Really grateful to have 7 papers accepted at @icmlconf 2026, including 2 spotlights!
Massive thanks to all my collaborators—I’ve been lucky to work with such brilliant people
See you all in Seoul?…it feels surreal saying that while still in Rio for ICLR 😄 #ICML2026
We’re hiring!
Looking for Interns, Research Assistants, and Postdocs to work on Automated Interpretability--building systems that can analyse, explain, and intervene on large models to make them safe!
Work with me @Oxford, or remotely. Apply by Nov 15:
forms.gle/bKp8x2eYiFfmpC…
Excited to share our paper: "Chain-of-Thought Is Not Explainability"!
We unpack a critical misconception in AI: models explaining their Chain-of-Thought (CoT) steps aren't necessarily revealing their true reasoning. Spoiler: transparency of CoT can be an illusion. (1/9) 🧵
New Paper 🎉: arxiv.org/pdf/2401.01814…
Can language models relearn removed concepts?
Model editing aims to eliminate unwanted concepts through neuron pruning. LLMs demonstrate a remarkable capacity to adapt and regain conceptual representations which have been removed
🧵1/8
🚨 New Paper Alert: Open Problem in Machine Unlearning for AI Safety 🚨
Can AI truly "forget"? While unlearning promises data removal, controlling emergent capabilities is a inherent challenge. Here's why it matters: 👇
Paper: arxiv.org/pdf/2501.04952
1/8
📢 🎉 New paper with @_clementneo & Shay Cohen! We study how attention heads work with MLP neurons to predict the next token. We find a set of interpretable activity. More in the thread!
How does a 1-layer transformer carry out n-digit addition?
"Understanding Addition in Transformers" has been accepted to #ICLR2024!
We find that a 1-layer model processes digit-specific streams in parallel, and uses distinct algorithms for different digit positions.
🧵1/8
🎉 New paper to appear at ACL 2023 : arxiv.org/abs/2305.17553
Large Language Models (LLMs) are powerful tools, but they can memorize false or outdated associations. Model editing techniques promise to solve this, but do they really work?
1/
New paper alert! 🚨
Important question: Do SAEs generalise?
We explore the answerability detection in LLMs by comparing SAE features vs. linear residual stream probes.
Answer:
probes outperform SAE features in-domain, out-of-domain generalization varies sharply between
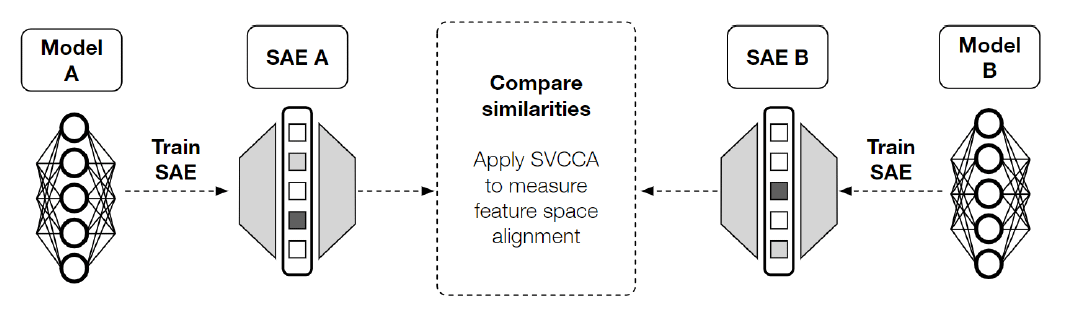
📢 New paper!
How universal are features across LLMs?
We tackle this question using Sparse Autoencoders (SAEs) and Representational Similarity Metrics.
🔍 We find that Sparse Autoencoders (SAEs) trained on LLMs reveal universal feature spaces across LLMs.
🚨New AI Safety Course @aims_oxford!
I’m thrilled to launch a new called AI Safety & Alignment (AISAA) course on the foundations & frontier research of making advanced AI systems safe and aligned at @UniofOxford
what to expect 👇
robots.ox.ac.uk/~fazl/aisaa/
New Paper 📢✨ Beyond Training Objectives: Interpreting Reward Model Divergence in LLMs 🚨
Does your LLM have the reward model you think it does?
Performance in training doesn’t provide much info about an LLM and can’t distinguish deceptive LLMs from aligned ones.
1/8
Technology = power. AI is reshaping power — fast.
Today’s AI doesn’t just assist decisions; it makes them. Governments use it for surveillance, prediction, and control — often with no oversight.
Our new paper proposes some ML safeguards to resist AI-enabled authoritarianism: