Settings: temperature=1, top_p=0.95, 128k max output tokens via Xiaomi's API. The model has a 1M-token context window.
Both models are cheap to run: MiMo 2.5 at $0.04/test and the Pro at $0.09/test, putting them among the more cost-efficient options on the index.
Both hold up well on academic benchmarks: MMLU Pro lands at 84.6% for the Pro and 82.9% for the base, GPQA Diamond at 82.6% and 81.6%, and LiveCodeBench around 81.5% for both. MiMo 2.5 is also the #1 open-weight model on Terminal-Bench 2.1 (60.7%).
Both models will sometimes reason, and occasionally answer, in Chinese regardless of the prompt language. We saw a related issue on SAGE, where the model skips the system prompt and just solves the underlying question instead of grading the student response. It showed up more
The text-only limitation costs the Pro version on Vibe Code Bench. MiMo 2.5 can use screenshots to debug its own web app (42.2%), while the text-only Pro is essentially working blind (34.1%). This is the main reason 2.5 Pro ranks just below 2.5 on the index.
MiMo 2.5 and MiMo 2.5 Pro just landed on the Vals Index, ranking #5 and #6 among open-weight models, respectively. Pro is text-only, while MiMo 2.5 is multimodal, taking #3 on the Vals Multimodal Index (52.8%).
Consistent with Jack Clark + Gillian Hadfield's regulatory markets paper 3 years ago. Private orgs are often better at building tech needed to keep up with the market rather than slowing it down. But need the right incentive structure to be public good aligned.
Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-on…
We have added the ability to view Fable 5 scores with Opus 4.8 fallbacks disabled to the Vals AI website (refusals are marked as zero).
The eval community was ill-equipped for this, but transparency is our first priority.
We’re anticipating more models like this, and are
Going forward, evaluations will have to report not only on capability, but also how much of that capability is available to users.
We will soon be sharing updated methodology on tracking and reporting APIs that ship with fallback models or have high rejection rates.
We also saw a small quantity of rejections on our Finance Agent Benchmark. These were only on questions analyzing pharmaceutical or biological public companies.
Here is a stripped-down reproduction (real FAB questions are far harder)
The rejected tasks (16% overall) for Terminal Bench 2.1 were for biology and cyber.
The tasks were: write-compressor, vulnerable-secret, sam-cell-seg, protein-assembly, path-tracing-reverse, password-recovery, model-extraction-relu-logits, feal-linear-cryptanalysis,
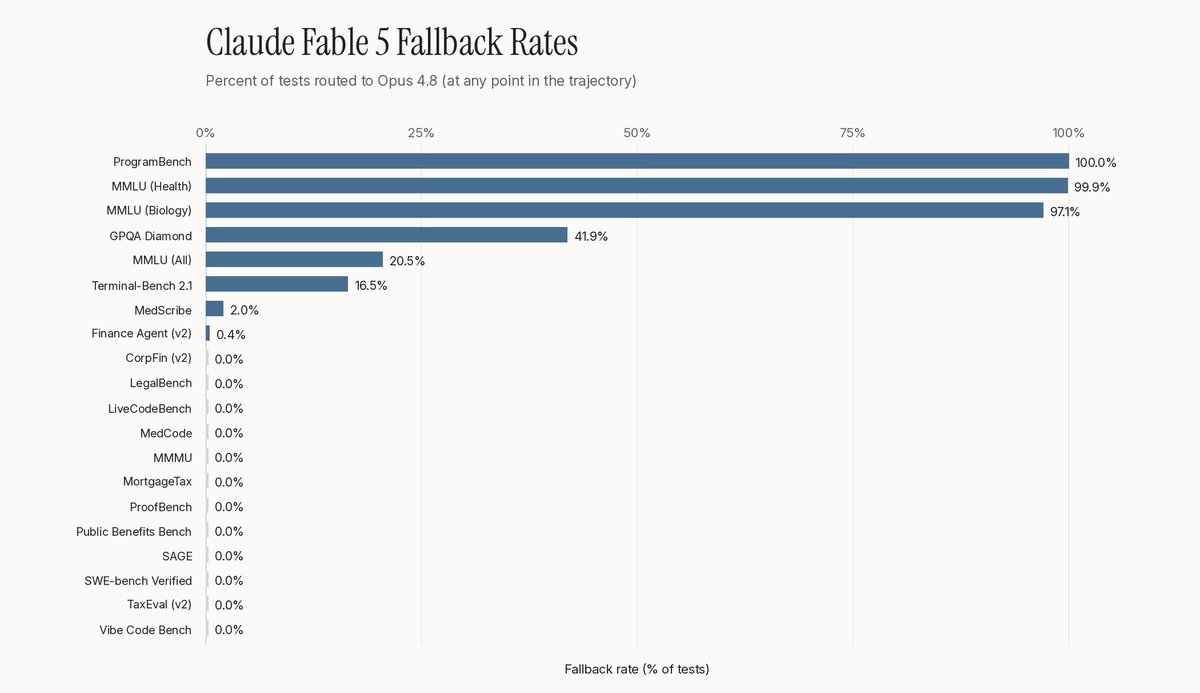
We are also releasing the per-benchmark fallback rates.
The majority of benchmarks had no or very low fallback rates, but as mentioned in our previous post, the safety classifier was highly sensitive to certain benchmarks.
For example, MMLU Biology and Health have nearly a 100%