I got a chance to sit in on some @ycombinator pitches this week. A few thoughts:
1⃣ I have AI fatigue--SO MUCH. Very little of it is deep tech; mostly applying OpenAI FM to stuff. Investors in this space: I have no idea how you do this. I feel like there's a lot of $ to be lost.
Successful intern projects:
1. High value if completed.
2. Low risk if not completed.
3. Able to finish in allotted time (2-3 months).
4. Exciting to work on and talk about.
Anything else I'm missing?
Embedded DBs are having a renaissance.
RDBMS: SQLite
OLAP: DuckDB
Graph: KuzuDB
Search: Chroma
The developer experience is so good on these. Things just work. Really cool to see.
My @InfoQ talk 🎙️ on the "Future of Data Engineering" is up! I cover the six stages of data pipeline maturity:
0. None
1. Batch
2. Realtime
3. Integration
4. Automation
5. Decentralization
Check it out! 👀
(I'm so sorry for the link picture)
It's out! I've been working with @paulgb, @vigneshc, the team @responsive_apps, and others to put together an LSM storage engine built on object storage.
Contributors, users, and feedback would all be great!
“Reddit’s database has two tables”
“Instead, they keep a Thing Table and a Data Table. Everything in Reddit is a Thing: users, links, comments, subreddits, awards, etc. Things keep common attribute like up/down votes, a type, and creation date”
🥴
kevin.burke.dev/kevin/reddits-…
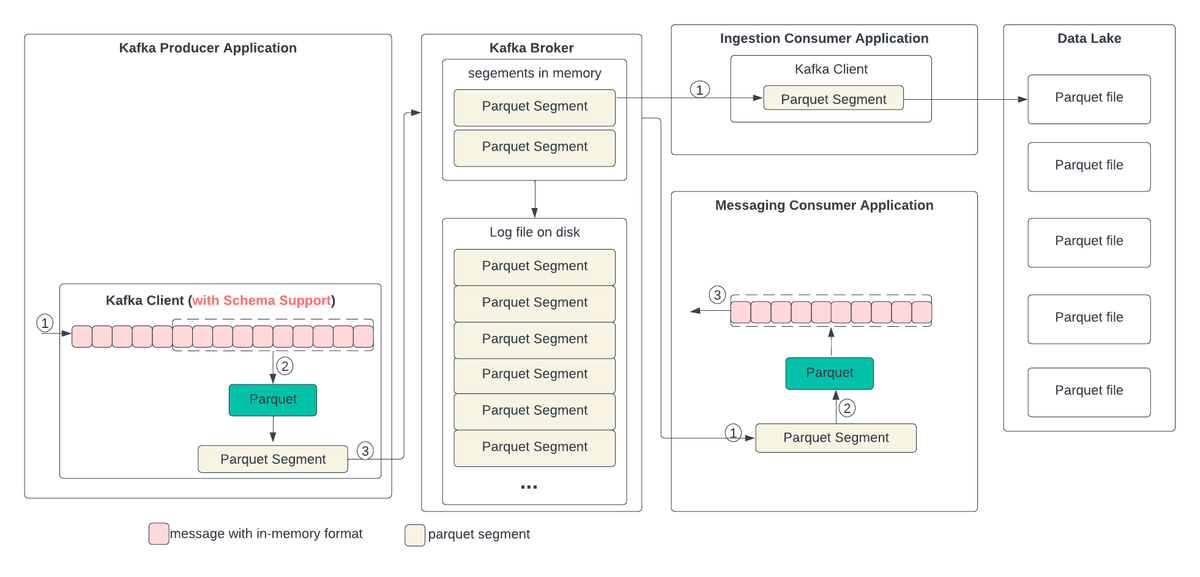
"KIP-1008: ParKa - the Marriage of Parquet and Kafka"
That's an interesting proposal: writing #Kafka segments as #Parquet files. Can see the appeal for data lake ingest; wondering though how well the columnar file structure plays with Kafka semantics 🤔.
cwiki.apache.org/confluence/dis…
DBs are getting totally ripped apart right now and I love it. Query engines (trino, duck), storage (s3, gcs), and indexing (iceberg, hudi) all separate.
"Querying SQLite databases with DuckDB"
Enjoyed watching this fast-paced video by @markhneedham demoing how to use #DuckDB's query engine to run analytics queries against data in a #SQLite file. 5:50 well spent 🦆!
youtube.com/watch?v=ogge3k…
I'm open sourcing Recap, a dead simple data catalog for engineers! Unlike traditional catalogs, Recap is built to power infrastructure and tools that need metadata.
Read the docs:
docs.recap.cloud
Or dive straight into the Github repo:
github.com/recap-cloud/re…
Big news: I'm helping with @martinkl with a second edition of Designing Data-Intensive Applications! An early release of the first 3 chapters is now available (O'Reilly Learning subscribers only at this point) and we're hoping to finish it next year.