Pinned

How can we unlock generalized reasoning?
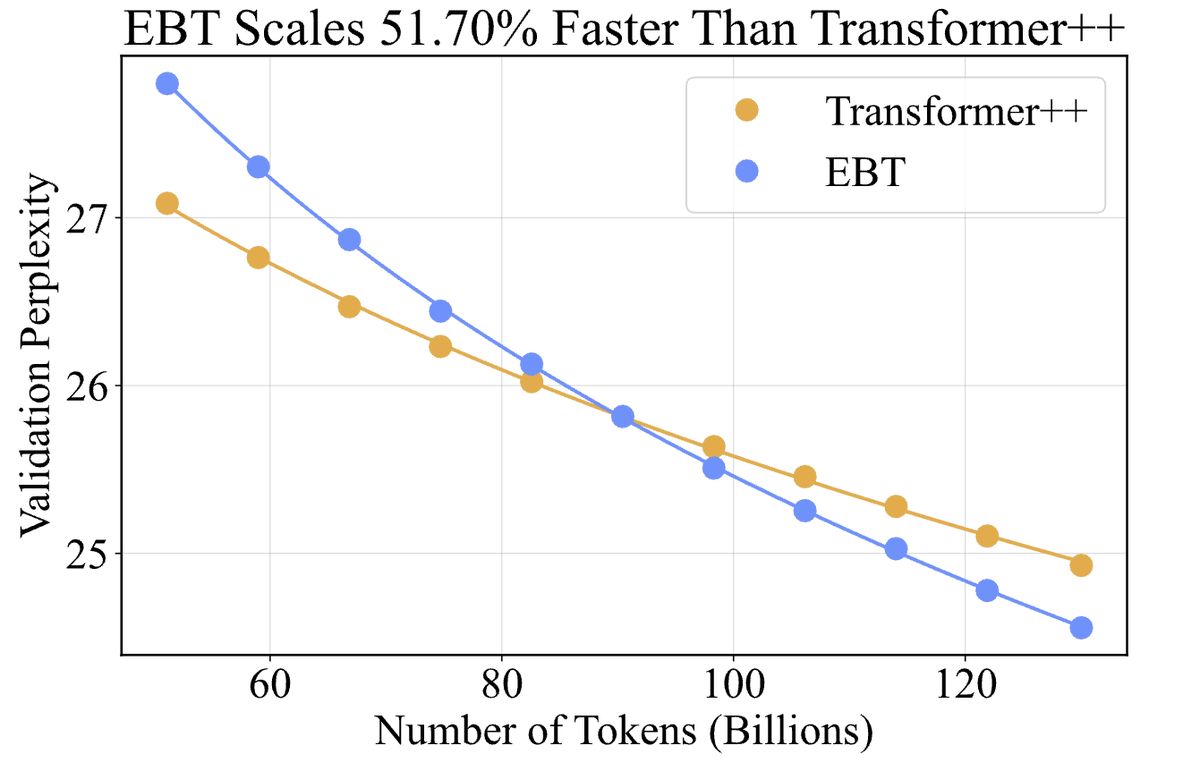
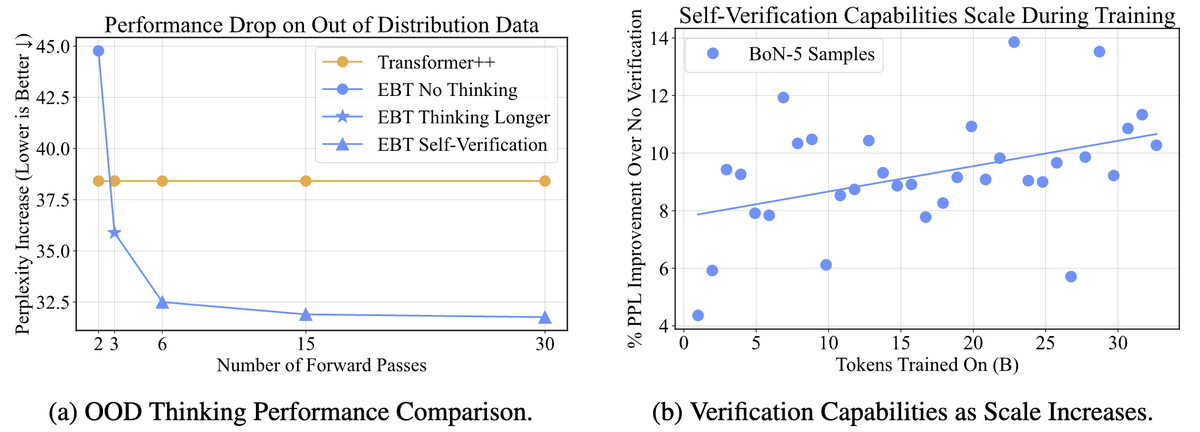
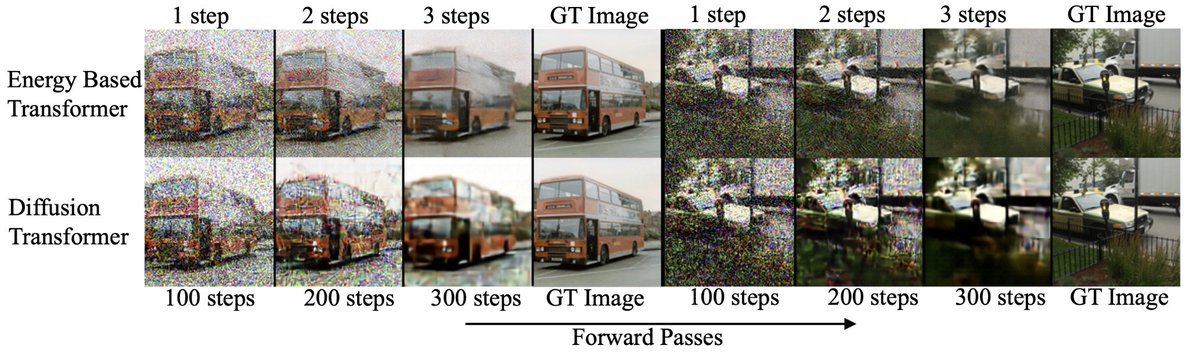
⚡️Introducing Energy-Based Transformers (EBTs), an approach that out-scales (feed-forward) transformers and unlocks generalized reasoning/thinking on any modality/problem without rewards.
TLDR:
- EBTs are the first model to outscale the