This is a long overdue section of the ML Engineering
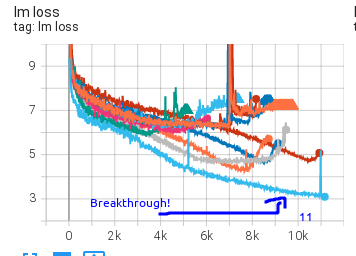
Understanding Training Loss Patterns
github.com/stas00/ml-engi…
I warn you that the "Understanding" part is overloaded here since most of the time we don't really understand why certain types of spikes happen. Here