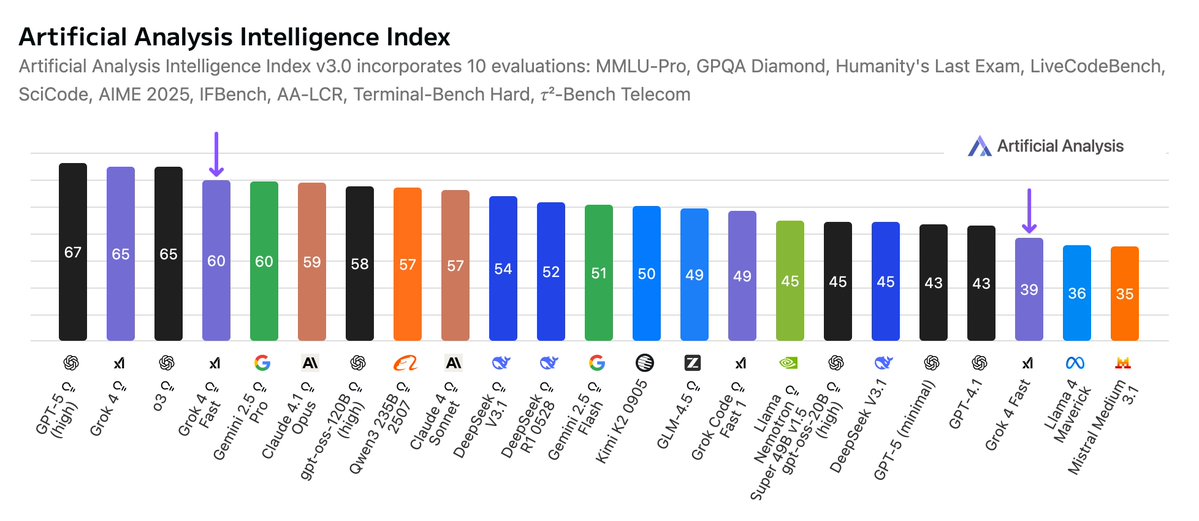
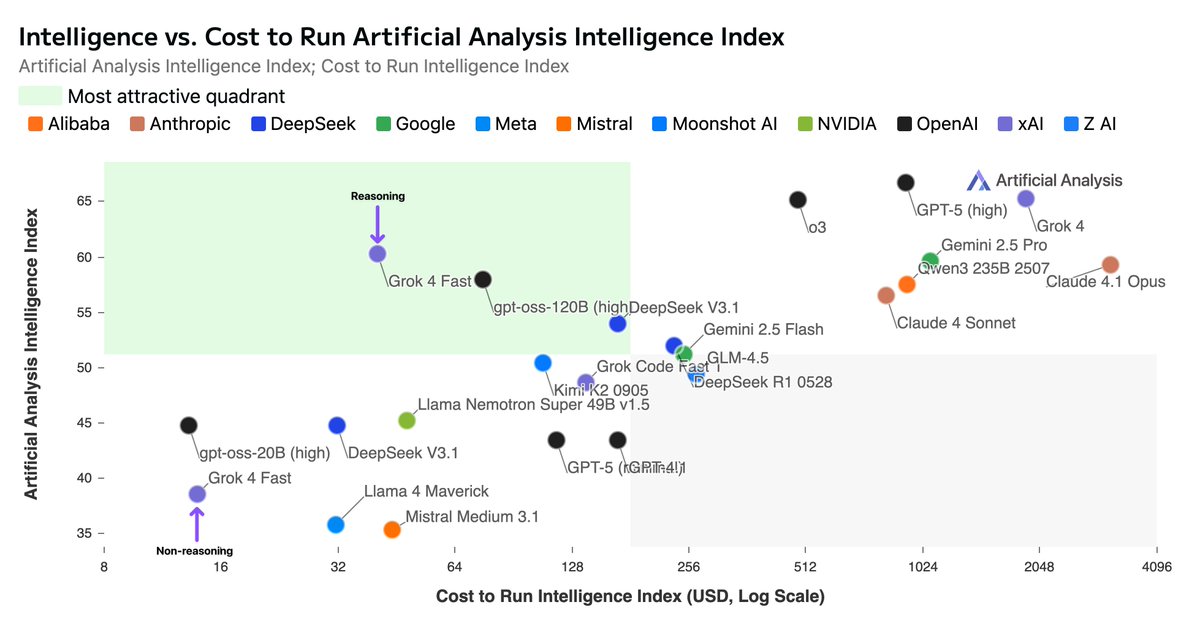
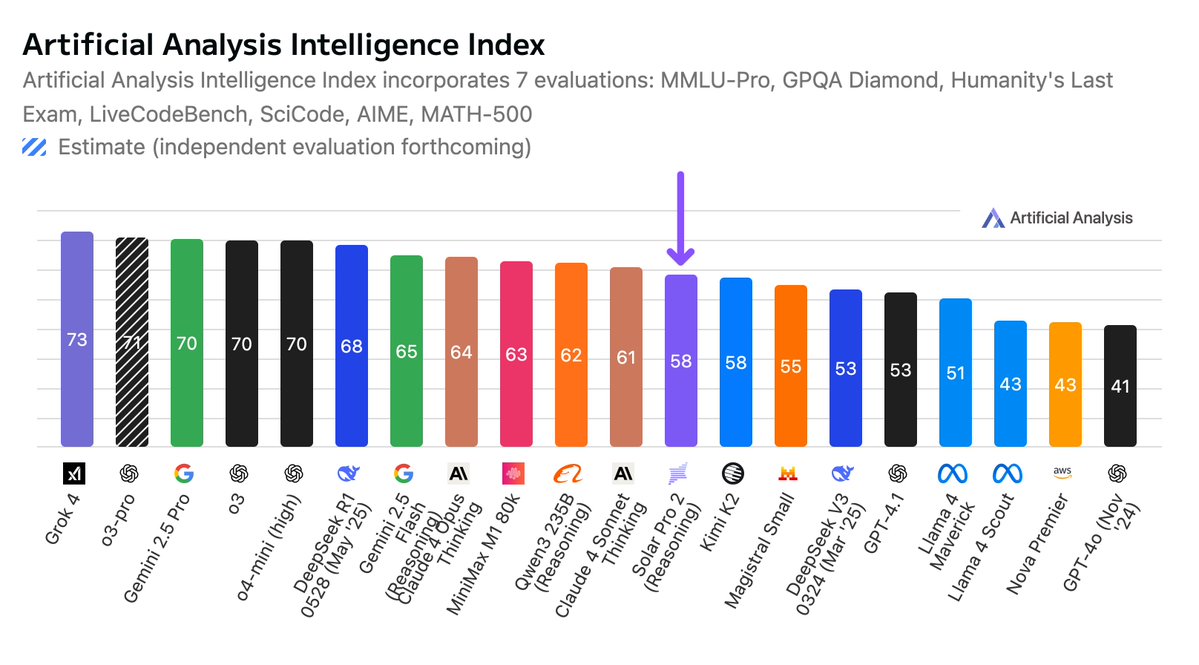
Pinned
Thanks for the support @AndrewYNg! Completely agree, faster token generation will become increasingly important as a greater proportion of output tokens are consumed by models, such as in multi-step agentic workflows, rather than being read by people.

Shoutout to the team that built artificialanalysis.ai . Really neat site that benchmarks the speed of different LLM API providers to help developers pick which models to use. This nicely complements the LMSYS Chatbot Arena, Hugging Face open LLM leaderboards and Stanford's HELM