Pinned

"The future is already here – it's just not evenly distributed."
- William Gibson
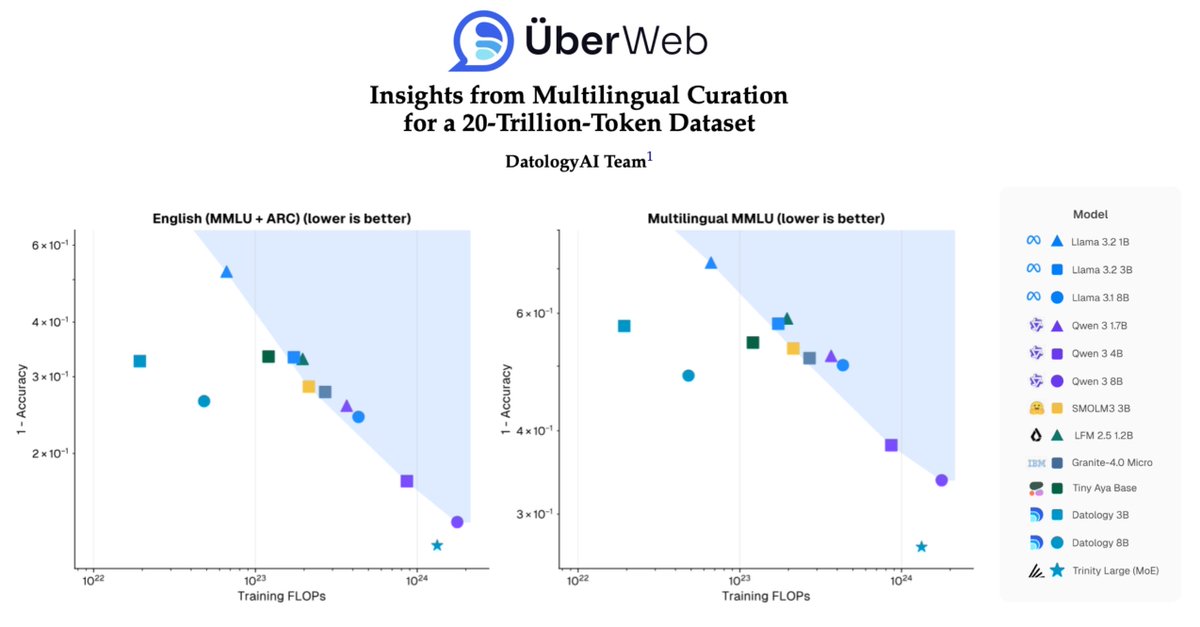
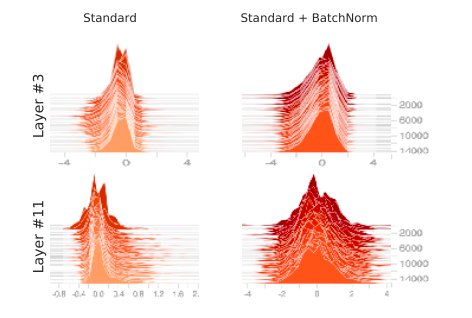
Today we're sharing results from ÜberWeb, our multilingual curation suite, which matches many of the best open models with a fraction of the train compute, all through better data.

1/ People often think better multilingual models must come at the cost of English performance. Not true. The constraint isn’t capacity, it’s data quality, and we can fix it.
Today @datologyai shares ÜberWeb: a year of multilingual curation lessons, scaled to 20T+ tokens.