2026
Η καταληκτική ημερομηνία υποβολής είναι η 15η Μαΐου 2026, ενώ οι εργασίες θα πρέπει να κατατεθούν μέσω της πλατφόρμας OpenReview.
Οι υποβολές μπορούν να αφορούν papers που έχουν υποβληθεί ή γίνει αποδεκτά μέσα στον τελευταίο χρόνο, καλύπτοντας ένα ευρύ φάσμα θεμάτων στην Τεχνητή Νοημοσύνη και τη Μηχανική Μάθηση.
Οι αποδεκτές εργασίες θα παρουσιαστούν είτε ως:
posters,
spotlight talks,
είτε ως σύντομες 6λεπτες oral presentations κατά τη διάρκεια του συμποσίου.
Ενδεικτικά θέματα ενδιαφέροντος
Μεταξύ άλλων, το Greeks in AI 2026 δέχεται εργασίες στις εξής περιοχές:
Το Coordinate me επιστρέφει για τρίτη χρονιά ως διεθνής διαγωνισμός στο Wikidata, με στόχο την ενίσχυση και εμπλουτισμό δεδομένων που περιλαμβάνουν γεωγραφικές πληροφορίες – από μικρούς οικισμούς και φαρμακεία έως δημόσια τέχνη και φυσικά μνημεία.
Ο διαγωνισμός επικεντρώνεται στη δημιουργία και βελτίωση στοιχείων στο Wikidata που σχετίζονται με συγκεκριμένες χώρες-στόχους, ενισχύοντας έτσι την ποιότητα και την πληρότητα των ανοιχτών γεωδεδομένων.
Το Coordinate me 2026 θα πραγματοποιηθεί από τις 1 έως τις 31 Μαΐου 2026. Κατά τη διάρκειά του, συντάκτες από όλο τον κόσμο θα έχουν τη δυνατότητα να συμμετάσχουν, συμβάλλοντας ενεργά στην ενίσχυση της γνώσης που διατίθεται ελεύθερα μέσω του Wikidata.
Για τη συμμετοχή τους, οι ενδιαφερόμενοι μπορούν να ακολουθήσουν τις αναλυτικές οδηγίες που είναι διαθέσιμες στη σχετική σελίδα του εγχειρήματος.
Συνολικά, θα απονεμηθούν βραβεία αξίας 4.850 ευρώ σε διακριθέντες συμμετέχοντες, ως αναγνώριση της συνεισφοράς τους.
Ο διαγωνισμός υποστηρίζεται από το Wikimedia Community User Group Greece.
Η Ευρωπαϊκή Ένωση εισέρχεται σε μια κρίσιμη περίοδο για τη ρύθμιση του ψηφιακού χώρου. Μετά την υιοθέτηση σημαντικών νομοθεσιών όπως ο Νόμος για τις Ψηφιακές Υπηρεσίες (DSA), ο Νόμος για τις Ψηφιακές Αγορές (DMA) και ο Κανονισμός για την Τεχνητή Νοημοσύνη (AI Act), το ενδιαφέρον στρέφεται πλέον στην εφαρμογή τους και στη διασφάλιση ότι οι νέοι κανόνες θα προστατεύουν πραγματικά τα δικαιώματα των πολιτών.
Στο πλαίσιο αυτό, η Ευρωπαϊκή Επιτροπή προωθεί τον νέο Νόμο Ψηφιακής Δικαιοσύνης (Digital Fairness Act – DFA), με στόχο να αντιμετωπίσει φαινόμενα όπως οι παραπλανητικές πρακτικές σχεδιασμού (“dark patterns”), η καταχρηστική εξατομίκευση περιεχομένου και οι αθέμιτες πρακτικές των ψηφιακών πλατφορμών. Σύμφωνα με τις Οργανώσεις Ψηφιακών Δικαιωμάτων, ο νέος νόμος μπορεί να αποτελέσει σημαντικό βήμα υπέρ των χρηστών — αρκεί να επικεντρωθεί στις πραγματικές αιτίες των προβλημάτων και όχι σε επιφανειακές λύσεις.
Η ανάγκη για προστασία της ιδιωτικότητας
Οι Οργανώσεις Ψηφιακών Δικαιωμάτων τονίζουν ότι η ψηφιακή αδικία βασίζεται κυρίως στη μαζική συλλογή και εκμετάλλευση προσωπικών δεδομένων. Η συνεχής παρακολούθηση των χρηστών και η δημιουργία προφίλ συμπεριφοράς αποτελούν τη βάση πολλών επιβλαβών πρακτικών, από τις χειραγωγικές διαφημίσεις μέχρι τις αδιαφανείς προτάσεις περιεχομένου.
Για τον λόγο αυτό, προτείνεται ο νέος νόμος να περιορίσει τα επιχειρηματικά μοντέλα που βασίζονται στην παρακολούθηση. Οι χρήστες δεν θα πρέπει να αναγκάζονται είτε να παραχωρούν τα προσωπικά τους δεδομένα είτε να πληρώνουν επιπλέον χρήματα για να προστατεύσουν την ιδιωτικότητά τους. Παράλληλα, οι οργανώσεις ζητούν την αναγνώριση αυτόματων ρυθμίσεων απορρήτου από browsers και λειτουργικά συστήματα, ώστε οι πολίτες να μπορούν πιο εύκολα να απορρίπτουν την παρακολούθηση.
Ιδιαίτερη έμφαση δίνεται και στην προστασία των παιδιών. Αντί για υποχρεωτικά συστήματα επαλήθευσης ηλικίας — τα οποία θεωρούνται επεμβατικά και επικίνδυνα για την ιδιωτικότητα — προτείνεται ο περιορισμός της συλλογής δεδομένων ανηλίκων εξαρχής.
Τι είναι τα “dark patterns”
Ένα από τα βασικά ζητήματα που θέλει να αντιμετωπίσει ο DFA είναι τα λεγόμενα “dark patterns”. Πρόκειται για τεχνικές σχεδιασμού που χρησιμοποιούνται από εταιρείες για να επηρεάζουν ή να χειραγωγούν τις αποφάσεις των χρηστών.
Παραδείγματα τέτοιων πρακτικών είναι:
κουμπιά που δυσκολεύουν την απόρριψη cookies,
παραπλανητικές επιλογές συνδρομών,
πολύπλοκες διαδικασίες διαγραφής λογαριασμού,
σχεδιασμός που ωθεί τους χρήστες να μοιράζονται περισσότερα δεδομένα από όσα επιθυμούν.
Οι Οργανώσεις Ψηφιακών Δικαιωμάτων ζητούν σαφή απαγόρευση τέτοιων πρακτικών, καθώς θεωρούν ότι περιορίζουν την ελευθερία επιλογής και υπονομεύουν την αυτονομία των πολιτών στο διαδίκτυο.
Ενίσχυση της κυριαρχίας των χρηστών
Ένα ακόμη σημαντικό ζήτημα αφορά τον έλεγχο που έχουν οι πολίτες πάνω στις ψηφιακές υπηρεσίες και τα προϊόντα που αγοράζουν. Σήμερα, πολλές εταιρείες επιβάλλουν περιορισμούς μέσω ασαφών όρων χρήσης, τεχνικών περιορισμών ή απομακρυσμένου ελέγχου συσκευών και εφαρμογών.
Στην πράξη, αυτό σημαίνει ότι ένας χρήστης μπορεί:
να χάσει πρόσβαση σε ψηφιακό περιεχόμενο που έχει αγοράσει,
να μην μπορεί να επισκευάσει ή να τροποποιήσει μια συσκευή,
να εξαρτάται αποκλειστικά από μία πλατφόρμα ή υπηρεσία.
Οι οργανώσεις ζητούν ο DFA να ενισχύσει το δικαίωμα των χρηστών να ελέγχουν τις ψηφιακές τους συσκευές και υπηρεσίες, να διευκολύνει τη μεταφορά δεδομένων μεταξύ πλατφορμών και να προωθήσει τη διαλειτουργικότητα μεταξύ εφαρμογών και υπηρεσιών.
Μια διαφορετική προσέγγιση για το ψηφιακό μέλλον
Σύμφωνα με τις Οργανώσεις Ψηφιακών Δικαιωμάτων, η ψηφιακή δικαιοσύνη δεν μπορεί να επιτευχθεί μέσω περισσότερης επιτήρησης ή αυστηρότερου ελέγχου των χρηστών. Αντίθετα, απαιτείται ένα πλαίσιο που να ενισχύει:
την ιδιωτικότητα,
την ελευθερία έκφρασης,
τη διαφάνεια,
και την πραγματική δυνατότητα επιλογής.
Ο Νόμος Ψηφιακής Δικαιοσύνης μπορεί να αποτελέσει σημαντική ευκαιρία για την Ευρώπη να δημιουργήσει ένα πιο δίκαιο και ασφαλές ψηφιακό περιβάλλον. Το ερώτημα είναι αν οι τελικές ρυθμίσεις θα περιορίσουν πραγματικά την εξουσία των μεγάλων ψηφιακών πλατφορμών ή αν θα οδηγήσουν σε νέες μορφές ελέγχου και παρακολούθησης των πολιτών.
O πλανήτης αποτελεί ένα τόπο συνάντησης των μελών της ελληνικής κοινότητας ΕΛ/ΛΑΚ.
Τα άρθρα του πλανήτη συλλέγονται αυτόματα χωρίς ανθρώπινη παρέμβαση, αποτελούν πνευματική ιδιοκτησία των συγγραφέων τους και αντικατοπτρίζουν τις απόψεις τους.
Η διαχείριση του πλανήτη γίνεται δημόσια μέσα από το σχετικό repository της υπηρεσίας GitHub: greek-libre-planet, όπου μπορείς να ζητήσεις την προσθήκη του blog σου δηλώνοντας το feed της κατηγορίας, του tag, ή το γενικό feed του blog σου, το όνομα/επώνυμο σου και προαιρετικά το avatar σου, αφού πρώτα εγγραφείτε και κατόπιν συνδεθείτε στην υπηρεσία GitΗub, ανοίγοντας νέο issue που θα περιέχει τα συγκεκριμένα στοιχεία σου.
(Αν δεν έχετε λογαριασμό στην υπηρεσία GitHub, για να προστεθει το blog σου θα προστεθεί στον πλανήτη ΕΛ/ΛΑΚ μπορείτε εναλλακτικά να μας αποστειλετε τα παραπάνω στοιχεία στην ηλεκτρονική διεύθυνση info @ eellak gr.)










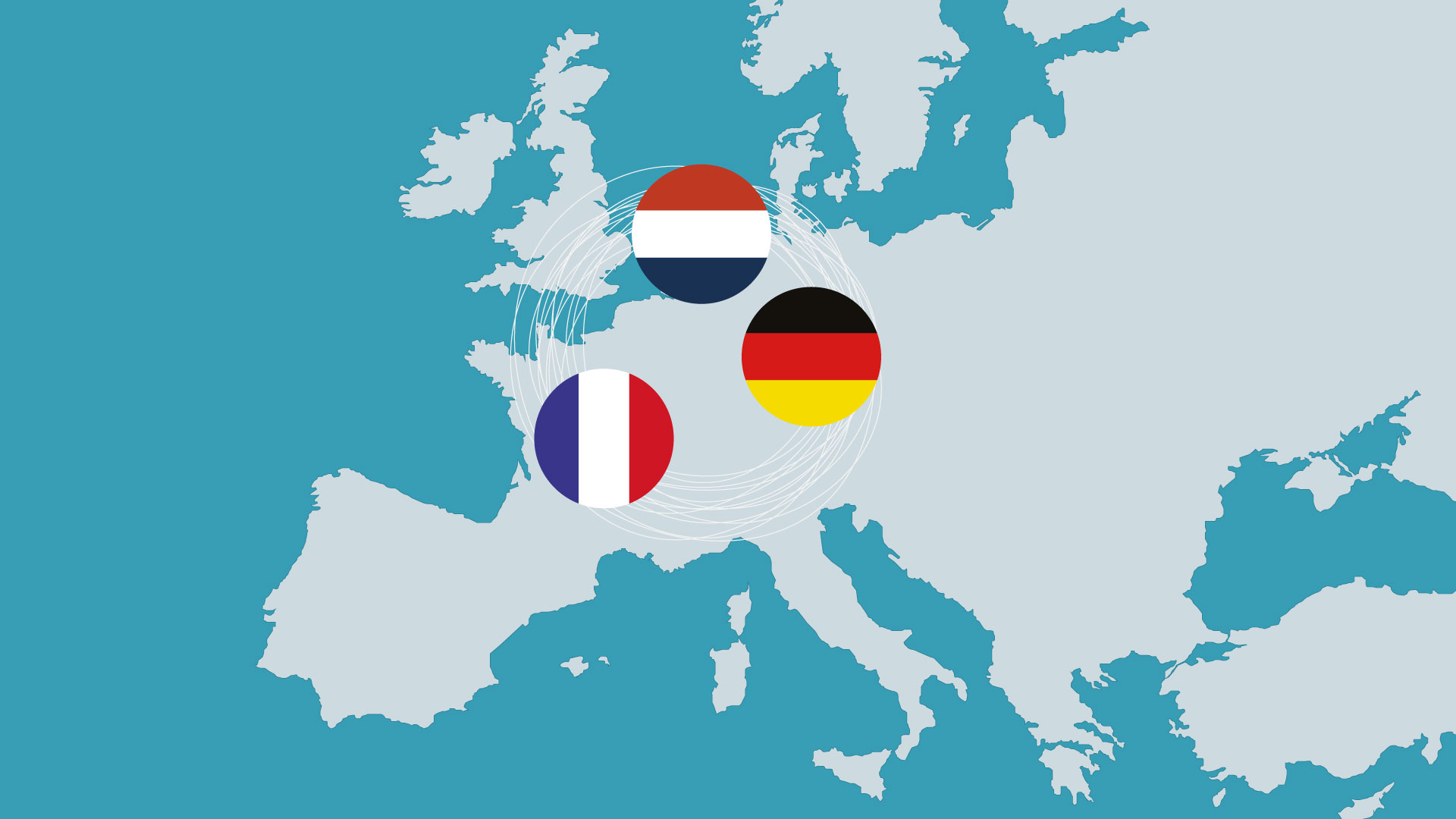









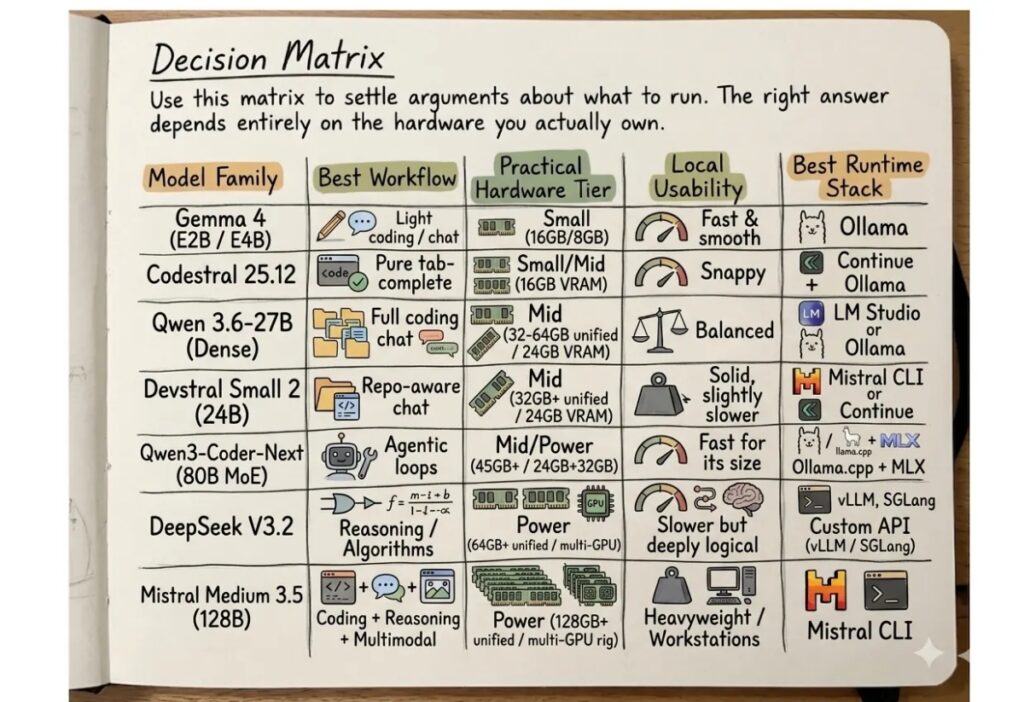
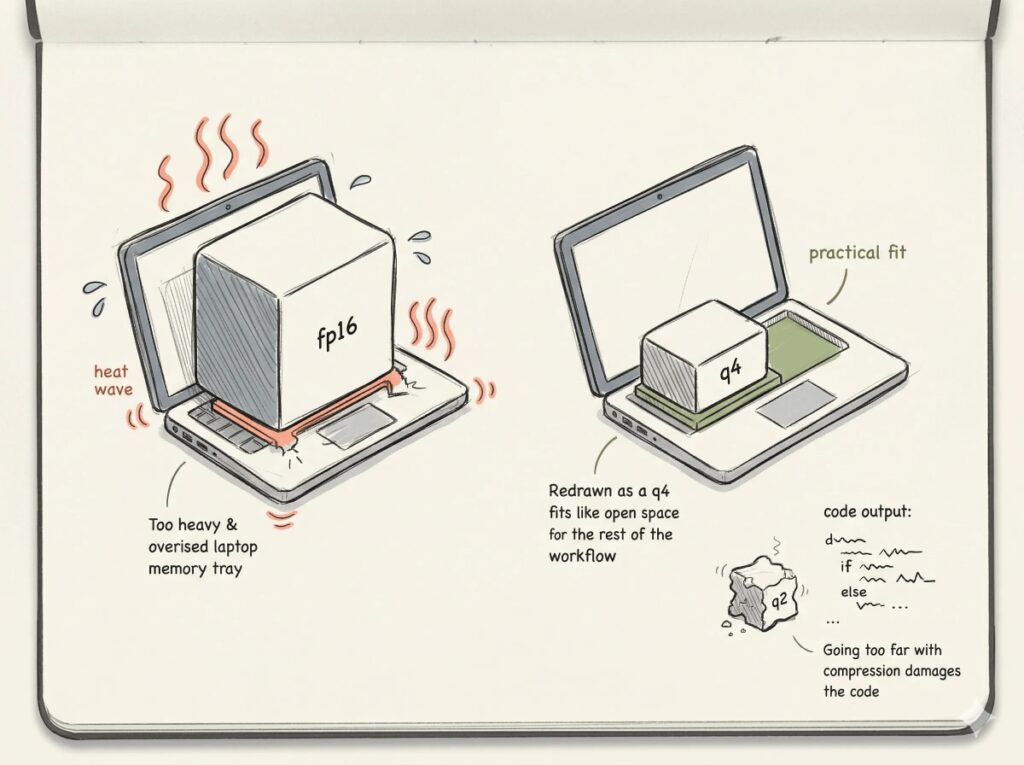















 «Τεχνολογίες επιτήρησης συνόρων: Περιγραφή, νομικό πλαίσιο και επιπτώσεις στα Δικαιώματα του Ανθρώπου» Εισηγητής: Λευτέρης Χελιουδάκης, Δικηγόρος LL.B. LL.M. Msc, PhD (c), Εκτελεστικός Διευθυντής της HomoDigitalis – Κυριακή 24 Μαΐου 2026 / 6-8 μ.μ. / [
«Τεχνολογίες επιτήρησης συνόρων: Περιγραφή, νομικό πλαίσιο και επιπτώσεις στα Δικαιώματα του Ανθρώπου» Εισηγητής: Λευτέρης Χελιουδάκης, Δικηγόρος LL.B. LL.M. Msc, PhD (c), Εκτελεστικός Διευθυντής της HomoDigitalis – Κυριακή 24 Μαΐου 2026 / 6-8 μ.μ. / [

























