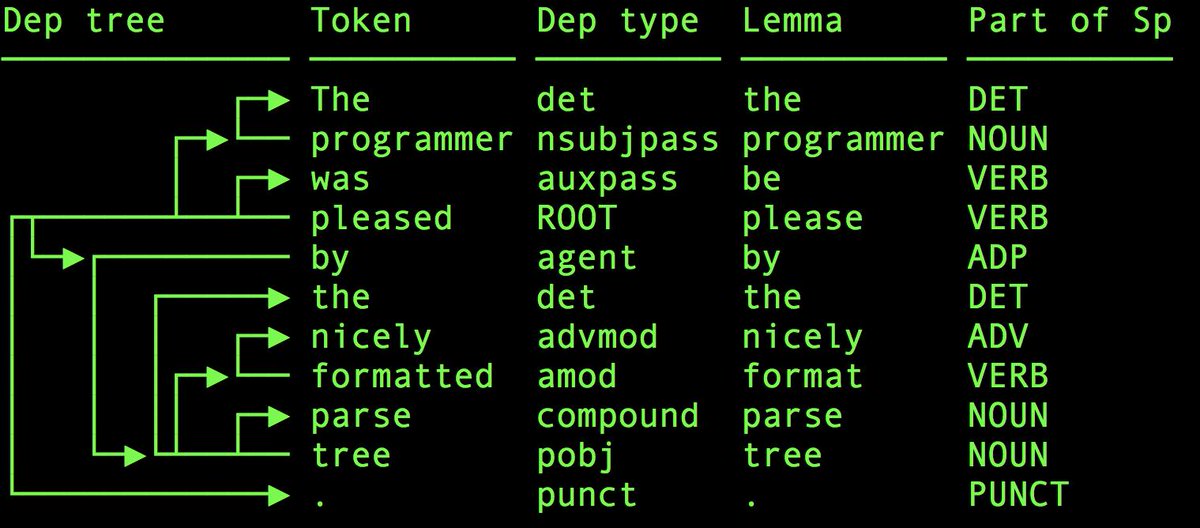
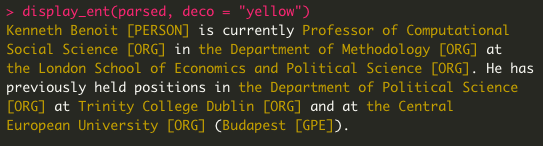
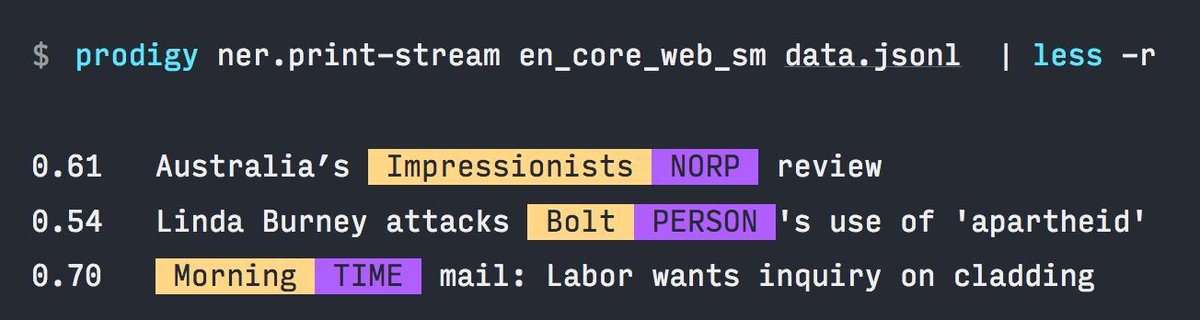
Like many of you, I'm incredibly disappointed by DataCamp. I wanted to make a free version of my spaCy course so you don't have to sign up for their service – and ended up building my own interactive app. Powered by the awesome @mybinderteam & @gatsbyjs 💖