ICYMI, all of the sessions from #tvmcon are available for streaming! Catch up on the latest advances, case studies, and tutorials in #ML acceleration from the @ApacheTVM community. tvmcon.org
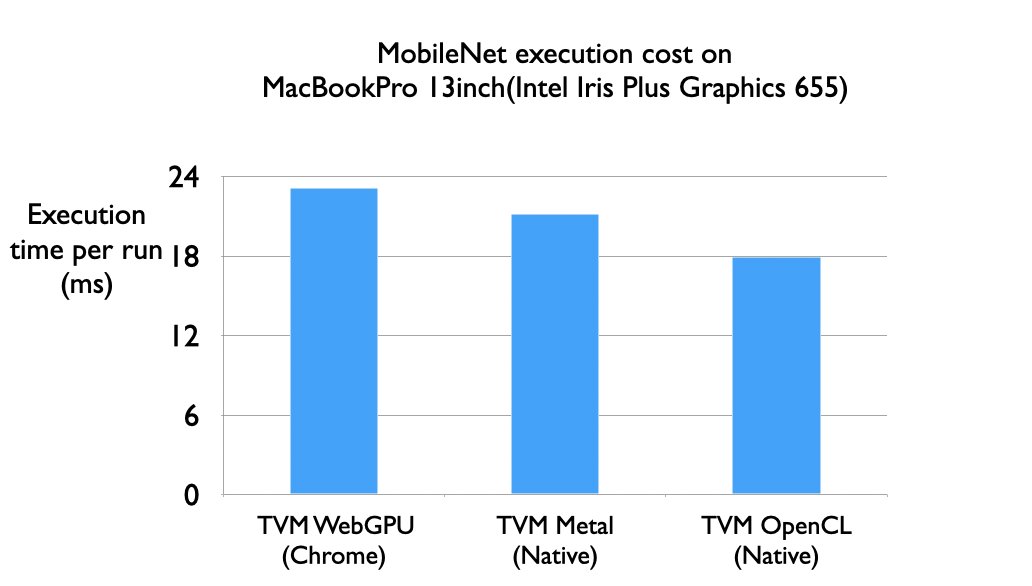
Compiling Machine Learning to WASM and WebGPU with Apache TVM. Preliminary experiments shows that TVM’s WebGPU backend can get close to native GPU performance when deploying models to the web.🚀🚀
tvm.apache.org/2020/05/14/com…
Bridging PyTorch and TVM tvm.apache.org/2020/07/14/ber… by @ThomasViehmann talks about using TVM to deploy 🤗 bert on AMD GPUs, and explores the initial path toward training compilation 🐴🐴
Presentation slides for TVM and Deep Learning Compiler Conference are now available. Check out 20+ talks on differentiable programming, quantization, IoT, ASIC, machine learning for systems and more sampl.cs.washington.edu/tvmconf/#about…
TVM 0.5 is here github.com/dmlc/tvm/relea… High-level differentiable programming Relay IR, flexible low bit quantization flow, better AutoTVM; @golang and @rustlang support; Most importantly, an open, collaborative and growing community!
Automating Optimization of Quantized Deep Learning Models on CUDA. With learning-based program optimizer. Wuwei Lin is able to get
competitive performance on benchmark models and significant boost on emerging models against TensorRT(int8). tvm.ai/2019/04/29/opt…
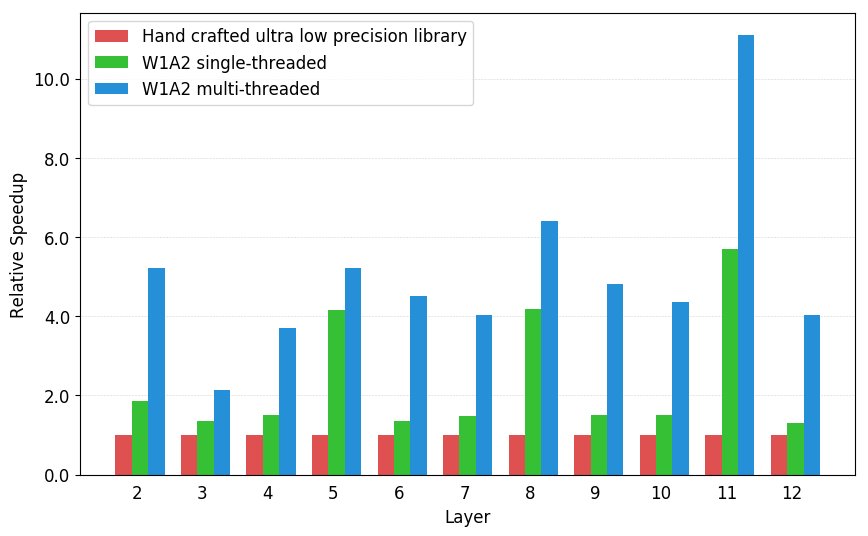
Blog: "Automating Generation of Low Precision Deep Learning Operators". Ultra low-bit deep learning operators have the potential to power IoT, but are extremely hard to write and optimize. Meghan from UW SAMPL group shows how to automate this process. tvm.ai/2018/12/18/low…
Introducing VTA, the open-source, generic, and customizable deep learning accelerator with a complete deep learning software stack, so you can start to experiment with hardware specialization right away with a friendly python interface: tvm.ai/2018/07/12/vta…