wrote a paper: it lets you *train* in 1.58b! could use 97% less energy, 90% less weight memory. leads to a new model format which can store a 175B model in ~20mb. also, no backprop!
arxiv mods rejected this paper. they won’t say why. I don’t really care at this point, took weeks to get approval to submit. I think twitter boys will like it, that’s what matters.
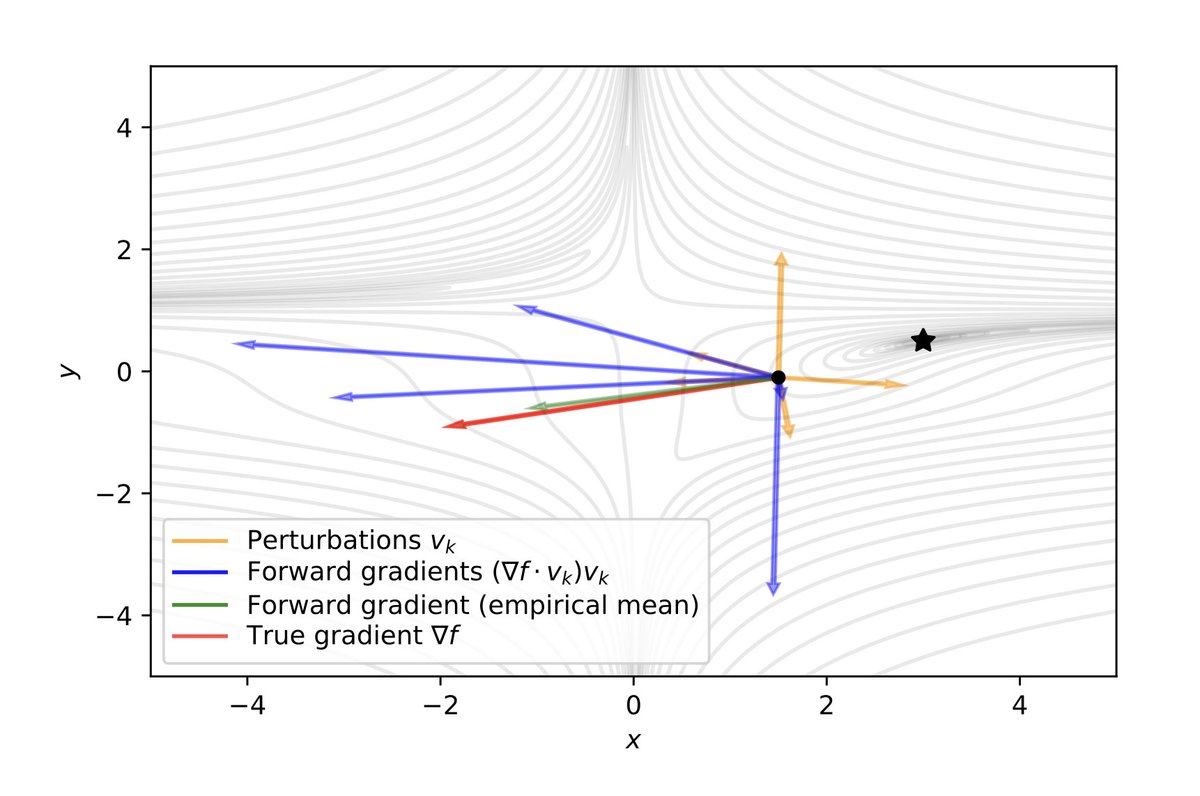
the core trick I use comes from `Gradients without Backpropagation`. using the JVP, you can find the alignment of random vectors to the gradient, and reconstruct it. only a forward pass!
doesn’t this violate information theory? no, it’s probably that the domain in which models are compressible is the correlation of their loss gradient to noise. or something.
what about bitnet? bitnet does inference in 1.58b, but training uses precision weights. basically they clamp weights to ternary {-1,0,1} in forward pass, and pretend they didn’t in backward pass.
it’s often said academia is unwell. I was unimpressed with how these people operate. Real Science needs a massive cultural change. More openness, less hostility, less structure. I’m not a real researcher; freely discard my comments.
actually, one acknowledgement: call me schizo but months ago I was discussing the algorithm loudly at dinner and I swear @DarioAmodei was watching me, grinning just like this. just eating with his wife. perhaps some things are fated.
the other thing is distributed training. the steps are tiny, the optimizer is stateless. imagine: a distributed training cluster across the internet with such low traffic it’s undetectable.