no model is able to escape the 66% accuracy @ 120k tokens, except Gemini 2.5 Pro which sits at 90%
even the new GPT-4.1 with 1 mil ctx is stuck at 60%...
(please tells us your secret gemini🥺)
Long Context benchmark updated with GPT-4.1. Looks like it's the "optimus" version instead of the better performing original quasar.
The smaller versions are not usable in long context.
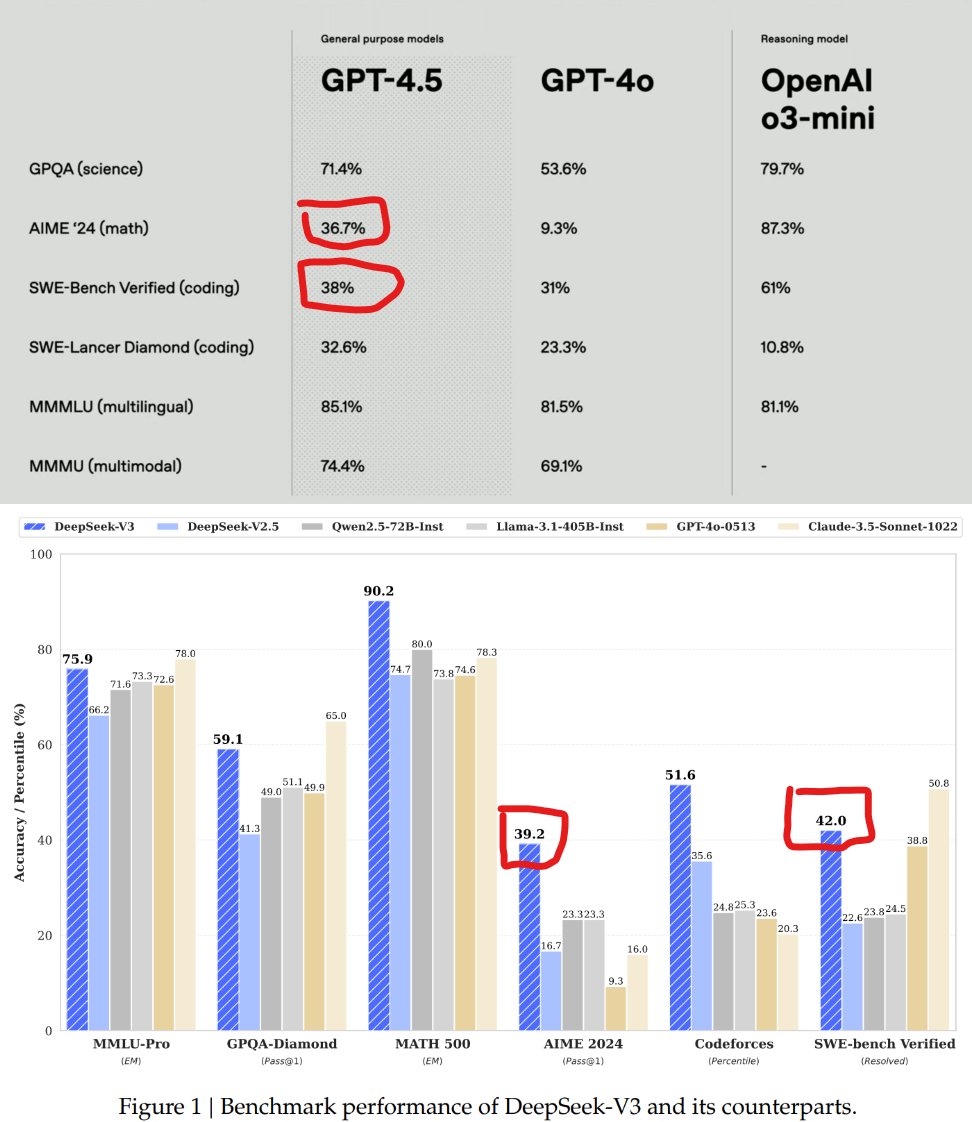
how does DeepSeek V3 win against GPT-4.5? (NOT R1 btw)
openAI claimed that GPT-4.5 is a VERY big model, yet GPT-4.5 falls short compared to DeepSeek-V3
What.
super interesting read
maybe we just need to find the rules that are class 4 equivalent when generating synthetic data to get better performance on reasoning
making a video on this now😳
what also intrigued me about this is that @ 120k context window, 2.5 pro did a 90% accuracy while no one else crossed 66%
everyone else starts to fall off hard @ 4k
what new attention technique did google invent???
(and why is there a sudden dip at 16k???????)
small tangent - people always ask about gemini context window, yeah it’s big, it probably uses some sliding window-like architecture too (don’t quote me).
most notably though, google has it’s own proprietary accelerators called TPUs. much more GPU memory, so they can fit larger