
Ishaan Gulrajani
1,031 posts


Ishaan Gulrajani
@__ishaan
San Francisco
Joined November 2010
- OpenAI is nothing without its people.
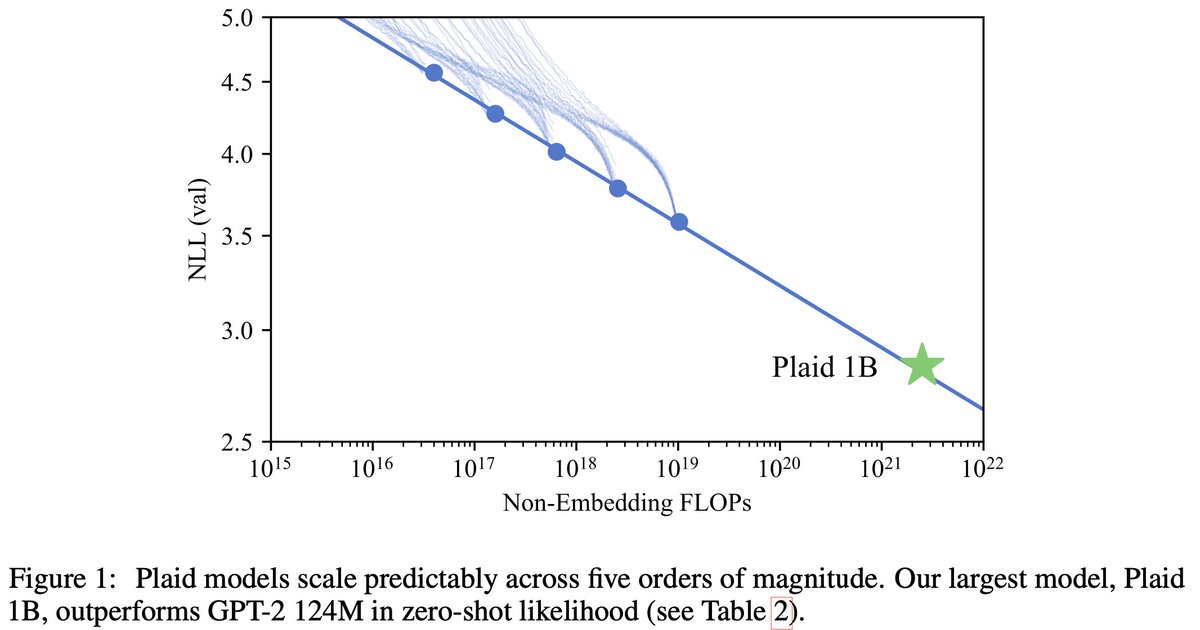
- New paper with @tatsu_hashimoto! Likelihood-Based Diffusion Language Models: arxiv.org/abs/2305.18619 Likelihood-based training is a key ingredient of current LLMs. Despite this, diffusion LMs haven't shown any nontrivial likelihoods on standard LM benchmarks. We fix this!🧵
- i love the openai team so much
- .@ilyasut gets it: There's very little world knowledge that is strictly impossible to learn from text, but some things more efficiently learned through other mediums. But, I claim: the efficiency advantage of multimodal learning *increases*, not decreases, with scale.Replying to @10_zin_The scale of GPT allows it to learn about the world just by reading, despite having no eyes and ears. For example text-only GPT understands red is more similar to orange than blue, despite having never seen them. But of course, with vision you learn more and faster.
 00:00
00:00 - Very happy to share our work on invariance, causality, and out-of-distribution generalization! With Martín Arjovsky, Léon Bottou, David Lopez-Paz.Long-awaited and beautiful paper on "Invariant Risk Minimization" by Arjovsky et al. studies relationship between invariance, causality and the many pitfalls of ERM when biasing models to simple functions. Love the Socratic dialogue the paper ends with... arxiv.org/abs/1907.02893

- This GAN works okay, except sometimes it draws faces on things which really shouldn’t have faces.

- Super cool! Also: "we observe that training using a discriminator leads to significantly lower L2 distances than when directly minimizing L2." turns out we've been doing regression wrong this whole time 😅RL + GANs: Program synthesis with an agent that uses a paint program to fool a discriminator. Paper+Blog: deepmind.com/blog/learning-…
 GIF
GIF - Replying to @mat_kelceyTranspose conv is faster, might work better if you have lots of data & training time because resample+conv is equivalent to transpose conv with a constraint on the weight matrix. distill.pub/2016/deconv-ch…
- Replying to @sedielemFun fact that didn’t make it into the paper: when we started the project, the gap was 10,000x 😳. It took stacking many 10% improvements to make it this far.
- Quasi-Recurrent NNs: masked gated convs + fast elemwise-only recurrence, *16x faster* than LSTM! @jekbradbury et al. openreview.net/forum?id=H1zJ-…
- Replying to @sedielemVery nice post! A related idea that I’ve found useful is Tenenbaum’s “suspicious coincidence” (eg web.mit.edu/cocosci/Papers…): A fair coin yielding HHHHHHHHHH is “anomalous” not because it has low probability under our model, but because it has high prob under an alternate model.
- from a glance this is an excellent sequel to @lucastheis ' 2015 paper, which remains the most important thing i've ever read on evaluating generative modelsWhat does it mean for an image, video, or text to be 𝑟𝑒𝑎𝑙𝑖𝑠𝑡𝑖𝑐? Despite how far we've come in 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑖𝑛𝑔 realistic data, 𝑞𝑢𝑎𝑛𝑡𝑖𝑓𝑦𝑖𝑛𝑔 realism is still a poorly understood problem. I've shared my thoughts on how to correctly quantify realism here:







