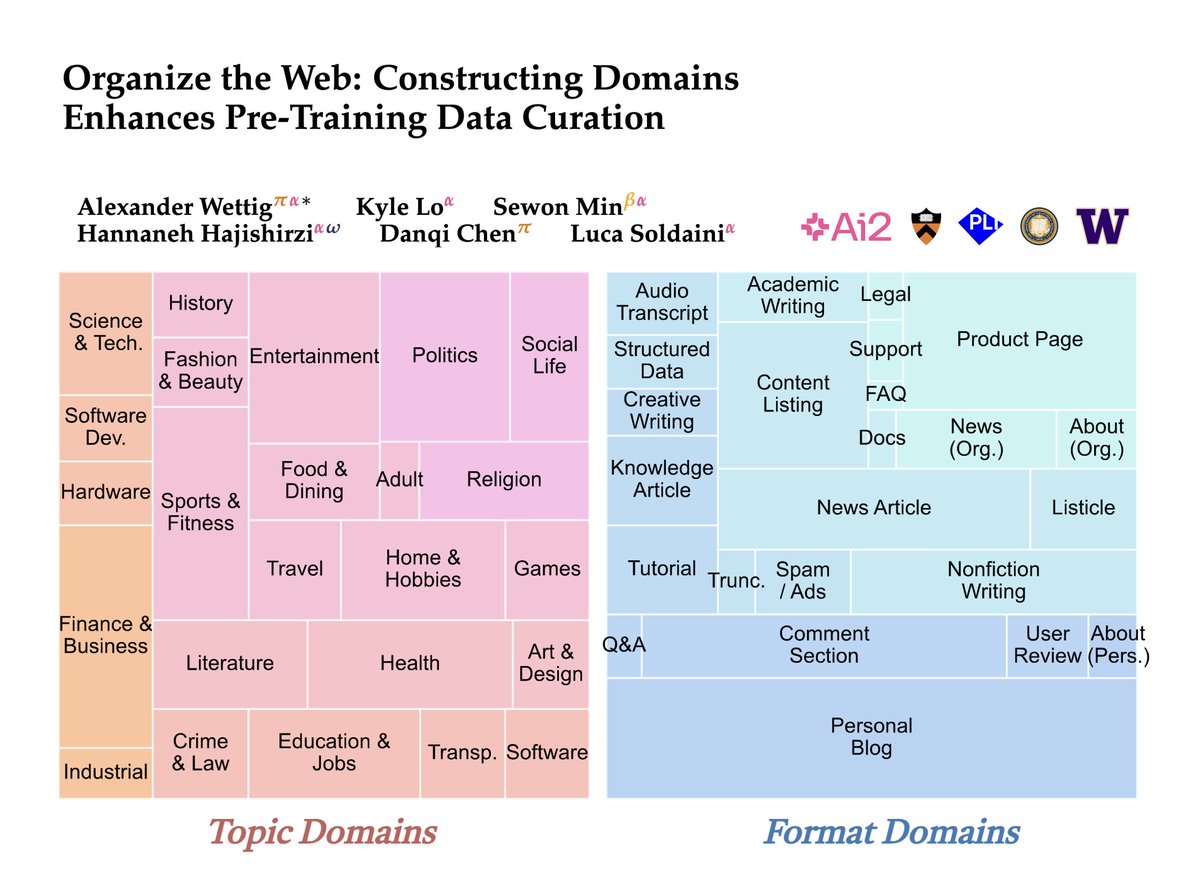
🤔 Ever wondered how prevalent some type of web content is during LM pre-training?
In our new paper, we propose WebOrganizer which *constructs domains* based on the topic and format of CommonCrawl web pages 🌐
Key takeaway: domains help us curate better pre-training data! 🧵/N