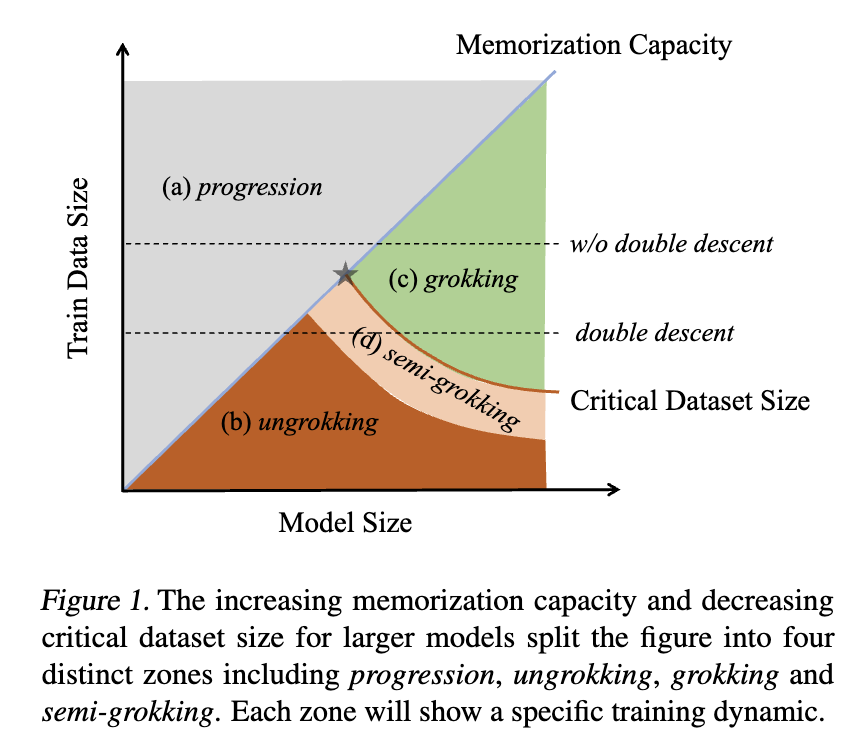
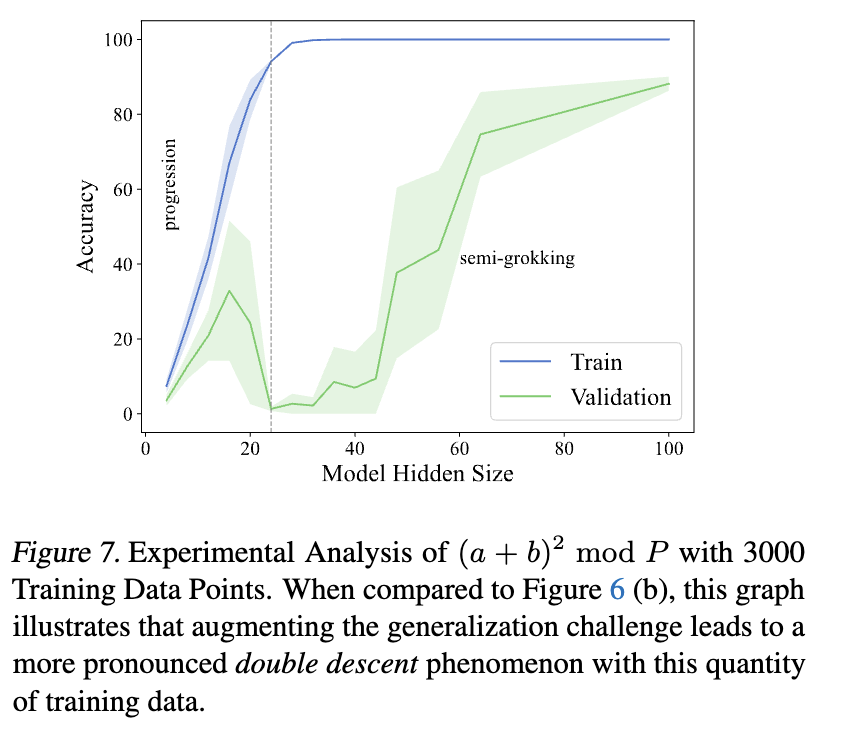
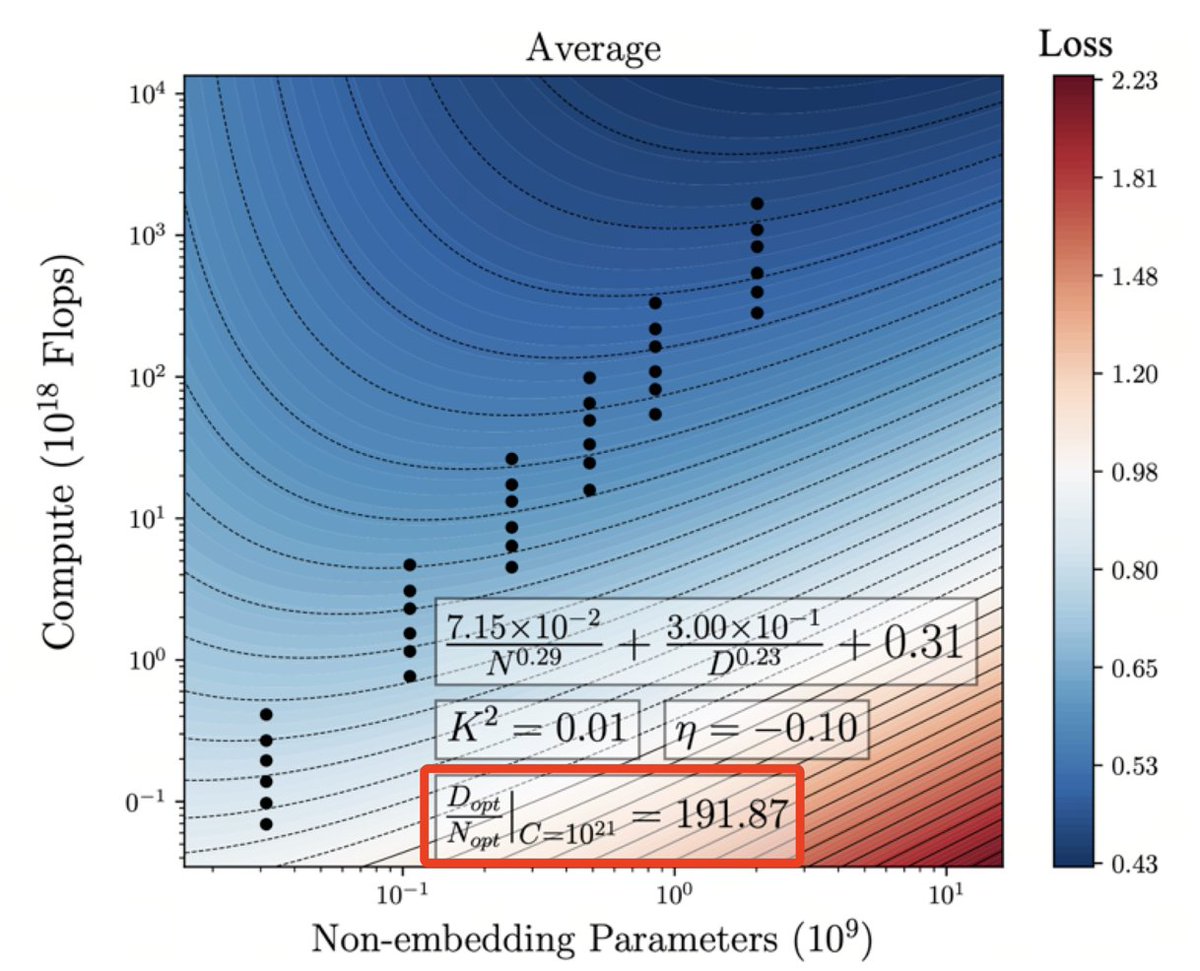
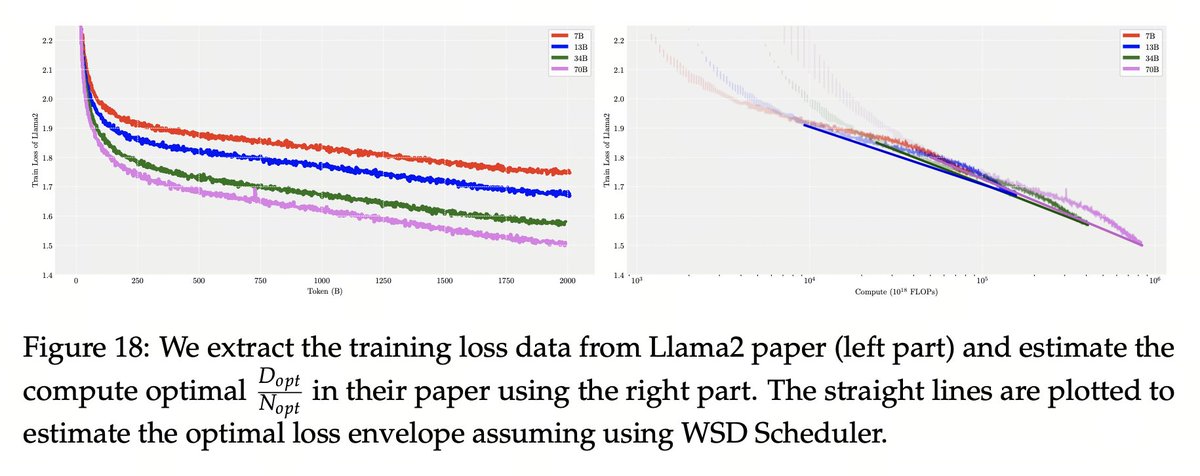
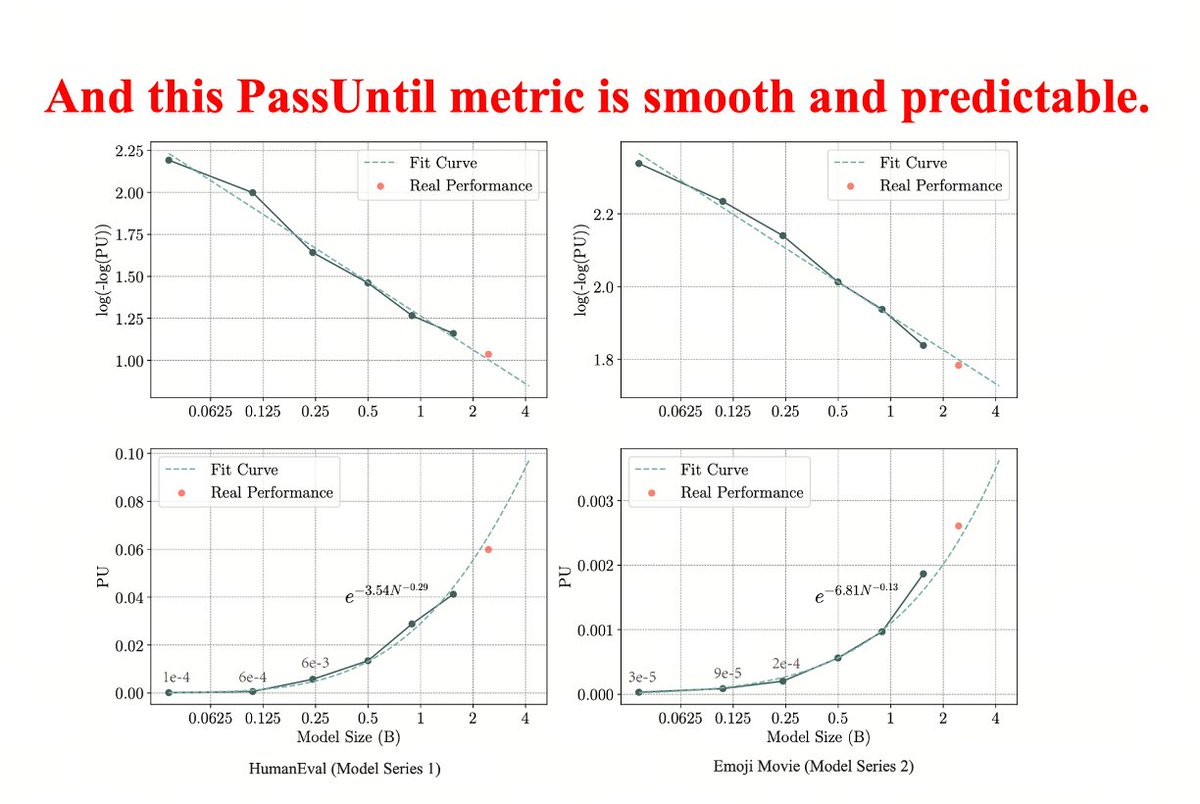
We are excited to share our recent results on the dynamics of model training from a mechanistic interpretability perspective. It appears that Grokking, Double Descent, and Emergent Ability might share the same underlying dynamics! #LLM
arxiv.org/abs/2402.15175