2/ A core issue with parameter-only RL is that it forces task-specific learning into the model weights. Traditional RL can improve model performance on the current task, but it also tends to shift behavior away from the base model, increase forgetting and reduce plasticity. On
4/ This reframes post-training. The default view treats adaptation as one channel — push every improvement into the weights — and pays for it with forgetting, eroded generality, and lost plasticity. FST splits that into two channels that co-evolve: task-specific nuance lives in
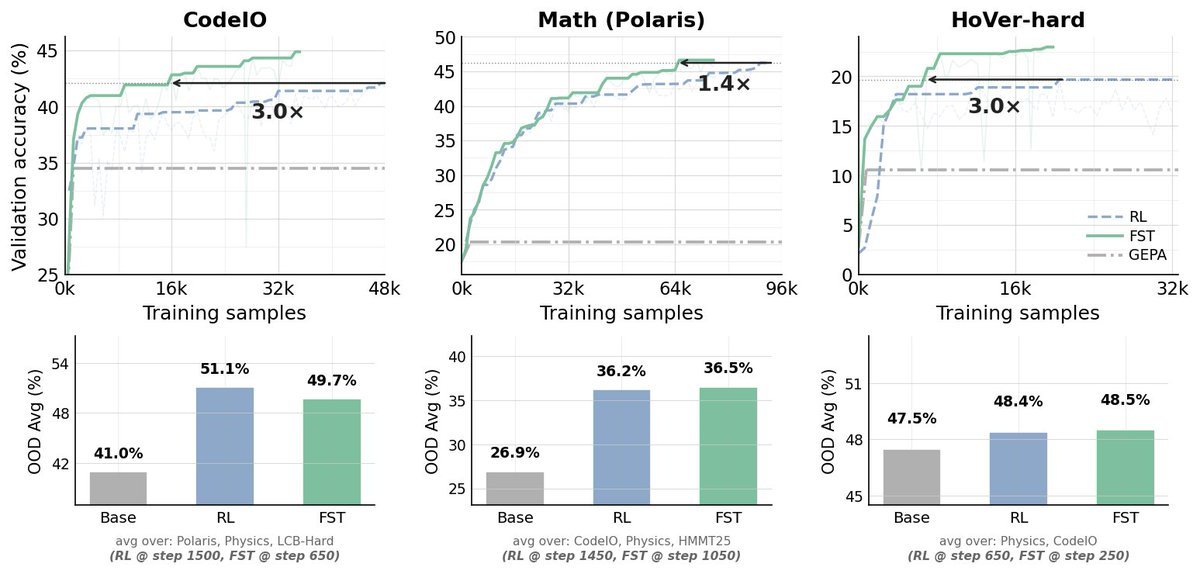
3/ FST beats RL-only across four axes:
- Data efficiency: FST reaches RL's running peak in substantially fewer optimizer steps — 3.0× fewer on CodeIO, 1.4× on Math (Polaris), and 3.0× on HoVer-hard — and continuing past the crossover, FST's running peak also exceeds RL's on all
How FST Works: To leverage the strong in-context learning of current LLMs, we treat the context as "fast weights" and model parameters as "slow weights", drawing from a rich literature in classic ML
Announcing Fast-Slow Training (FST) pairing "slow" weights with "fast" context.
We try to answer the question, can LLMs adapt continually without losing base skills?
FST vs RL:
- 3x more sample-efficient
-Higher performance ceiling
- Less KL drift
- Continual learning: succeeds
Excited to share our first research paper Learning, Fast and Slow: Towards LLMs That Adapt Continually.
Fast-Slow Training (FST) combines optimized context with model weight updates.
Read more here: arxiv.org/pdf/2605.12484
1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training
4/ This reframes post-training. The default view treats adaptation as one channel — push every improvement into the weights — and pays for it with forgetting, eroded generality, and lost plasticity. FST splits that into two channels that co-evolve: task-specific nuance lives in
3/ FST beats RL-only across four axes:
- Data efficiency: FST reaches RL's running peak in substantially fewer optimizer steps — 3.0× fewer on CodeIO, 1.4× on Math (Polaris), and 3.0× on HoVer-hard — and continuing past the crossover, FST's running peak also exceeds RL's on all
2/ A core issue with parameter-only RL is that it forces task-specific learning into the model weights. Traditional RL can improve model performance on the current task, but it also tends to shift behavior away from the base model, increase forgetting and reduce plasticity. On
1/ At Eragon, we’re building an AI operating system that connects a company’s entire tech stack into a single interface for work, powered by a model post-trained on the customer’s own data so it understands the company’s unique context.
We believe that AI system post-training