1/ This week we released DINOv2: a series of general vision encoders pretrained without supervision. Good out-of-the-box performance on a variety of domains, matching or surpassing other publicly available encoders.
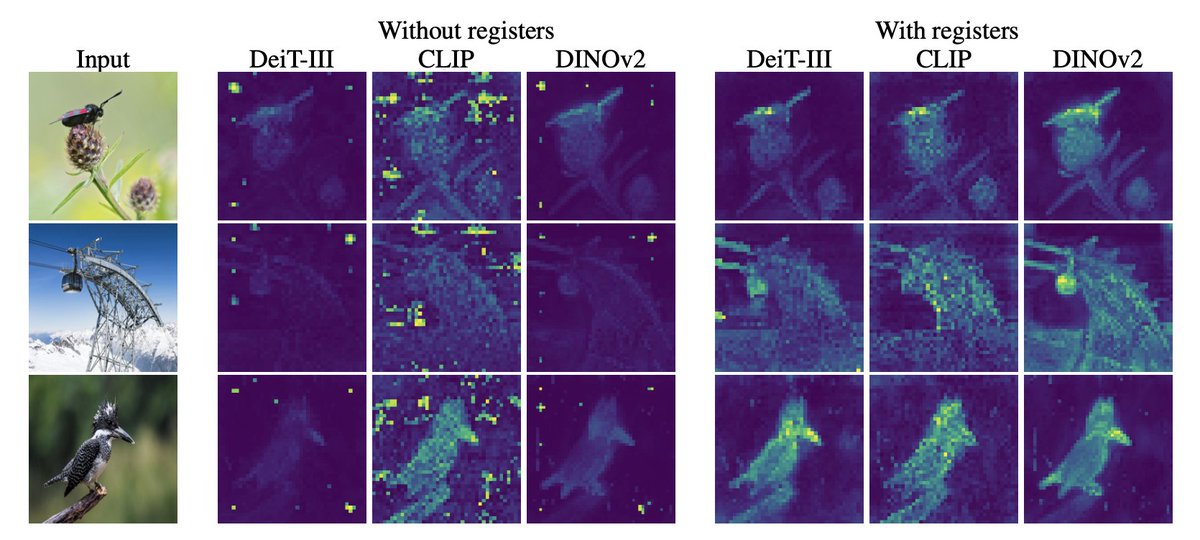
Vision transformers need registers!
Or at least, it seems they 𝘸𝘢𝘯𝘵 some…
ViTs have artifacts in attention maps. It’s due to the model using these patches as “registers”.
Just add new tokens (“[reg]”):
- no artifacts
- interpretable attention maps 🦖
- improved performances!
what happens in the residual stream of gemma3? l2 norm of activation explodes at the end of every transformer block after x=x+res. key architectural difference between gemma2 and 3 is softcapping vs qknorm. 1b is not even multimodal (fig reps gemma2-2b vs 3-1b). what's wrong?
DINOv2+registers=♥️
We are releasing code and checkpoints for DINOv2 augmented with registers and a slightly better training recipe. No more of those pesky artifacts!
Simple one-liner, try it out:
dinov2_vitg14_reg = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitg14_reg')
Is there a good reason we use softmax losses in contrastive learning, instead of just doing MSE? ie L = ||xi-xi'||² - lambda sum_k ||xi-xk'||²
I'd guess the optimization dynamics are maybe friendlier, but does anyone have a good pointer?
Both for CLIP and SSL btw
Funniest bug of my phd: model loses 1 point if pretrain and eval use different conda env
The difference was libjpeg vs libjpeg-turbo
iiuc the jpeg algo is not entirely standardized (wtf?) and libjpeg != libjpeg-turbo
Tiny differences in decoding artifacts caused a 1 point drop!
Alright actual serious post.
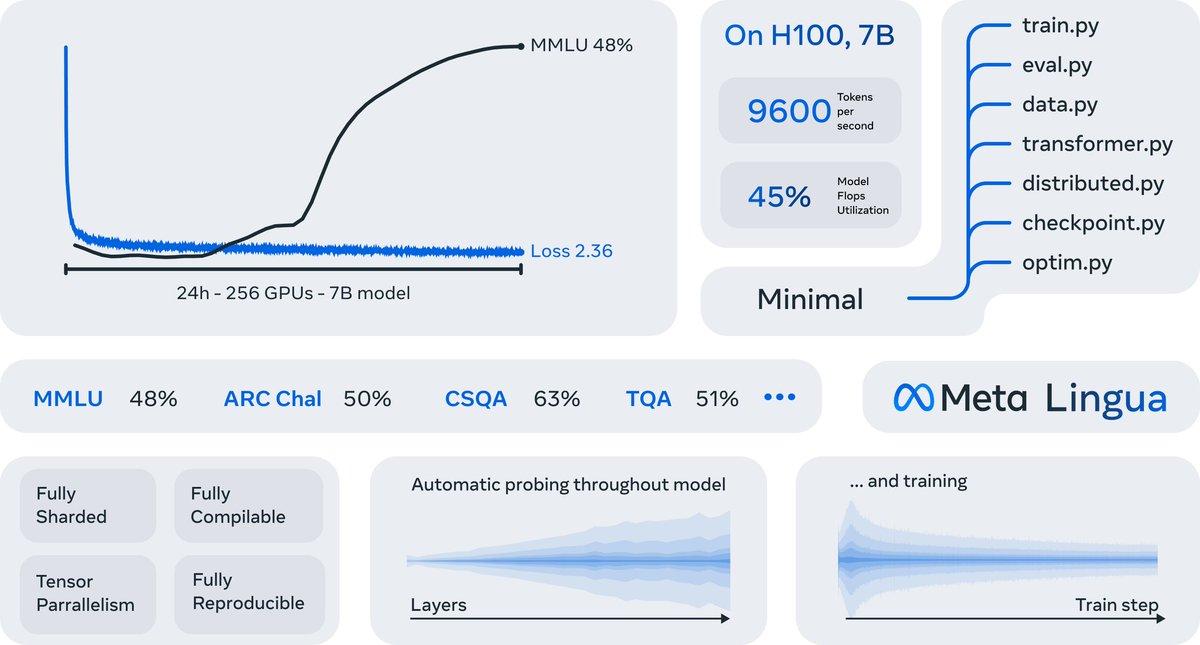
Lingua := super simple codebase + torch.compile for speed
--> clean, hackable, but still efficient
*It can train a 7B >llama2 in 24h*. Crazy. If you got the gpus, not only can you train a good 7B, you can *iterate* on it. You can do *research*
🚨 RELEASE ALERT ‼️
github.com/facebookresear…
THIS CHANGES EVERYTHING
$META just dropped a game-changing codebase!
Now everyone can do LLM research! 😱
🧵10 best things people are already building with lingua 🔥👇
I did not realize people used frameworks for simple distributed trainings.
Tip: for 80% of trainings you just need DDP, and it's trivial to setup
For the rest go with fsdp (either pytorch fsdp2 or the single-file fsdp in the CAPI repo)