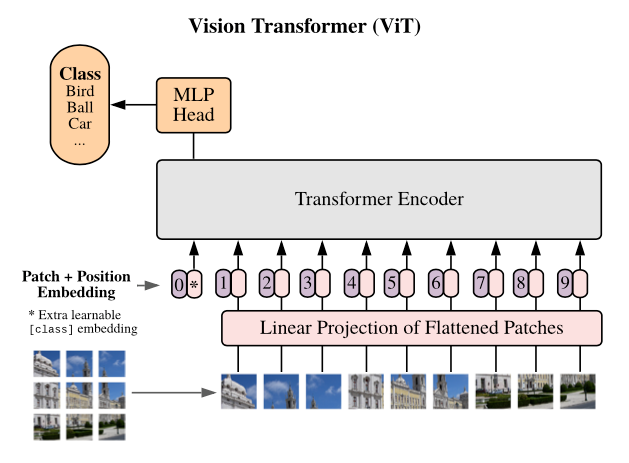
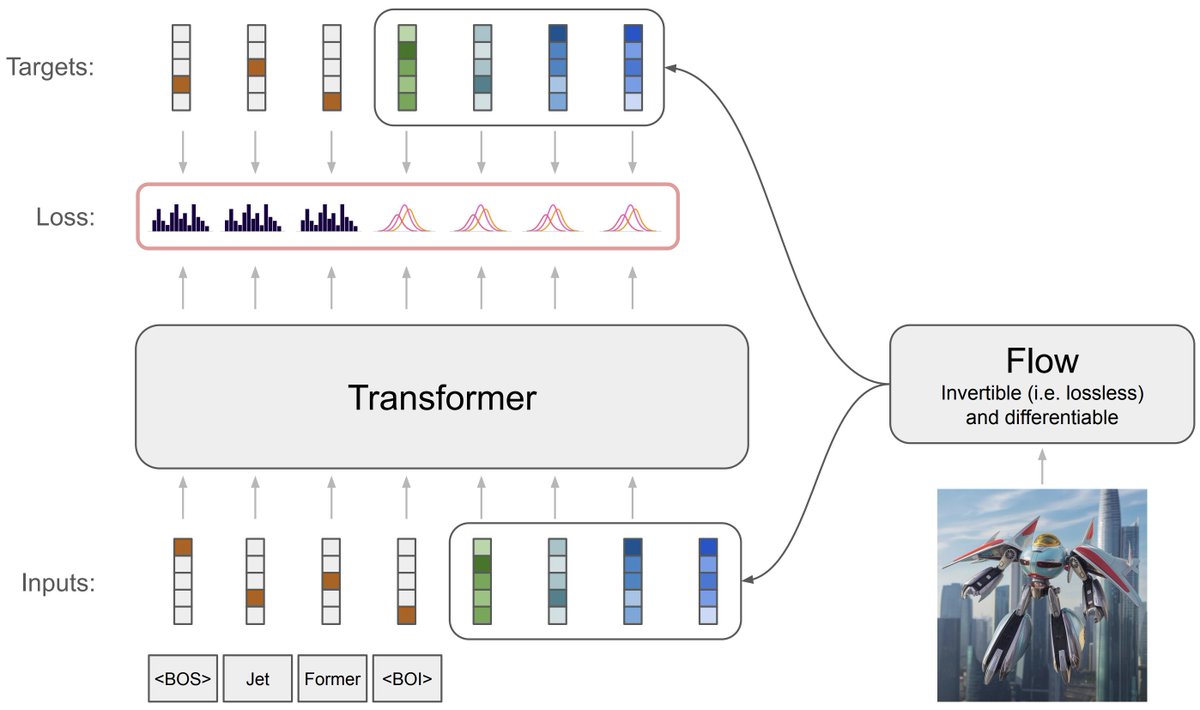
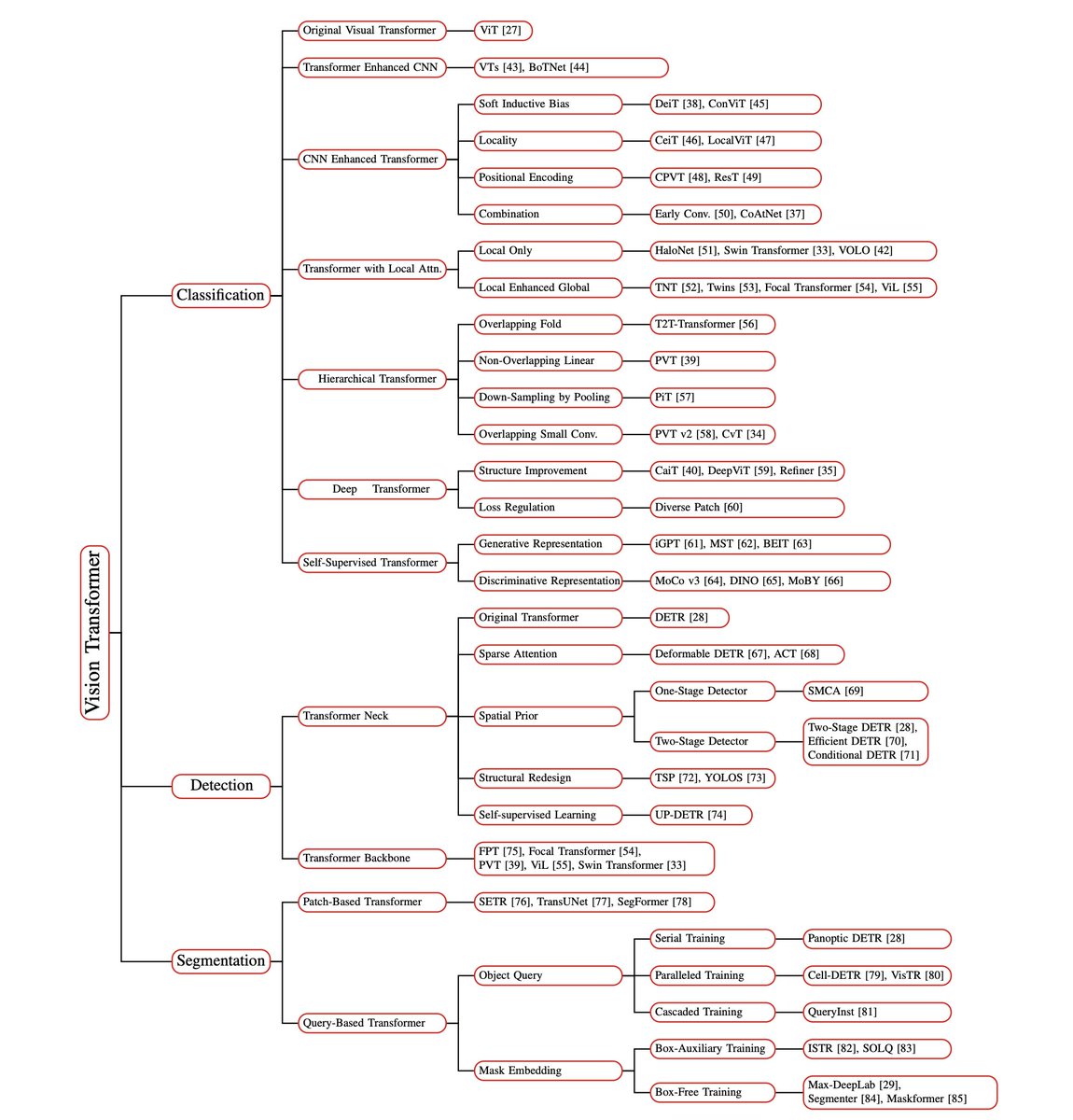
Ok, it is yesterdays news already, but good night sleep is important.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @XiaohuaZhai and @giffmana, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.