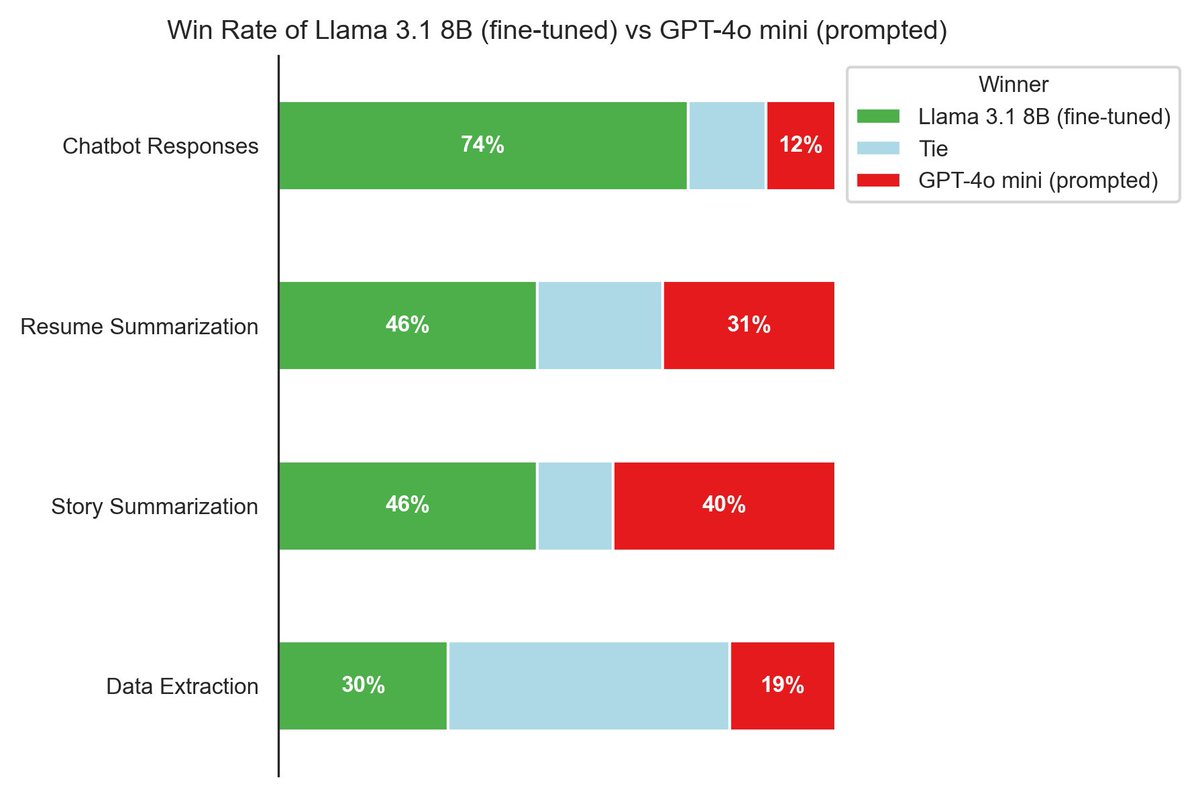
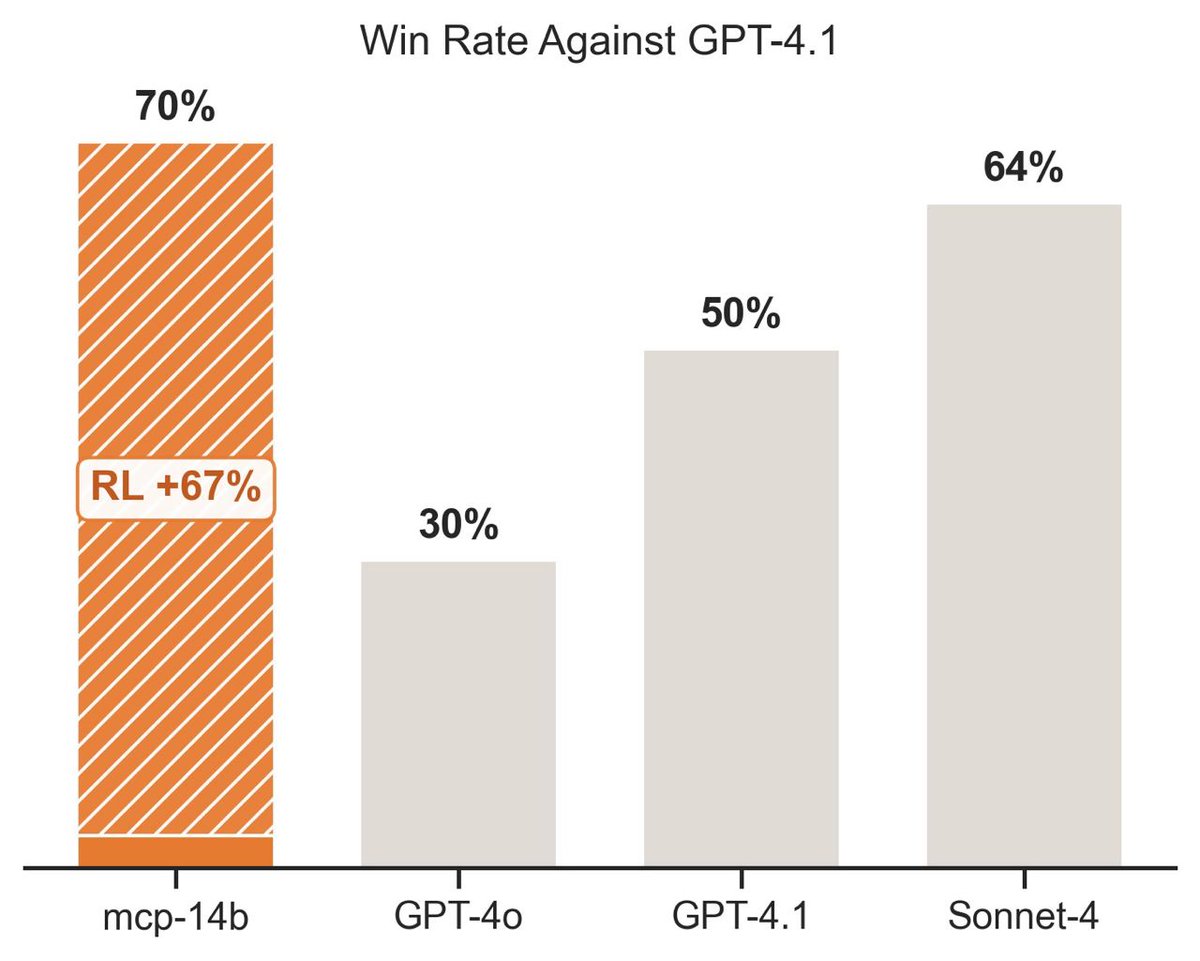
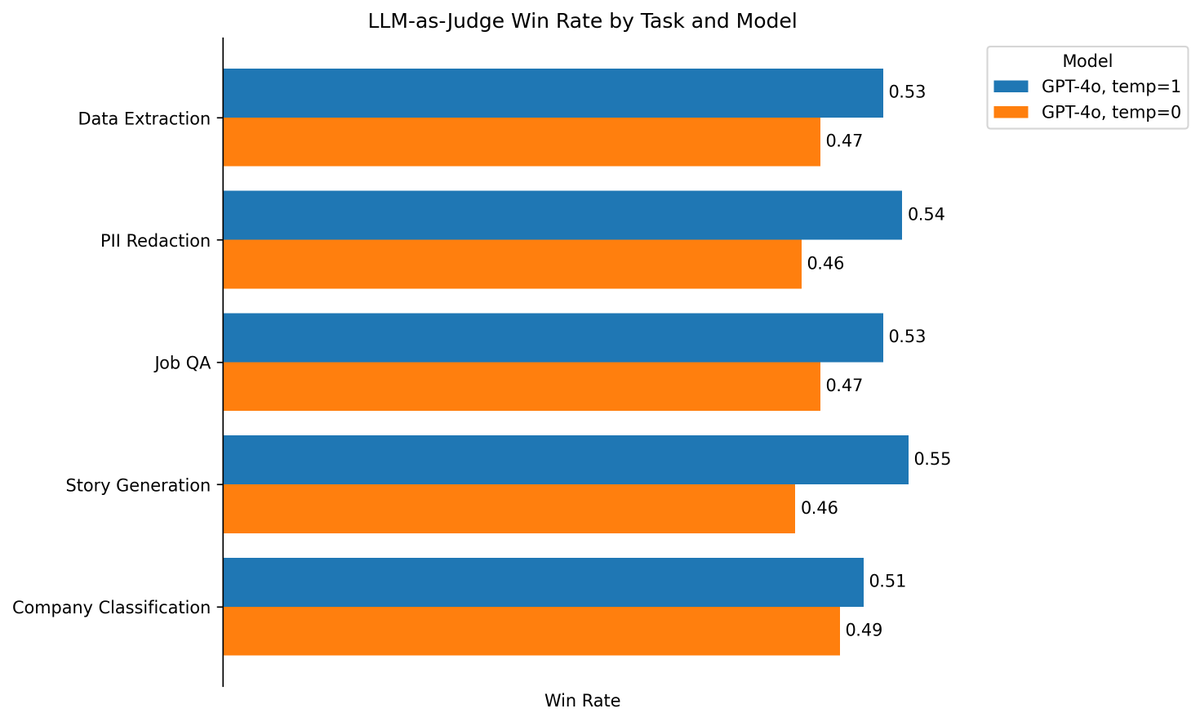
At a recent dinner I met a very senior engineer at one of the Big Four tech cos.
His team develops tooling for a 0-engineer future. They're not allowed to tell anyone internally what they're working on to avoid mass panic. He figures mega layoffs start in 18 months.